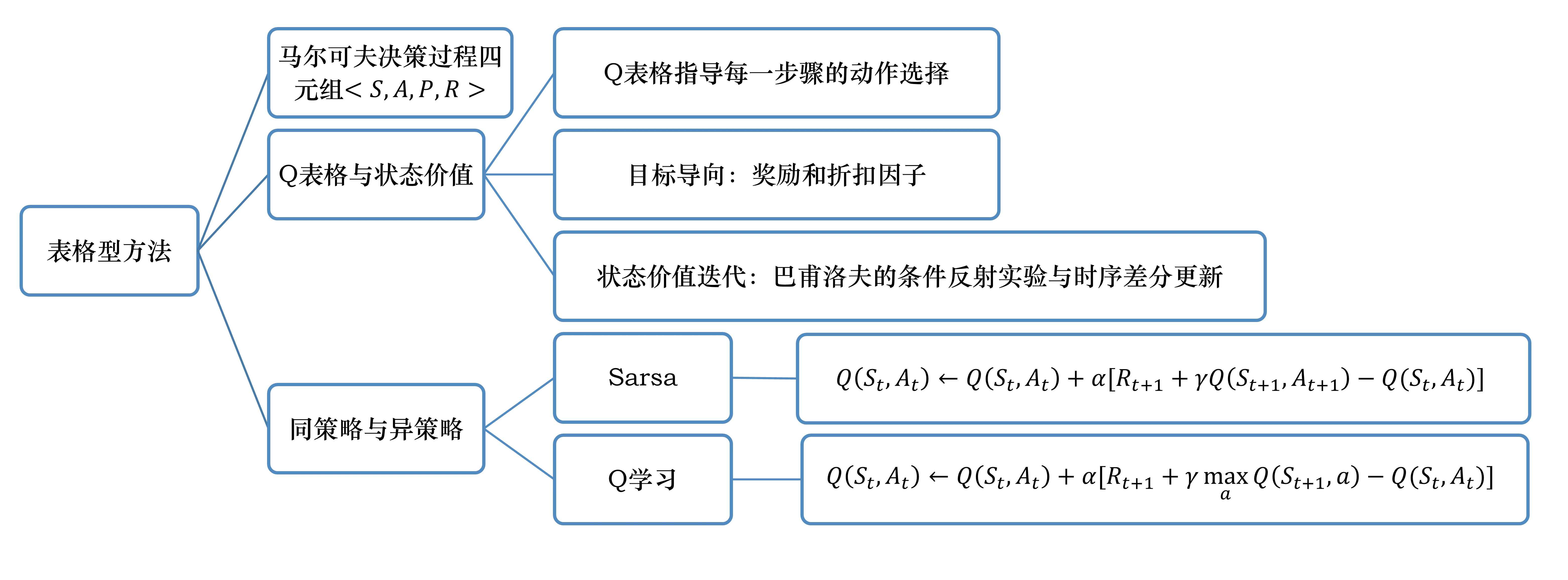
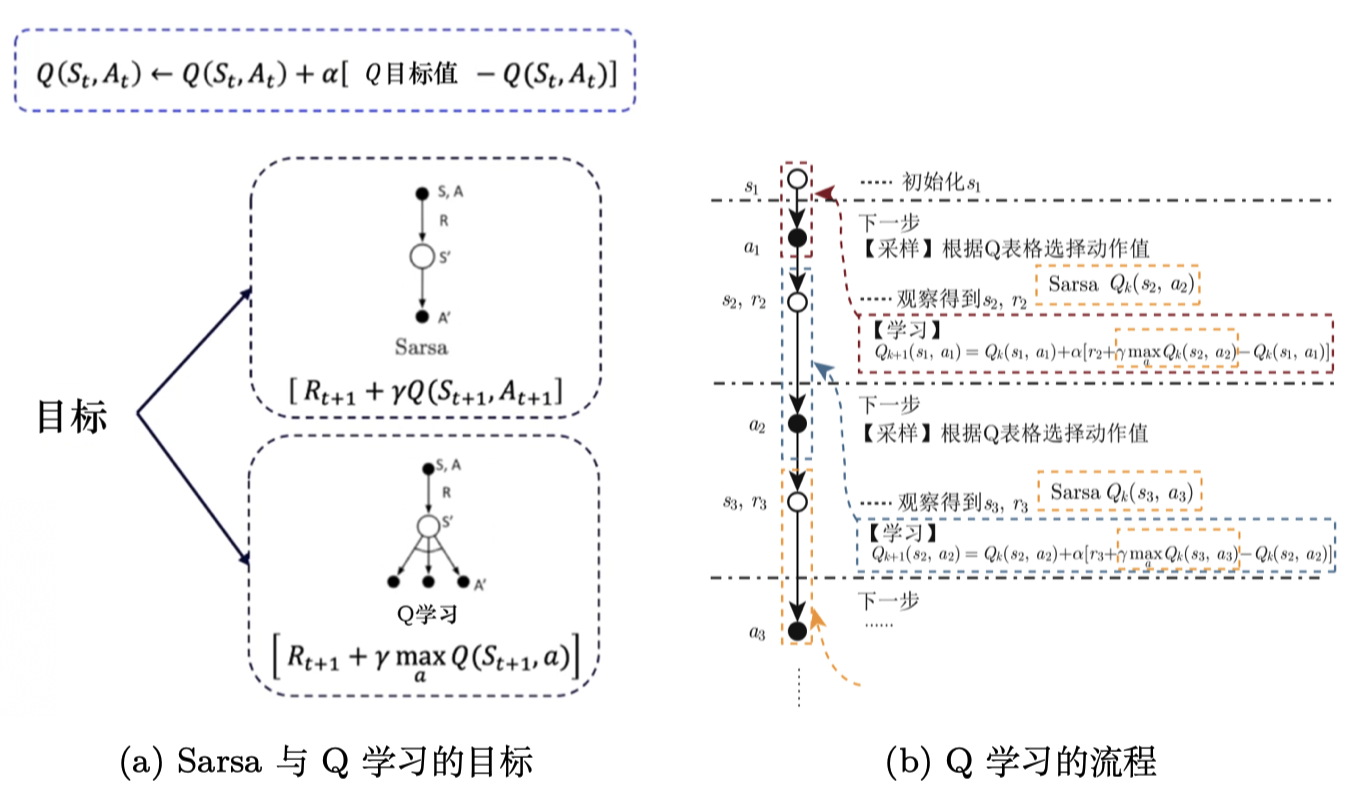
免模型预测和控制
