cs224n的笔记,过拟合、预处理、初始化、Batch Normalization
过拟合
过拟合
训练数据很少,或者训练次数很多,会导致过拟合。避免过拟合的方法有如下几种:
- early stop
- 数据集扩增
- 正则化 (L1, L2权重衰减)
- Dropout
- 决策树剪枝(尽管不属于神经网络)
现在一般用L2正则化+Dropout。
过拟合时,拟合系数一般都很大。过拟合需要顾及到所有的数据点,意味着拟合函数波动很大。
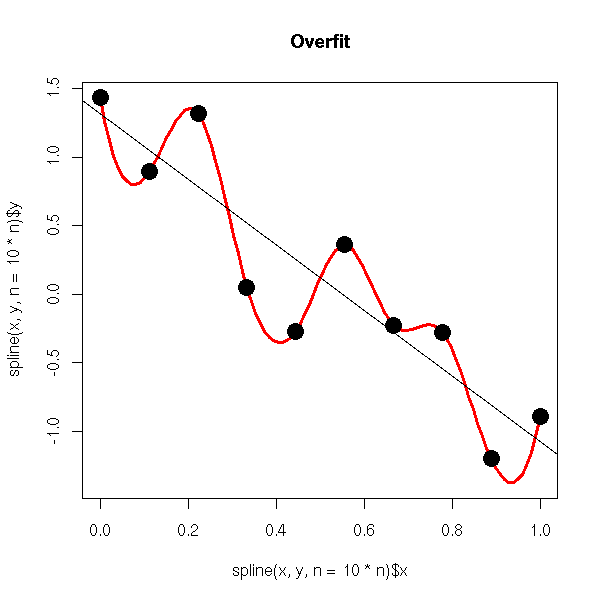
看到,在某些很小的区间内里,函数值的变化很剧烈。意味着这些小区间的导数值(绝对值)非常大。由于自变量值可大可小,所以只有系数足够大,才能保证导数值足够大。
所以:过拟合时,参数一般都很大。参数较小时,意味着模型复杂度更低,对数据的拟合刚刚好, 这也是奥卡姆剃刀法则。
范数
向量范数
\(x \in \mathbb {R}^d\)
| 范数 | 定义 |
|---|---|
| 1-范数 | \(\left \| x\right\|_1 = \sum_i^d \|x_i\|\), 绝对值之和 |
| 2-范数 | \(\left \| x\right\|_2 = \left(\sum_i^d \vert x_i\vert^2\right)^{\frac{1}{2}}\), 绝对值平方之和再开方 |
| p-范数 | \(\left \| x\right\|_p = \left(\sum_i^d \|x_i\|^p\right)^{\frac{1}{p}}\), 绝对值的p次方之和的\(\frac{1}{p}\)次幂 |
| \(\infty\)-范数 | \(\left \| x\right\|_\infty = \max_\limits i \|x_i\|\) ,绝对值的最大值 |
| -\(\infty\)-范数 | \(\left \| x\right\|_{-\infty} = \min_\limits i \|x_i\|\) ,绝对值的最小值 |
矩阵范数
\(A \in \mathbb R^{m \times n}\)
| 范数 | 定义 |
|---|---|
| 1-范数 | \(\left \| A\right\|_1 = \max \limits_{j}\sum_i^m \|a_{ij}\|\),列和范数,矩阵列向量绝对值之和的最大值。 |
