强化学习基本概念
📅 发表于 2025/08/19
🔄 更新于 2025/08/19
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
rl
#试错学习
#智能体
#环境
#动作空间
#策略
#随机性策略
#确定性策略
#模型
#状态转移
#奖励
#回报
#价值
#序列决策
#规划
#学习
#Value-based RL
#Policy-based RL
#Model-based RL
#Model-free RL
#探索
#利用
监督学习
独立同分布上限为人类 😔强化学习
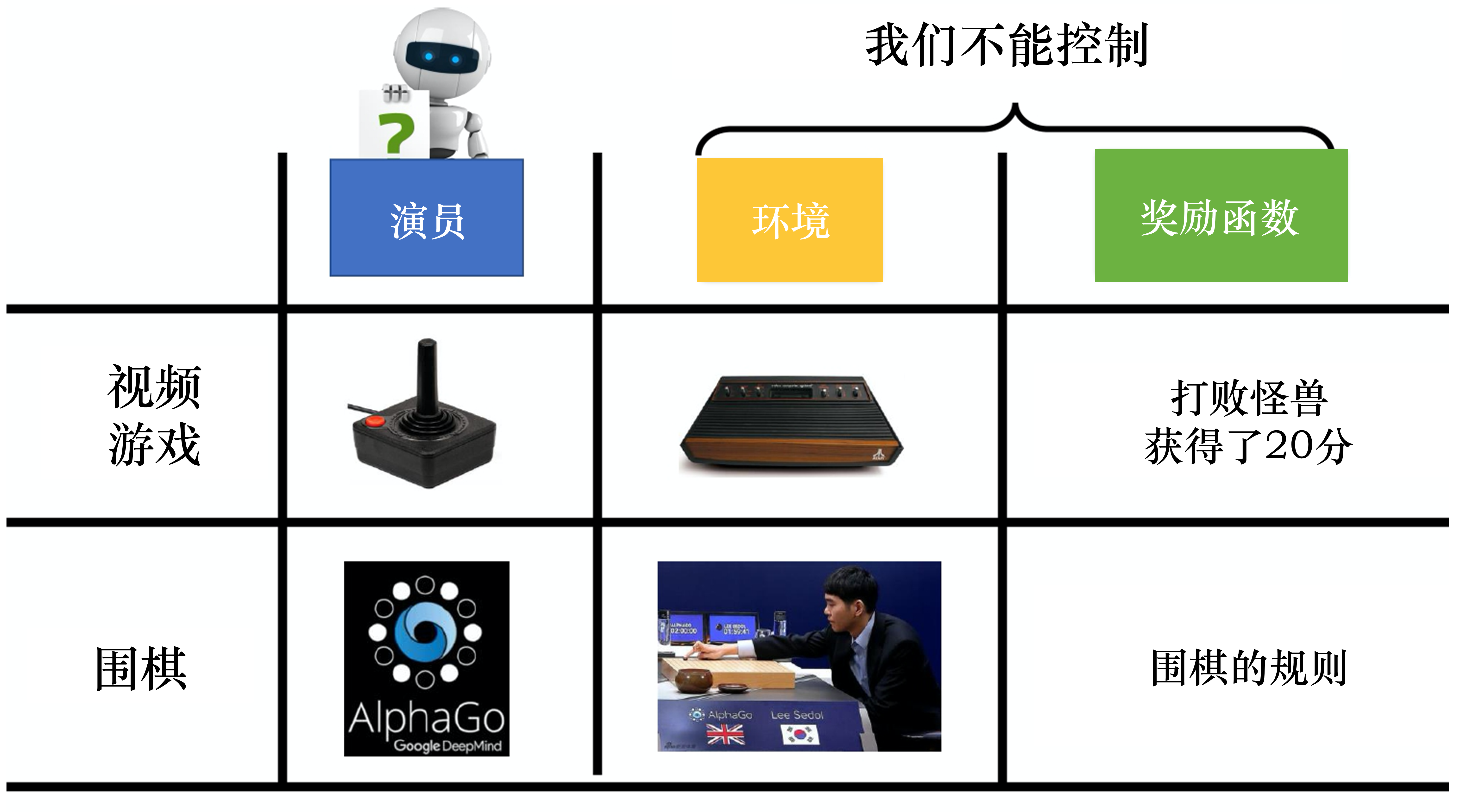
序列数据,样本前后有关联哪些动作能带来更多奖励上限超人类‼️奖励好的样本、惩罚差的样本当前模型在线产出的样本训练自身。 特点
影响它随后得到的数据如何让智能体动作稳定提升研究问题
