网络优化
📅 发表于 2018/03/30
🔄 更新于 2018/03/30
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
深度学习
#神经网络
#数据预处理
#归一化
#优化方法
#Adam
#动量法
#学习率
参数初始化、数据预处理、逐层归一化、各种优化方法、超参数优化。
任何数学技巧都不能弥补信息的缺失。本文介绍网络优化方法
神经网络有很强的表达能力。但有优化问题和泛化问题。主要通过优化和正则化来提升网络。
优化问题的难点
低维空间非凸优化:存在局部最优点,难在初始化参数和逃离局部最优点
高维空间非凸优化:难在如何逃离鞍点。 鞍点是梯度为0,但一些维度是最高点,另一些维度是最低点。
梯度下降法很难逃离鞍点。
梯度下降法面临的问题
神经网络拟合能力很强,容易过拟合。解决过拟合的5个方法
全0产生的对称权重问题
参数千万不能全0初始化。如果全0初始化,会导致隐层神经元激活值都相同,导致深层神经元没有区分性。这就是对称权重现象。
通俗点:
应该对每个参数随机初始化,打破这个对称权重现象,使得不同神经元之间区分性更好。
参数区间的选择
参数太小时
使得Sigmoid激活函数丢失非线性的能力。在0附近近似线性,多层神经网络的优势也不存在。
参数太大时
Sigmoid的输入会变得很大,输出接近1。梯度直接等于0。
选择一个合适的初始化区间非常重要。如果,一个神经元输入连接很多,那么每个输入连接上的权值就应该小一些。
高斯分布也就是正态分布。
初始化一个深度网络,比较好的方案是保持每个神经元输入的方差为一个常量。
如果神经元输入是
在
会自动计算超参数
设
logsitic激活函数 :tanh激活函数: 为了避免初始化参数使得激活值变得饱和,尽量使
假设
输入信号经过该神经元后,被放大或缩小了
为了使输入信号经过多层网络后,不被过分放大或过分缩小,应该使
综合前向和后向,使信号在前向和反向传播中都不被放大或缩小,综合设置方差:
每一维的特征的来源和度量单位不同,导致特征分布不同。
