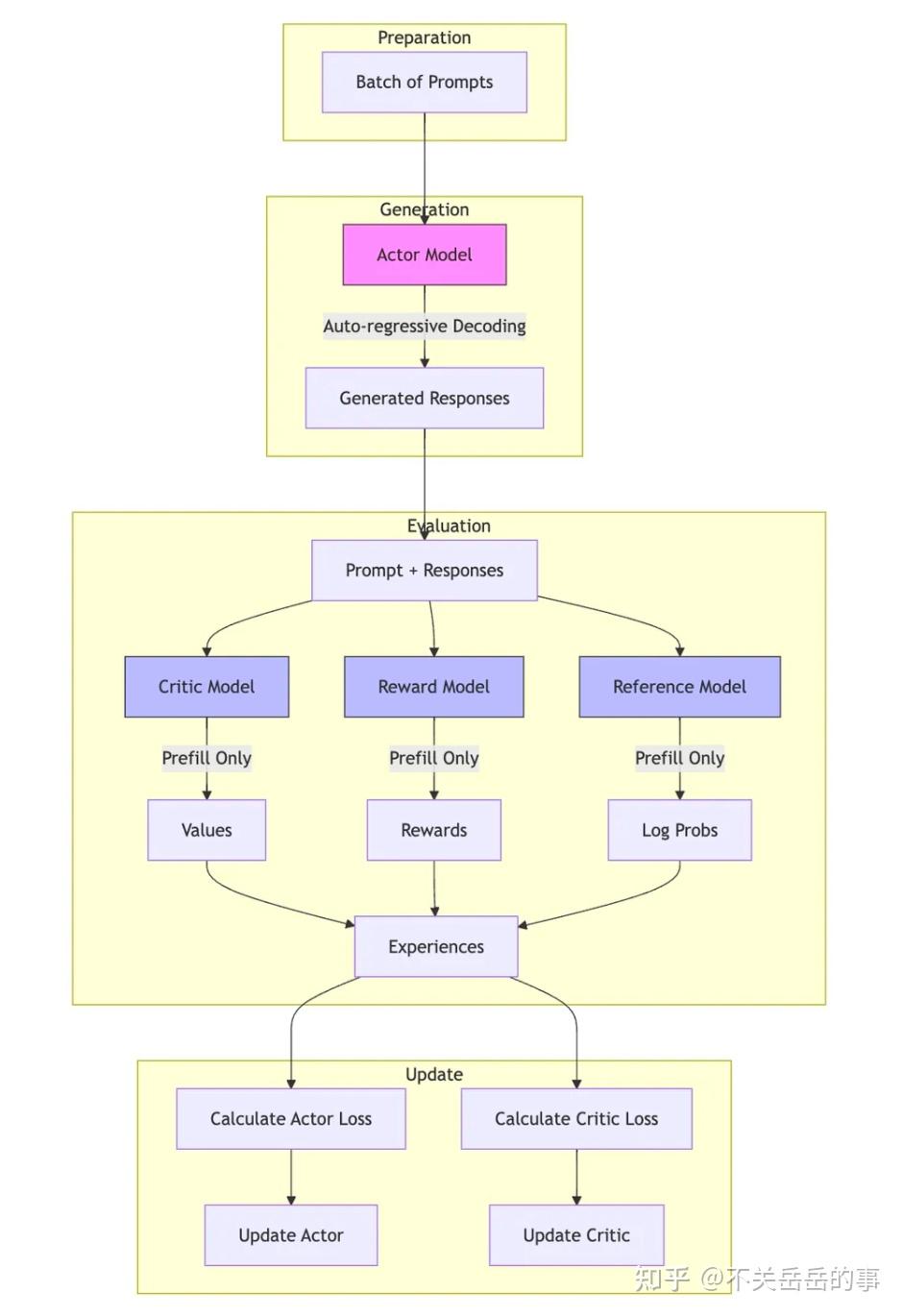
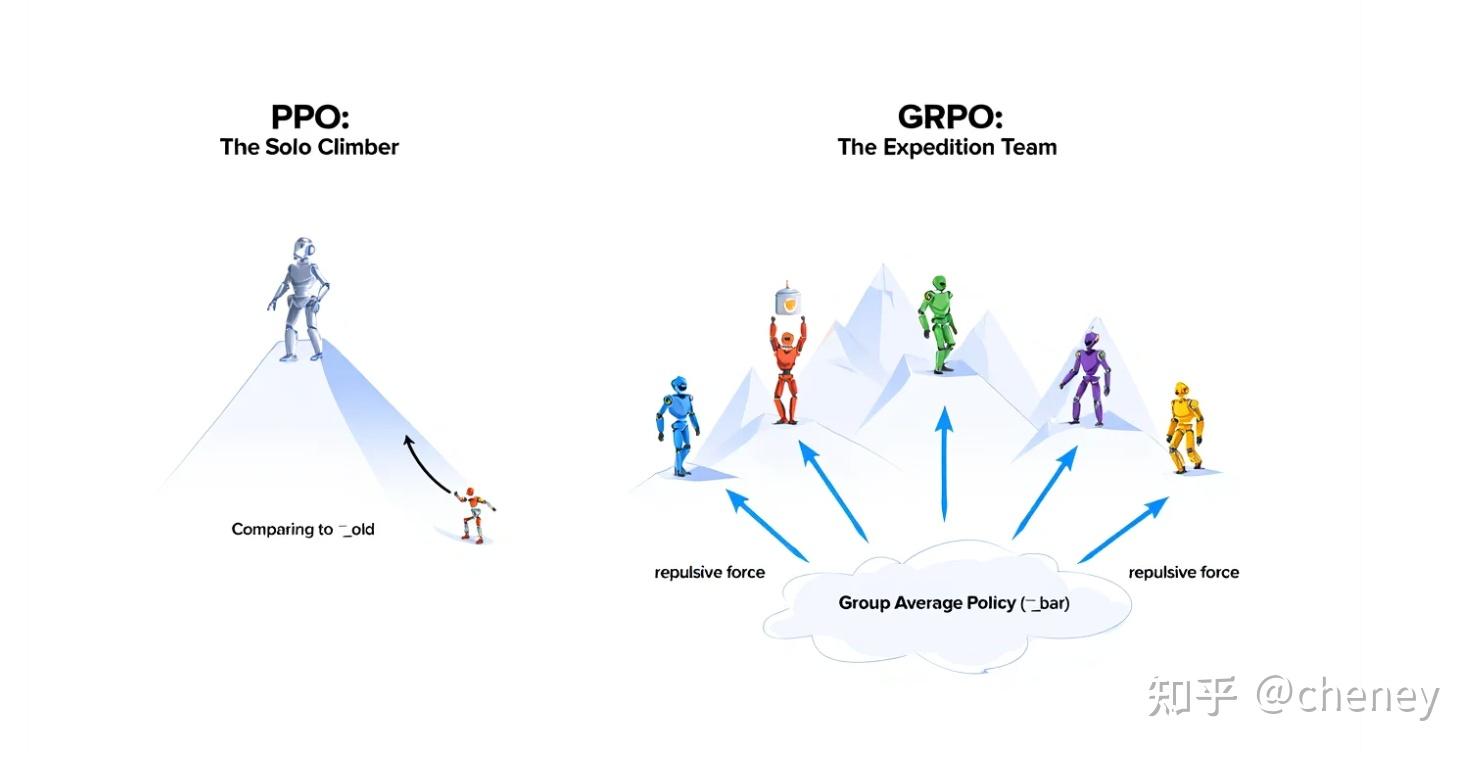
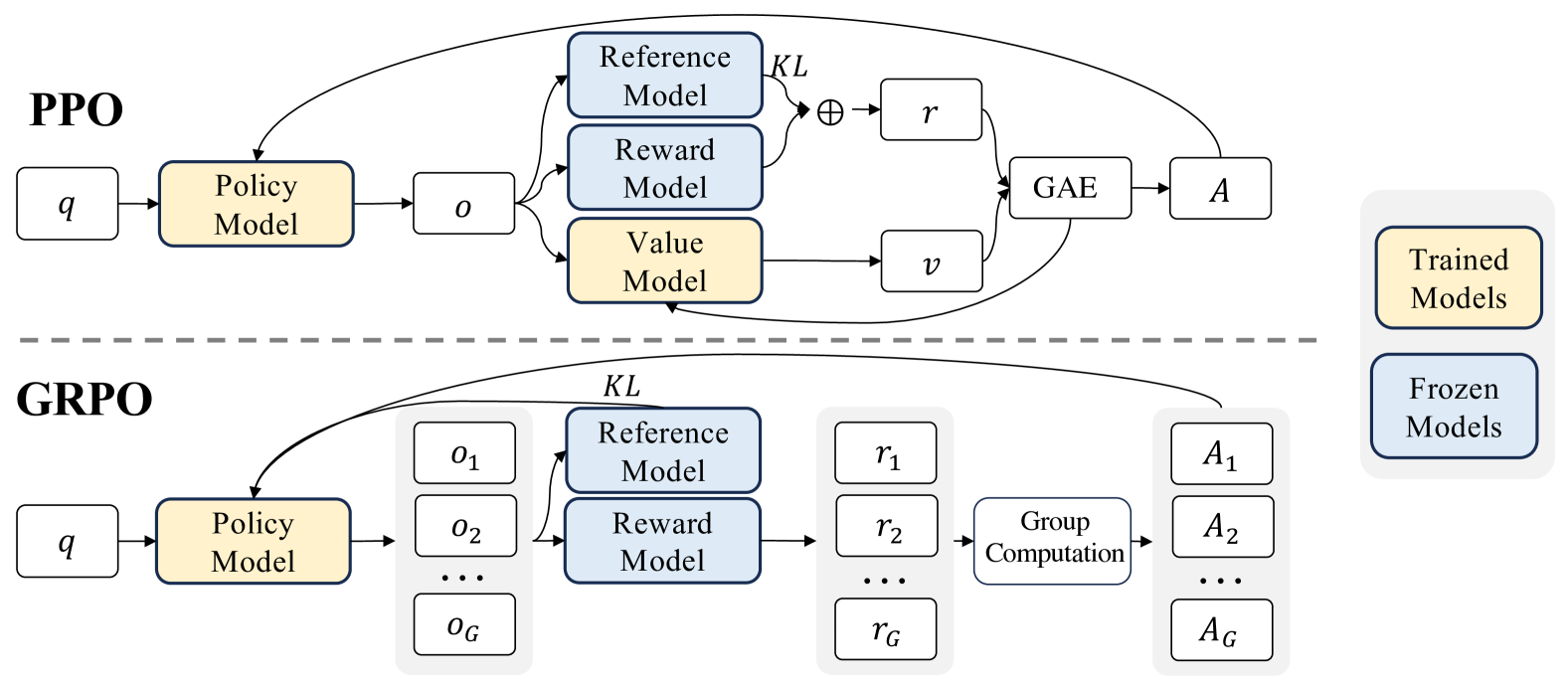
