熵和RL相关文章
📅 发表于 2025/11/04
🔄 更新于 2025/11/04
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
rl
#entropy
非常有深度的一篇文章。
围绕熵坍塌进行了深入研究
模型性能和熵存在预测关系,熵限制,性能有上限。熵和协方差有关系。协方差2个变量:对数概率和logit变化程度。高优势高概率token,协方差大,使得熵坍塌提出Clip-Cov和KL-Cov的方法,精准控制少部分高协方差token。
❓问题背景
RL 核心挑战
策略熵的含义
探索潜力的一个量化指标,代表动作探索空间的不确定性。熵坍塌的表现
训练开始一些step后,策略熵就急剧下降甚至趋于0。策略变得极其确定。熵坍塌的危害
无法探索新路径熵耗尽,性能达瓶颈,再继续训练也是徒劳的。普通正则熵无效
熵正则是无效的。需要打破熵瓶颈
可扩展RL,需要打破熵瓶颈。Entropy Loss:在loss上减去熵
熵越大, loss会小一点。激励模型去寻找熵更高的策略。 entropy_coef参数非常敏感,非常脆弱entropy_coef 太小:[0.0001, 0.001],对熵几乎没有作用,熵依然崩溃entropy_coef 太大:0.01,熵直接爆炸了,胡言乱语,输出随机tokenKL Loss:在loss上增加KL惩罚
