Actor-Critic 算法
📅 发表于 2025/08/31
🔄 更新于 2025/08/31
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
rl-theory
#Actor
#Critic
#Q Actor-Critic
#A2C
#A3C
#Advantage
#Actor loss
#Critic Loss
#GAE
#λ-return
#单步TD
#MC估计
整体流程
做出动作打分 调整策略,更新参数争取下次做的更好调整打分策略,更新参数让评的更准关键点
最大化未来总收益,评委根据观众评的更准。演员只迎合评委。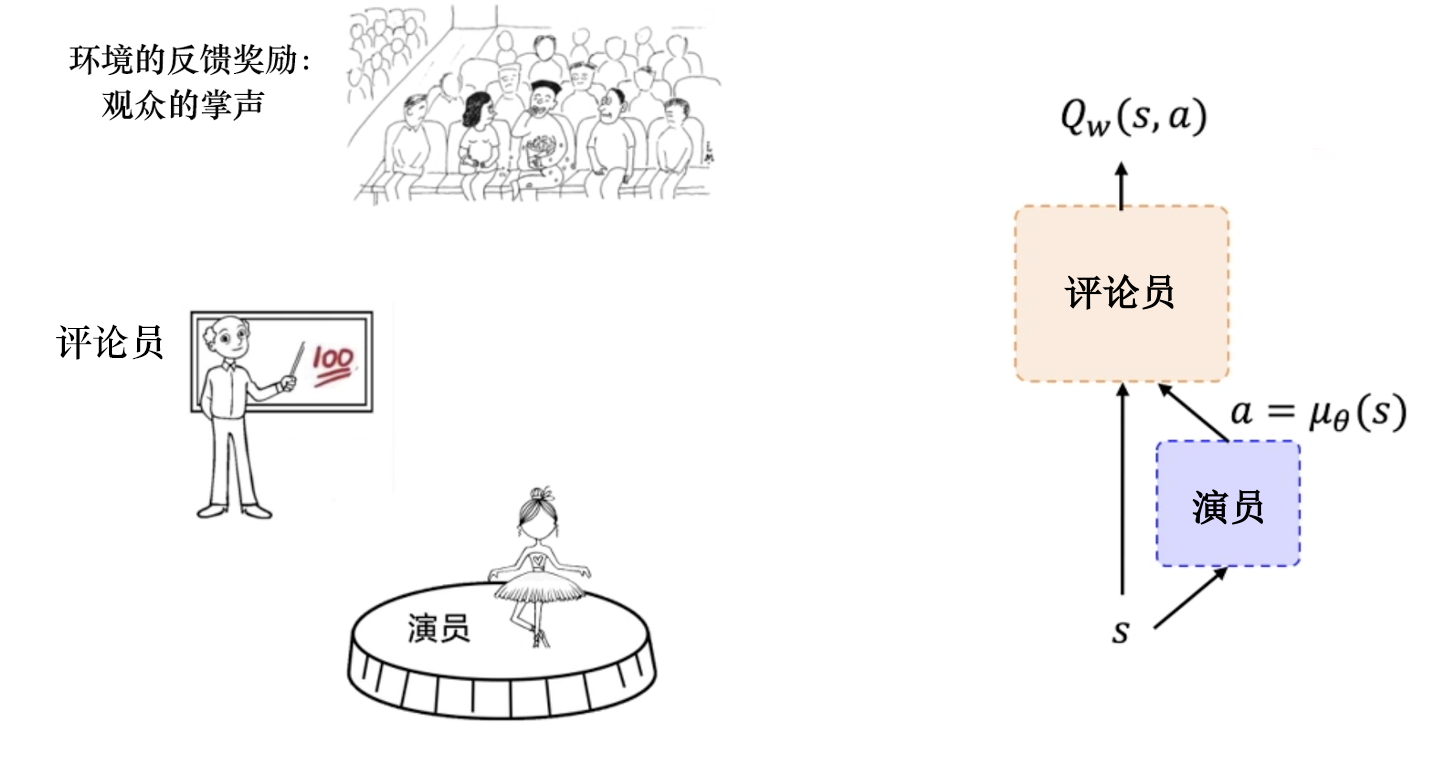
背景
轨迹随机性):影响收敛速度,且不适合在线学习MC方法。TD改进版本核心思想
演员&评论员
学习好的策略,尽可能获得高回报。准确评估当前策略的好坏相互博弈思想优点
高方差问题策略梯度和采样策略的价值估计,带来了更稳定的估计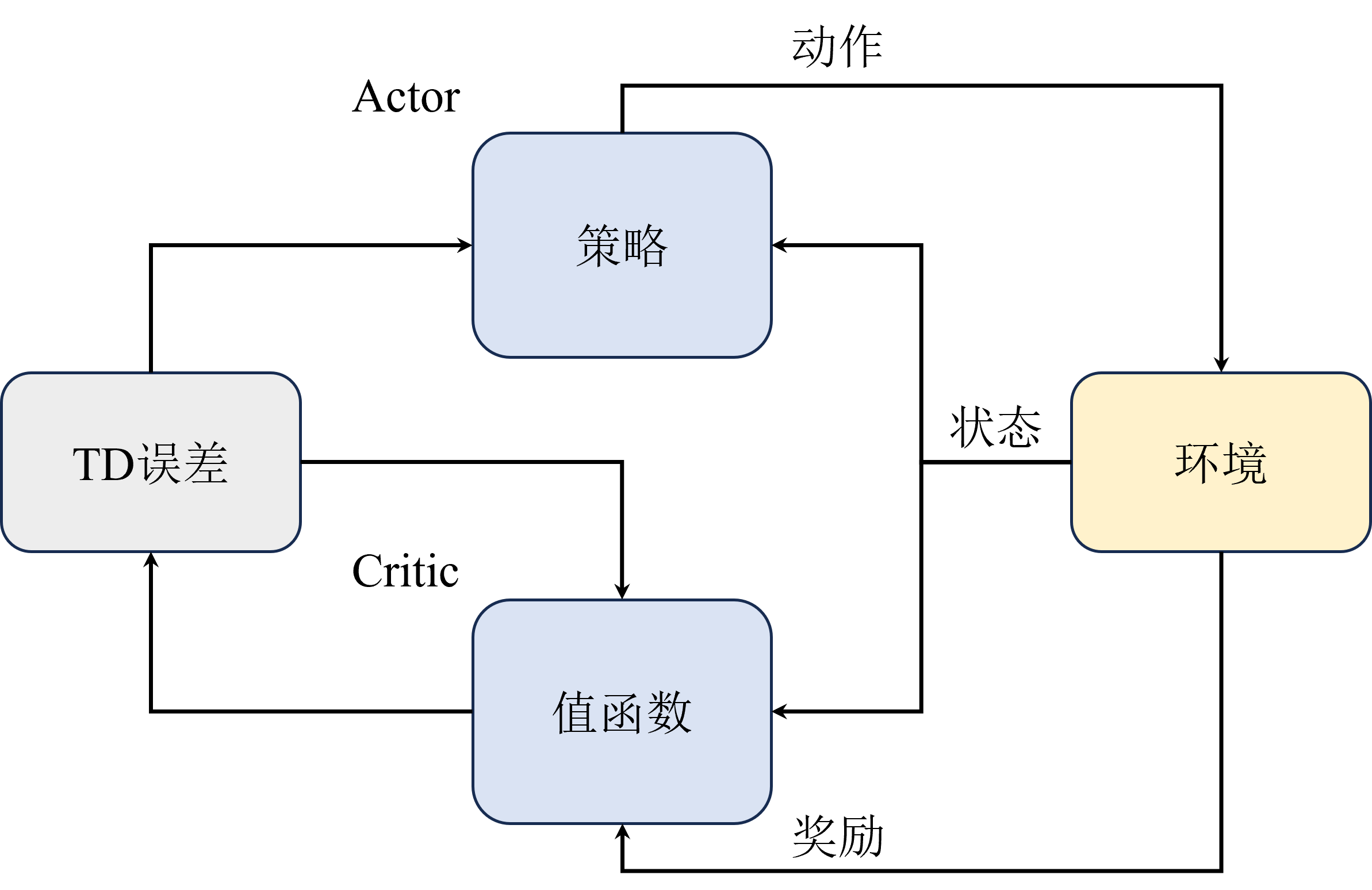
恒大于0、方差较大所有动作权重都相同ActorCritic 存在的问题 (TRPO/PPO来解决)
更新步长选择困难症
每次梯度更新时,都对策略做采样。
训练过程比较慢、采样随机性导致可能朝着错误方向更新。TD Error 估计优势函数是有偏的
背景
方差大核心思想
优势函数=Q-V作为权重,动作是Q,基线是V 同一状态下的基线, 而非所有状态的均值TD Error 作为优势函数
