Agent-RL 相关算法
📅 发表于 2025/11/18
🔄 更新于 2025/11/18
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
agentrl
#agentrl
#LOOP
❓问题背景
📕核心方法
✍️实验设置
🍑关键结果
⛳未来方向
🌺 论文摘要
参考链接
核心方法
LOOP: 留一法算优势 + 去掉std + PPO Off-Policy + PPO Clip + Token级建模AppWorld 训练数据筛选:去掉难度3场景、再去掉6场景模型效果(Qwen2.5-32B-Inst, AppWorld)
TestNormal:TGC 达71.3分,SGC 达53.6分。整体均超过其他方法。重要结论
per-token > per-turn > per-traj,71.3 > 64.1 > 53.3组内std归一化 会降低9pt:71.3 -> 61.9 移除KL惩罚有效果:Test-C TGC 从 22.4 -> 26.6Loop 优于 GRPO:71.3 > 58。LOOP 非归一化 优于 GRPO 归一化 ?Loop 优于 PPO:71.3 > 50.8。Critic 不好训,易引入误差关键贡献
各方法对比实验❓问题背景
LLM Agent处理真实任务效果不行
python环境可能交互40轮、32k长度。stateful、多领域、多app、环境API交互现有模型效果不好RLOO 缺点
同策略算法,样本效率低。Trajetory-Level 建模,但Token-Level 通常更稳定一些。RL建模:llm token-level MDP
1. REINFORCE算法
参考笔记:REINFORCE、REINFORC++算法、优势AC算法
策略梯度,优势决定更新方向。优势大于0,鼓励;优势小于0,抑制。
2. RLOO 算法
参考笔记:RLOO
REINFORCE+留一法计算优势,无需Critic和Ref模型。
3. 本文LOOP 算法
RLOO + 异策略,具体引入PPO信任域,提升样本效率。4. GRPO 算法
5. PPO 算法