智能体 如何在复杂、不确定的环境中,通过一次次决策,来最大化它能获得的回报。关键定义
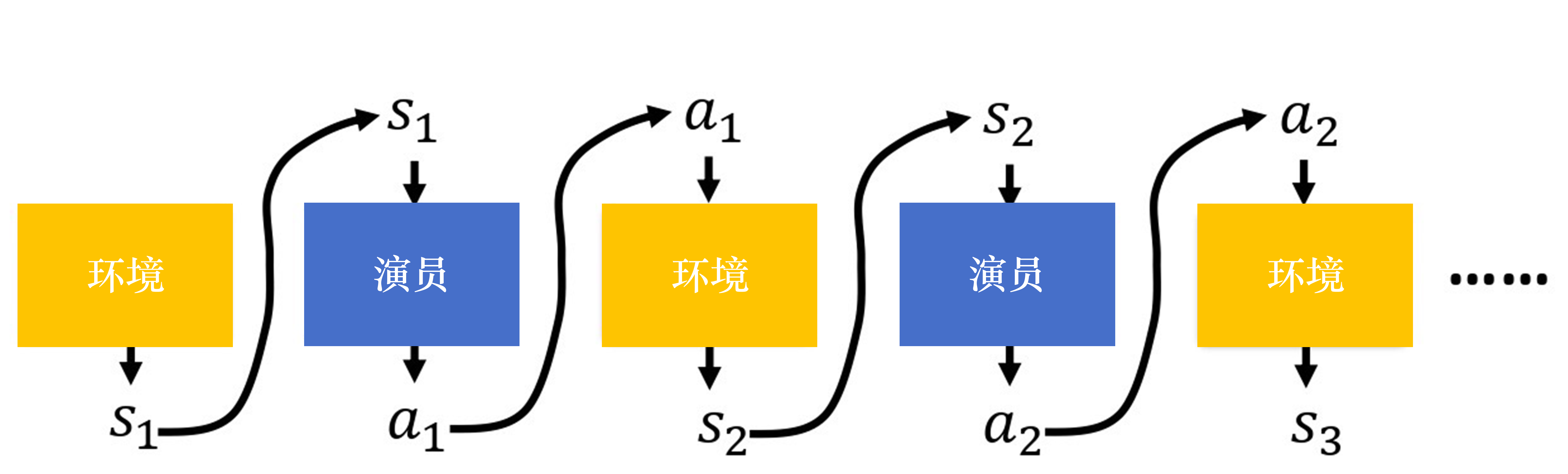
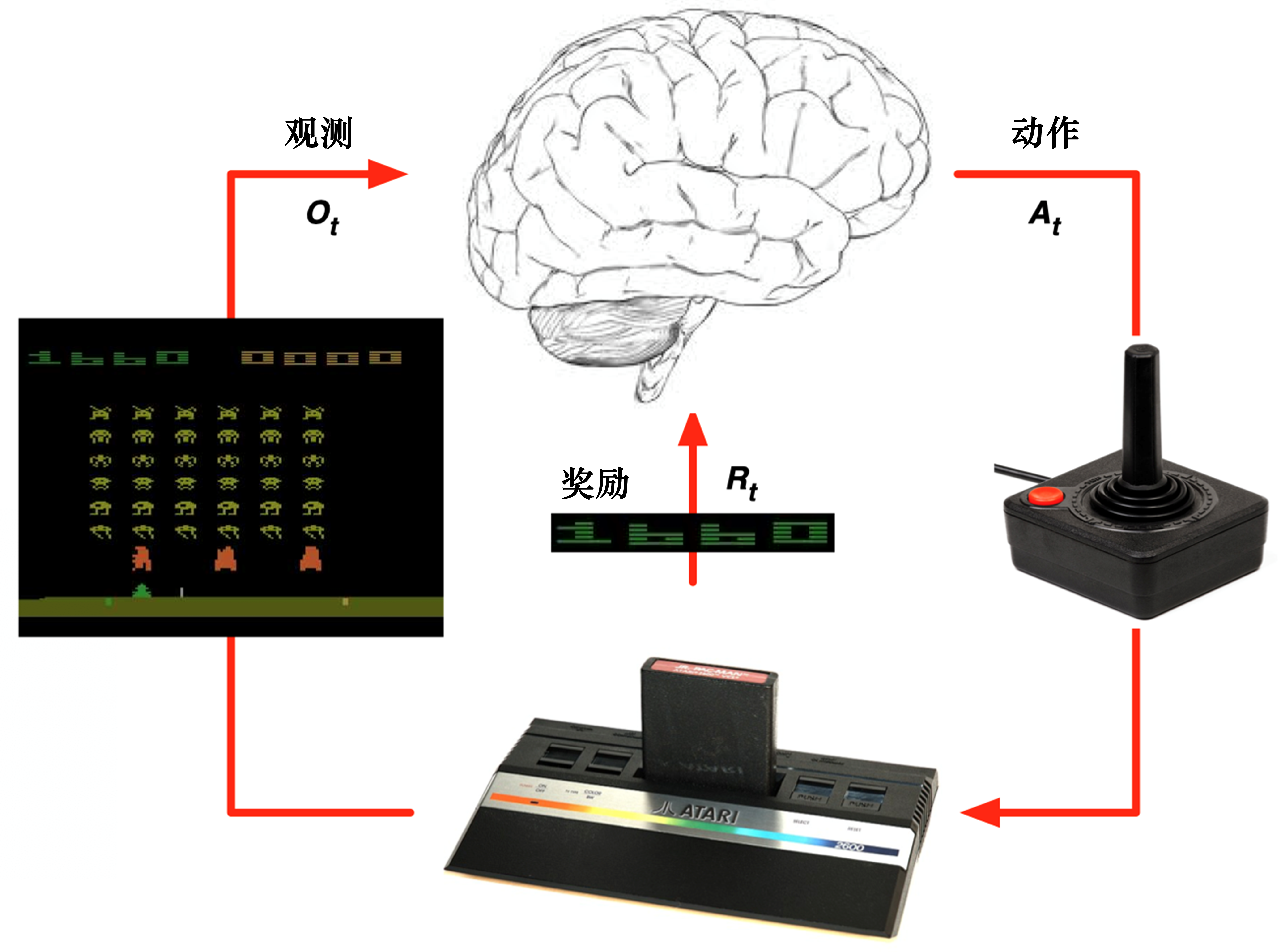
与环境交互,利用环境状态,采取动作输出下一时刻状态 和反馈动作奖励。试错学习⭐
尝试和试错中学习到正确的策略一系列动作或行为过程中的错误,包括自身行为不当、环境不稳定等。积极或消极),都对下一次尝试产生影响。 奖励;差的结果:惩罚不断尝试和试错,逐渐积累经验,了解哪些动作会产生更有利结果,在下一次尝试中做出更明智选择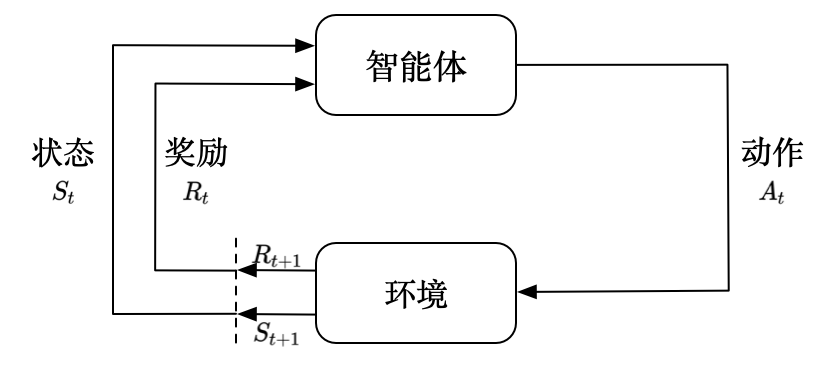
我们唯一需要做的就是调整演员的策略。
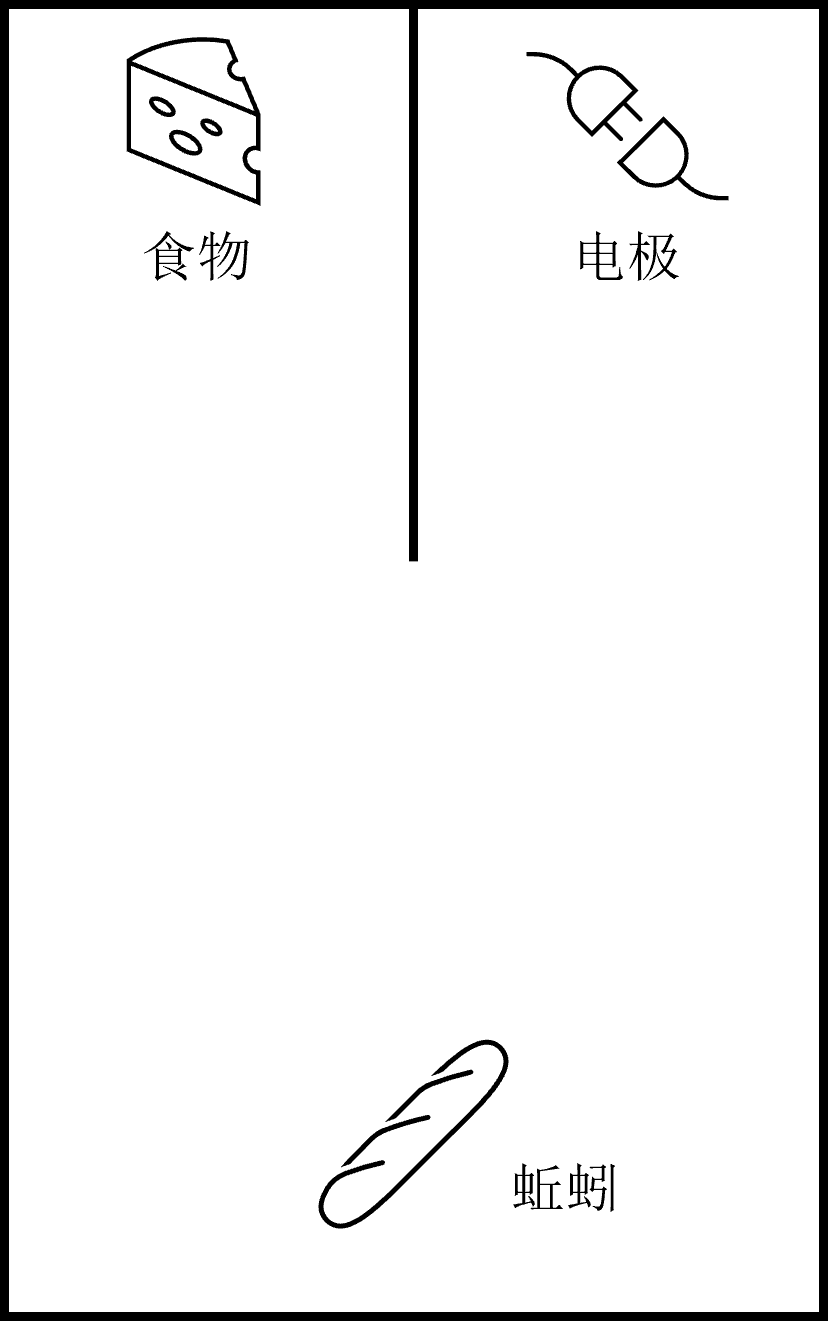