避免Q网络,只需V,直接使用 去掉了期望值, 因为论文实验其效果好优点
无需估计Qr的方差相比G的方差 小很多策略梯度
参数更新过程
策略梯度 * 权重(优势) ,权重指引优化方向log_probs * advantages.detach()).mean()均方误差作为critic loss评估得越来越准预期回报接近实际回报。advantages.pow(2).mean()优点
减去基线,降低了方差,详见降低方差数学推导过程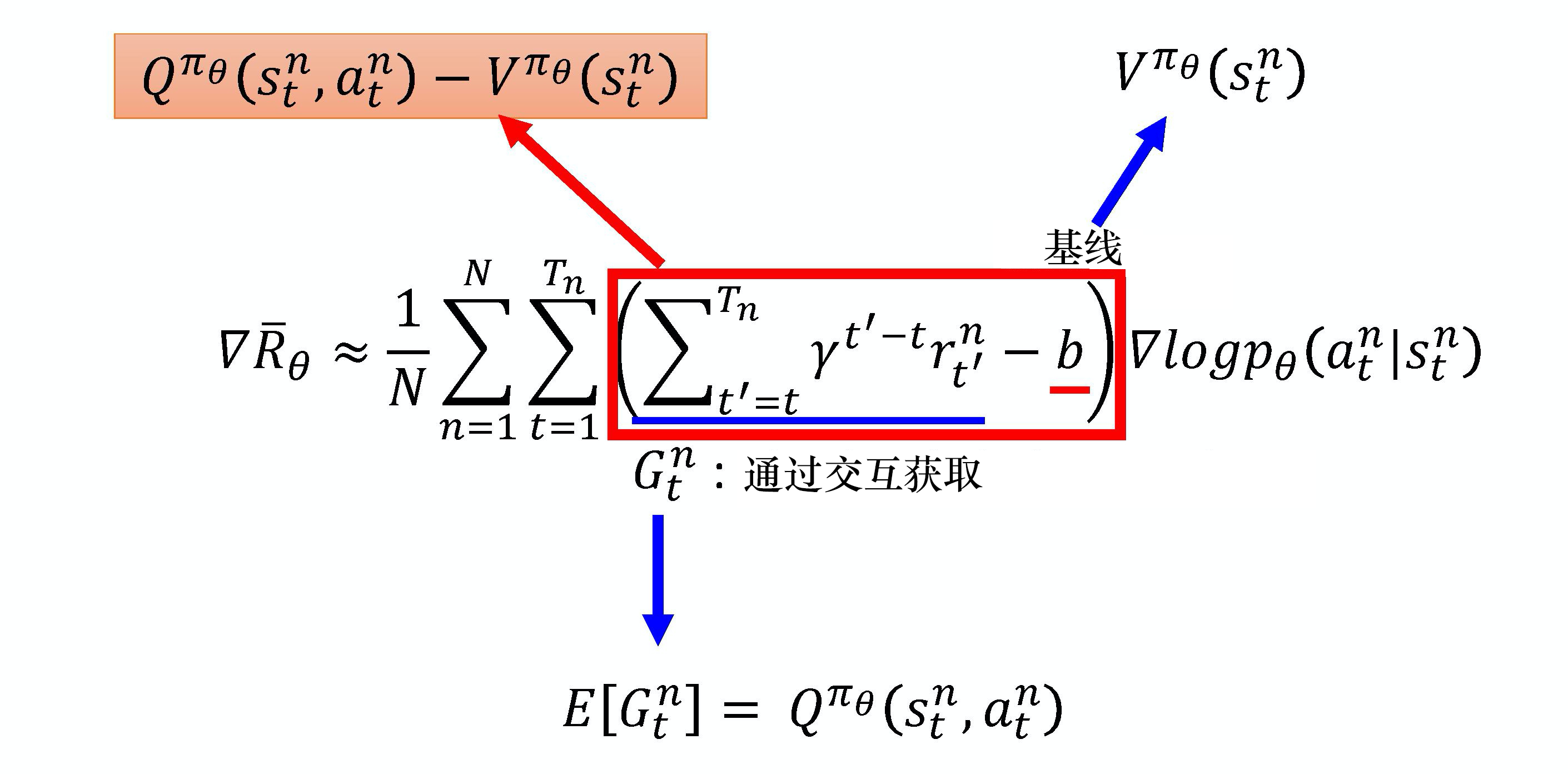
优势
差值就是优势。更合理地帮助衡量单步价值信号,可替换总回报等,见策略梯度权重多种形式优势越大,说明该动作比其他动作更好,应该提升该动作的概率 。按此方式去更新策略。该动作的概率已是1或最大。Q已经接近V,从而 A 趋近于0。此时策略已经趋于最优,产出最优最大的。推动它找到某个状态下最佳的动作,逐步向推动它准确衡量当前策略的价值,逐步向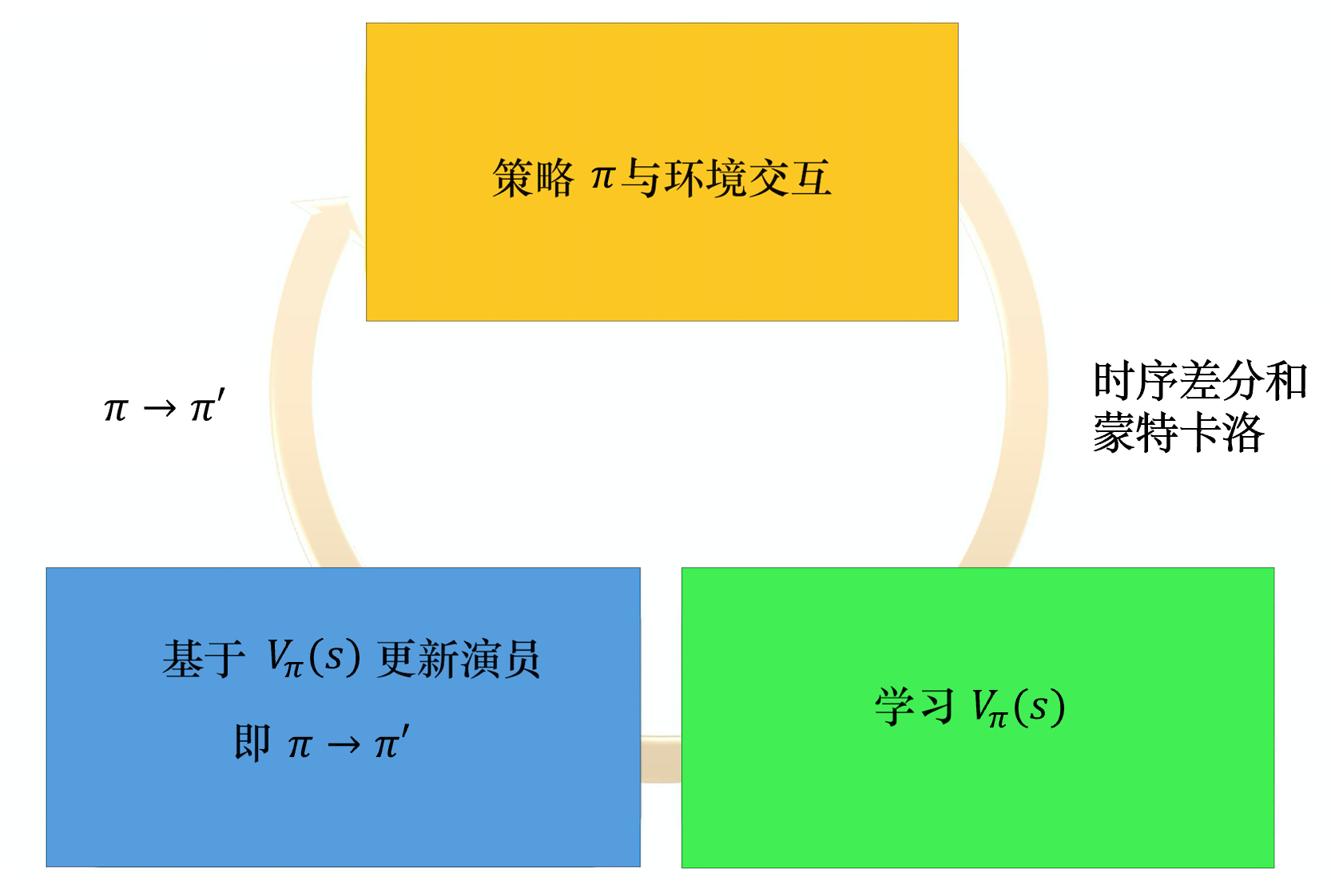
1. Stop-Gradient
2:探索机制-熵正则化
输出设置约束,使分布的熵不要太小,希望不同动作的采样概率平均一些3:优势函数值域固定到[-1,1]
4. 共享网络
5. 估计V和Actor2个网络
Actor、Critic 定义
# 分开定义
class Critic(nn.Module):
''' 估计状态价值,输出标量
'''
def __init__(self,state_dim):