偏离参考模型较远时,loss会大一点。 拉住熵的作用。kl_coef扼杀了模型的学习能力。kl_coef>0 模型性能低于kl_coef=0RL 优化目标
通过策略梯度来优化
PPO 近端策略优化
GRPO 组内优势减小方差
策略熵
含义:量化不确定性,策略在选择动作时的可预测性、随机性。
计算:给定策略和数据,平均token-level的熵,作为策略熵。
策略熵公式理解
生成下一词概率,[0, 1]之间,模型自信程度。概率越大, 越自信,不确定性越低。序列内部所有token求平均,平均token熵序列间 所有序列求平均,作为策略熵。概率越大,不确定性越低。把值转换成正数。值越小,熵越小,概率越高,不确定性越低;值越大,熵越高,概率越低,不确定性越高。性能和熵直接挂钩
在没有熵loss或KL正则的情况下
模型性能可预测的指数关系
性能提升,熵必然减小。牺牲熵、来提升模型性能。
性能和熵挂钩,而不是和计算资源挂钩,且和算法无关,后期实验有验证。
性能存在上限
后续投入再多计算资源也无用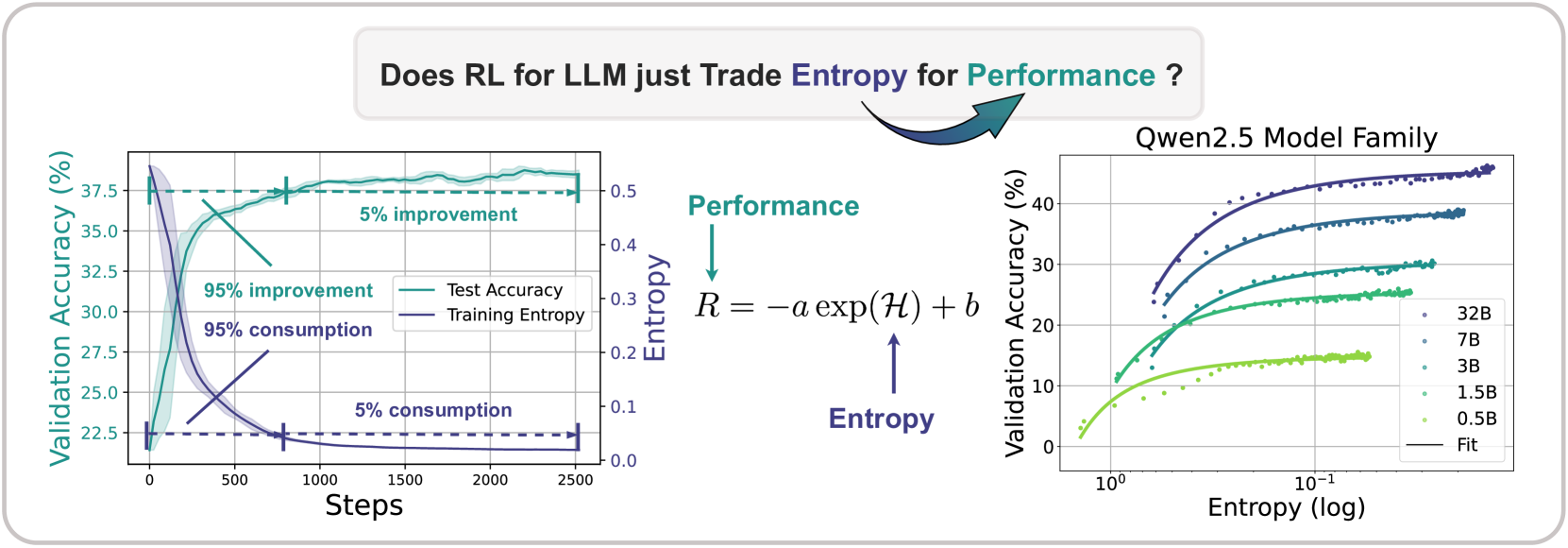
