PPO 改进系列
📅 发表于 2025/09/23
🔄 更新于 2025/09/23
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
ppo
#ppo
#vc-ppo
#vapo
#价值偏差
#长度不一
#奖励稀疏
#GAE奖励信号衰减
#价值预训练
#Decoupled-GAE
#长度自适应GAE
#Token-level Policy
#Clip-Higher
#正样本LM Loss
#分组采样
#RLOO
#REINFORCE++
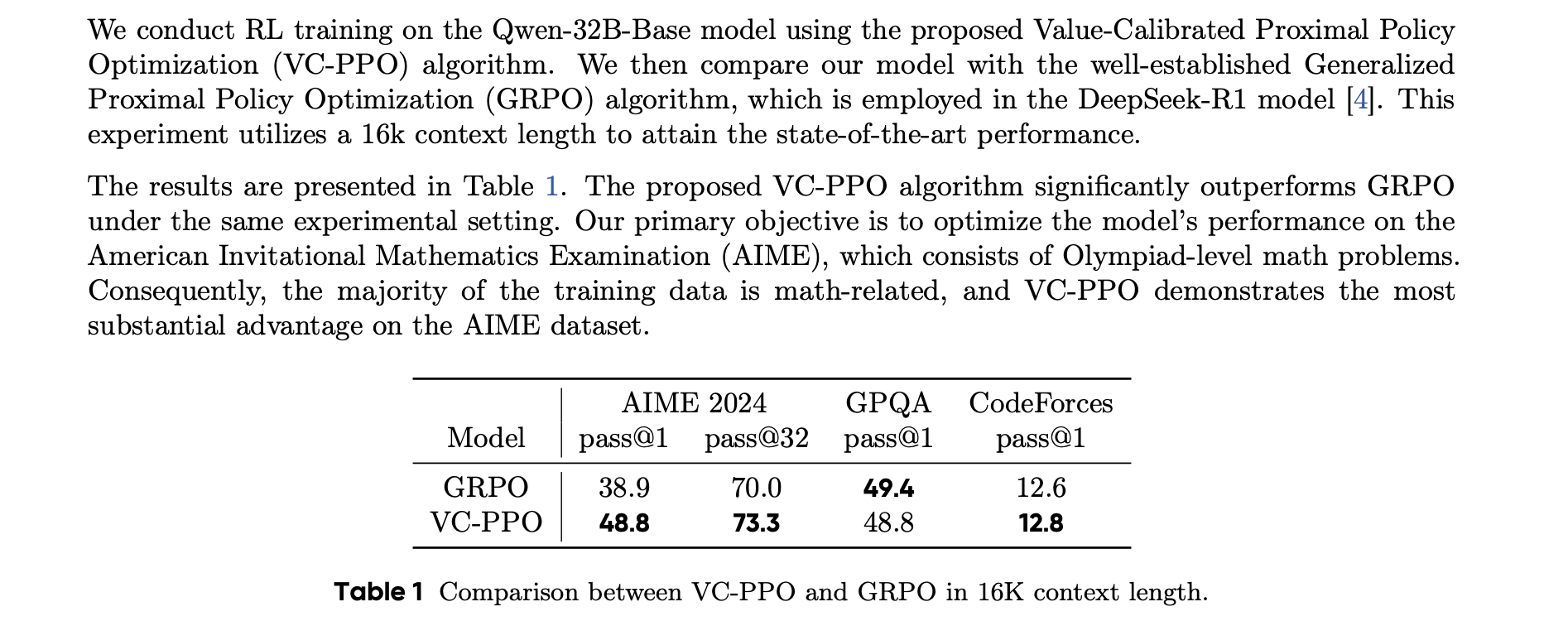
非常solid的文章,基于PPO的改进优化。价值偏差、长度不一、奖励稀疏3大问题价值预训练、解耦GAE、长度自适应GAE、token-level loss、CLip-Higher、正样本LMLoss、分组采样等7大核心方法。提高更细粒度的学习信号,性能更好、训练效率、稳定性更高。❓问题背景
LongCoT 推理任务 RL 在Value-based方法上,存在挑战。
1. 价值模型偏差
RM和Critic目标不一致,却用RM初始化Critic。 正向优势偏差。2. 训练过程序列长度不一
固定λ无法适应动态长度。方差很高,导致训练不稳定过多自举,引入高偏差。 每一步的微小误差在长序列中不断累计放大,影响学习效果。GAE指数衰减特性,天然不适合处理长度变化范围极大的序列。标准Seq-Loss 缺点
标准PPO是Sequence-Level Policy Loss,即2步平均。
序列内平均(inner average):对一个序列的所有token求平均,作为序列loss样本间平均(outer average):对所有序列的loss求平均后果