未归一化数据的3个坏处
未归一化对梯度下降的影响
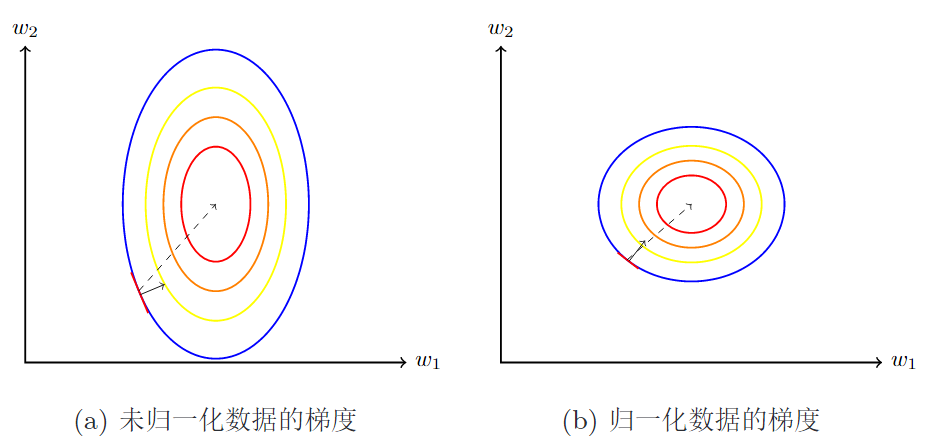
归一化要做的事情
实际上是由中心化和标准化结合的。 把数据归一化到标准正态分布。
计算均值和方差
归一化数据,减均值除以标准差。如果
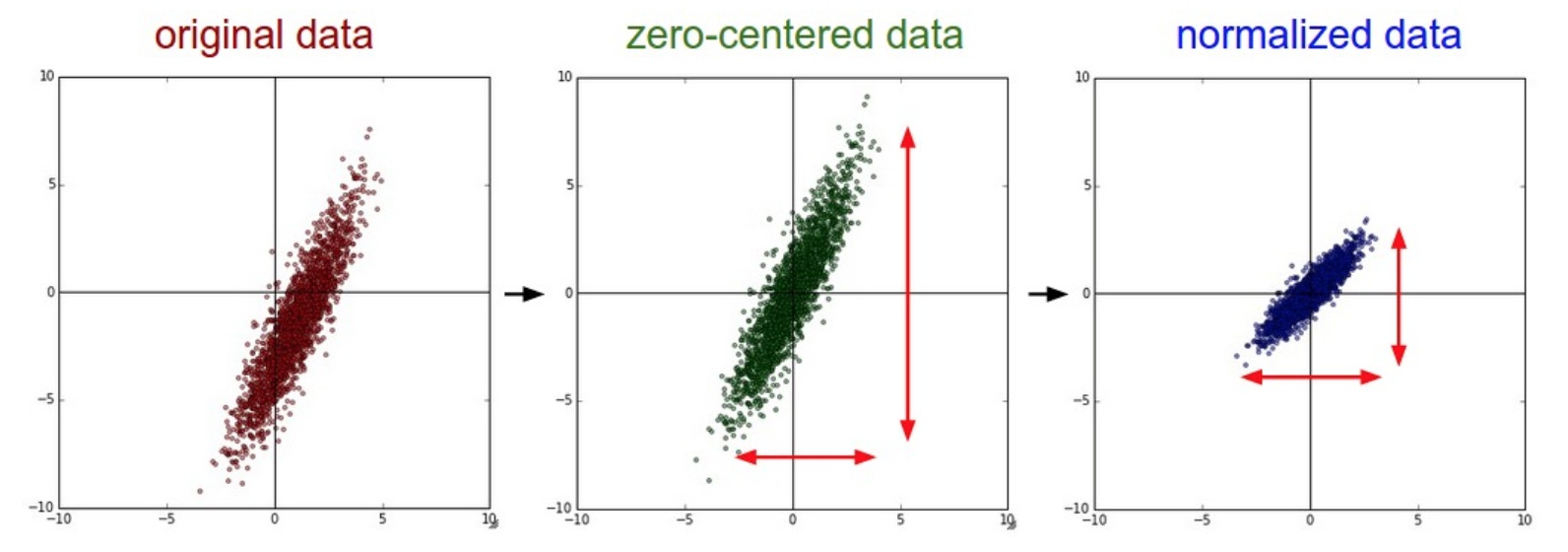
把数据归一化到
白化用来降低输入数据特征之间的冗余性。白化主要使用PCA来去掉特征之间的相关性。我的白化笔记
处理后的数据
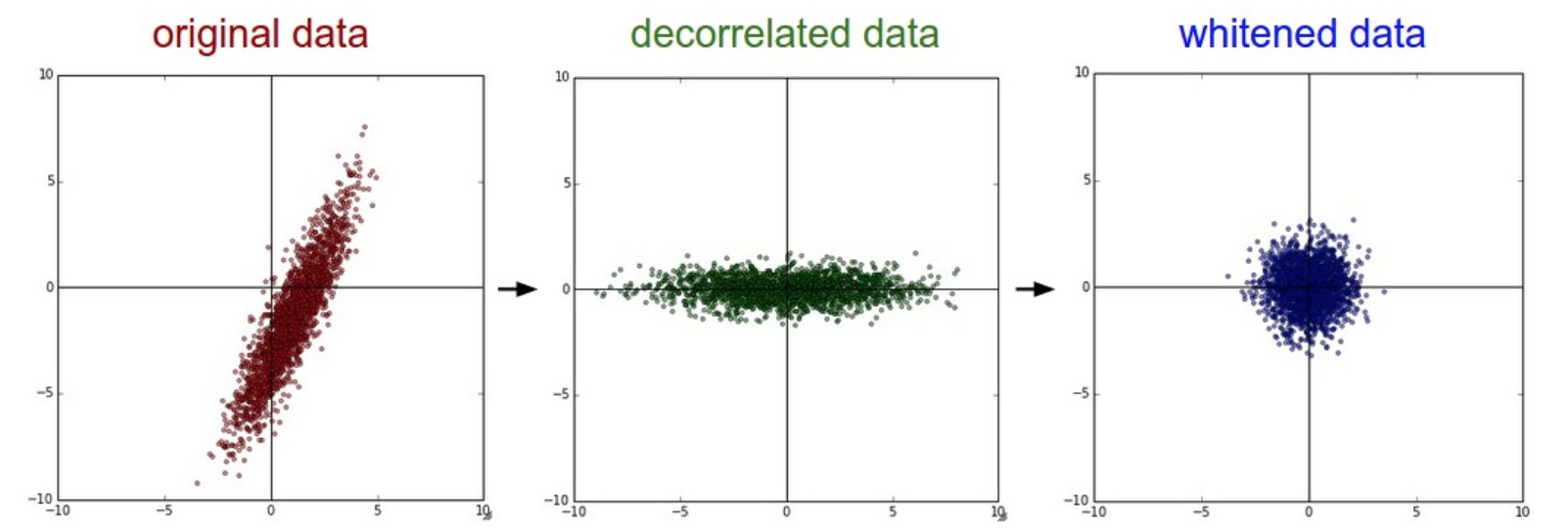
白化的缺点
可能会夸大数据中的噪声。所有维度都拉到了相同的数值范围。可能有一些差异性小、但大多数是噪声的维度。可以使用平滑来解决。
深层神经网络,中间层的输入是上一层的输出。每次SGD参数更新,都会导致每一层的输入分布发生改变。
像高楼,低楼层发生较小偏移,就会导致高楼层发生较大偏移。
