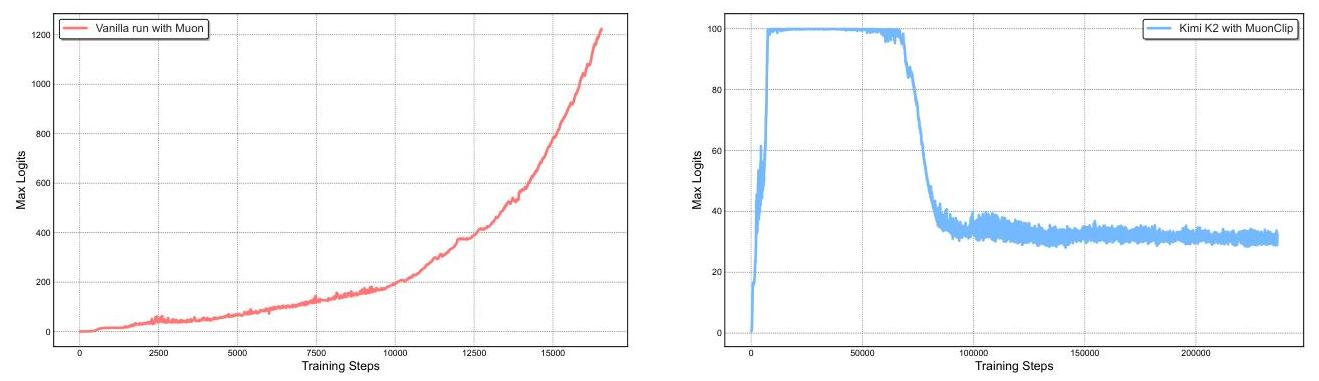
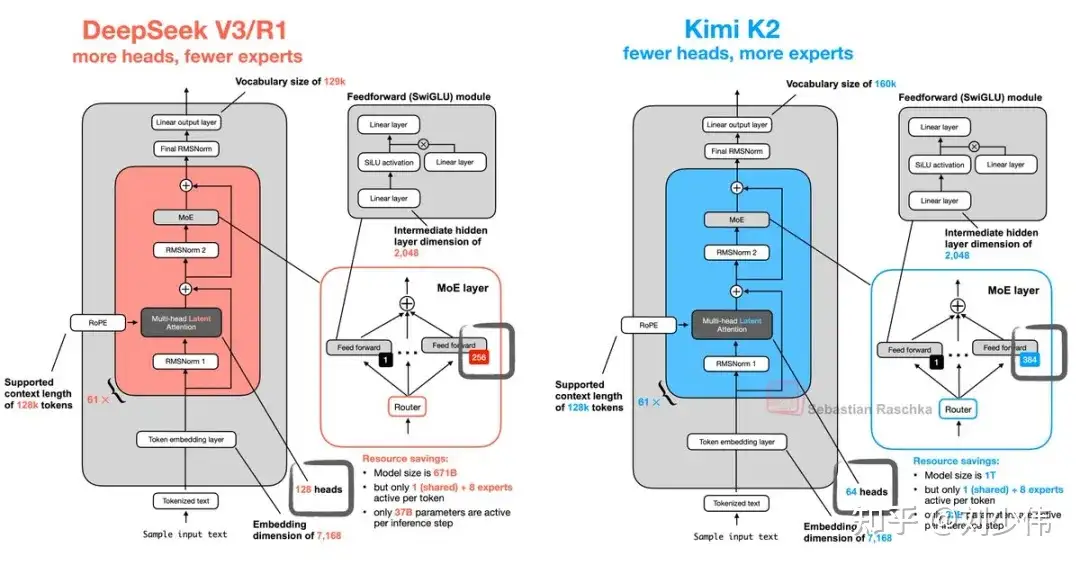
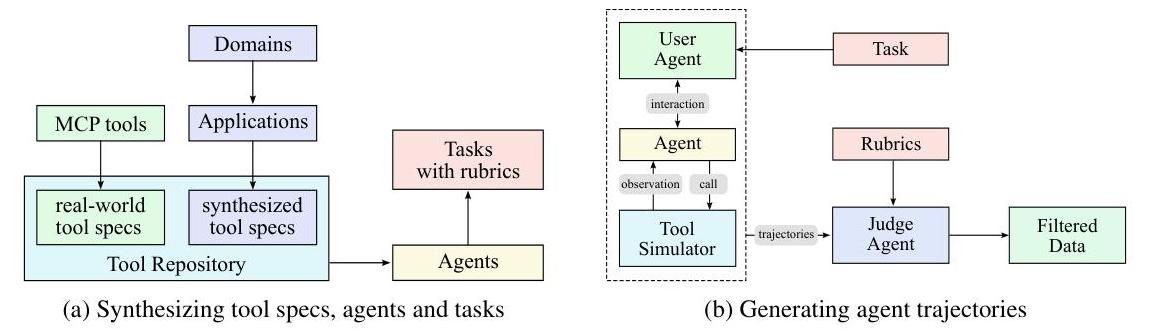
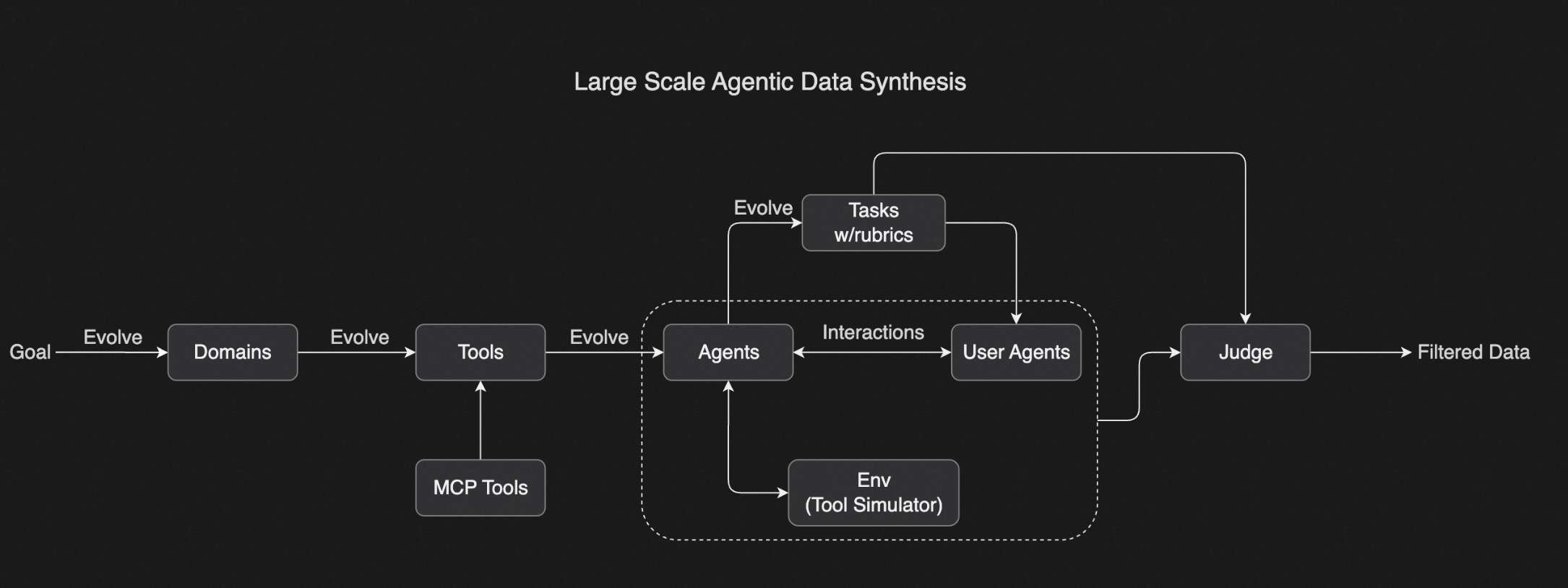
Kimi 系列
📅 发表于 2025/07/16
🔄 更新于 2025/07/16
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
kimi
#Kimi K2
#MLA
#MuonClip
#QK-Clip
#Agent数据合成技术
#Rewards Gym
#Self-Critic Rubric Reward
#Kimi Researcher
#上下文管理
#全异步rollouts
#Reinforce
#端到端RL学习
#工具使用数据生成方法
#Kimi1.5
#上下文扩展
#Partial Rollouts
#改进Policy
#Long2short