| \(\infty\)-范数 | \(\left \| A\right\|_\infty = \max_\limits i \sum_{j}^{n}\|a_{ij}\|\) ,行和范数,所有行向量绝对值之和的最大值。 |
| 2-范数 | \(\left \| A\right\|_2 = \sqrt{\lambda_{m}}\) , 其中\(\lambda_m\)是\(A^TA\)的最大特征值。 |
| F-范数 | \(\left \| A\right\|_F = \left(\sum_i^m \sum_j^n a_{ij}^2\right)^{\frac{1}{2}}\),所有元素的平方之和,再开方。或者不开方, L2正则化就直接平方,不开方。 |
L2正则化权重衰减
为了避免过拟合,使用L2正则化参数。\(\lambda\)是正则项系数,用来权衡正则项和默认损失的比重。\(\lambda\) 的选取很重要。 \[ J_R = J + \lambda \sum_{i=1}^L \left \| W^{(i)}\right \|_F \] L2惩罚更倾向于更小更分散的权重向量,鼓励使用所有维度的特征,而不是只依赖其中的几个,这也避免了过拟合。
标准L2正则化
\(\lambda\) 是正则项系数,\(n\)是数据数量,\(w\)是模型的参数。 \[
C = C_0 + \frac {\lambda} {2n} \sum_w w^2
\] \(C\)对参数\(w\)和\(b\)的偏导: \[
\begin {align}
& \frac{\partial C}{\partial w} = \frac{\partial C_0}{\partial w} + \frac{\lambda}{n} w \\
& \frac{\partial C}{\partial b} = \frac{\partial C_0}{\partial b} \\
\end{align}
\] 更新参数 :可以看出,正则化\(C\)对\(w\)有影响,对\(b\)无影响。
\[
\begin{align}
w
&= w - \alpha \cdot \frac{\partial C}{\partial w} \\