如果某个层的输入发生改变,其参数就需要重新学习,这也是内部协变量偏移问题。
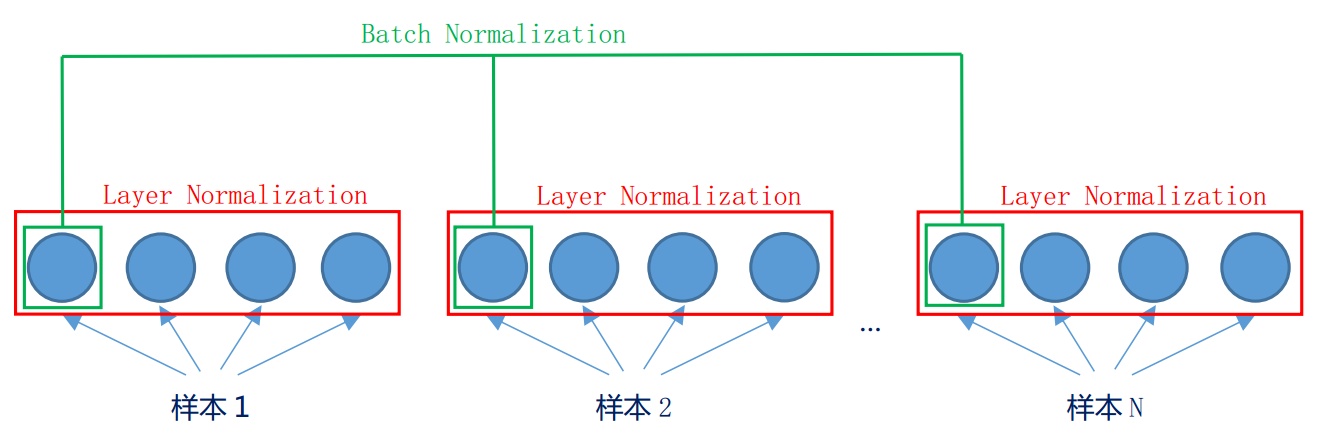
在训练过程中,要使得每一层的输入分布保持一致。简单点,对每一个神经层进行归一化。
针对每一个维度,对每个batch的数据进行归一化+缩放平移。
批量归一化Batch Normalization ,我的BN详细笔记。 对每一层(单个神经元)的输入进行归一化
缩放参数平移参数
注意:
对每个样本,对所有维度做一个归一化,即对同层的所有神经元的输入做归一化。
层归一化是对一个中间层的所有神经元进行归一化设第均值和方差
层归一化 如下,其中
层归一化的RNN
RNN的净输入一般会随着时间慢慢变大或变小,导致梯度爆炸或消失。
层归一化的RNN可以有效缓解梯度消失和梯度爆炸。
思想类似,都是标准归一化 + 缩放和平移。
权重归一化
对神经网络的连接权重进行归一化。
局部相应归一化
对同层的神经元进行归一化。但是局部响应归一化,用在激活函数之后,对邻近的神经元进行局部归一化。