6. 其他非RL
不断筛选好样本,来微调模型。PPO 建模方式
Per-轨迹:把整个序列看成1个动作,计算1个总的重要性权重。GSPO 序列级IS权重
Per-Token:把每个词看成1个动作,为每个词 单独计算重要性权重。更稳定、平滑。
PPO Loss 计算方式
Seq-Level-Loss:PPO Seq-level-Loss, GSPO Seq-Level-LossToken-Level-Loss:DAPO Token-Level-LossPPO CLIP 粒度
per-trajectory:1条轨迹计算1个IS权重。
per-turn:为每个回合计算1个IS权重。
per-token:为每个token单独计算1个IS权重。
买东西,1个app,8个动作,每回合最多1个参数场景和任务
多样化复杂逻辑:邮件、支付、音乐、购物、打电话、文件系统等。9个真实app,457个API调用,单API最多17个参数。250个场景,每个场景有3个任务,总计750个任务。1-3档。训练评测数据量
35场景,105个任务。20场景,60任务。56场景,168任务。139场景,417任务。复杂、新APP。评测维度
1套单元测试,3个维度事情已完成:任务所要求的环境状态成功执行无副作用:没有对环境或APP造成额外的修改答案正确:agent最终答案和标准答案一致评估指标
任务目标完成率场景目标完成率3个任务全部完成,才算场景完成。状态
初始隐藏状态:Python REPL状态、模拟数据库等,智能体看不见,
上下文:user prompt
所有token序列:大模型生成token + 环境返回token,是agent可观察的历史信息。
动作
状态转移
LLM生成token 环境返回token轨迹概率
优化目标
📕核心方法
PPO Off-Policy 提高样本效率
多轮次训练ppo_epochs轮,训练多轮。重要性权重来做分布修正。ppo_epochs=1,则LOOP退化成RLOO。小批量学习多个mini-batch,进行多次梯度更新。PPO Clip 保证更新稳定
PPO-Clip 限制更新策略幅度 保证稳定标准差