更关注学好短序列,忽略长序列中token的错误学不好处理长序列问题,因为长序列权重被稀释。短序列/长序列token影响力不同
由于序列是平均对待,因此短序列token影响力比长序列token影响力更强。
1/10。1/1000。犯错带来的惩罚影响力是长序列B Token影响力的100倍。奖励被稀释
被其他900个普通token平均,导致最终总贡献和50个token普通回答差不多。惩罚被稀释
但差的被前面好的平均稀释了,得不到足够的惩罚。更长、质量更差的回答。3. 稀疏奖励信号
长CoT会加剧稀疏性,采样到非0奖励的样本概率更低,大部分尝试都是错的。需要保持平衡。 需要探索:保持不确定性去探索不同推理路径,找到正确答案。需要利用:需要利用艰苦探索得到的正确样本,提升学习效率。如果不平衡,可能陷入局部最优解、大量无效探索。📕核心方法
整体背景
价值模型初始化不当 和奖励衰减带来的偏差问题。背景
价值模型初始化偏差问题。核心思想
固定策略+MC采样回报,来预训练价值模型。更准确、偏差更低的估计。避免训练初期崩溃。价值预训练
背景
长序列中奖励衰减 导致价值更新不准确的问题。核心思想
使用不同的λ。λ=1,使用无偏MC回报来训练网络,消除自举带来的偏差让模型能学到长序列末端的真实奖励信号。λ<1(0.95),虽然引入一些偏差,但能有效降低方差。加速策略收敛和保持训练稳定。问题
无法适应长短不同序列的问题。目的
动态调整GAE的λ参数,适应不同长度。核心思想
动态调整λ,与序列长度l做适应
序列很长时:λ变大, 接近1
使最终奖励信号传播得更远,能看得越远,确保末端奖励信号不丢失,从而降低偏差。序列很短时:λ适当变小
GAE 权重系数总和
对当前决策的总影响力,TD(λ) 权重理解具体做法