&= (1 - \frac{\alpha \lambda}{n})w - \alpha \frac{\partial C_0}{\partial w} \\
\end{align}
\] 从上式可以看出:
- 不使用正则化时,\(w\)的系数是1
- 使用正则化时
- \(w\)的系数是\(1 - \frac{\alpha \lambda}{n} < 1\) ,效果是减小\(w\), 所以是权重衰减
weight decay - 当然,\(w\)具体增大或减小,还取决于后面的导数项
mini-batch随机梯度下降
设\(m\) 是这个batch的样本个数,有更新参数如下,即求batch个C对w的平均偏导值 \[ \begin {align} & w = (1 - \frac{\alpha \lambda}{n})w - \frac{\alpha}{m} \cdot \sum_{i=1}^{m}\frac{\partial C_i}{\partial w} \\ & b = b - \frac{\alpha}{m} \cdot \sum_{i=1}^{m}\frac{\partial C_i}{\partial b} \\ \end{align} \] 所以,权重衰减后一般可以减小过拟合。 L2正则化比L1正则化更加发散,权值也会被限制的更小。 一般使用L2正则化。
还有一种方法是最大范数限制:给范数一个上界\(\left \| w \right \| < c\) , 可以在学习率太高的时候网络不会爆炸,因为更新总是有界的。
实例说明
增加网络的层的数量和尺寸时,网络的容量上升,多个神经元一起合作,可以表达各种复杂的函数。
如下图,2分类问题,有噪声数据。
一个隐藏层。神经元数量分别是3、6、20。很明显20过拟合了,拟合了所有的数据。正则化就是处理过拟合的非常好的办法。
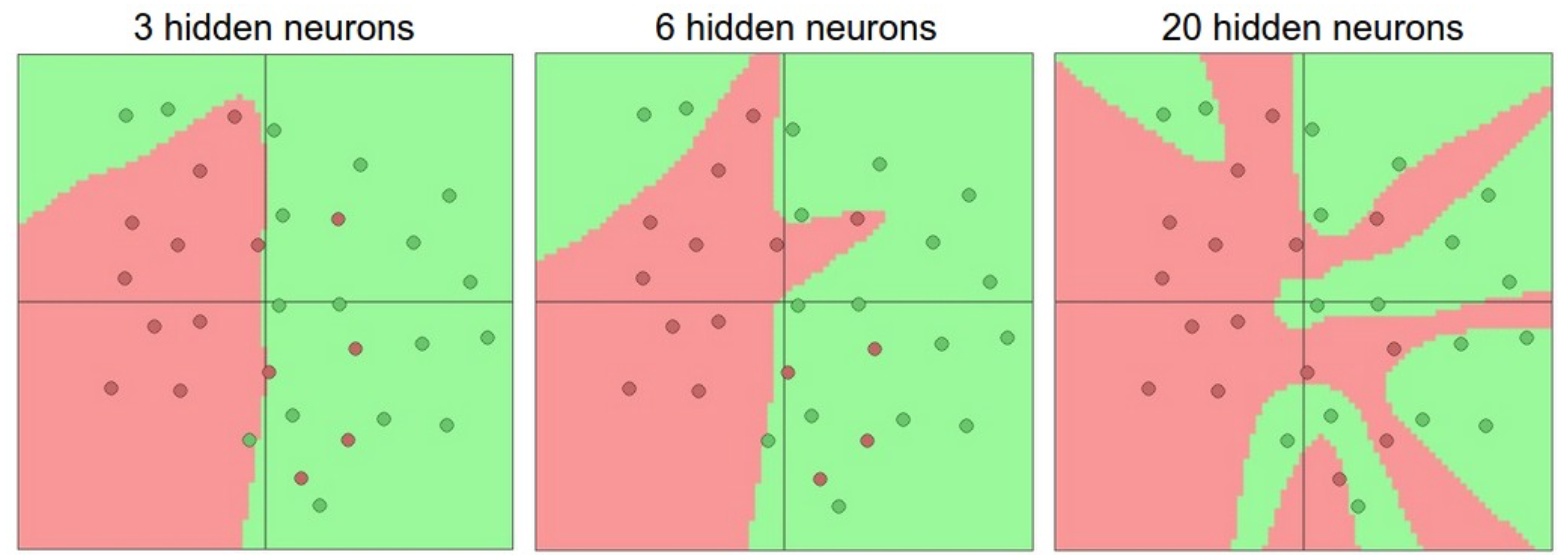
对20个神经元的网络,使用正则化,解决过拟合问题。正则化强度\(\lambda\)很重要。
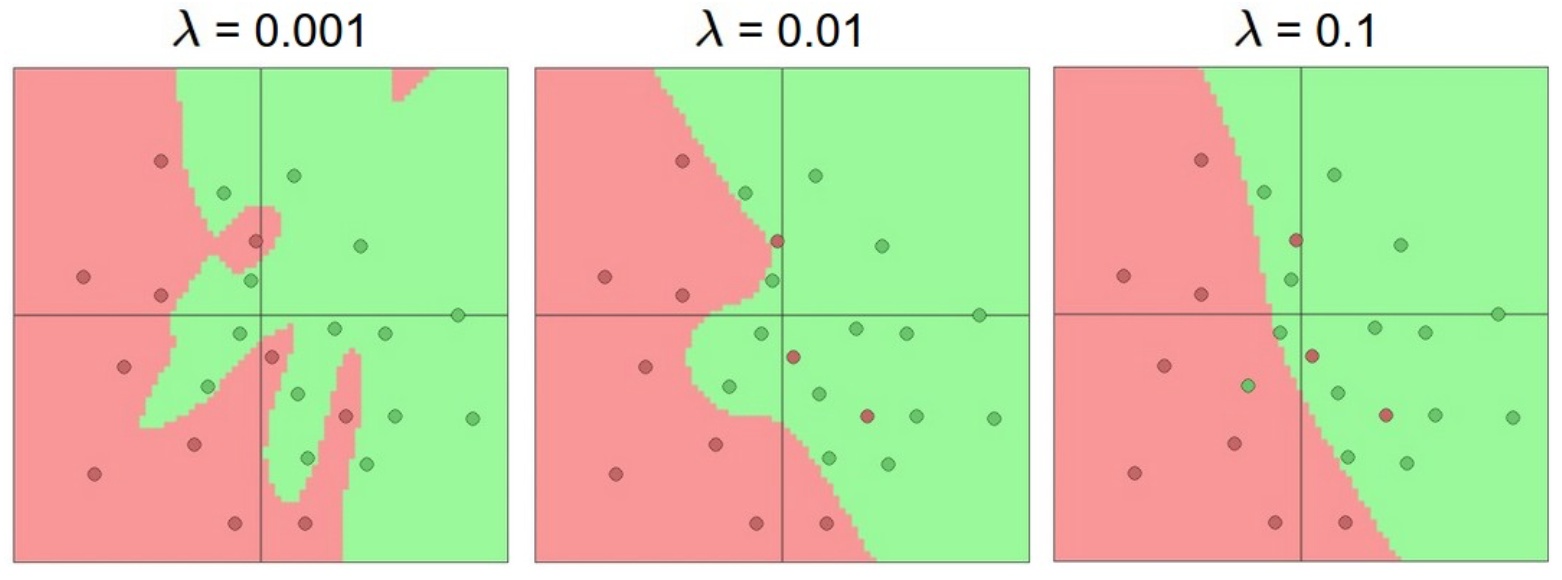
L1正则化
正则化loss如下: \[
C = C_0 + \frac {\lambda} {n} \sum_w |w|