不稳定的任务上,标准差大除以标准差,会削弱或抑制那些偶然成功的高奖励学习信号。差异
除以标准差。不除以标准差。LOOP 实验
不除以标准差好,能更有效地从不稳定的、探索性的行为中学习。相关算法
不除以标准差,避免难度偏差。Global std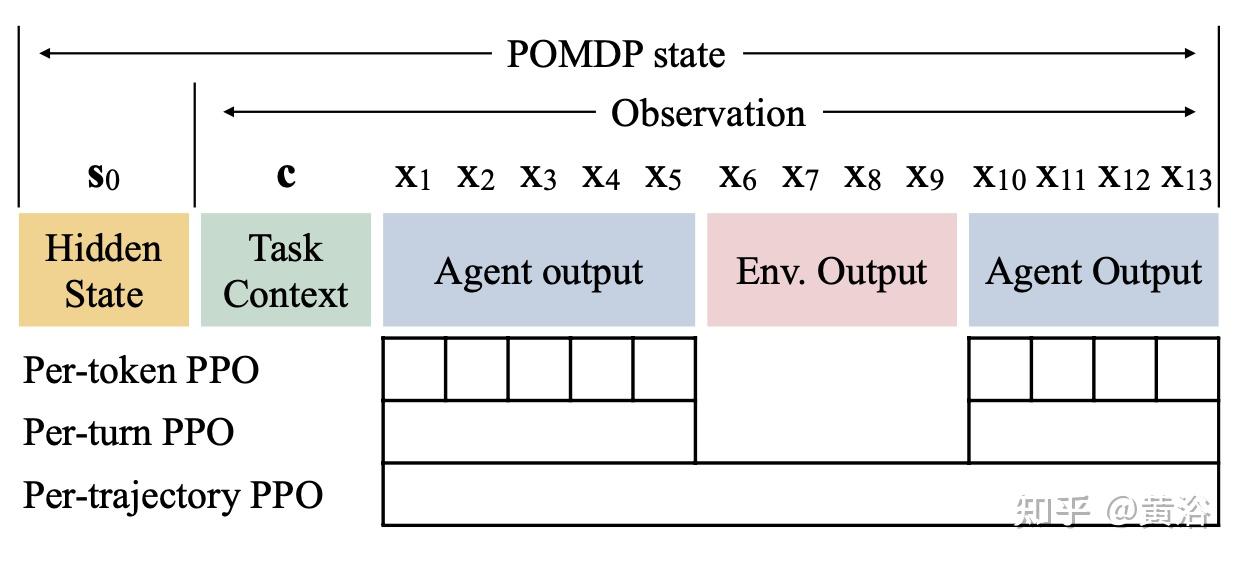
✍️实验设置
奖励函数
单元测试通过比例。no sparse训练数据
筛选出24场景,共72任务。先去掉难度3场景,只用难度1和2(35 -> 30)。 去掉6个场景:30 -> 24。其他超参
训练40轮,测试50轮。40个任务、每次学习40*6=240条序列1500 token;环境单次:3000 token。训练90轮,取最好的checkpoint。基础模型
训练任务/数据
筛选后的训练数据:24个场景,共72个任务。评测任务/数据
Test-normal, Test-Challenge算法/策略
LOOP, LORA训练超参
🍑关键结果
模型效果(Qwen2.5-32B-Inst, AppWorld)
TestNormal:TGC 达71.3分,SGC 达53.6分。重要结论
per-token > per-turn > per-traj,71.3 > 64.1 > 53.3组内std归一化 会降低9pt:71.3 -> 61.9 移除KL惩罚有效果:Test-C TGC 从 22.4 -> 26.6Loop 优于 GRPO:71.3 > 58。LOOP 非归一化 优于 GRPO 归一化 ?Loop 优于 PPO:71.3 > 50.8。Critic 不好训,易引入误差关键贡献
莽撞到谨慎:不必要代码执行减少6倍,避免了次优loop想当然到查文档:调用特定APP接口时,API文档查询增加60%瞎猜到求证:毫无根据的假设减少了30倍,虚构密码等重要位置减少了6倍脆弱到坚韧:失败后放弃次数减少3倍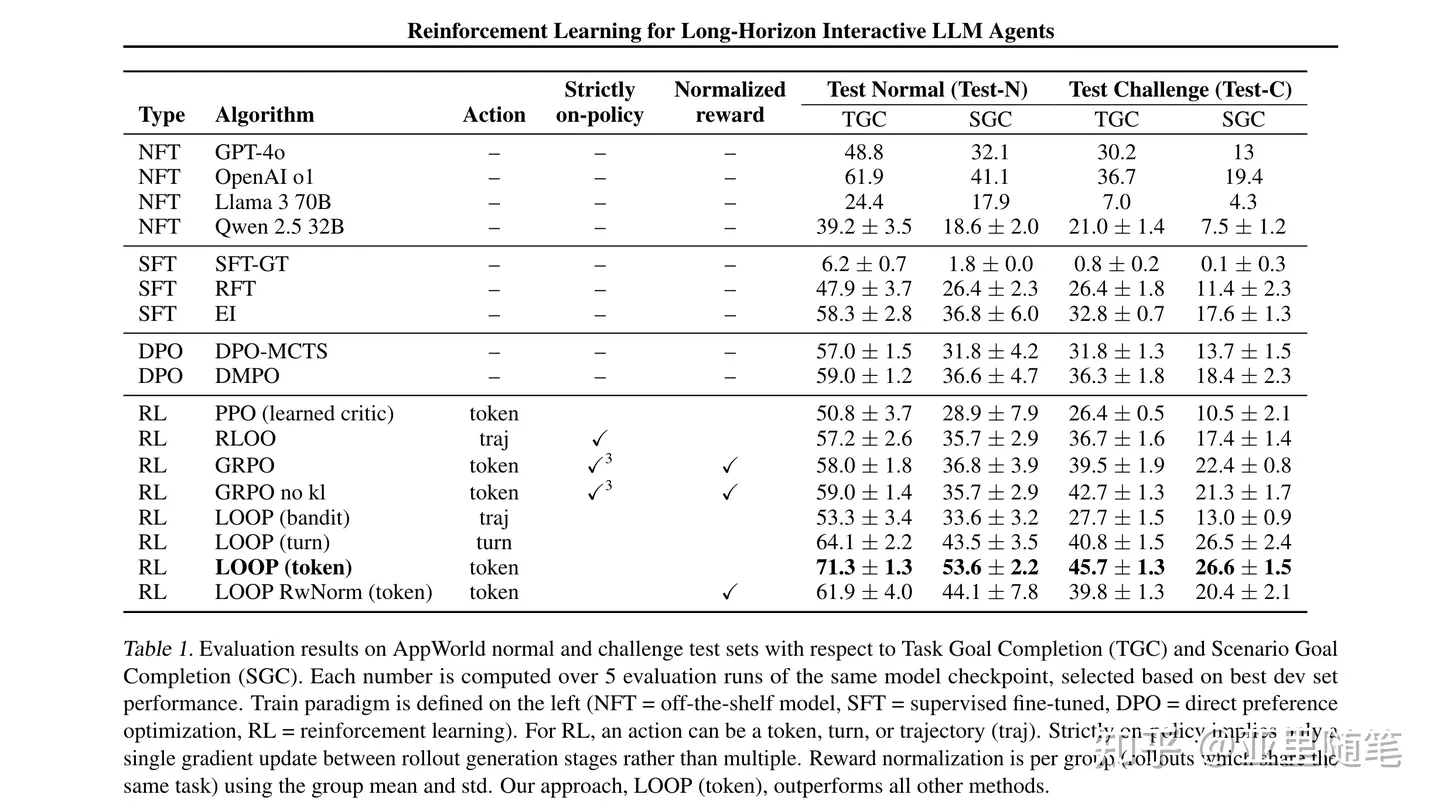

⛳未来方向
性能还不够好,提升成功率。目前仅70%完成。需提升真实复杂情况。 多模态能力:看懂网页截图、图表等。