总影响力应该与序列长度l成正比
长度自适应
PPO Seq-Loss 缺点
标准PPO是Sequence-Level Policy Loss,即2步平均。
所有token求平均,作为序列loss所有序列的loss求平均例子见上文问题
模型更关注学好短序列,忽略长序列中token的错误,学不好处理长序列问题,因为长序列权重被稀释。
VAPO Token-Level Loss
直接对所有token做平均,每个token权重相同,不论它来自短序列或长序列。标准PPO-Clip问题
极好、但之前概率极低的策略时,很可能会被clip掉。天花板会限制奖励程度,使得策略更新过于保守,不利于大胆探索Clip-Higher:奖要重奖、罚要慎罚
把上下界解耦为非对称
提高上界
为奖励信号打开更高天花板;当探索到好路径时,策略可以进行大幅度更新。保持下界
惩罚错误路径时可能过于激进把概率压到0,这样会扼杀多样性,导致熵崩溃。目的
最大化正样本生成概率核心思想
强化学习策略更新基础上(正向奖励、PPO Loss、策略更新)。模仿学习,增加负对数似然,强迫模型去学习和复现整个正确推理过程。NLL Loss
最大化正样本的生成概率。且手把手教学如何做对的,记住这个过程。目的
生成对比性数据来提升学习。VAPO 选择深度优先策略
✍️实验设置
模型
数据
Baseline/基础算法
Base PPO 参数设置
Critic 学习率 2e-6。 VAPO 设置
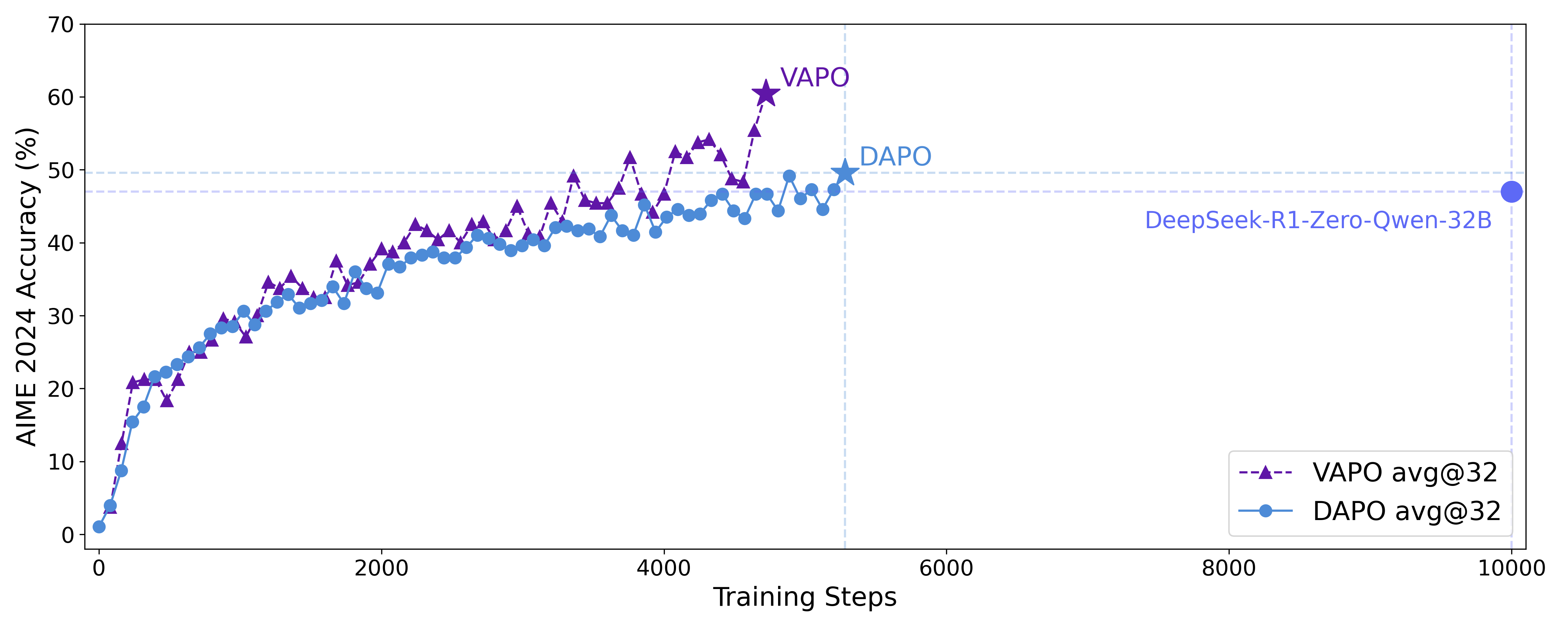
🍑关键结果
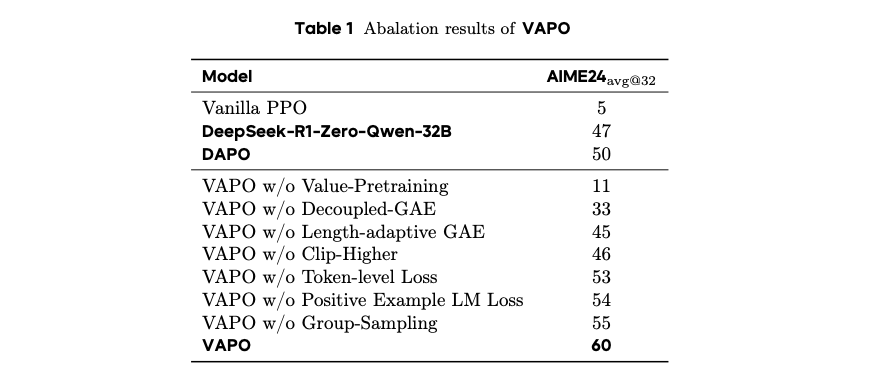
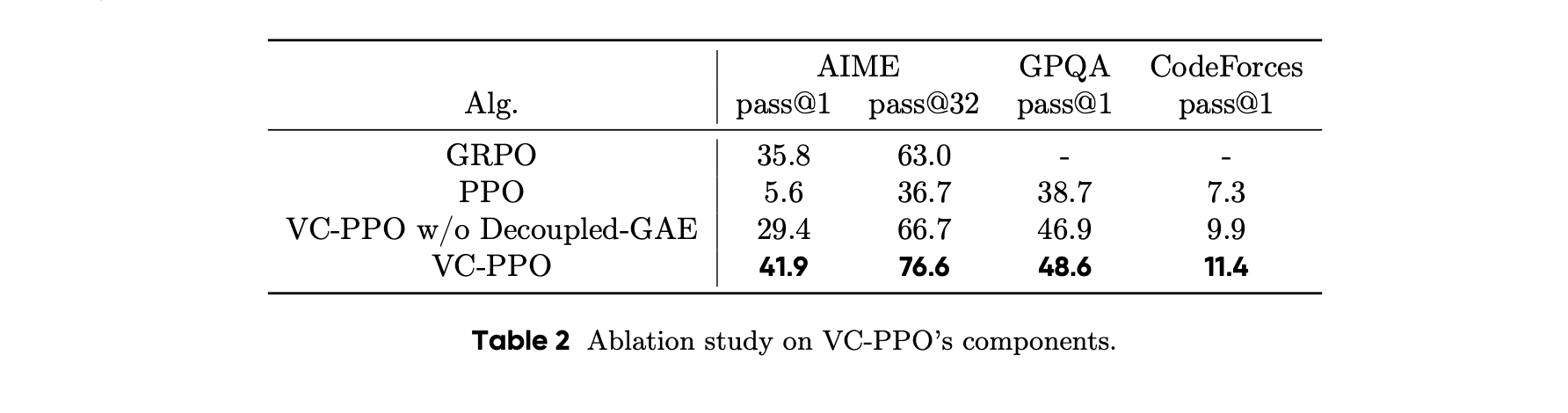