蚯蚓通过一次次实验,学会朝着有食物的方向爬行,而非电极方向。
智能体
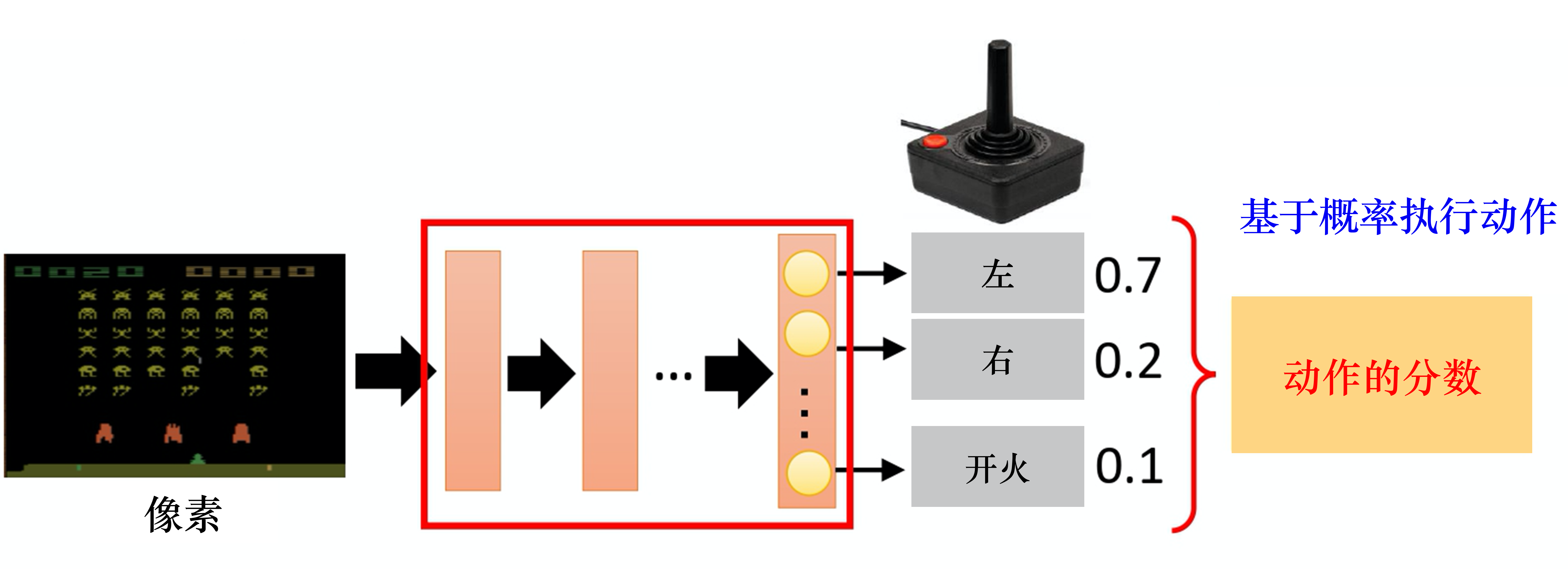
离散、连续动作空间选下一步动作动作概率分布,根据概率选动作,0.7概率往左,0.3概率往右直接选最有可能的动作,输出不变: 随机性策略👍,更好探索环境、动作具有多样性环境
奖励状态转移概率、奖励函数。奖励、回报、价值函数
演员的策略
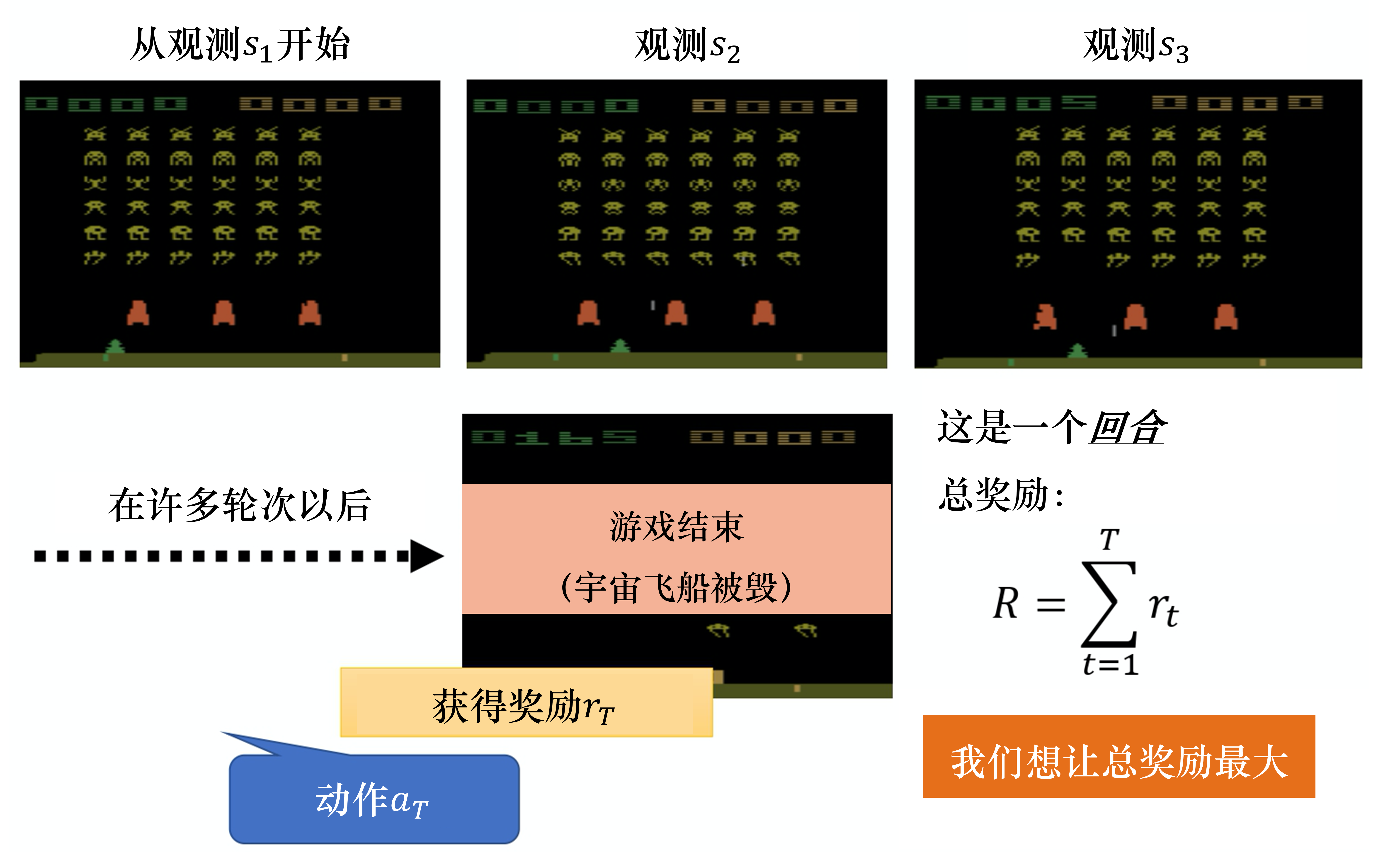
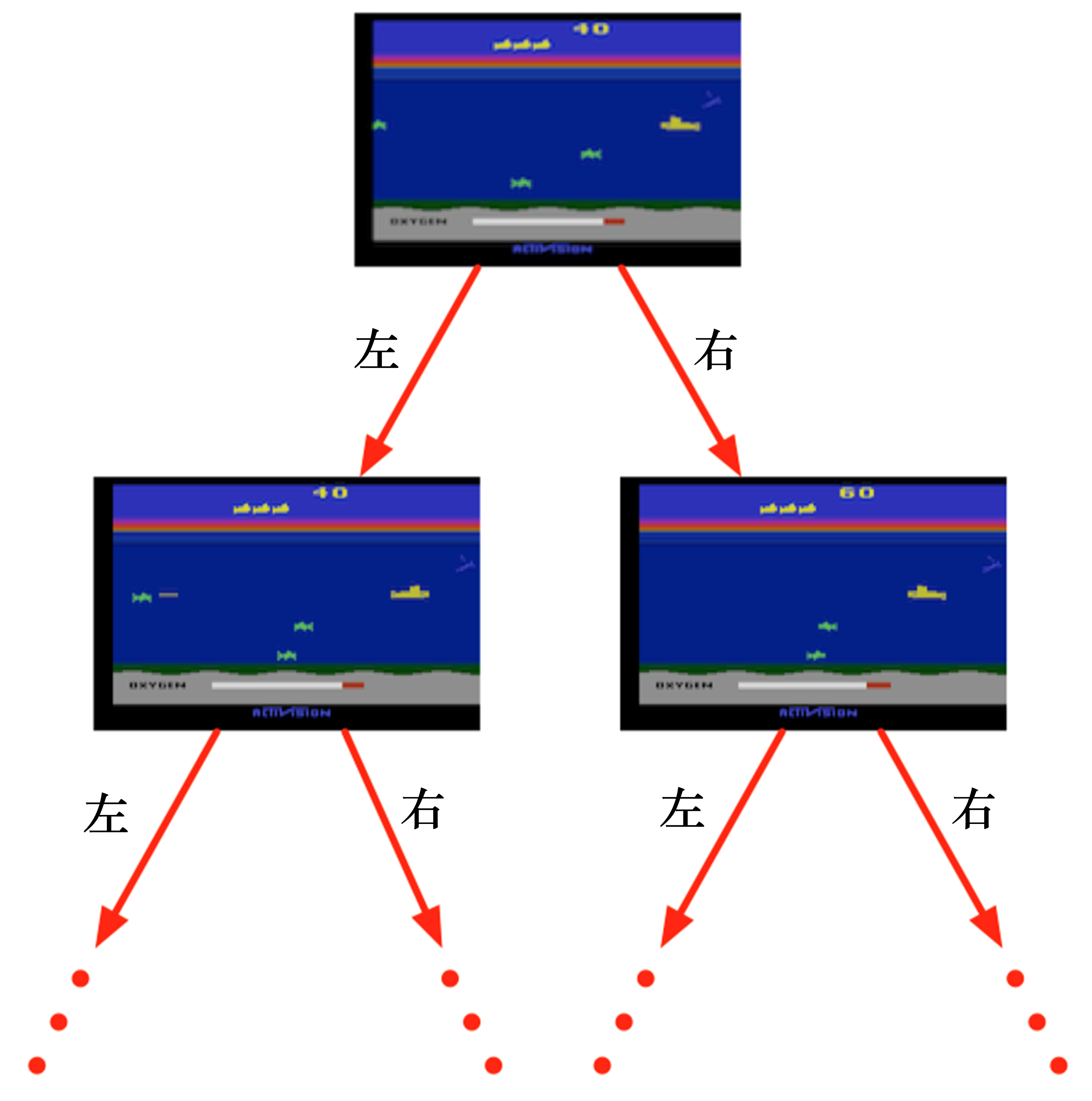
序列决策
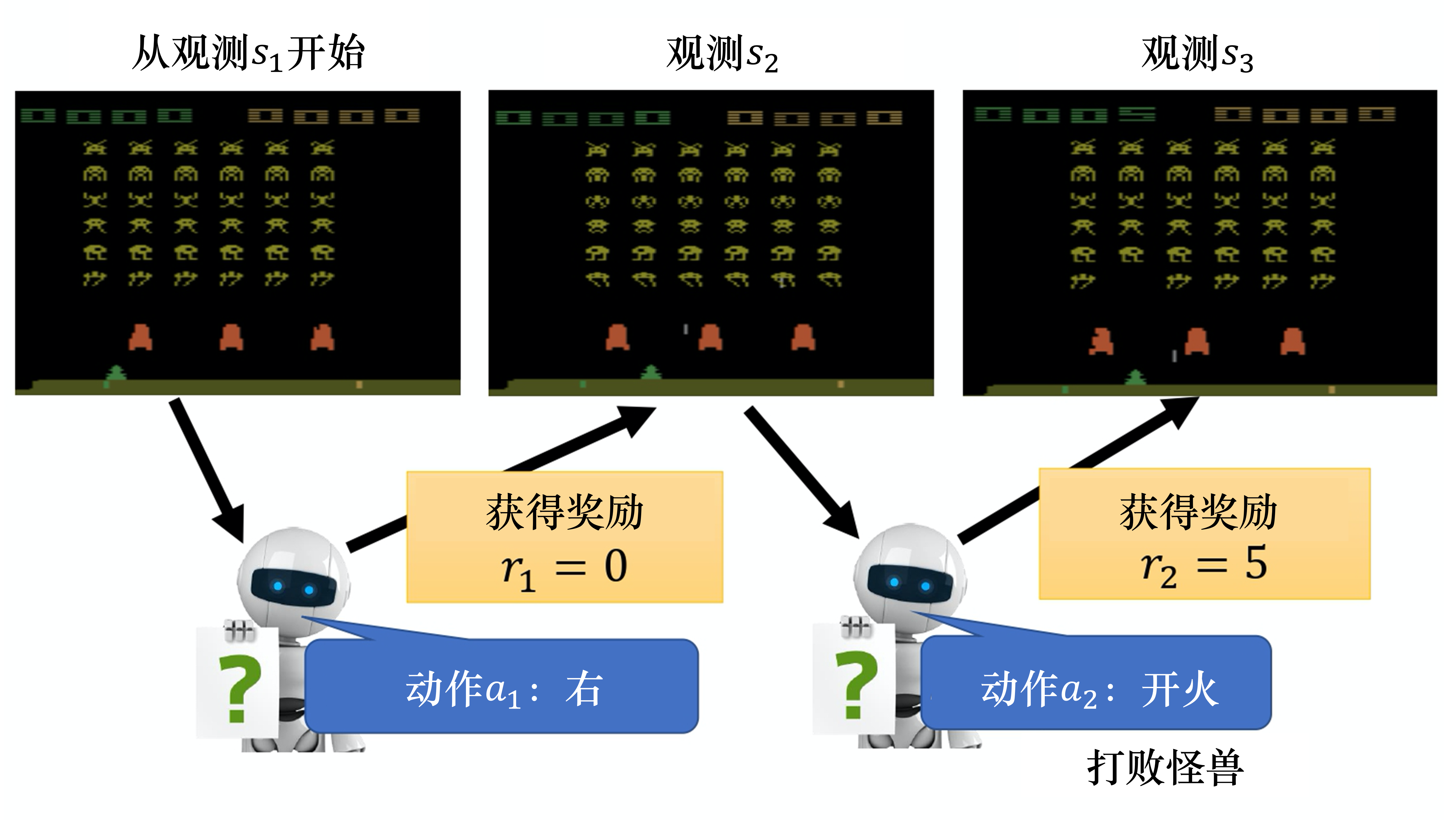
回报的例子
演员和环境
状态、观测、历史
序列决策
完全可观测,智能体能看到环境所有状态,部分可观测,智能体只能看到部分状态学习(learning)