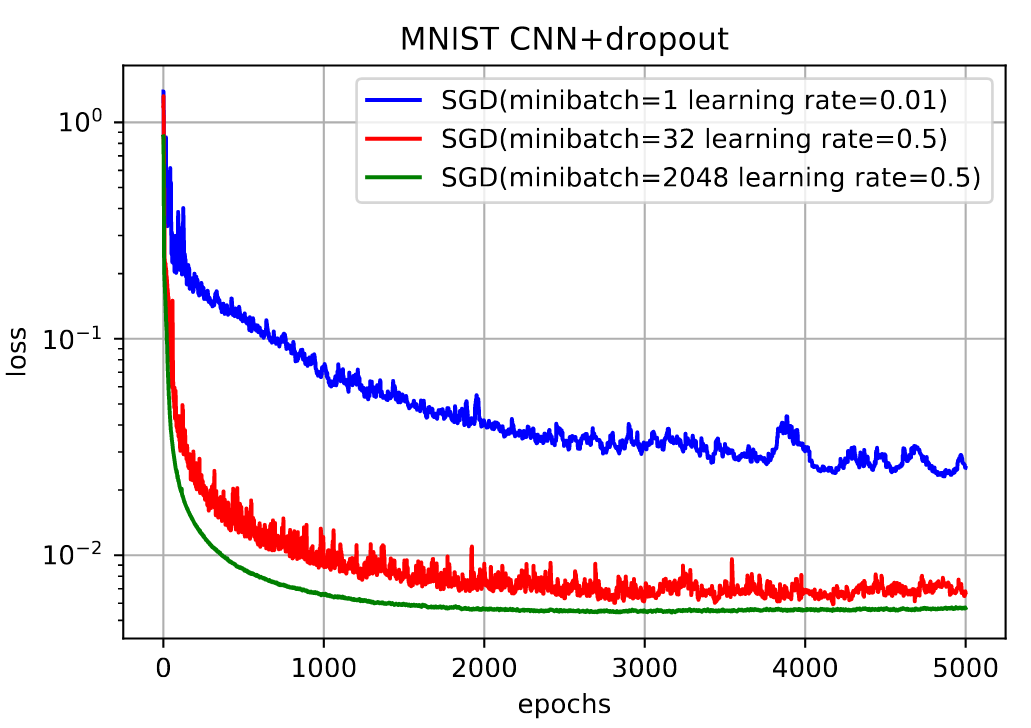
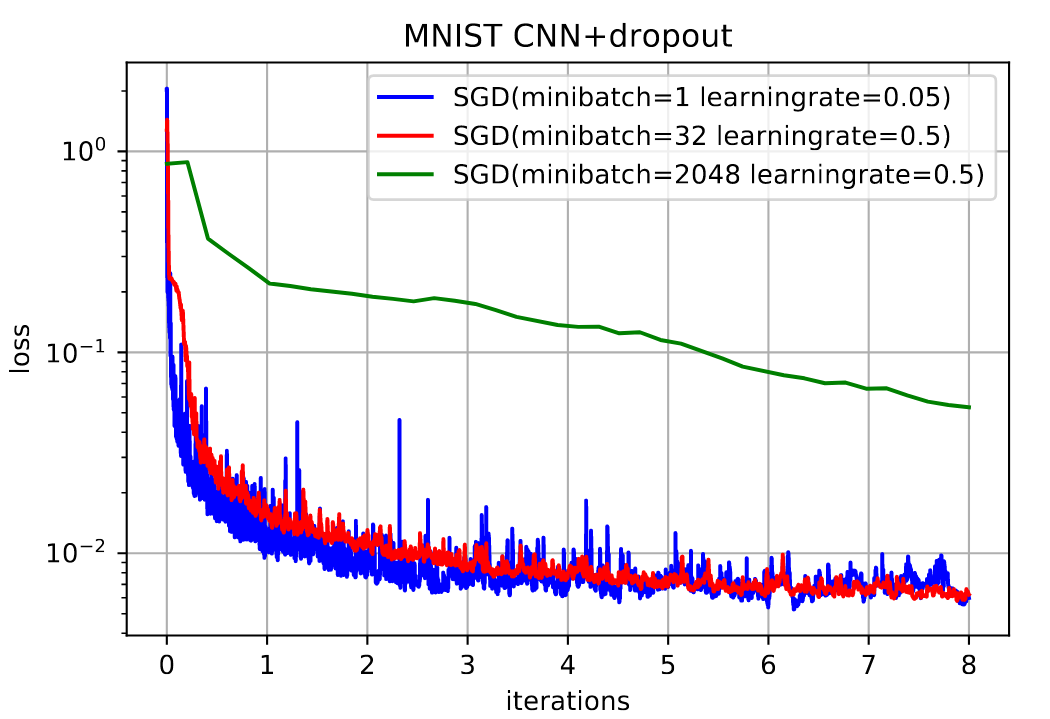
Mini-Batch梯度下降法。设
在第
更新参数,其中学习率
1. BGD
Batch Gradient Descent
意义:每一轮选择所有整个数据集去计算梯度更新参数
优点
缺点
2. SGD
Stochastic Gradient Descent
意义:每轮值选择一条数据去计算梯度更新参数
优点
缺点
3. Mini-BGD
Mini-Batch Gradient Descent
意义: 每次迭代只计算一个mini-batch的梯度去更新参数
优点
缺点
4. 梯度下降法的难点
主要通过学习率递减和动量法来优化梯度下降法。
可以看出
0 指数加权平均
求10天的平均温度,可以直接利用平均数求,每天的权值是一样的,且要保存所有的数值才能计算。
设
则有指数加权平均:
离当前越近,权值越大。越远,权值越小(指数递减),也有一定权值。
1. 按迭代次数递减
设置
反时衰减
指数衰减 :
自然指数衰减
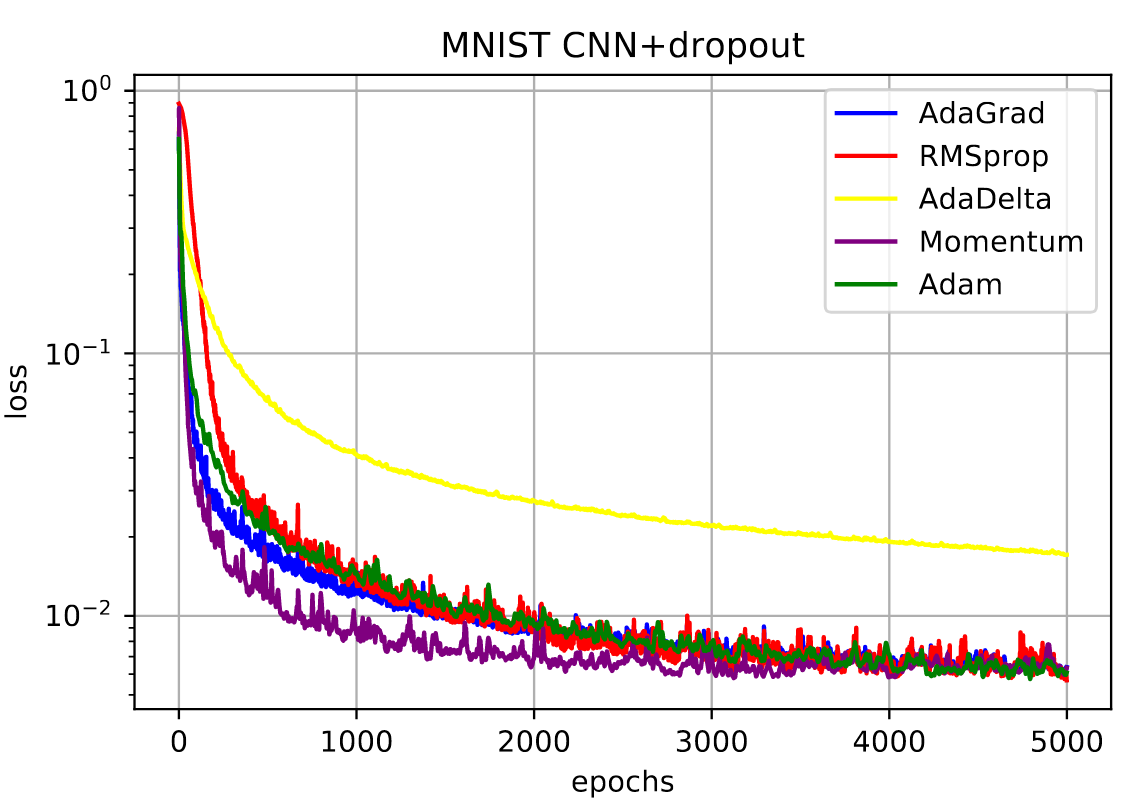
2. AdaGrad
Adaptive Gradient
意义:每次迭代时,根据历史梯度累积量来减小学习率,减小梯度。梯度平方的累计值来减小梯度
初始学习率
优点
缺点
3. RMSprop
意义:计算梯度指数递减移动平均, 即梯度平方的平均值来减小梯度
优点
缺点
4. AdaDelta
意义 不初始化学习率。计算梯度更新差平方的指数衰减移动平均来作为分子学习率,
优点
结合前面更新的方向和当前batch的方向,来更新参数。
解决了MBGD的不稳定性,增加了稳定性。可以加速或者减速。
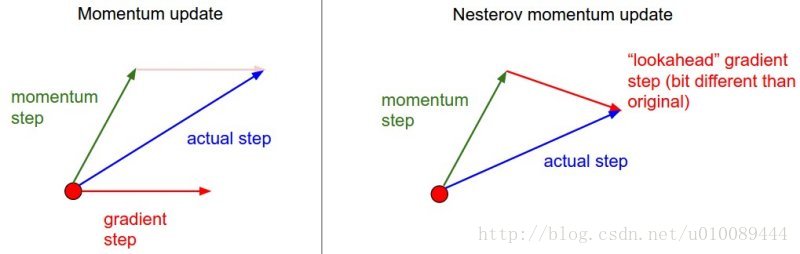
1. 普通动量法
设移动加权平均
当前梯度与最近时刻的梯度方向:
优点:
当前梯度叠加上上次的梯度,可以近似地看成二阶梯度。