价值预训练、解耦GAE。去掉后,分别暴跌49分、暴跌27分。长度自适应GAE(贡献15p)、Clip-Higher、Token-Level Loss(贡献7p)、正样本LM Loss(贡献6p)、分组采样(贡献5p)。更细粒度的学习信号,使得模型更好扩展推理长度,泛化更强。VAPO 效果好
消融实验:
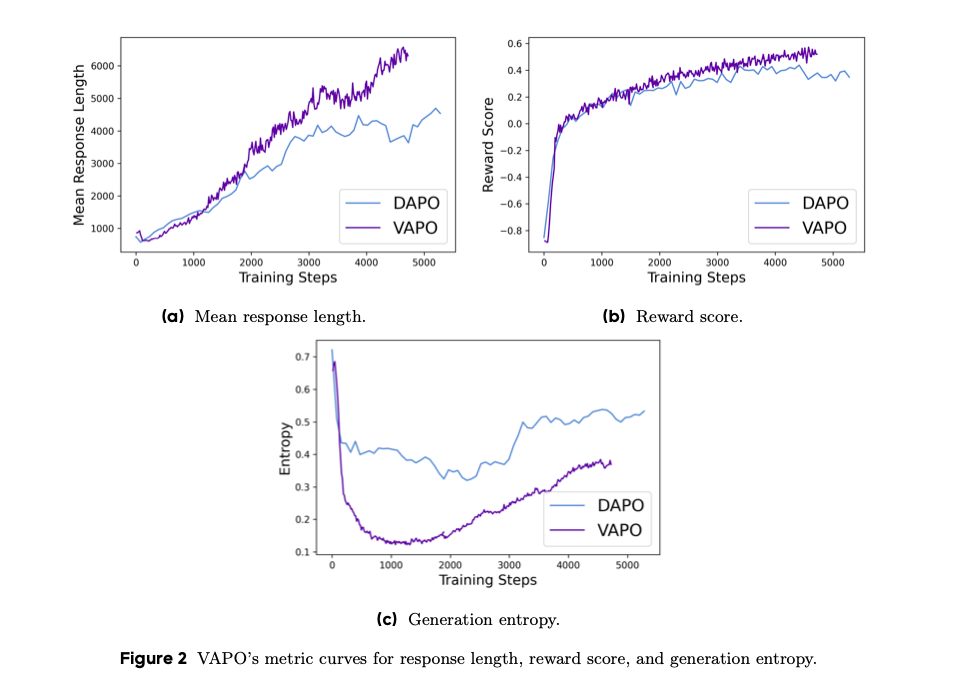
过程曲线
⛳未来方向
价值预训练、Decoupled-GAE两大方法,解决价值偏差问题。❓问题背景
PPO 在Long CoT上会训练崩溃。
回复长度急剧缩短、性能下降。Critic 初始化偏差、奖励信号衰减。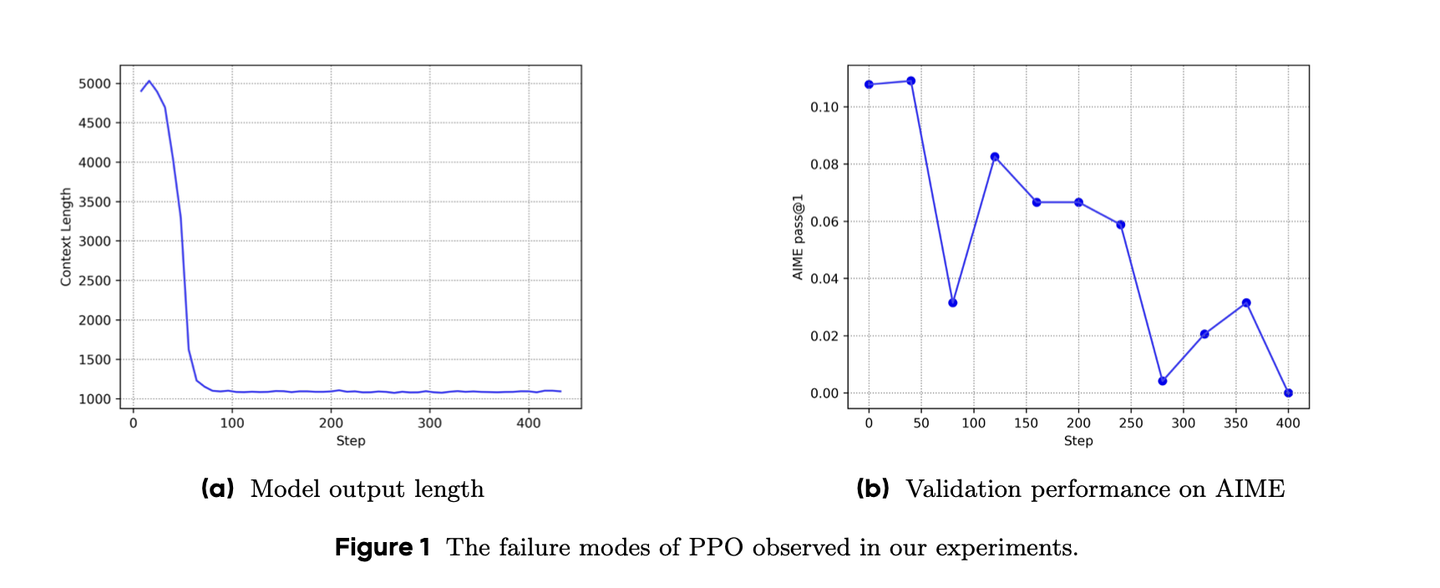
标准PPO Critic 由 RM初始化
RM和Critic 目标存在差异
<EOS>出现时做评估,<EOS>前面的token没被训过。从RM初始化的Critic:打分/优势存在偏差
打分偏差
靠前的、更不完整的句子状态,打低分。句子变长、越来越完整,打高分。优势偏差
优势恒大于0。由于TD Error恒大于0
Token越靠前,累加正项越多,其最终优势值 就越大。若TD大于0,越靠前的token,优势值越大,证明过程
令
从公式可以看出,t越靠前,优势值越大。
如下图所示,前面的token价值小、后面的token价值大,TDError>0,最终导致前面的token优势大,最后导致模型回复长度急剧缩短。
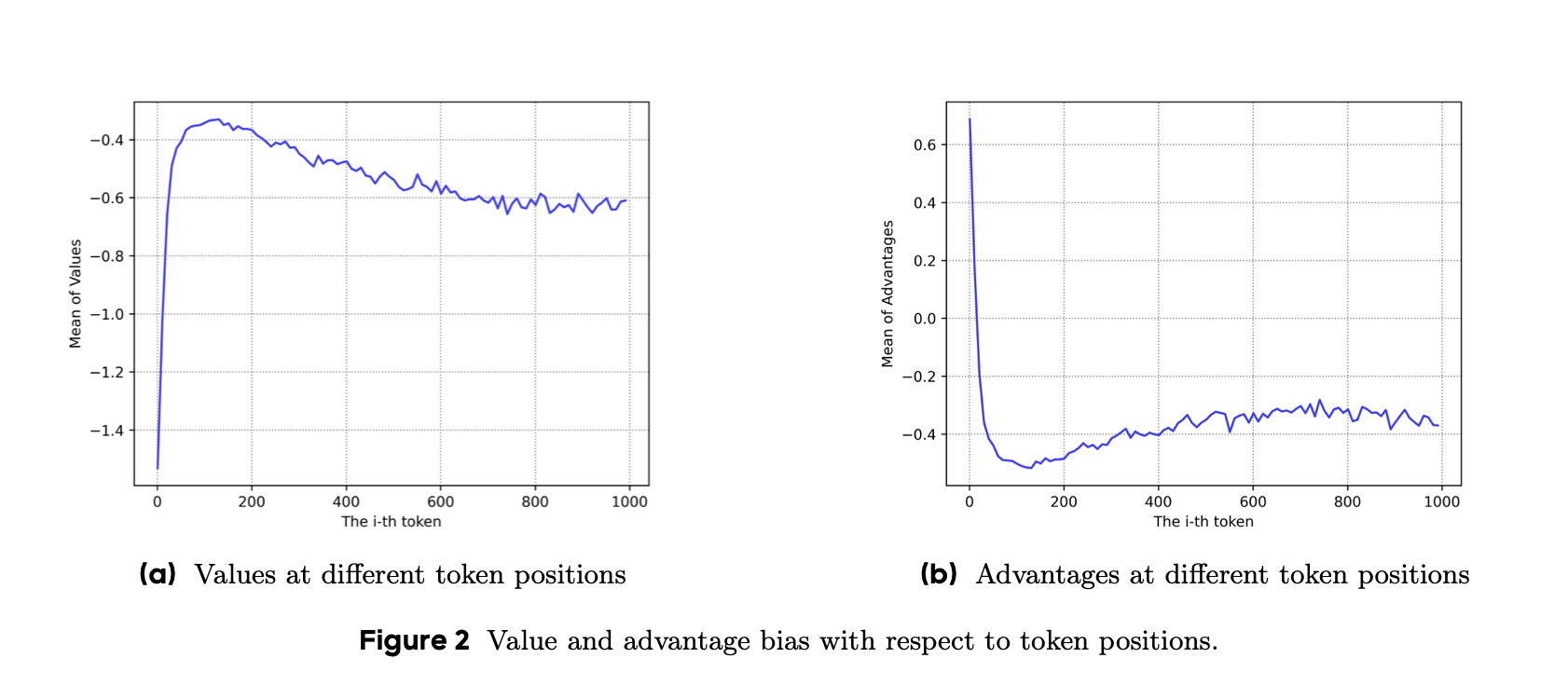
更多详细推导见 GAE 奖励信号衰减
背景
仅最后1个token有环境奖励信号 真实外部信号传递回第t个token时,会乘以权重权重容易变成0。奖励衰减缺陷