典型策略提升方法:TRPO+PPO+DPO+GRPO
📅 发表于 2025/09/02
🔄 更新于 2025/09/02
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
rl-theory
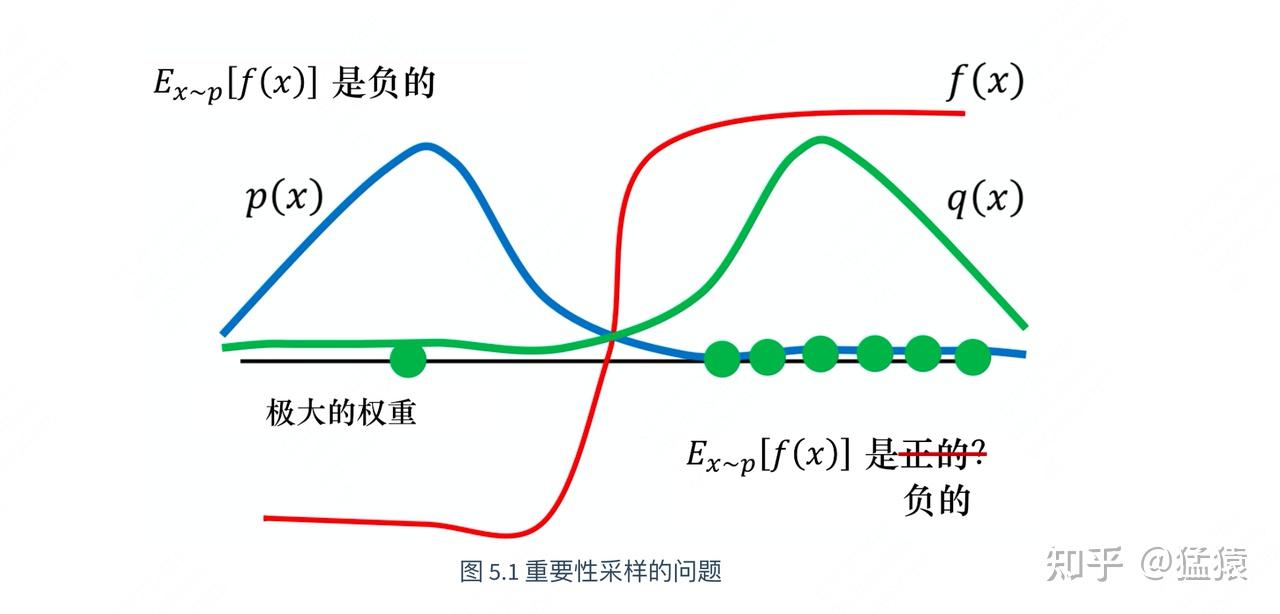
#重要性采样
#重要性采样策略梯度
#KL约束
#信任区域
#GAE
#n步优势估计
#TRPO
#PPO
#优势策略梯度