self.fc1 = nn.Linear(state_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
value = self.fc3(x)
return value
class Actor(nn.Module):
''' 采样动作,输出logits_p,动作概率
'''
def __init__(self, state_dim, action_dim):
self.fc1 = nn.Linear(state_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
logits_p = F.softmax(self.fc3(x), dim=1)
return logits_p
# 合在一起定义
class ActorCritic(nn.Module):
''' 输入状态,输出动作概率和状态价值
'''
def __init__(self, state_dim, action_dim):
self.fc1 = nn.Linear(state_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.action_layer = nn.Linear(256, action_dim)
self.value_layer = nn.Linear(256, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
logits_p = F.softmax(self.action_layer(x), dim=1)
value = self.value_layer(x)
return logits_p, valueAgent:采样动作、计算优势函数、计算loss、策略更新
from torch.distributions import Categorical
class Agent:
def __init__(self):
self.model = ActorCritic(state_dim, action_dim)
def sample_action(self,state):
''' 动作采样
'''
state = torch.tensor(state, device=self.device, dtype=torch.float32)
# 策略网络输出动作概率分布
logits_p, value = self.model(state)
dist = Categorical(logits_p)
# 依概率采样一个分布
action = dist.sample()
return action
def _compute_returns(self, rewards, dones):
''' 计算回报,做归一化
'''
returns = []
discounted_sum = 0
for reward, done in zip(reversed(rewards), reversed(dones)):
if done:
discounted_sum = 0