\] 对\(w\)的偏导, 其中\(\rm{sgn}(w)\)是符号函数: \[
\frac{\partial C}{\partial w} = \frac{\partial C_0}{\partial w} + \frac{\lambda}{n} \cdot \rm{sgn}(w)
\] 更新参数: \[
w
= w - \frac{\alpha \lambda}{n} \cdot \rm{sgn}(w) - \alpha \frac{\partial C_0}{\partial w}
\] 分析:\(w\)为正,减小;\(w\)为负,增大。所以L1正则化就是使参数向0靠近,是权重尽可能为0,减小网络复杂度,防止过拟合。
特别地:当\(w=0\)时,不可导,就不要正则化项了。L1正则化更加稀疏。
随机失活Dropout
Dropout是非常有用的正则化的办法,它改变了网络结构。一般采用L2正则化+Dropout来防止过拟合。
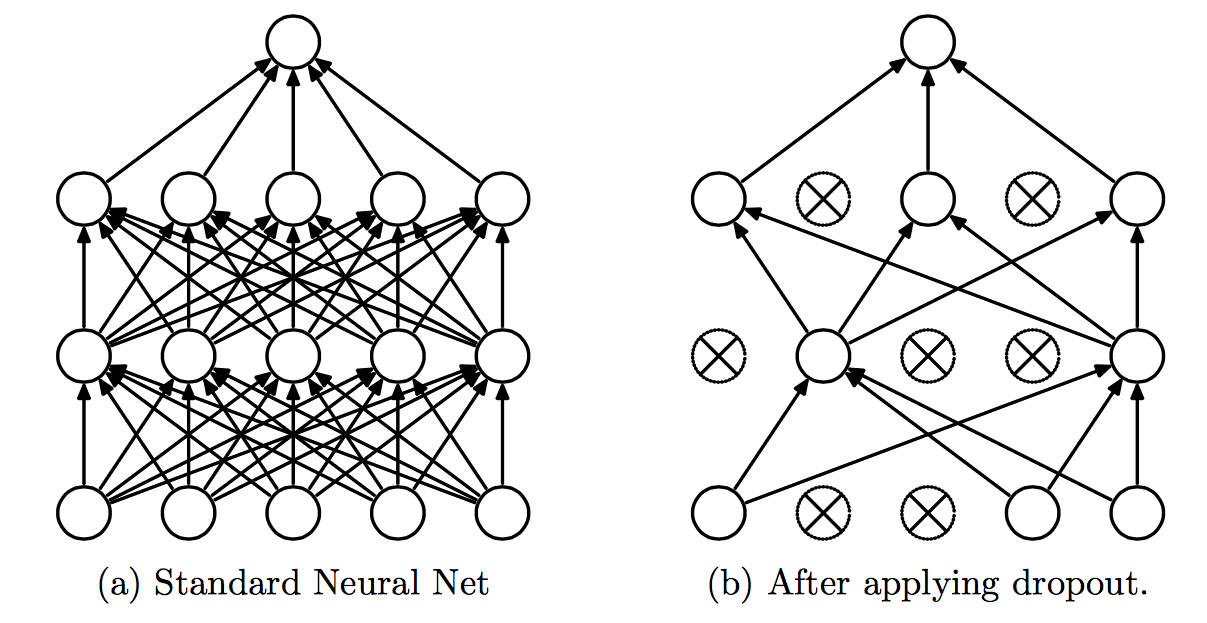
训练的时候,输出不变,随机以概率\(p\)保留神经元,\(1-p\)删除神经元(置位0)。每次迭代删除的神经元都不一样。
BP的时候,置位0的神经元的参数就不再更新, 只更新前向时alive的神经元。
预测的时候,要保留所有的神经元,即不使用Dropout。
相当于训练了很多个(指数级数量)小网络(半数网络),在预测的时候综合它们的结果。随着训练的进行,大部分的半数网络都可以给出正确的分类结果。
数据预处理
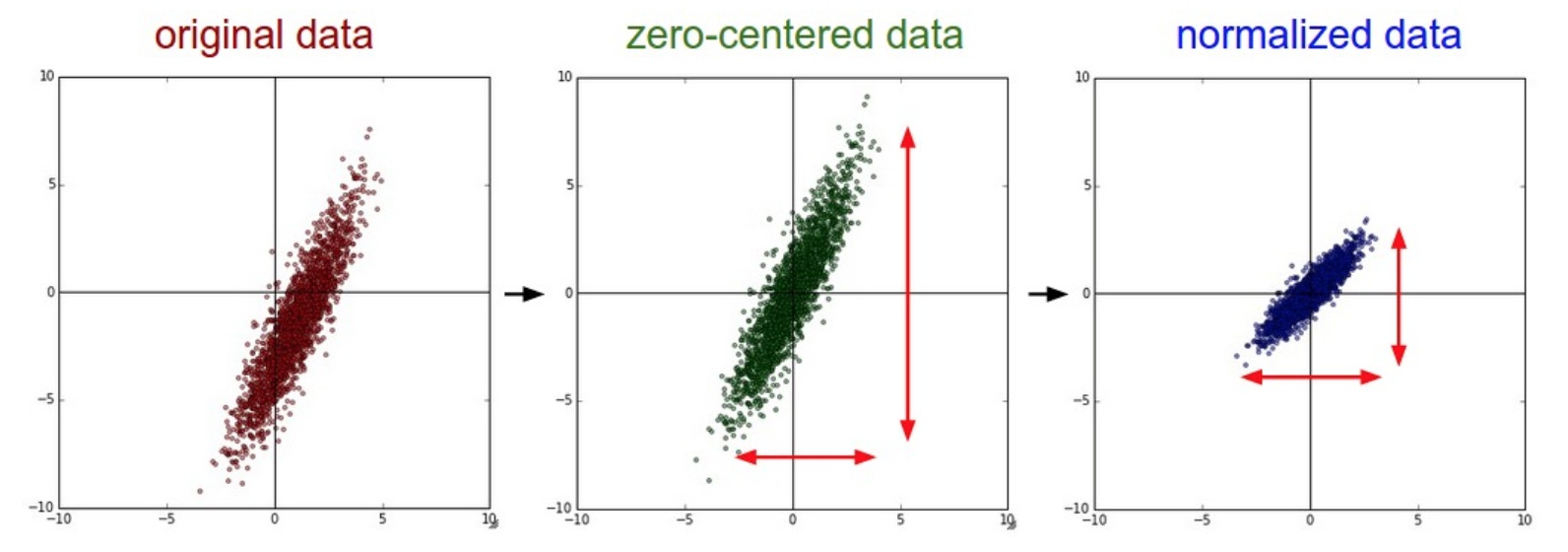
用的很多的是0中心化。CNN中很少用PCA和白化。
应该:线划分训练、验证、测试集,只是从训练集中求平均值!然后各个集再减去这个平均值。
中心化
也称作均值减法, 把数据所有维度变成0均值,其实就是减去均值。就是将数据迁移到原点。 \[
x = x - \rm{avg}(x) = x - \bar x
\]
标准化
也称作归一化, 数据所有维度都归一化,使其数值变化范围都近似相等。
- 除以标准差
- 最大值和最小值按照比例缩放到\((-1 ,1)\) 之间
方差\(s^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar x)^2\) ,标准差就是\(s\) 。数据除以标准差,接近标准高斯分布。 \[