✍️实验设置
模型
任务/数据
算法
超参
过滤掉全对或全错的prompt, DAPO 动态采样🍑关键结果
早期消耗熵活动性能
多组实验完美拟合熵和性能的曲线
ab 系数理解
a:转化效率。
b、-a+b:性能潜力
早期消耗熵、增加性能。
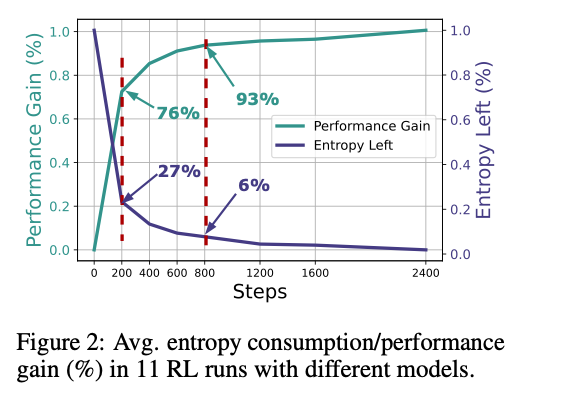
完美拟合曲线:实线是公式计算的,散点是实际测量的(熵, 性能)数据对。
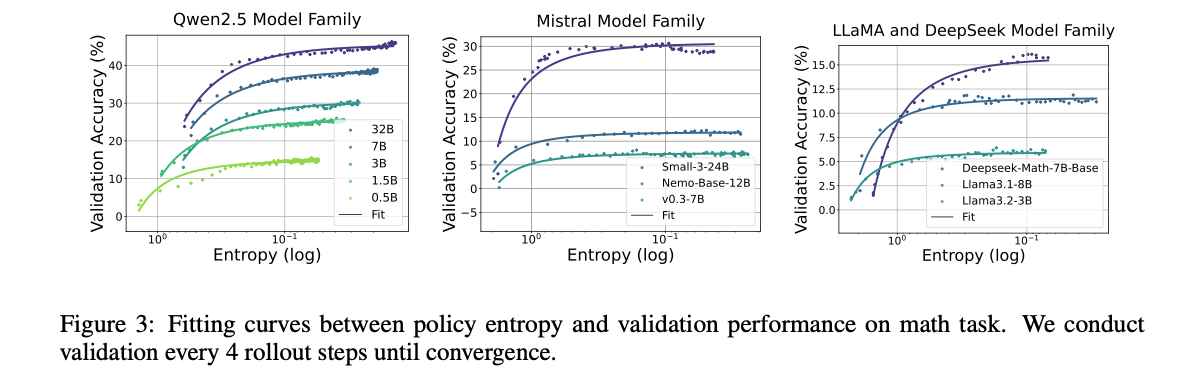
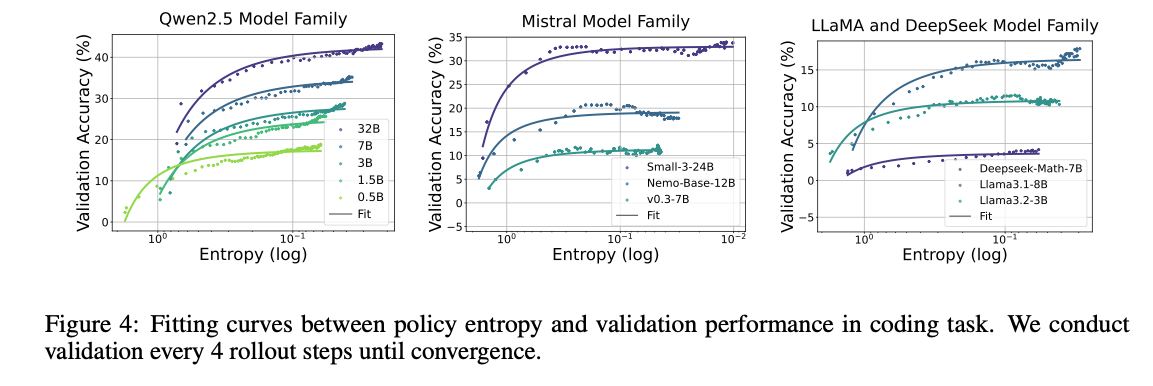
在训练早期,可以通过公式来预测后期性能,性能上限是注定的。
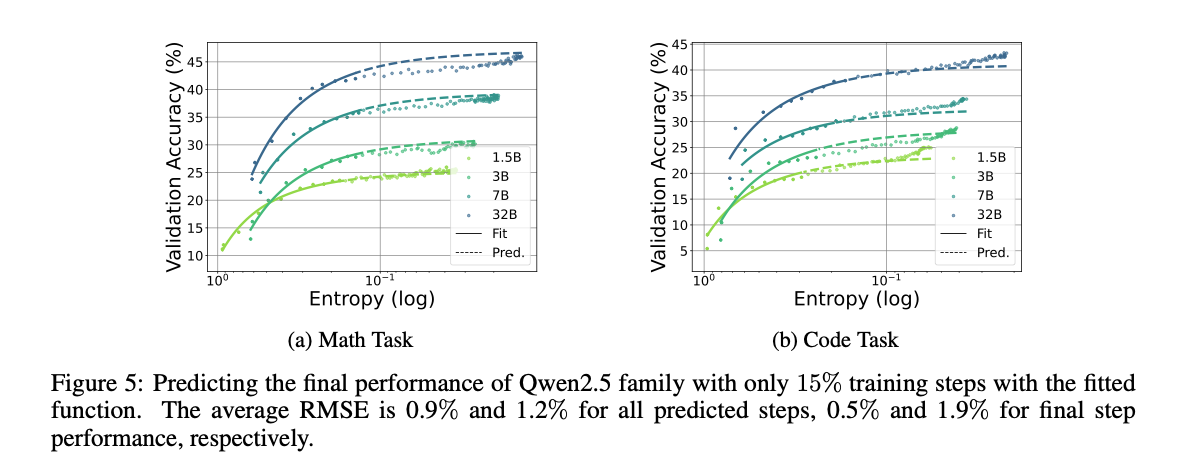
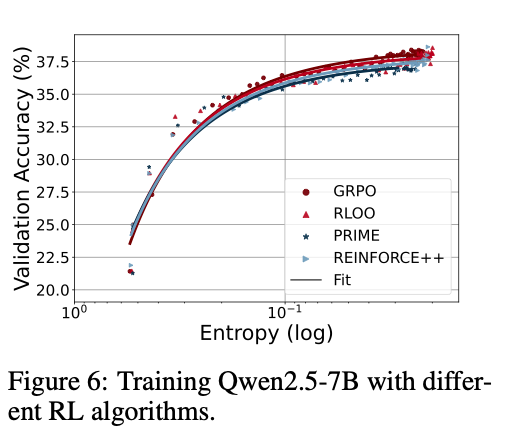
熵性能曲线和RL算法无关,不同算法结果类似。
熵变化和协方差有关系
熵变化与协方差 有关系。协方差理解