规划(planning)
有模型RL,已知状态转移和奖励函数,只需通过动态规划寻找最优解即可。常用RL思路
学习:
规划:
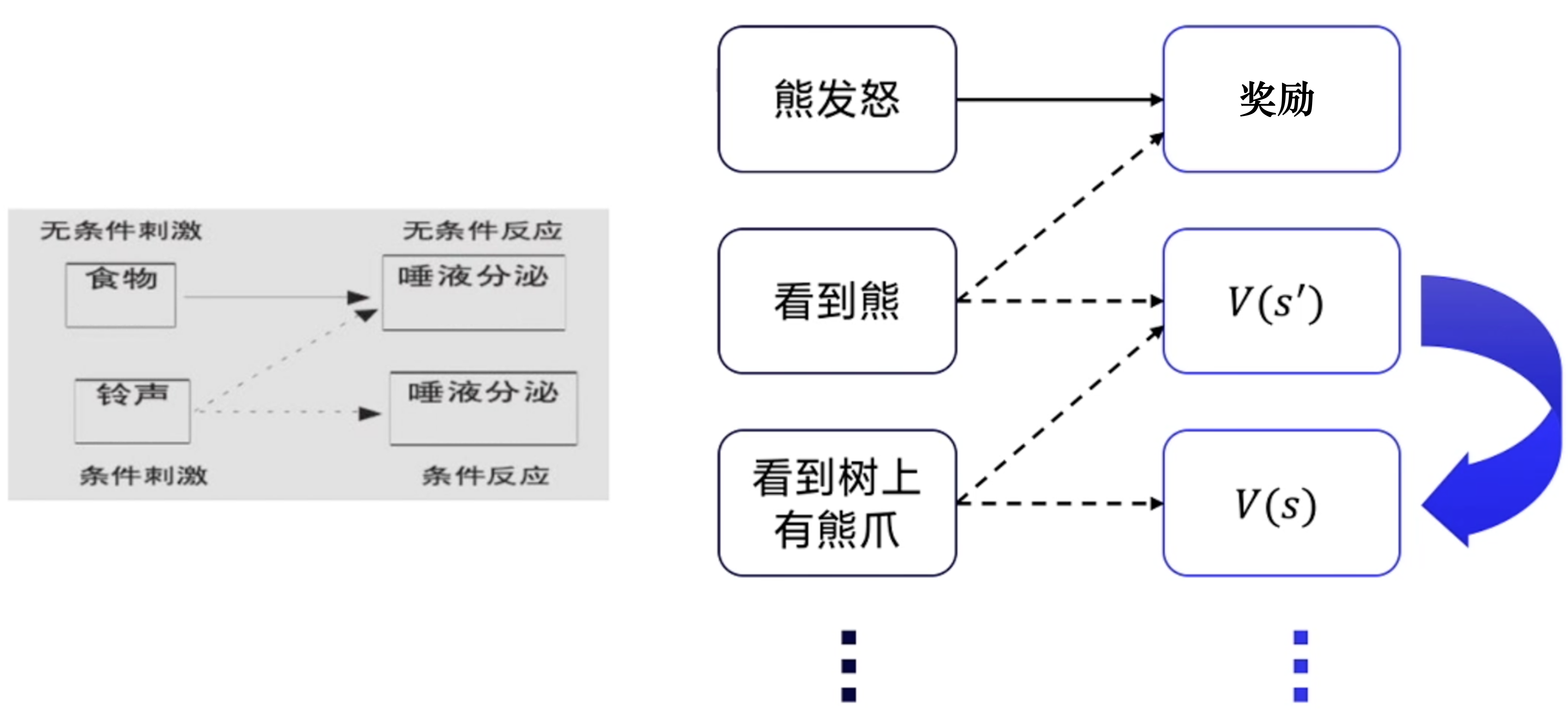
强化
下一个状态的价值,可以不断强化影响(更新) 上一个状态的价值自举
动态规划
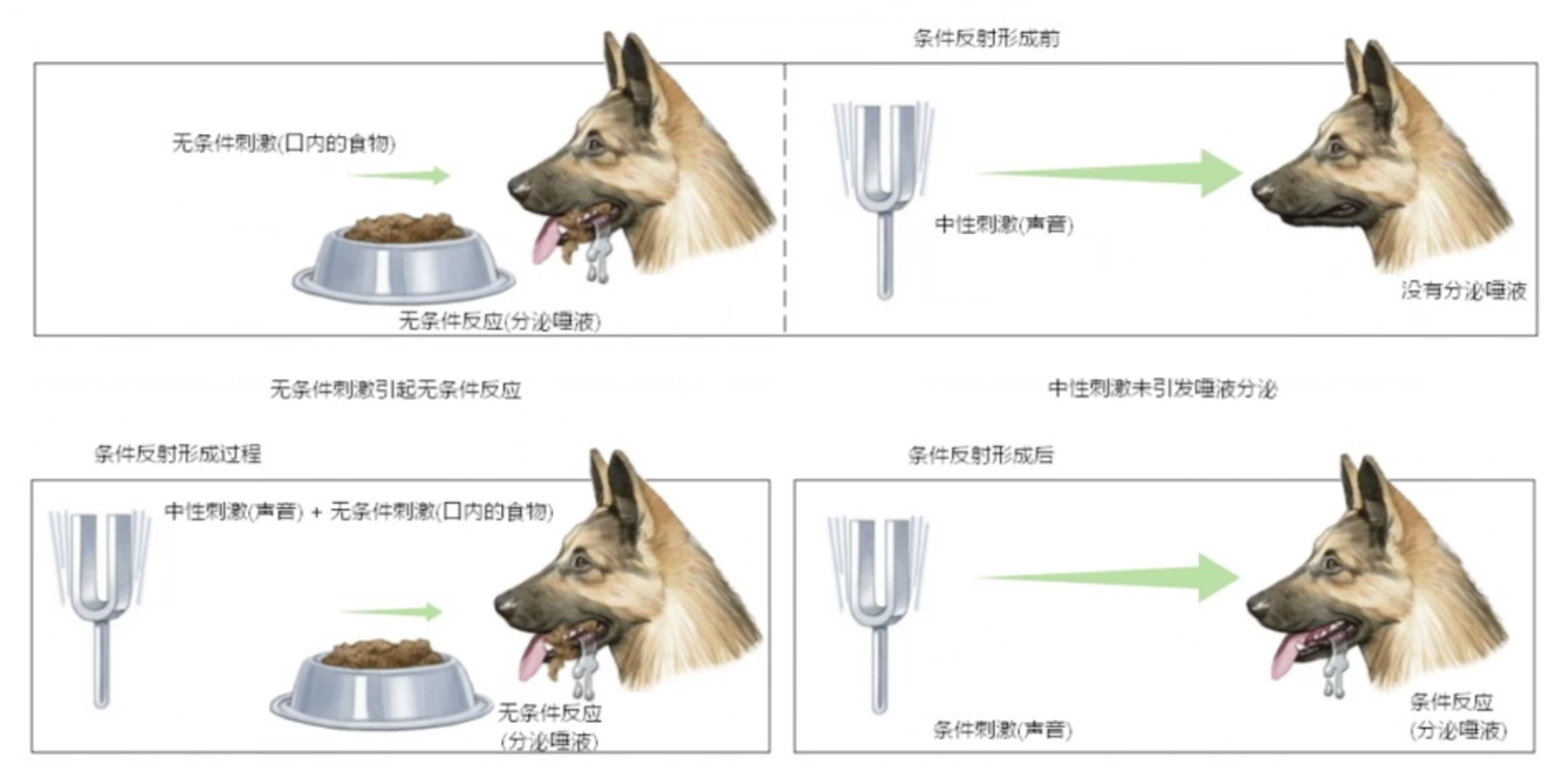
巴普洛夫条件反射实验
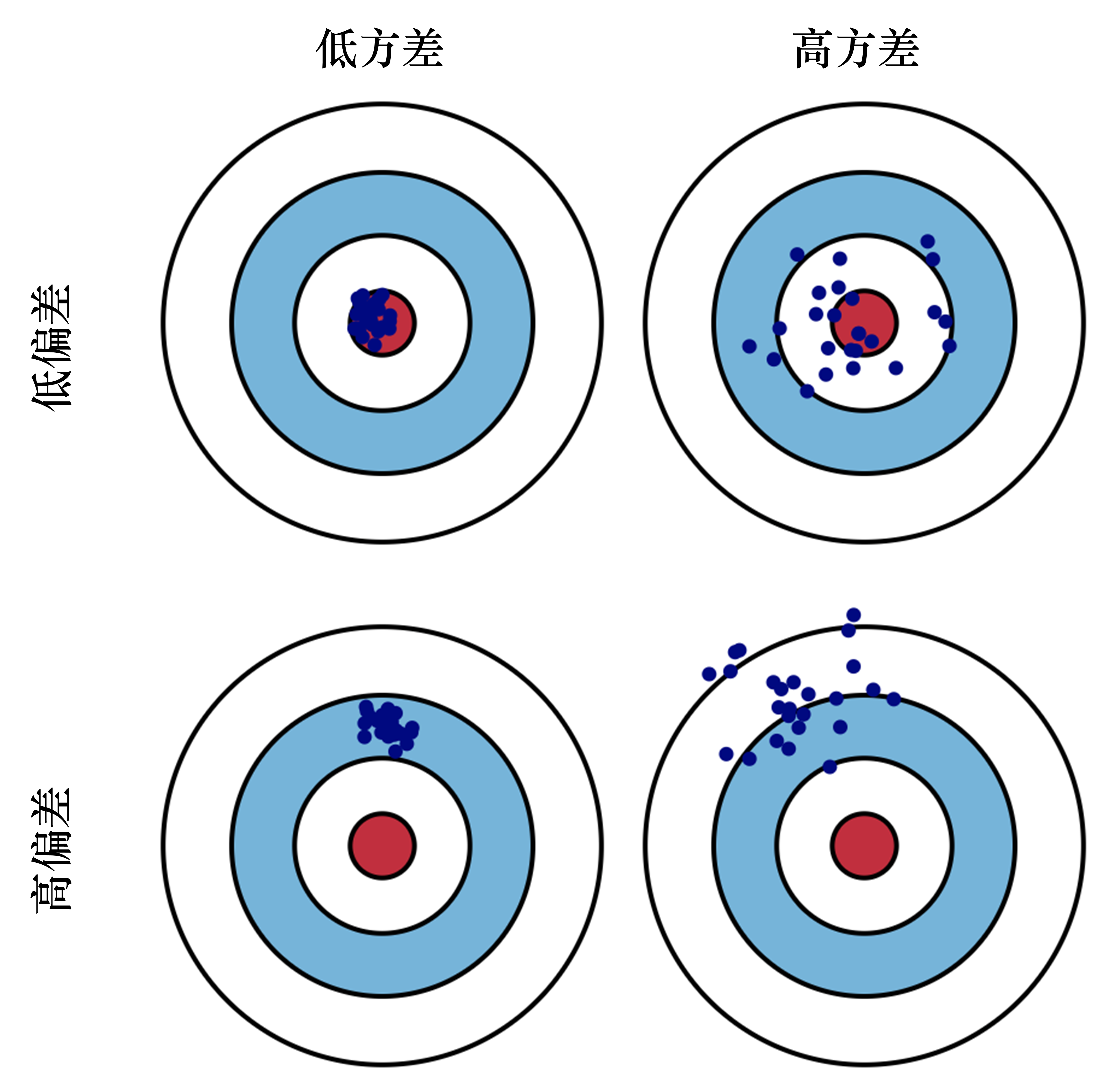
问题1:方差和偏差 / 如何提高对值函数估计
问题2:提高探索性以及平衡探索和利用的关系
偏差
方差
探索
探索环境,通过尝试不同动作来得到最佳策略。
通过试错探索,去理解采取的动作到底好不好
一无所有,也可能小概率超过所有已知动作。仅探索
K-臂赌博机示例)环境已知无需探索 (状态转移概率、奖励函数)