x = \frac{x}{s}
\] 
PCA
协方差
协方差就是乘积的期望-期望的乘积。 \[
\rm{Cov}(X, Y) = E(XY) - E(X)E(Y)
\] 协方差的性质如下: \[
\begin{align}
& \rm{Cov}(X, Y) = \rm{Conv}(Y, X) \\ \\
& \rm{Cov}(aX, bY) = ab \cdot \rm{Conv}(Y, X) \\ \\
& \rm{Cov}(X, X) = E(X^2) - E^2(X) = D(X) , \quad \text{三方公式}\\ \\
& \rm{Cov}(X, C) = 0 \\ \\
& \rm{Cov}(X, Y) = 0 \leftrightarrow X与Y独立
\end{align}
\] 还有别的性质就看考研笔记吧。
奇异值分解 \[ A_{m \times n} = U_{m \times m} \Sigma_{m \times n} V^T_{n \times n} \] \(V_{n \times n}\) :\(V\)的列,一组对A正交输入或分析的基向量(线性无关)。这些向量是\(M^TM\) 的特征向量。
\(U_{m \times m}\) :\(U\)的列,一组对A正交输出的基向量 。是\(MM^T\)的特征向量。
\(\Sigma_{m \times n}\):对角矩阵。对角元素按照从小到大排列,这些对角元素称为奇异值。 是\(M^TM, MM^T\) 的特征值的非负平方根,并且与U和V的行向量对应。
记\(r\)是非0奇异值的个数,则A中仅有\(r\)个重要特征,其余特征都是噪声和冗余特征。
利用SVD进行PCA
先将数据中心化。输入是\(X \in \mathbb R^ {N \times D}\) ,则协方差矩阵 如下: \[
\mathrm{Cov}(X) = \frac{X^TX}{N} \; \in \mathbb R^{D \times D}
\] 比如X有a和b两维,均值均是0。那么\(\rm{Cov}(ab)=E(ab)-0=(a_0b_0+a_1b_1+\cdots + a_nb_n) /n\) ,就得到了协方差值。
- 中心化
- 计算\(x\)的
协方差矩阵cov - 对协方差矩阵cov进行