前面token收不到任何有效奖励信号,权重接近0了。Critic模型无法学习到他们的真正贡献。当λ<1时,奖励信号衰减权重在后面的token衰减很快,接近1时衰减较慢。
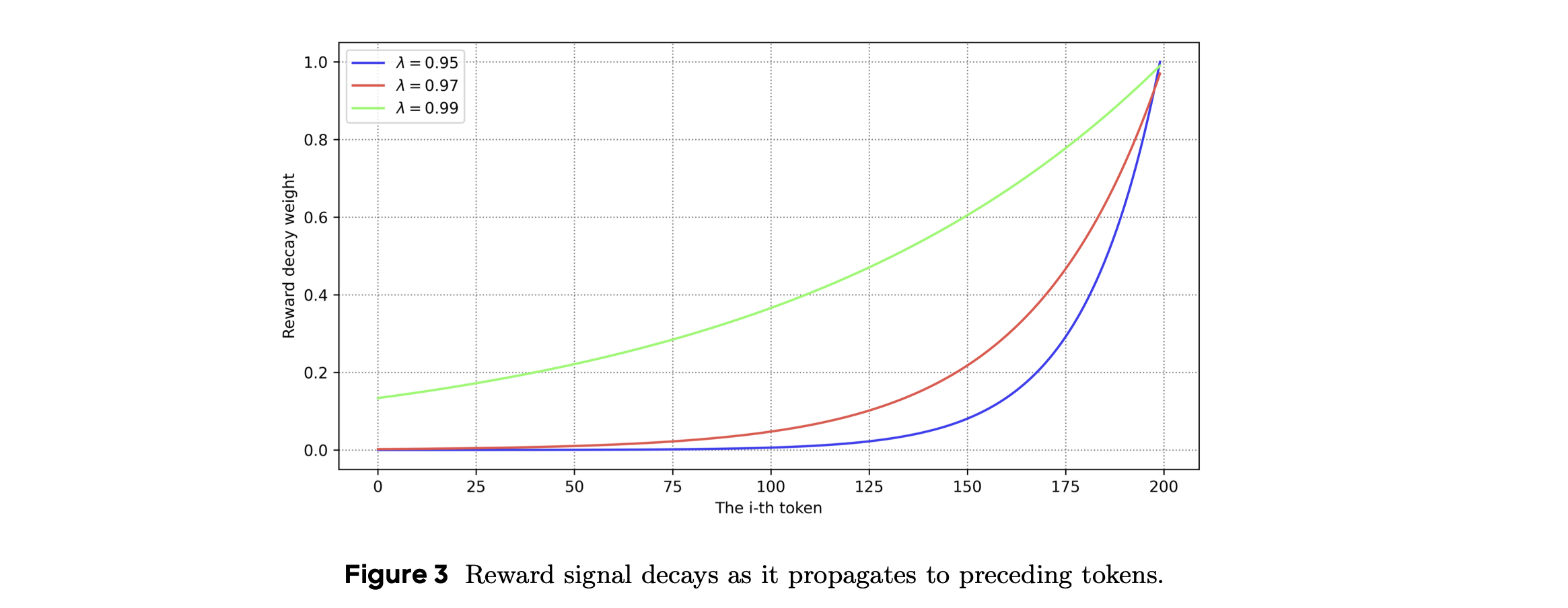
符号定义
Token-Level MDP
状态空间
动作空间
论文里常用符号,q代表x,o代表y输出。也有用c代表当前状态状态转移矩阵
执行动作终止条件:达到EOS或最大长度。
奖励函数
仅在序列结束后,环境才会给一个序列级信号。初始状态分布
优化目标
📕核心方法
解决问题
核心思想
固定策略+MC回报,把价值模型的学习从不稳定的RL过程变成 稳定的监督学习过程。具体做法
固定策略模型(如GAE + λ=1退成MC采样,得到稳定梯度信号。
单独训练Critic模型,使其准确预测回报,直到收敛,看2个指标
Value Loss:预测价值和真实奖励之间的差距
Explained Variance/解释方差:衡量预测趋势和真实趋势的匹配程度。
预测误差的方差除以真实方差。预测误差的方差:还剩下多少无法解释的波动性。正式PPO时,使用预训练过的Critic模型,而不再使用RM做随机初始化。
价值预训练以后,advantage不再有偏差,模型输出长度也正常了。
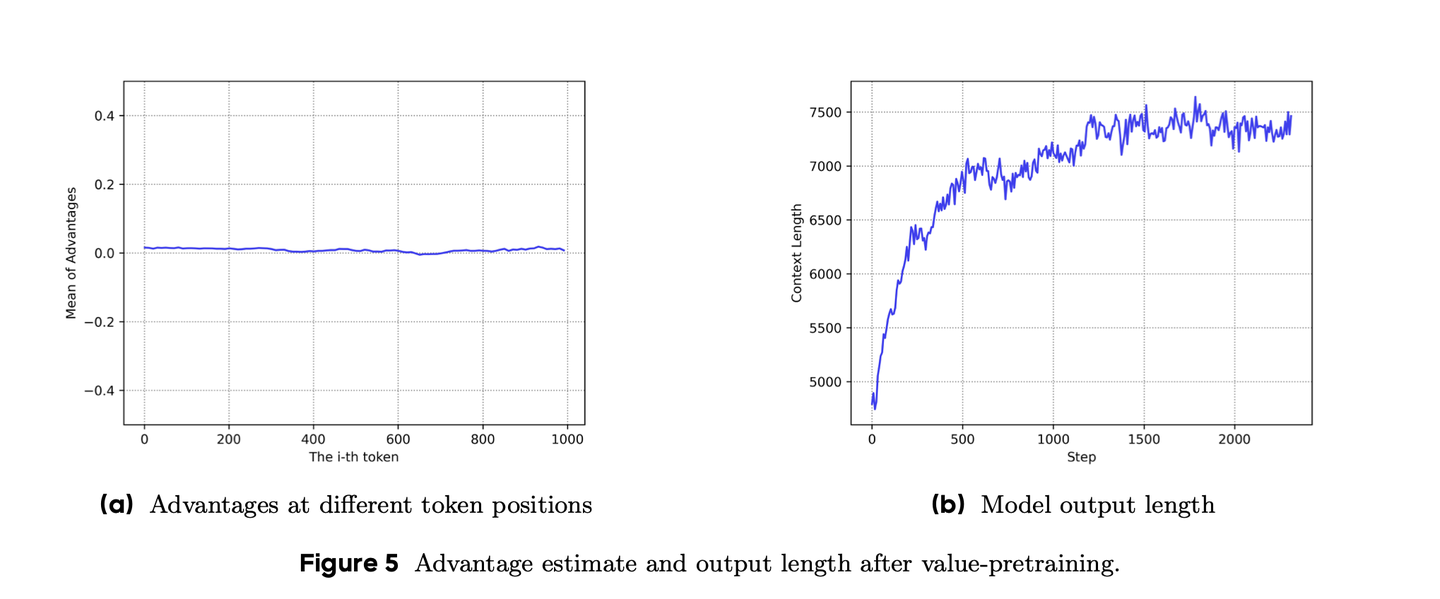
# 从SFT模型生成响应
responses = generate_responses(sft_model, prompts)
# 计算完整响应的奖励
rewards = reward_model(responses)
# 训练价值模型以预测每个token位置的奖励
for token_pos in range(len(response)):