# 折扣回报
discounted_sum = reward + (self.gamma * discounted_sum)
returns.insert(0, discounted_sum)
# 回报归一化
returns = torch.tensor(returns, device=self.device, dtype=torch.float32).unsqueeze(dim=1)
returns = (returns - returns.mean()) / (returns.std() + 1e-5) # 1e-5 to avoid division by zero
return returns
def compute_advantage(self):
''' 计算优势
'''
# 从经验池中采样数据:动作概率、状态、回报、结束
logits_p, states, rewards, dones = self.memory.sample()
# 根据rewards 计算回报
returns = self._compute_returns(rewards, dones)
states = torch.tensor(states, device=self.device, dtype=torch.float32)
# 当前模型去估计状态价值
logits_p, values = self.model(states)
# 实际回报 - 状态价值 作为优势
advantages = returns - values
return advantages
def compute_loss(self):
'''计算损失函数
'''
# 采样数据
logits_p, states, rewards, dones = self.memory.sample()
returns = self._compute_returns(rewards, dones)
states = torch.tensor(states, device=self.device, dtype=torch.float32)
# 估计价值V、计算策略logits_p
logits_p, values = self.model(states)
# 计算advantages
advantages = returns - values
dist = Categorical(logits_p)
# 计算log_prob
log_probs = dist.log_prob(actions)
# 注意这里策略损失反向传播时不需要优化优势函数,因此需要将其 detach 掉
actor_loss = -(log_probs * advantages.detach()).mean()
# critic loss
critic_loss = advantages.pow(2).mean()
return actor_loss, critic_loss背景
核心思想
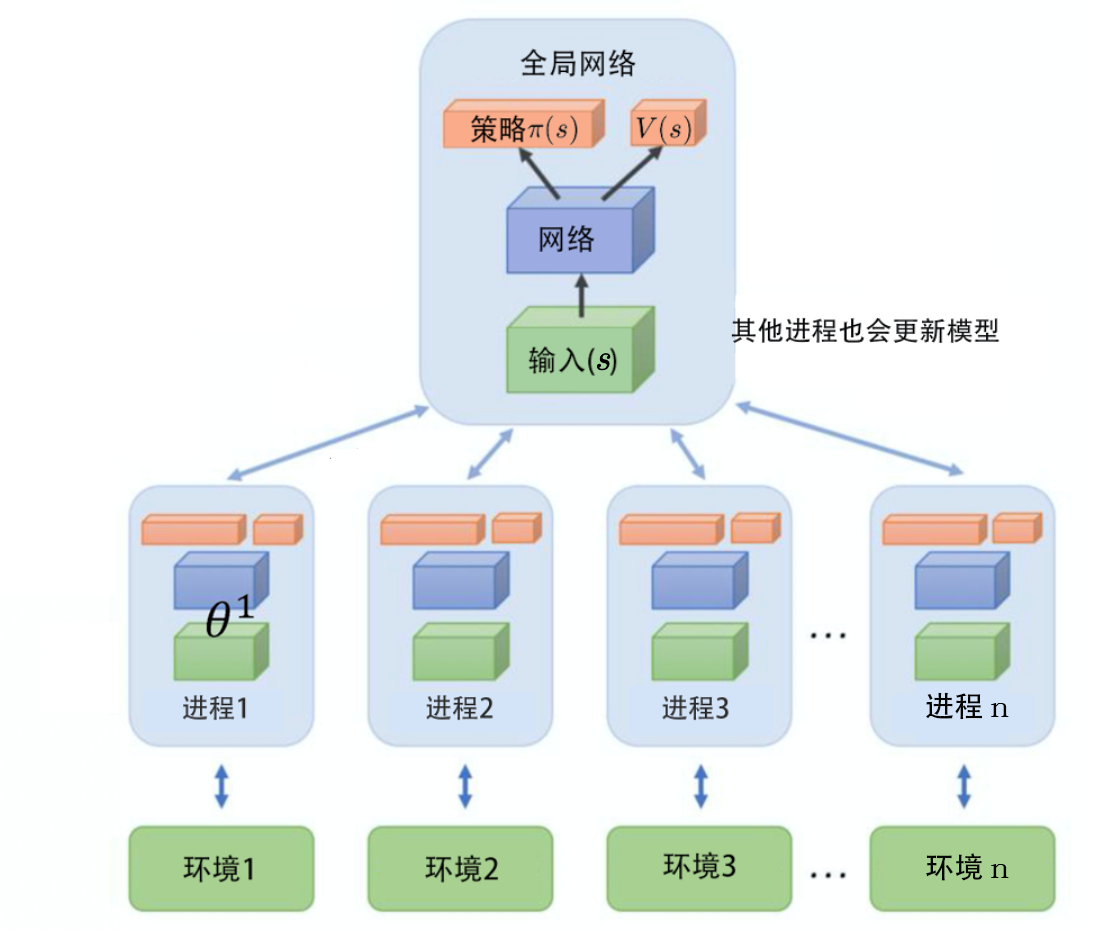
1个全局网络+多个worker并行探索训练同策略算法,虽然看起来像异策略 优点
平行探索,保持训练稳定性