动作的对数概率和对应的logit变化对数概率/自信程度:生成某个词的概率,值越大,模型越确定logit变化/信念增强程度:模型得到奖励BP后,对这个动作的增强程度。 同时很高时,协方差为正、很大。 继续强化这个动作,排除掉其他可能性,导致熵急剧下降。高协方差有害
高协方差 导致了熵急剧下降,对ScaleRL非常有害。熵的Token变化关系
高优势高概率 Token:协方差大,降低熵
高优势低概率 Token:协方差低,增加熵
Softmax 动作a概率
选择动作a的logit熵变化
熵变化≈对数概率和logits变化之间的负协方差。对动作a的初始信息负对数概率,范围[0, 1],概率越大,确定性越大,随机性越小。动作a的logit在更新后的变化量,对a信息的增强或减弱。增加负号结论
高概率、高优势 token,导致高协方差,会降低熵。协方差越高、熵下降越快。动作概率和动作优势呈强烈正相关,是导致策略熵下降的根本原因。实验结论
协方差越高、熵下降越快。难度大的样本,协方差更低,有助于熵;难度低的样本,协方差高。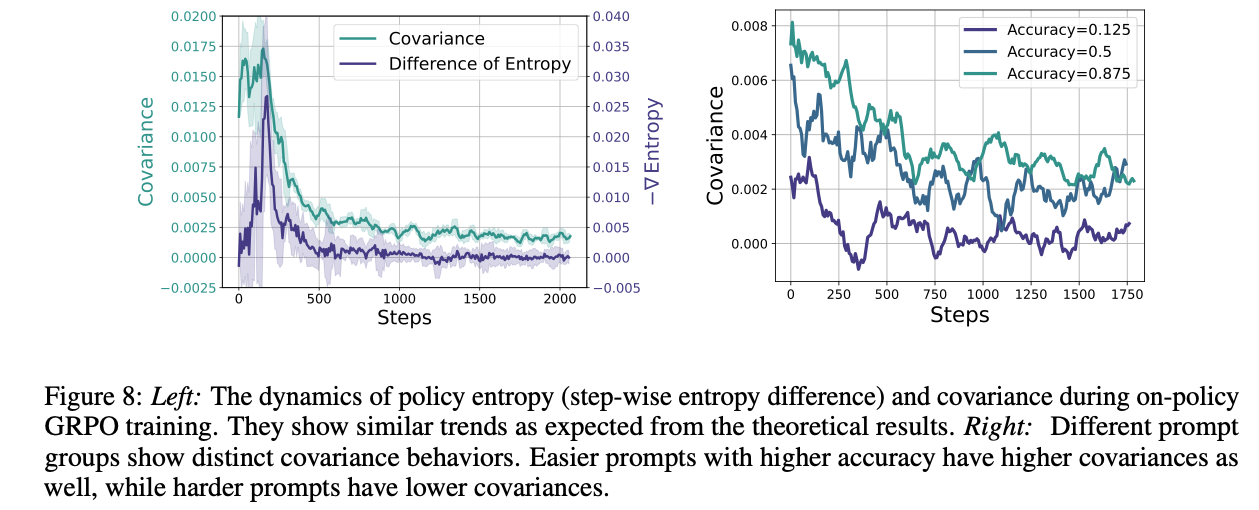
普通策略梯度
logit会被当前动作的概率 缩放自然策略梯度
把logit的变化和优势联系起来,导致缩放项消失了。不管动作初始概率是多少,更公平地对待所有动作的优势。| 特征 | 普通策略梯度 (VPG) | 自然策略梯度 (NPG) |
