(18年笔记)强化学习基础
📅 发表于 2018/04/01
🔄 更新于 2018/04/01
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
强化学习
#智能体
#环境
#奖励
#状态
#动作
#值函数
#贝尔曼方程
#V函数
#Q函数
Why RL
学习数据模式 😞和环境交互、最大化累计奖励来学习最优策略状态、动作、奖励 序列是动态的 ⭐动态的、环境交互的问题。When RL
环境交互的序列决策问题,能定义出合适的奖励信号用RL硬Train一发就对了核心思想🧠
智能体🤖和环境交互🌎过程中,根据奖励信号🎁,不断学习调整策略来完成特定目标🏆。最大化的期望累计奖励(回报)。智能体🤖
感知环境状态和反馈的奖励,进行决策和学习环境🌎
1. 状态
环境的状态(智能体所处的状态),状态空间2. 动作
智能体可执行的动作,动作空间3. 策略
根据环境状态s决定下一步动作a,分为确定性策略和随机性策略4. 状态转移概率环境模型
5. 即时奖励环境模型
环境根据智能体行为给出的奖励,标量函数。当前状态s和执行动作a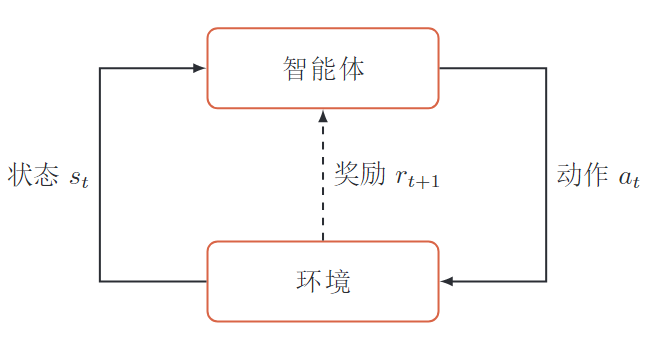
智能体与环境的交互是一个马尔可夫决策过程。
1. 马尔科夫过程
马尔可夫性,新状态只依赖于 当前状态2. 马尔科夫决策过程
依赖于 当前状态和 智能体当前的动作轨迹定义
一次交互过程(马尔可夫决策过程),给定策略轨迹概率
初始状态的概率 和 所有时刻概率的 乘积智能体执行动作、环境更新状态 💥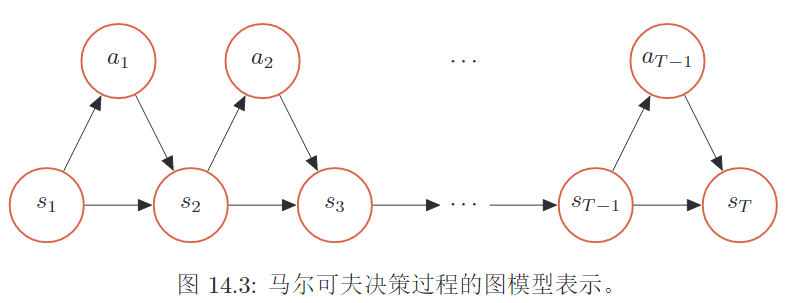
轨迹的总回报:策略的期望回报:强化学习的目标:学一个策略1. 某一时刻的奖励
环境给智能体的奖励2. 一条轨迹的回报/总回报
所有时刻的累积奖励3. 一条轨迹的折扣回报
折扣率 一个策略
策略的期望回报:该策略下所有轨迹总回报的期望值。
智能体能获得更多回报。本质是策略搜索,优化问题,无需值函数可以直接优化策略
连续状态和动作,直接学出随机性策略。方法:基于梯度的优化,无梯度的优化
初始状态为 执行策略初始状态为 进行动作执行策略评估策略对好的动作a(增大其概率 状态值函数初始状态执行策略 期望回报。
核心思想 📕
可通过下个状态的值函数进行递推计算。 迭代计算V函数 ⛳
初始状态为 执行策略 期望回报当前时刻奖励+下一时刻V值,求期望即可V函数的贝尔曼方程⭐
执行动作 状态变更 求期望即可Q函数(状态-动作值函数) 🍎
初始状态为 进行动作执行策略Q函数的贝尔曼方程 ‼️
下一时刻的V(s)函数 用 Q(s,a)函数期望来计算 👏1.
初始状态为 执行策略选择所有可能a的均值直接选择回报最大的a2.
初始状态为 进行动作执行策略选择所有可能s的均值直接选择最大回报的a3. V和Q的关系🔥
V函数 是所有动作a的Q函数的期望通过Q函数计算V函数通过V函数计算Q函数作用
值函数:对策略示例
在状态s,有一个动作a使得
说明
高于s状态所有动作的平均值 👏需要
有些任务的状态和动作非常多,并且是连续的。普通方法很难去计算。
可以使用更复杂的函数(深度神经网络)使智能体来感知更复杂的环境状态,建立更复杂的策略。
深度强化学习
强化学习 -- 定义问题和优化目标深度学习 -- 解决状态表示、策略表示等问题