📅 发表于 2025/08/28
🔄 更新于 2025/08/28
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
rl-theroy
#免模型
#免模型预测
#免模型控制
#蒙特卡洛
#时序差分
#λ-return算法
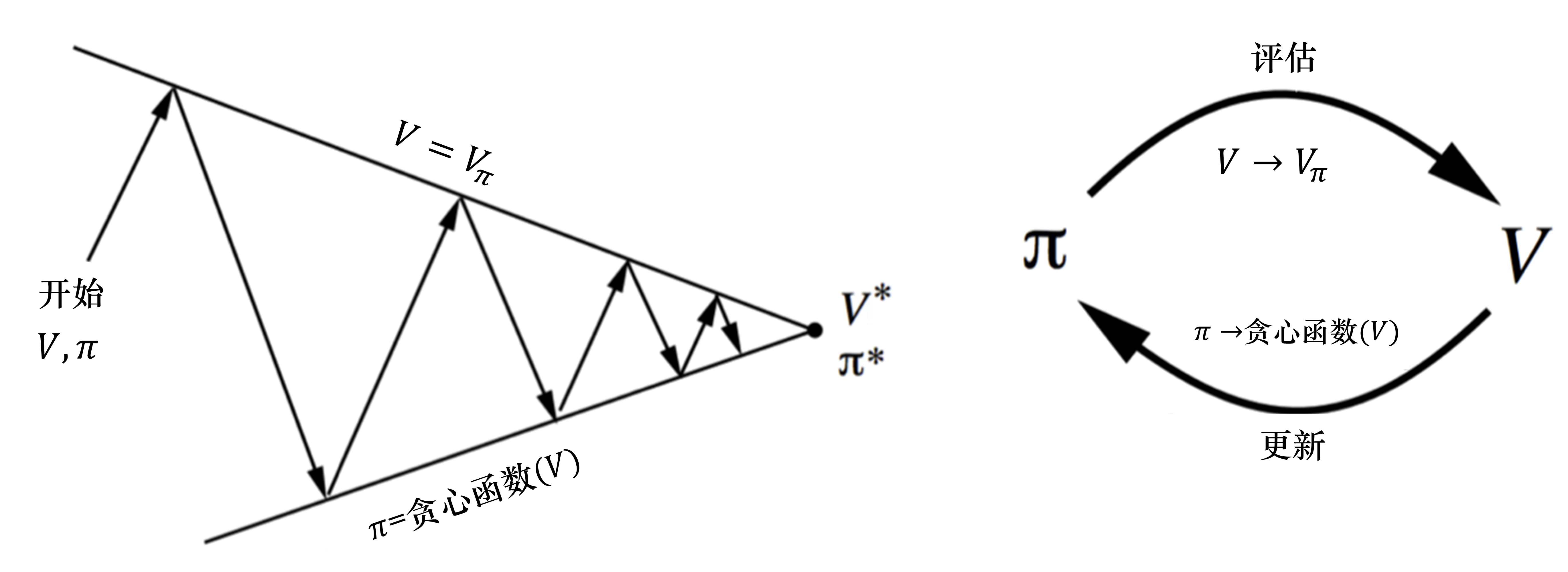