环境已知且可计算时,可通过planning直接求解最佳策略,无需RL,无需探索。在RL中环境大都具有未知性
利用
探索-利用 平衡/窘境
面临一个未知或部分已知的环境时
若不探索,就无从获得有价值的新信息
若过度探索,则会浪费一些机会成本,不能稳定地得到高回报
仅探索或仅利用,是矛盾的,加强一方会削弱另一方,都无法使最终累计奖励最大化
想要累计奖励最大,需要在探索和利用之间做好折中
一、Value-Based RL
并重复执行z步。 避免浅尝辄止、反复左右横跳。对尚未充分估计的Q值乐观一些,以吸引智能体去尝试动作,从而收集信息,减少不确定性。
面对不确定性时的乐观主义。Optimism in the face of uncertainty
玩1台老虎机时,考虑这台机器过去的平均收益(利用),也要考虑它有多大的不确定性(探索)。
不确定性本身吸引力就很高。为每台机器计算一个潜力得分/UCB,综合已知平均收益和不确定性带来的潜在收益。
UCB值 = 平均奖励 + 探索项,
如下公式:其中
二、Policy-Based RL
三、Model-Based RL
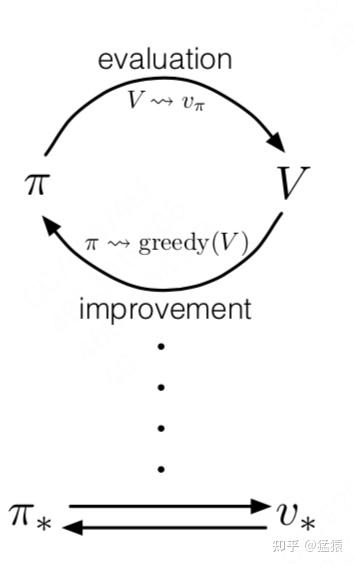
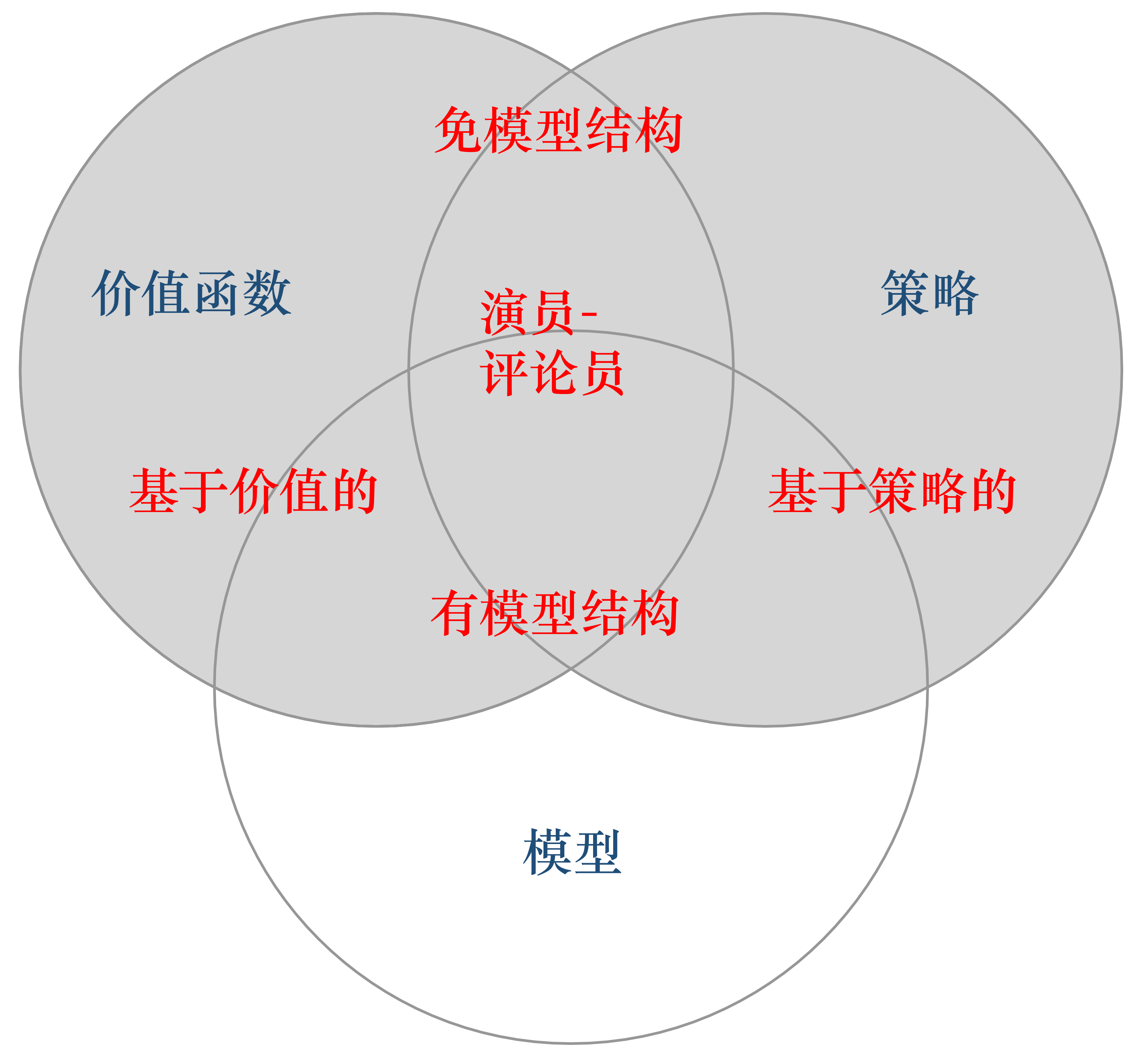
两个重要实体:策略 价值函数
从决策方式来看,RL可以划分为基于价值的方法和基于策略的方法。
Value-based RL
只有价值实体,显示学习价值函数,利用价值函数来指导策略做决策
衡量哪个状态/动作的价值最大。根据价值函数推算出来的。通过MC采样+时序差分来估计价值函数;选择价值最大的动作来更新策略。
类比:训练导航工具,直接告诉驾驶员最佳路径,指导其到达。
缺点
估计价值的方差很高典型算法:Q学习、SARSA、DeepQ网络等。