Adaptive Momentum Estimation = RMSProp + Momentum, 即自适应学习率+稳定性(动量法)。
意义:计算梯度动量),计算梯度平方自适应alpha)
设
优点
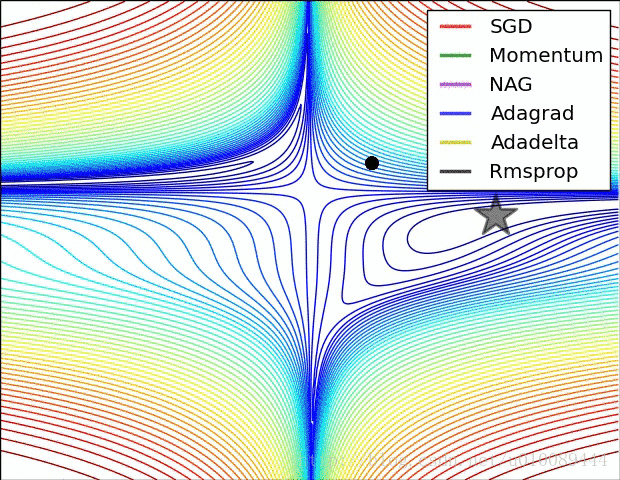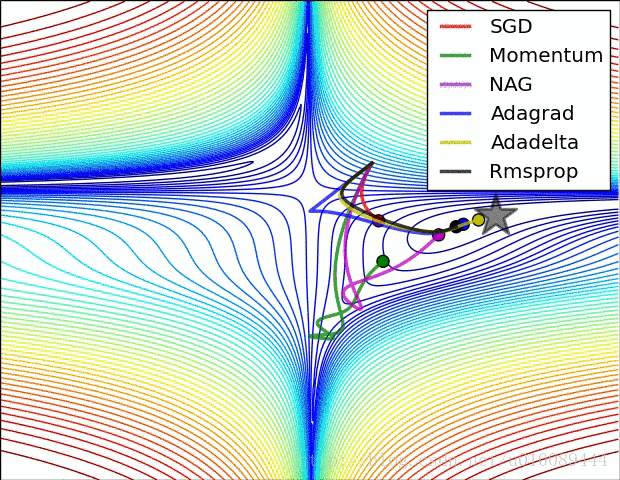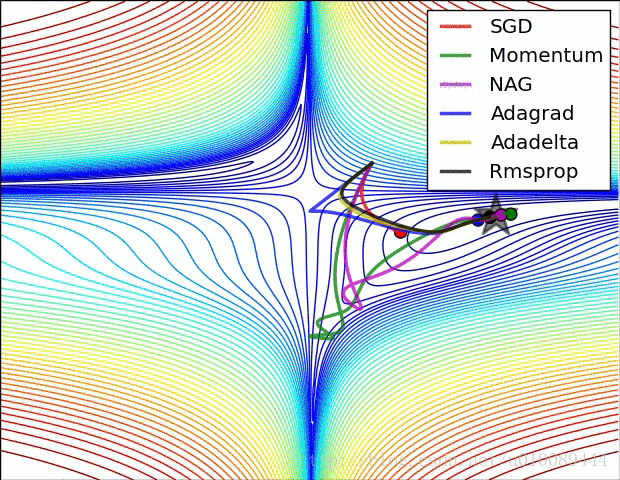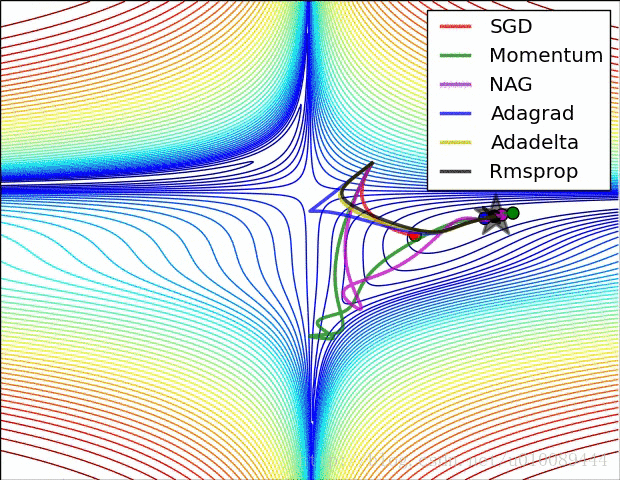
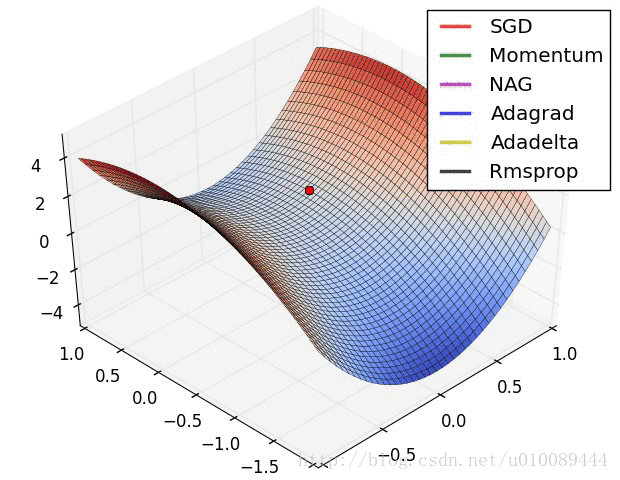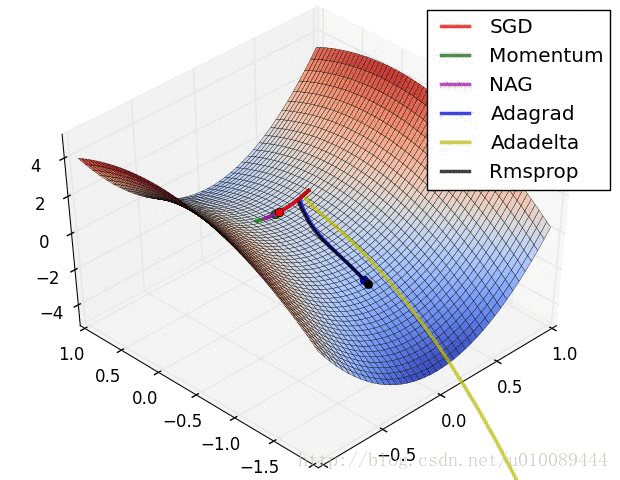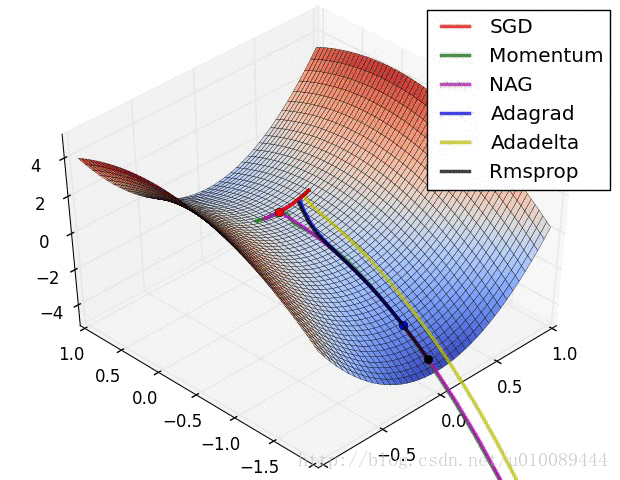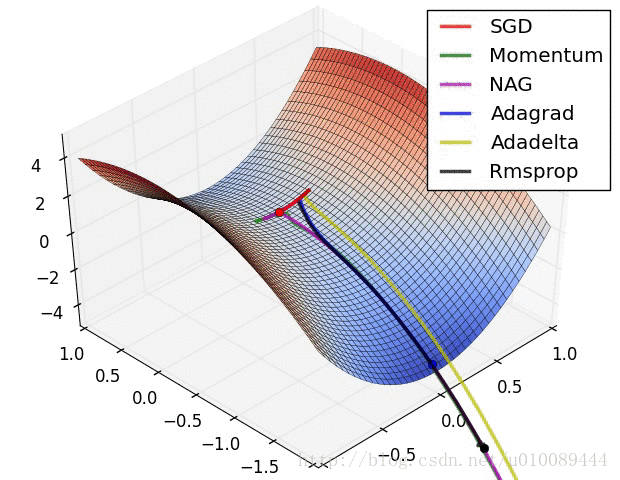
一般按模截断,如果
优化内容
优化难点
配置说明
超参数设置:人工搜索、网格搜索、随机搜索。
缺点:没有利用到不同超参数组合之间的相关性,搜索方式都比较低效。
1. 网格搜索
对于
如果超参数是连续的,可以根据经验选择一些经验值,比如学习率
对这些超参数的不同组合,分别训练一个模型,测试在开发集上的性能。选取一组性能最好的配置。
2. 随机搜索
有的超参数对模型影响力有限(正则化),有的超参数对模型性能影响比较大。网格搜索会遍历所有的可能性。
随机搜索:对超参数进行随机组合,选择一个性能最好的配置。
优点:比网格搜索好,更容易实现,更有效。
根据当前已经试验的超参数组合,来预测下一个可能带来的最大收益的组合。
贝叶斯优化过程:根据已有的N组试验结果来建立高斯过程,计算
在早期阶段,估计出一组配置的效果会比较差,则中止这组配置的评估。把更多的资源留给其他配置。
这是多臂赌博机的泛化问题:最优赌博机。在给定有限次数的情况下,玩赌博机,找到收益最大的臂。
通过神经网络来自动实现网络架构的设计。