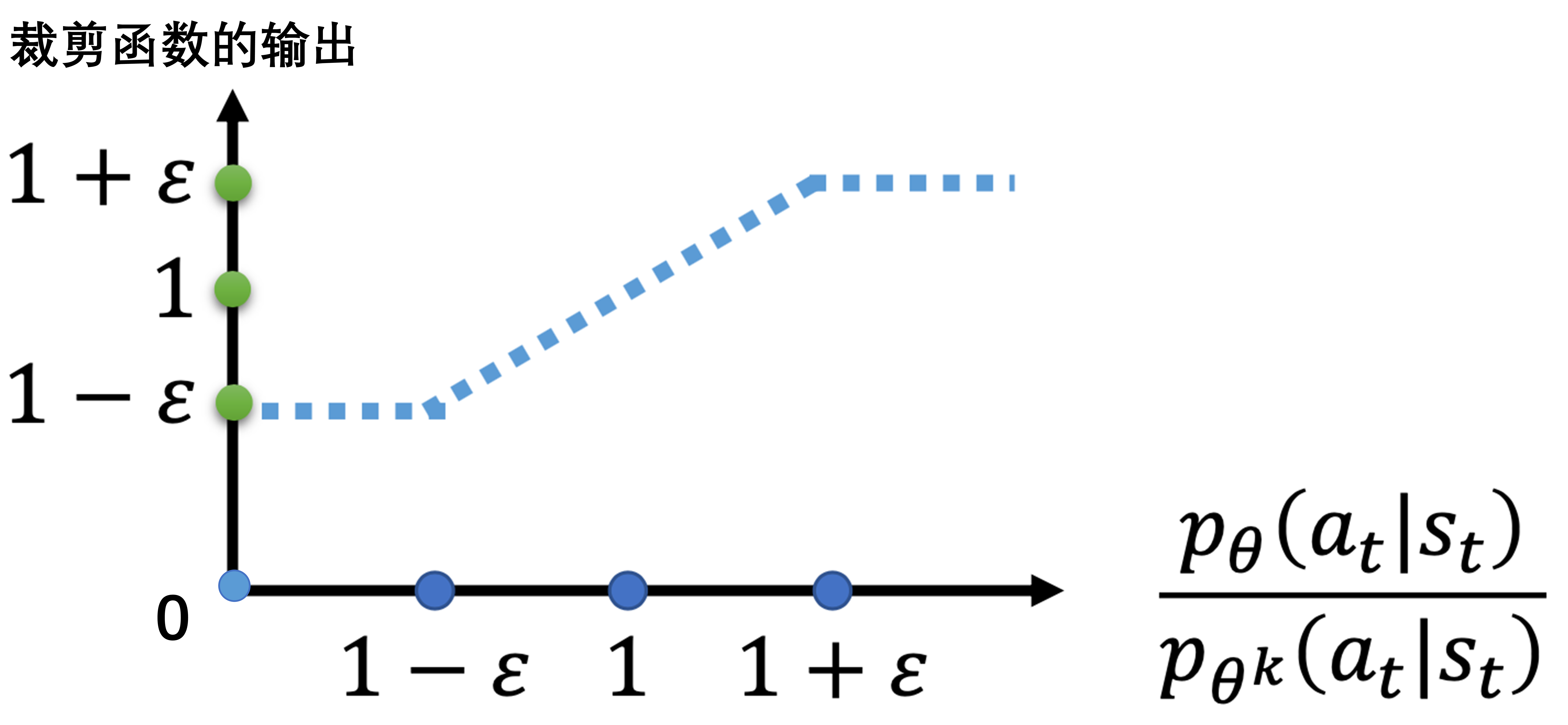
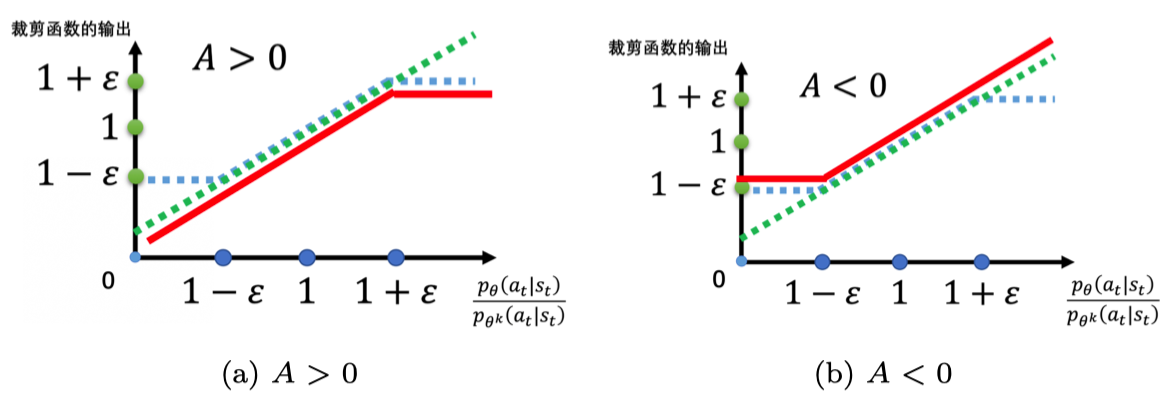
#PPO-Clip
#PPO-Penalty
#Reward Model
#Pairwise loss
#KL负奖励
#Critic学习目标
#Critic Loss
#TD Error
#Critic Value Clip
#踩坑经验
#DPO
#标准RLHF目标
#DPO显示最优解
#DPO Loss
#DPO缺点
#GRPO
#相对组优势