# 价值目标是序列的最终奖励
value_target = rewards[response_idx]
# 训练价值模型以预测每个位置的这个目标
value_loss = (value_model(token_pos) - value_target)^2
optimize(value_loss)解决问题
Critic偏好无偏估计,λ=1,追求准确性。Actor偏好低方差, λ<1,需要平衡偏差和方差。如果方差太大,会导致训练不稳定。核心思想
Critic和Actor使用不同的λ。Critic:λ=1,确保奖励信号在长序列中无衰减地传播,更好地学习价值模型。Actor:λ<1(0.95),有效降低优势估计的方差,使策略更新过程更稳定、收敛更快。# 解耦GAE
critic_lambda = 1.0 # 确保价值学习的强信号传播
actor_lambda = 0.95 # 控制策略更新中的方差
# 使用 critic_lambda 计算价值模型更新的优势
critic_advantages = calculate_gae(rewards, values, critic_lambda)
value_loss = (values - (rewards + gamma * next_values))^2
# 使用 actor_lambda 计算策略模型更新的优势
actor_advantages = calculate_gae(rewards, values, actor_lambda)
policy_loss = -log_probs * actor_advantages✍️实验设置
实验数据
模型
训练策略/算法
<think></think>格式输出Reward
Baseline
Policy 1e-6, Critic 2e-6,KL惩罚系数 0:因为是rule-based reward,没有hacking🍑关键结果
都很重要。 AIME 有提升,非常优雅的提升曲线,并且超过GRPO。
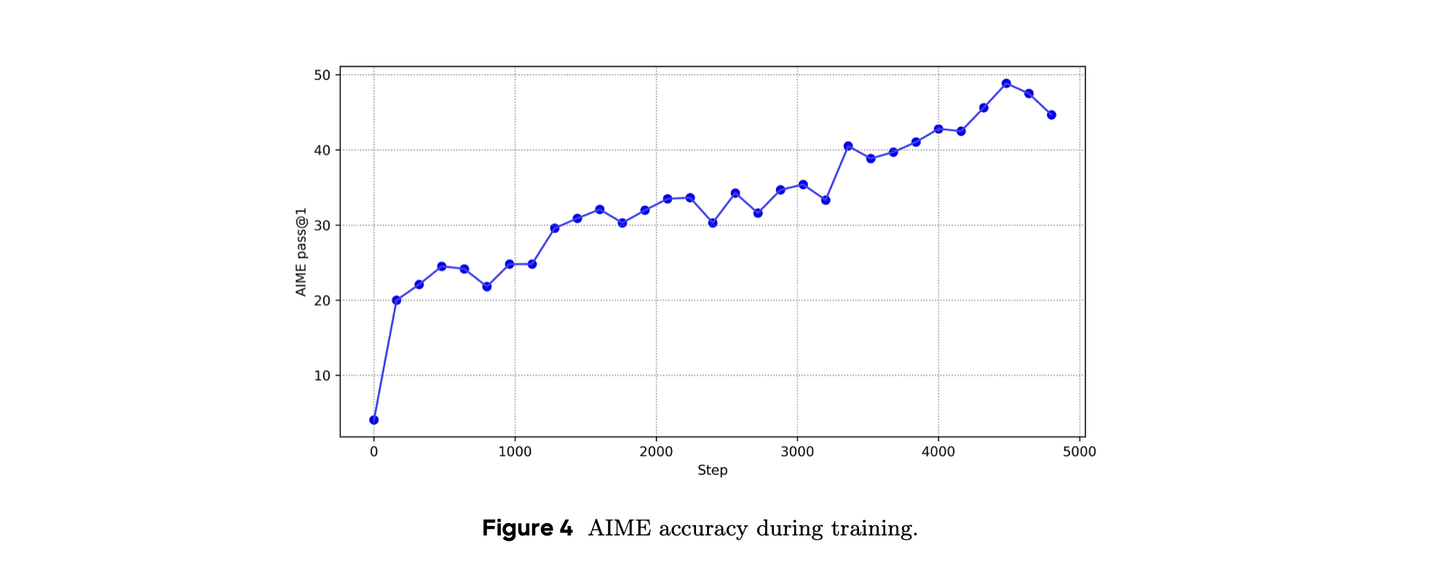
价值预训练和Decoupled-GAE 都很有用。
⛳未来方向
❓问题背景
现有RLHF方法存在一些问题
GRPO/RLOO Prompt/Local-Level Normalization 存在问题
存在理论偏差: 分子(reward)和分母(local std)不是独立的,存在理论偏差。实际不稳定标准差为0,优势值爆炸,训练不稳定。 任务过拟合简单任务上过拟合,复杂任务上难以提升。📕核心方法
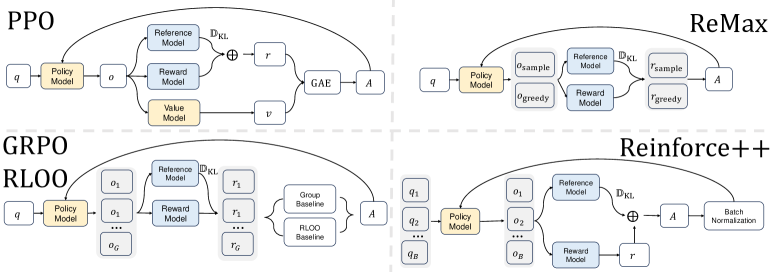
三个原则
整体目标
和PPO一样,只是修改了优势估计每次采样1个回答,G=1优势估计:Token-Level KL 惩罚直接加入Reward
奖励=真实轨迹线奖励 - KL惩罚KL惩罚:累加t时刻后每一个token的KL惩罚,因是对未来产生影响。全局归一化
使用batch-level 归一化
group mean + batch std 比较好。背景
核心思想
轨迹奖励 + Token-Level KL 惩罚
局部基线:Local/Group Baseline/Mean
全局归一化
Loss
KL散度使用K2: 低方差,更稳健
✍️实验设置
任务
模型
算法
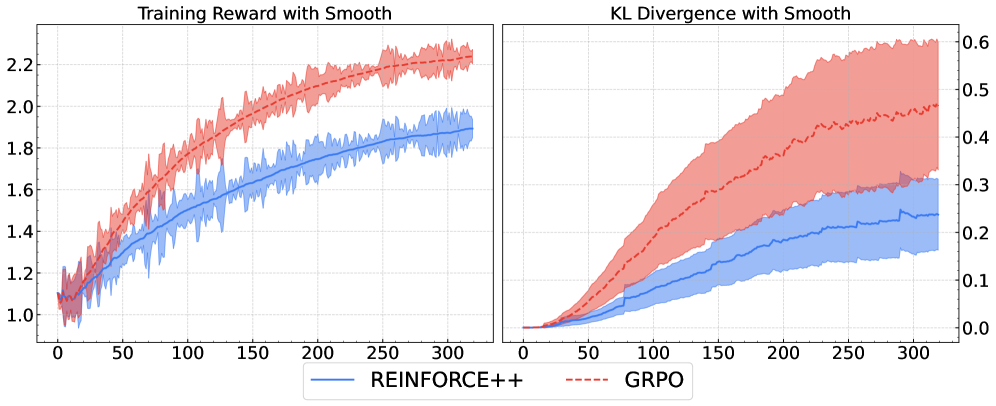
🍑关键结果