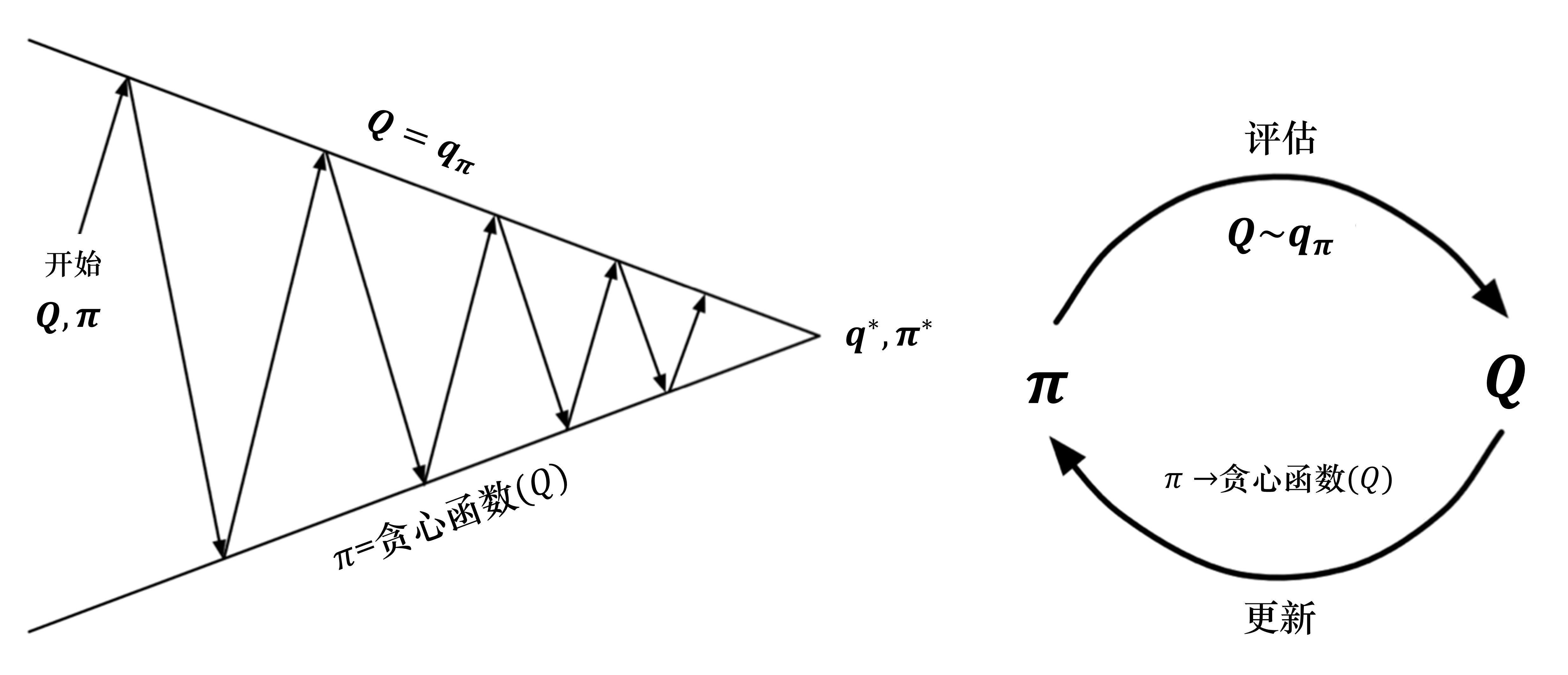
#狭义策略迭代
#广义策略迭代
#同策略
#异策略
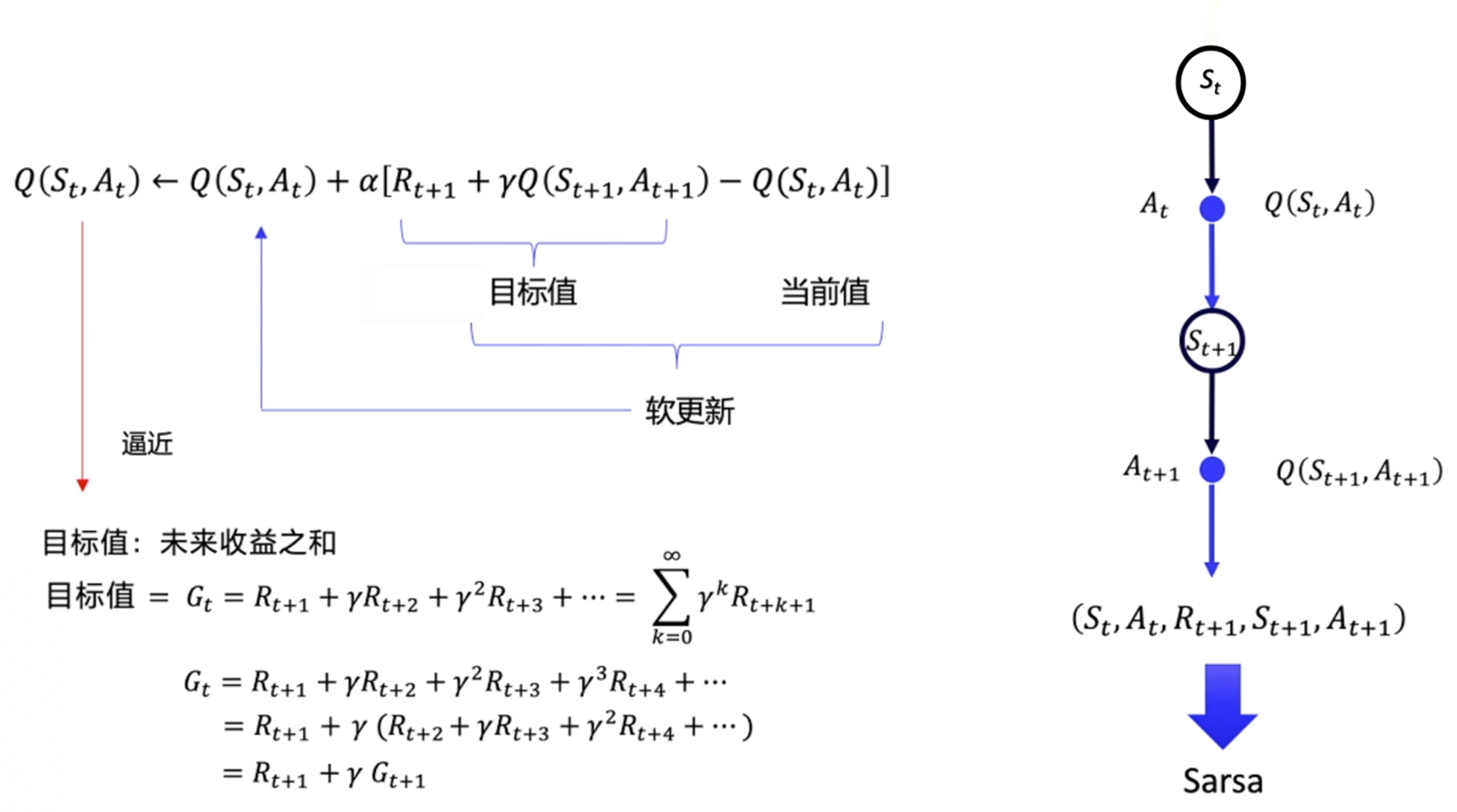