svd分解,得到u, s, v - 去除x的相关性,旋转,\(xrot = x \cdot u\) ,此时xrot的协方差矩阵只有对角线才有值,其余均为0
- 选出大于0的奇异值
- 数据降维
1 | def test_pca(): |
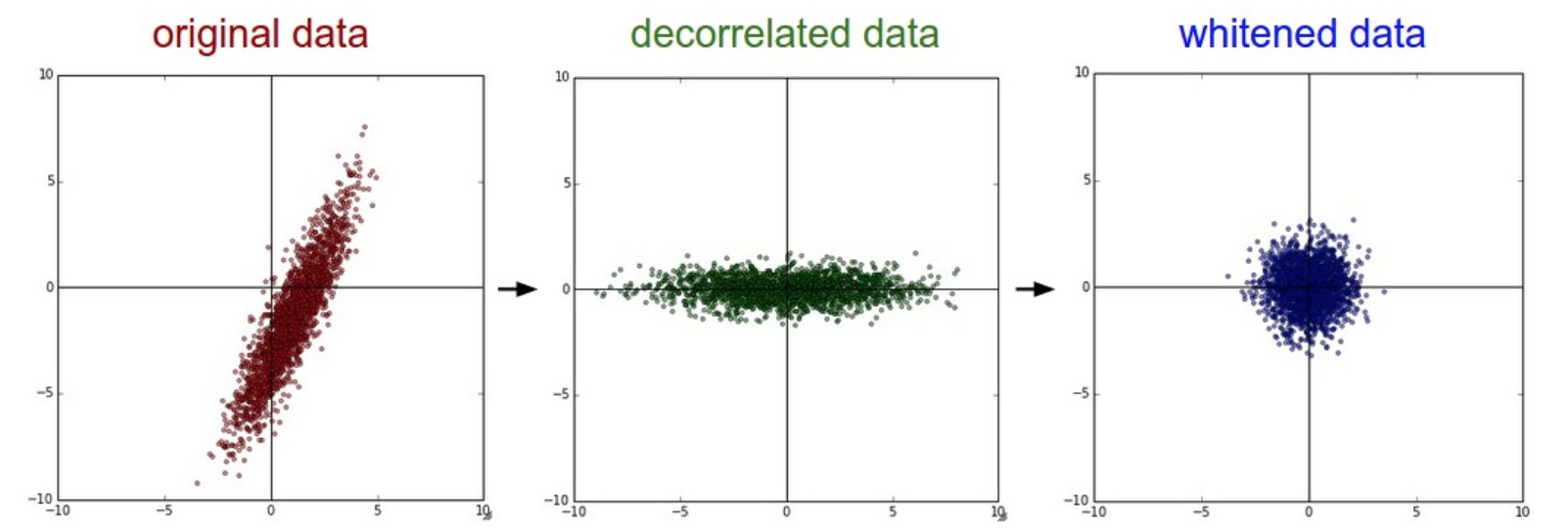
白化
白化希望特征之间的相关性较低,所有特征具有相同的协方差。白化后,得到均值为0,协方差相等的矩阵。对\(xrot\)除以特征值。 \[ x_{white} = \frac{x_{rot}}{\sqrt{\lambda + \epsilon}} \]
1 | x_white = xrot / np.sqrt(s + 1e-5) |
缺陷是:可能会夸大数据中的早上,因为把所有维度都拉伸到了相同的数值范围。可能有一些极少差异性(方差小)但大多数是噪声的维度。可以使用平滑来解决。
权重初始化
如果数据恰当归一化以后,可以假设所有权重数值中大约一半为正数,一半为负数。所以期望参数值是0。
千万不能够全零初始化。因为每个神经元的输出相同,BP时梯度也相同,参数更新也相同。神经元之间就失去了不对称性的源头。
小随机数初始化
如果神经元刚开始的时候是随机且不相等的,那么它们将计算出不同的更新,并成为网络的不同部分。
参数接近于0单不等于0。使用零均值和标准差的高斯分布来生成随机数初始化参数,这样就打破了对称性。
1 | W = 0.01 * np.random.randn(D,H) |
注意:不是参数值初始越小就一定好。参数小,意味着会减小BP中的梯度信号,在深度网络中,就会有问题。
校准方差
随着数据集的增长,随机初始化的神经元的输出数据分布的方差也会增大。可以使用\(\frac{1}{\sqrt{n}}\) 校准方差。n是数据的数量。这样就能保证网络中所有神经元起始时有近似同样的输出分布。这样也能够提高收敛的速度。 感觉实际上就是做了一个归一化。
数学详细推导见cs231n , \(s = \sum_{i}^nw_ix_i\) ,假设w和x都服从同样的分布。想要输出s和输入x有同样的方差。 \[
\begin {align}
& \because D(s) = n \cdot D(w)D(x), \; D(s) = D(x) \\