引入PPO技巧的REINFORCE算法,大量实验表明REINFORCE++在人类对齐上有优势
通用RLHF任务
推理任务
Agent 任务
全局归一化:被LitePPO、ScaleRL、DLER等相继验证
通用RLHF
谜题数据
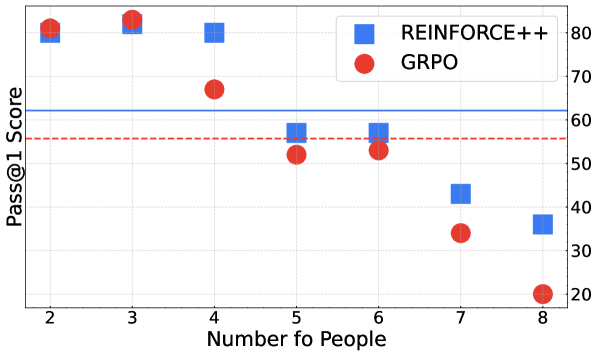
⛳未来方向
RLOO
REINFORCE + 留一法计算优势,无需Critic和Ref模型。Trajector-Level:在整个序列做建模,而非单个token作为一个动作。On-Policy 算法。在2个RLHF任务上,RLOO效果都优于PPO、Vanila PG、DAFT、DPO等。
❓问题背景
人类对齐标准PPO阶段
问题
PPO成本高、复杂。PPO 可能不是最优选择
低方差环境方差低。为降低方差,PPO引入Critic和优势估计,反而会带来偏差,得不偿失。PPO-Clip 可能不必要建模方式可能不恰当生成整个序列看成一个单一动作,更自然和高效,可能更合适📕核心方法
REINOFRCE
REINFORCE + Baseline,REINFORCE 笔记REINFORCE Leave-One-Out
对一个Prompt,采样K/G次。计算优势时,基线使用其余k-1个的奖励平均值
等同于减去平均回报基线
和GRPO很像,但是不除以标准差。
同策略算法,无需重要性权重修正偏差。
整体优化目标
Trajectory-Level,而非Token-Level。✍️实验设置
任务
模型
算法
评估指标
🍑关键结果
RLOO 77.9% > PPO 67.6% > RAFT 73.2% > DPO 66.6%)RLOO则更稳健。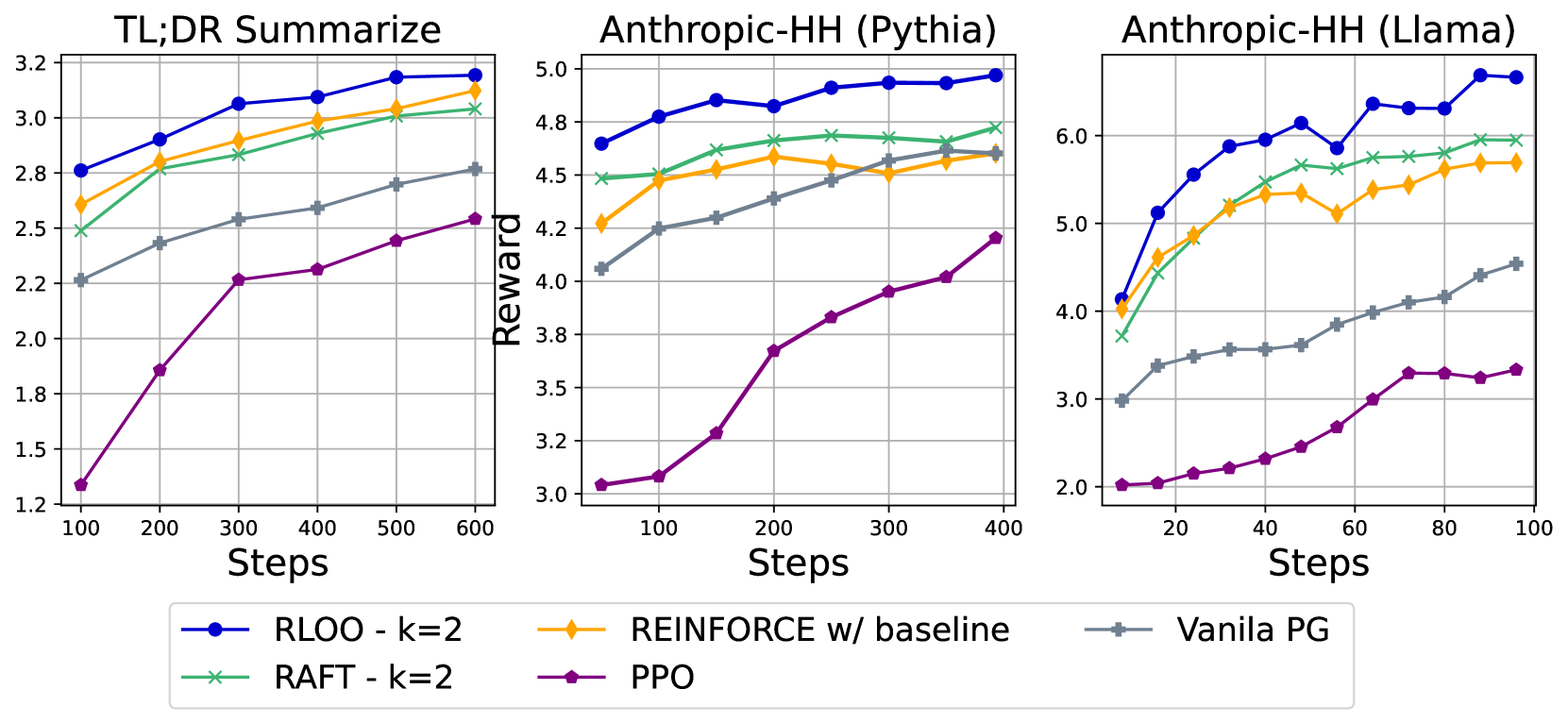
⛳未来方向