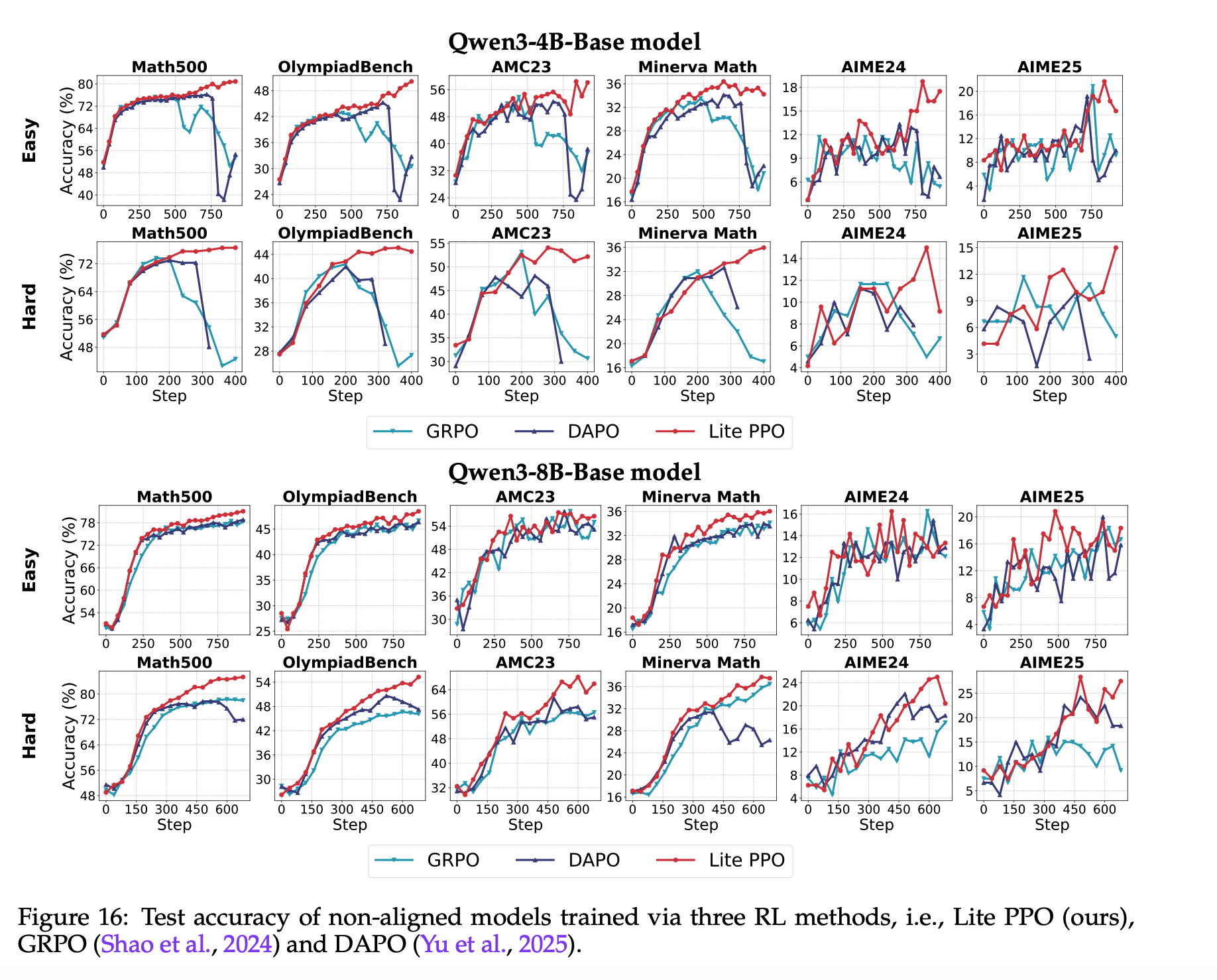
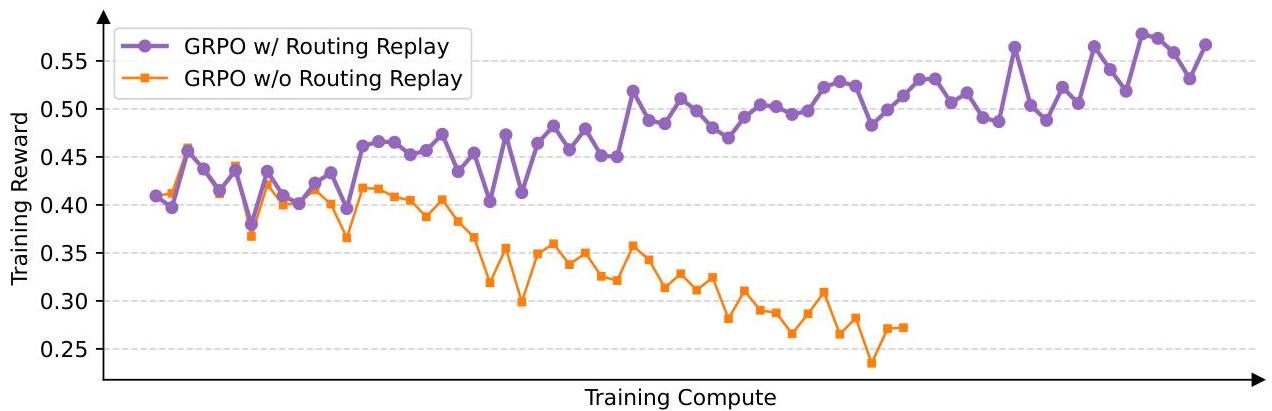
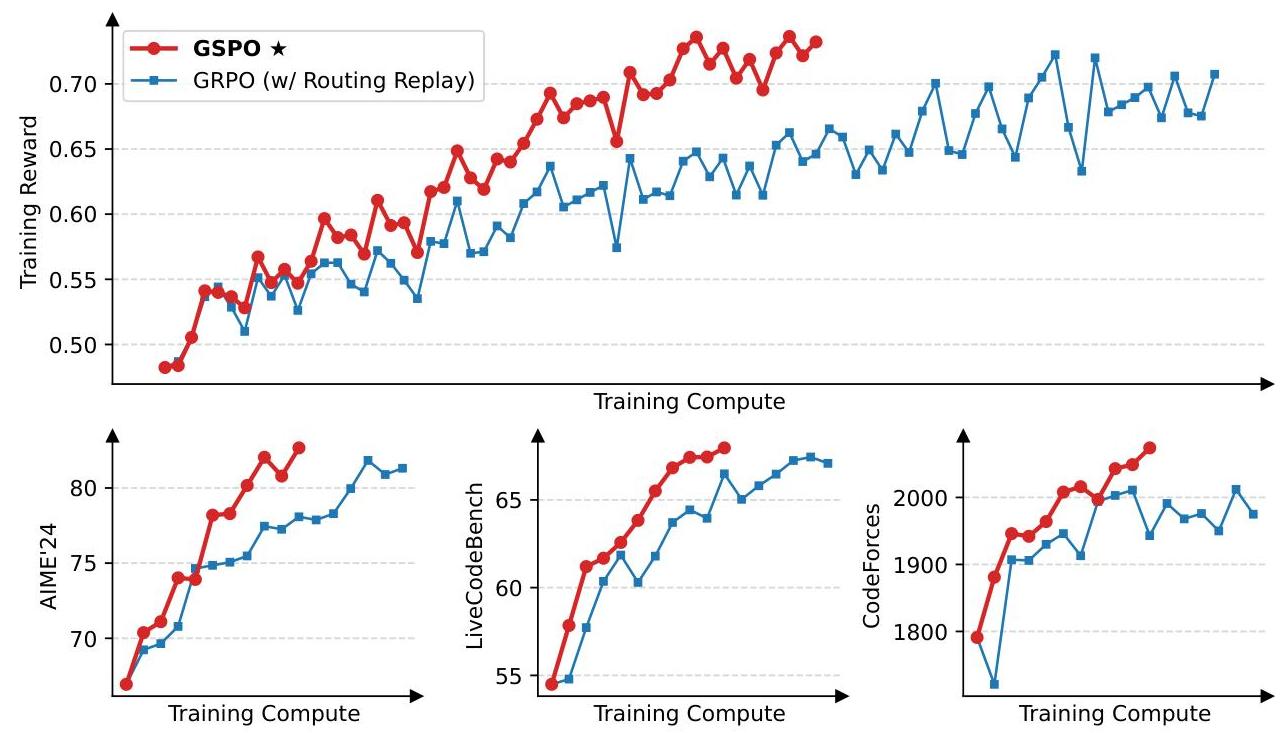
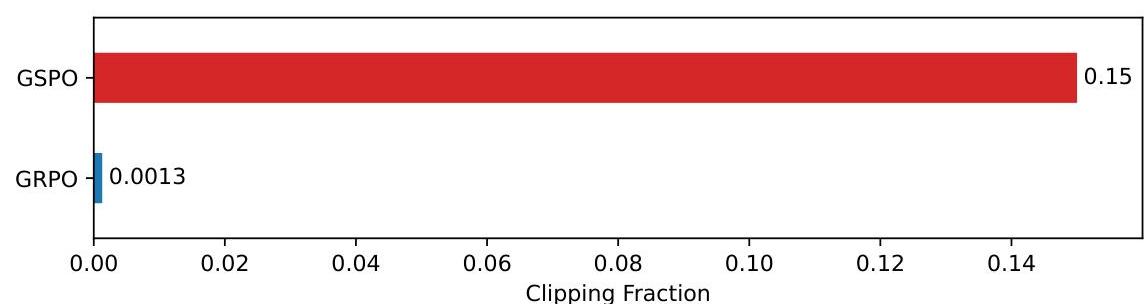
GRPO 改进系列
📅 发表于 2025/11/03
🔄 更新于 2025/11/03
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
grpo
#GPPO
#悲观更新
#GRPO
#DAPO
#熵坍塌
#Clip机制不公平
#探索
#奖励噪声
#训练不稳定
#Clip-Higher
#动态采样
#Token-Level Loss
#Overlong 奖励设计
#GSPO
#Token-Level 重要性权重
#Seq-Level 重要性权重
#MoE Routing RePlay
#CISPO
#重要性权重 Clip
#Dr.GRPO