#Sarsa
#Q学习
#经验平均回报
#增量均值
#蒙特卡洛误差
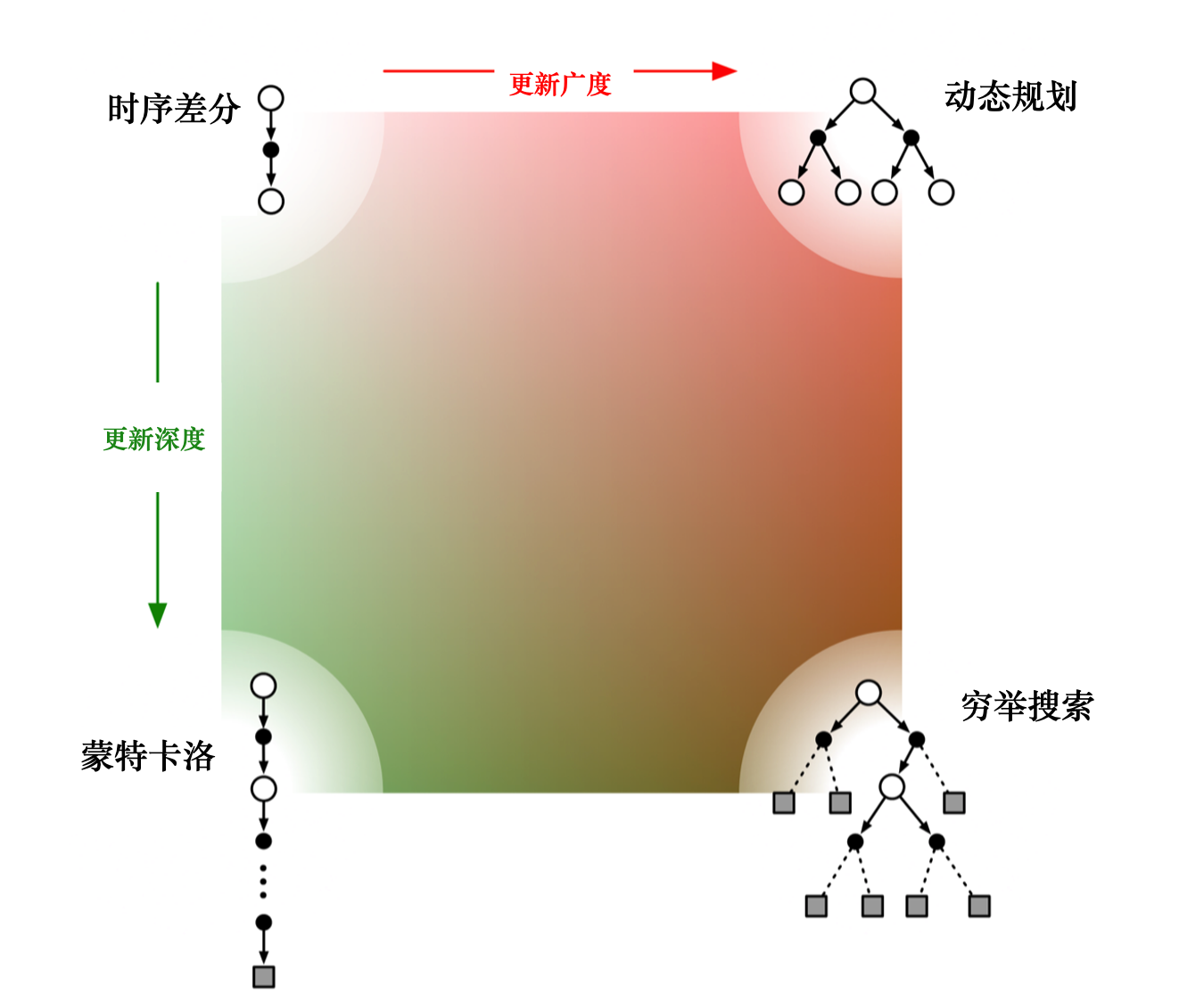
#动态规划
#自举
#采样