Policy-based RL
只有策略实体,直接对策略进行优化,在每个状态输出最佳动作,使其获得最大奖励。
如何优化?
策略和环境交互多次,采样足够多的轨迹数据,用这些数据对策略的价值做评估。轨迹的价值期望来确定策略迭代方向。没有学习价值函数
类比
训练驾驶员(策略),同时训练导航工具(价值函数);优点
驾驶员结合经验可直接纠正导航工具也可以及时纠正错误典型算法:Policy Gradient。
Actor-Critic (结合价值和策略)
策略价值函数。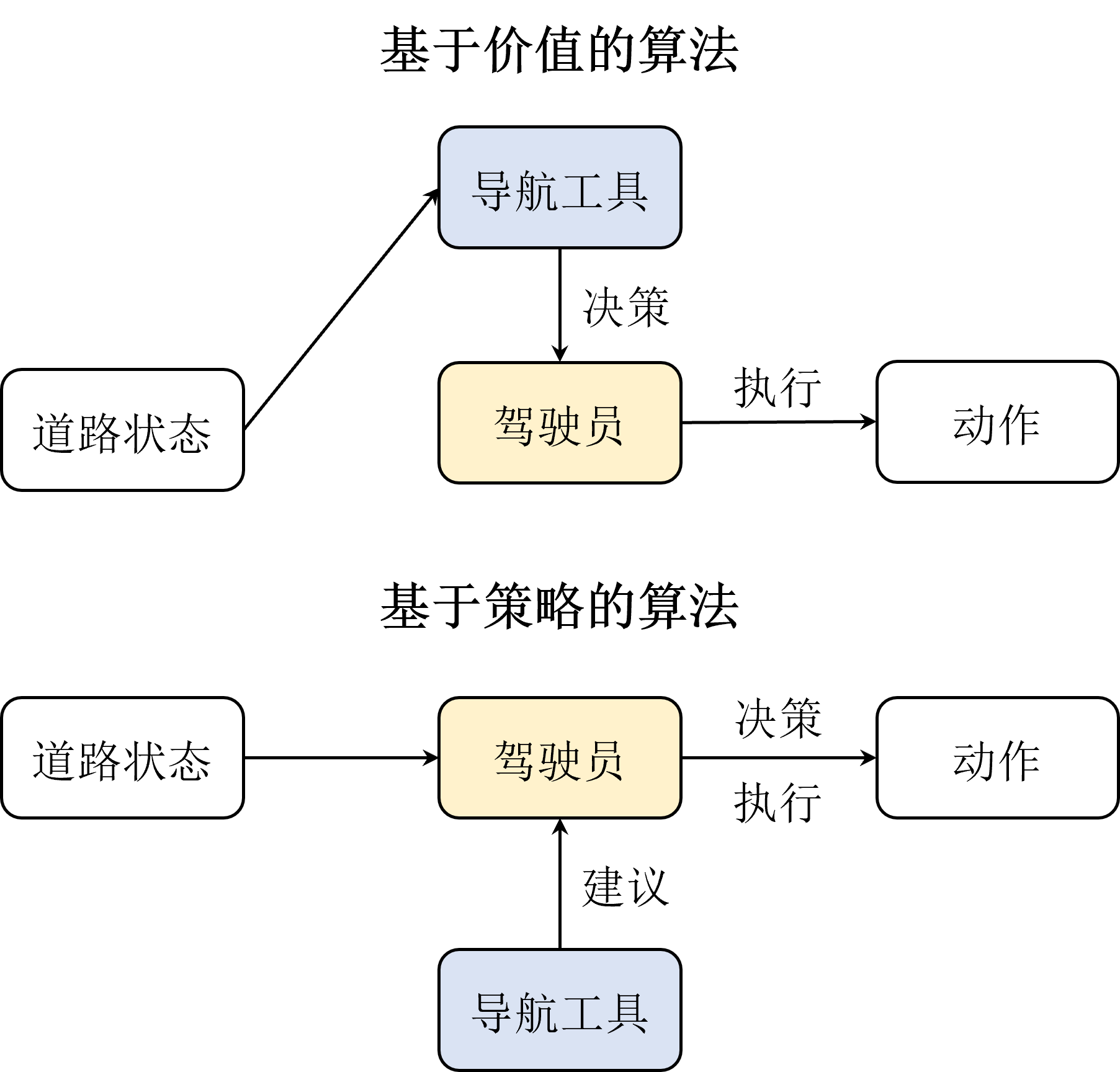
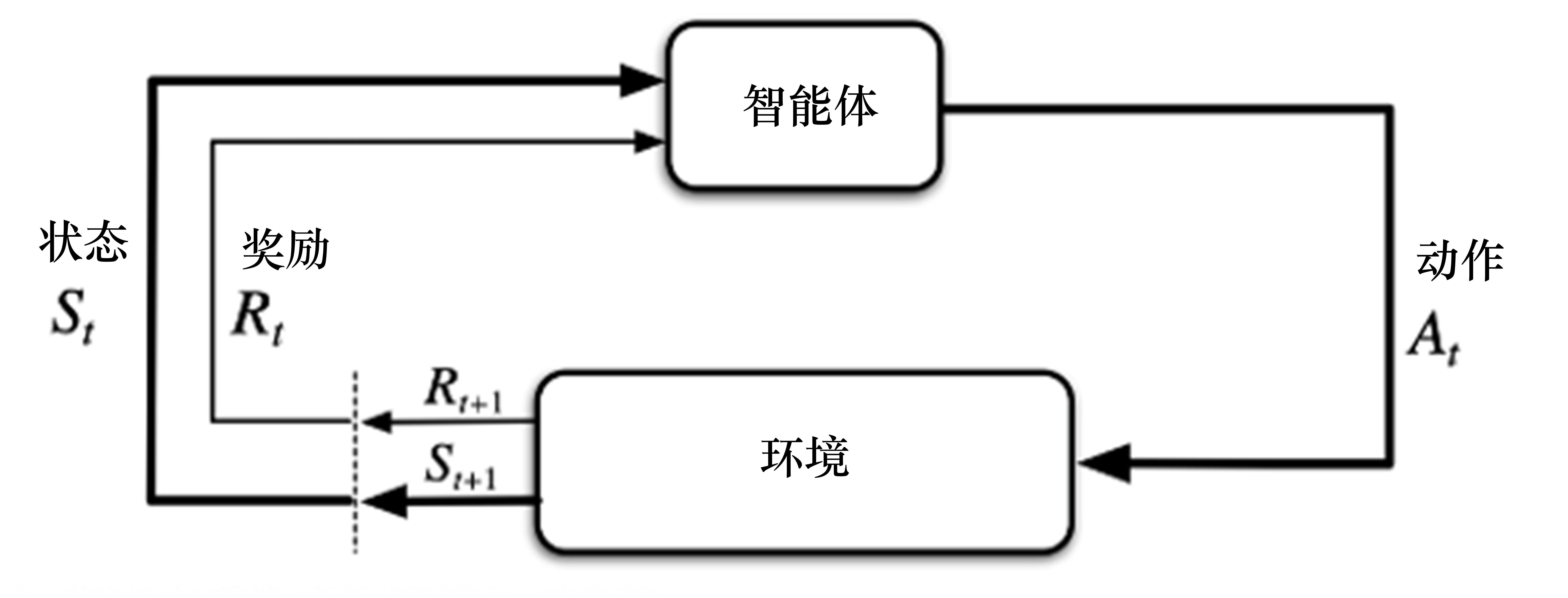
环境
状态转移概率 奖励函数定义特点
优点
一步一步采取策略等待真实反馈缺点
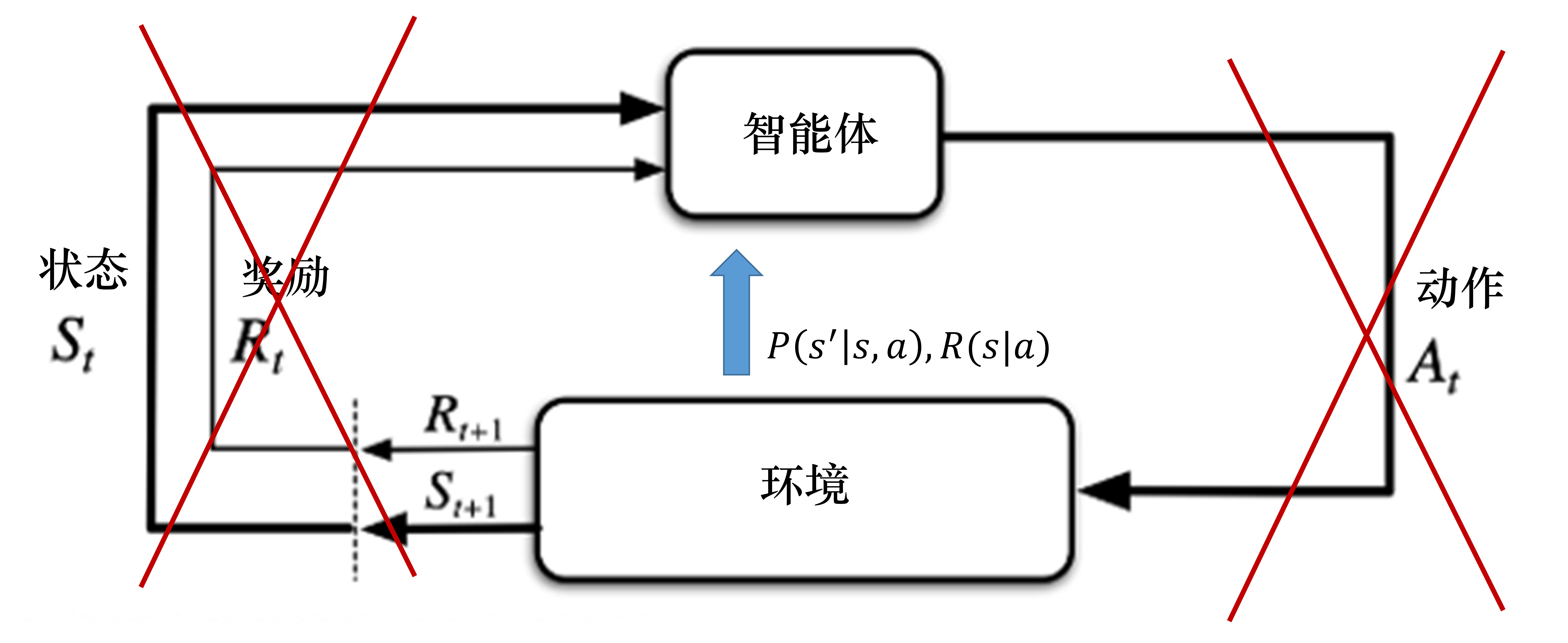
定义
不对环境建模,直接从真实环境交互中,来学习最优策略特点
数据驱动型方法,需大量采样来估计状态、动作、奖励函数,来优化策略
如《太空侵略者》需2亿帧游戏画面此能学到较好效果
优点
简单直观,不用学习复杂的环境模型,资料丰富缺点
适用场景
免模型RL
多智能体RL
模仿学习:奖励函数难以定义或策略很难学的情况下,通过模仿人类行为来学习一个较好策略。
典型:行为克隆,把状态-动作视为一个训练样本,通过SFT来学习一个策略。
存在分布漂移(泛化性)的问题。
逆强化学习:观察人类行为,来学习奖励函数,通过RL来学习策略。
背景
思路1:离线强化学习
思路2:世界模型
世界模型,并部署到在线环境进行决策。世界模型:预测下一个状态控制器:根据当前状态来决策动作背景
思路1:联合训练
奖励进行加权求和,来学习一个策略。思路2:分层强化学习
当前任务当前任务的动作