|---|---|---|
| 优化空间 | 参数空间 ( | 策略空间 (动作的概率分布) |
| 步长含义 | 在参数最陡峭的方向上迈出固定的一步。 | 在最优方向上产生一个固定大小的策略变化(KL散度)。 |
| Logit 变化 | ||
| 熵变化项 | ||
| 优点 | 实现简单。 | 更稳定,对参数化不敏感,能避免策略过早崩溃。 |
| 缺点 | 对参数化敏感,可能迈出毁灭性的大步。 | 计算昂贵(需要计算并求逆费雪矩阵)。 |
问题
熵坍塌,熵和协方差相关,熵正则无效。仅少量token 协方差特别大,导致熵崩溃。 核心思想
打击协方差特别大的token即可。协方差计算公式
背景
核心思想
选择一小部分高协方差token,在梯度更新中,分离并忽略掉他们的梯度 detach()筛选过程
计算每个token的协方差
设置协方差筛选范围上下限
筛选高协方差token:设置筛选比例
对高协方差token:一律detach 梯度,不做更新
背景
核心思想
施加KL惩罚,限制更新幅度不能太大。具体方法
从高到低排序,选择top-k比例的token增加KL惩罚,限制更新幅度Clip-Higher
Clip-Cov, KL-Cov
模型
Baseline
GRPO+Clip-Higher(0.28)任务
训练数据:DAPO-MATH-17K
评测数据:MATH500, AIME24, AIME25, AMC, Omini-Math, Olympiad-Bench, Minierva
超参
训练Rollout
评估
Clip-Cov
比例r:CLIP上下限 KL-Cov
top-k比例
max_generation_length = 8192
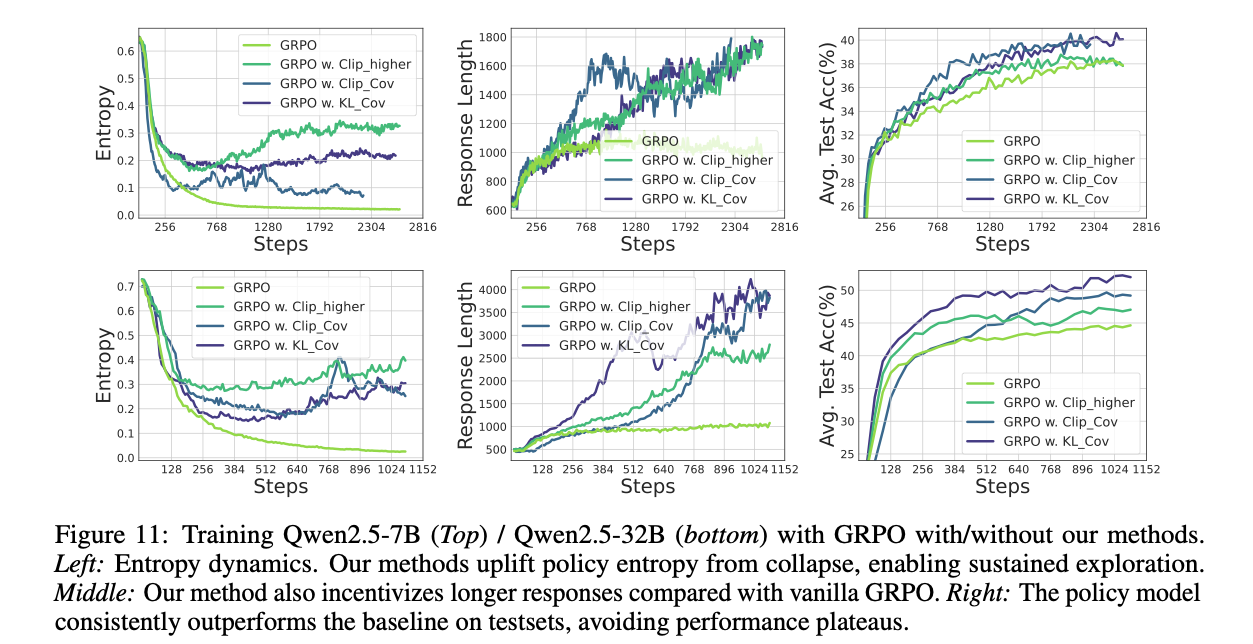
Clip-Cov和KL-Cov 效果好。7B平均提升2.0pt,32B提升6.4pt。高策略熵,实现了持续探索和学习。 持续稳定提升。大模型上效果更好,展现出良好的Scaling。 解除了探索限制,能更好释放大模型潜能。干预可控且高效。 熵崩溃是由少部分高优势高概率token引起的,是由少数点坍塌引发的连锁反应。 精准扶住关键点,就能稳住整个系统。熵和性能并非直接关系。 性能好
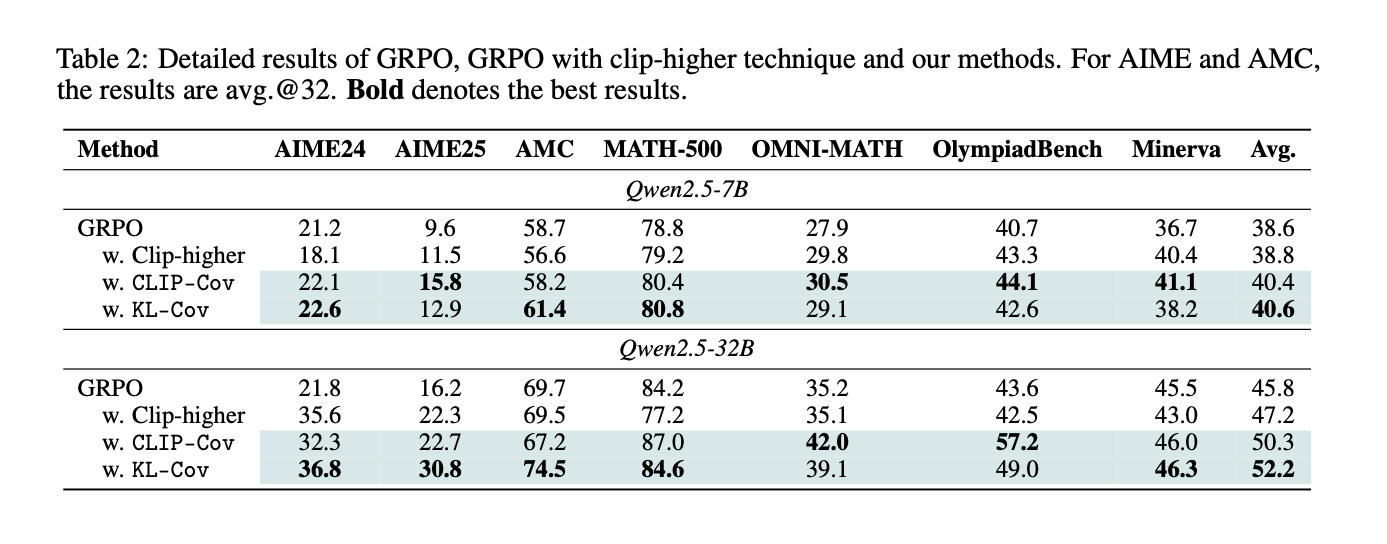
维持了高策略的熵,实现持续探索和学习。
⛳未来方向