#强化
#单步时序差分
#n步时序差分,TD Error
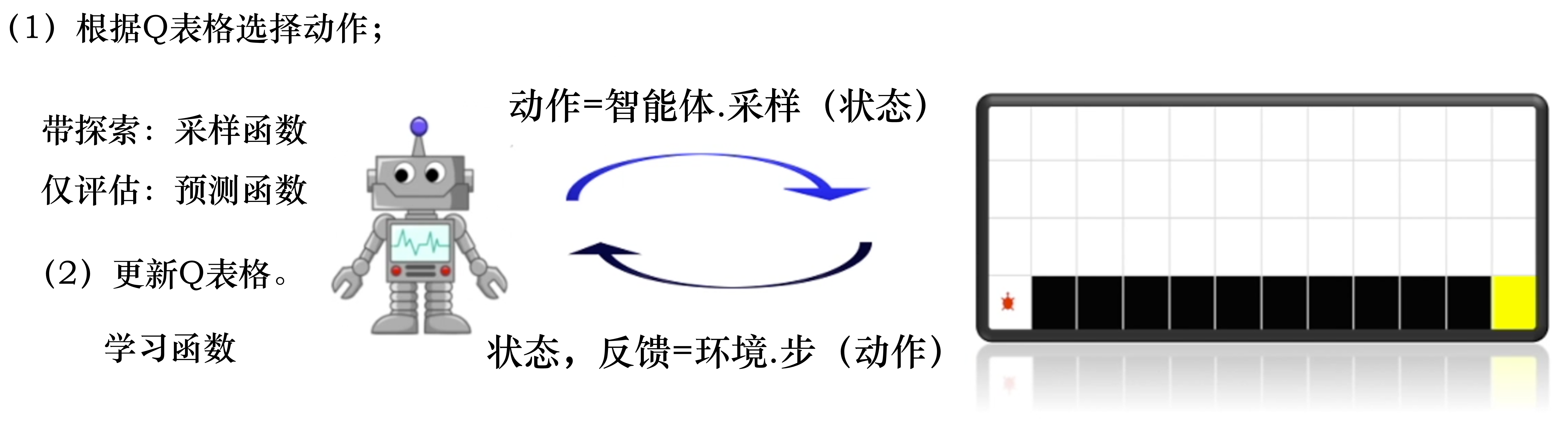
#e贪心策略
#行为策略
#目标策略
#Q函数估计