& \therefore D(w) = \frac{1}{n} \\
& \because D(w_{old}) = 1, \; D(aX) = a^2 D(X) \\
& \therefore D(w) = \frac{1}{n}D(w_{old}) = D(\frac{1}{\sqrt n} w_{old}) \\
& \therefore w = \frac{1}{\sqrt n} w_{old}
\end{align}
\] 所以要使用\(\frac{1}{\sqrt{n}}\)来标准化参数:
1 | W = 0.01 * np.random.randn(D,H)/ sqrt(n) |
经验公式
对于某一层的方差,应该取决于两层的输入和输出神经元的数量,如下: \[
\rm{D}(w) = \frac{2}{n_{in} + n_{out}}
\] ReLU来说,方差应该是\(\frac{2}{n}\)
1 | W = 0.01 * np.random.randn(D,H) * sqrt(2.0 / n) |
稀疏和偏置初始化
一般稀疏初始化用的比较少。一般偏置都初始化为0。
Batch Normalization
莫凡python BN讲解 和 CSDN-BN论文介绍 。Batch Normalization和普通数据标准化类似,是将分散的数据标准化。
Batch Normalization在神经网络非常流行,已经成为一个标准了。
训练速度分析
网络训练的时候,每一层网络参数更新,会导致下一层输入数据分布的变化。这个称为Internal Convariate Shift。
需要对数据归一化的原因 :
- 神经网络的本质是学习数据分布。如果训练数据与测试数据的分布不同,那么
泛化能力也大大降低 - 如果每个batch数据分布不同(batch 梯度下降),每次迭代都要去学习适应不同的分布,会大大降低训练速度
深度网络,前几层数据微小变化,后面几层数据差距会积累放大。
一旦某一层网络输入数据发生改变,这层网络就需要去适应学习这个新的数据分布。如果训练数据的分布一直变化,那么就会影响网络的训练速度。
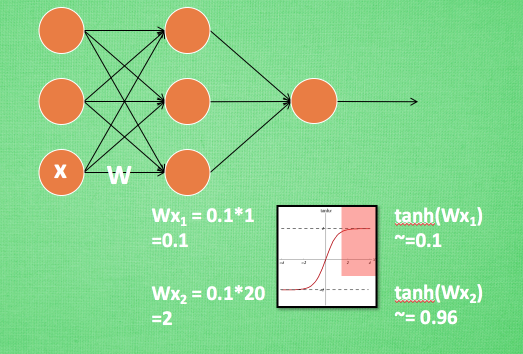
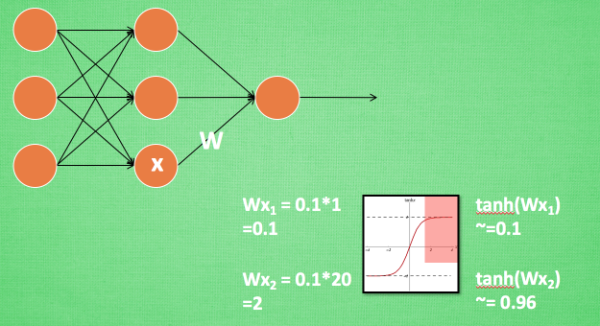
敏感度问题
神经网络中,如果使用tanh激活函数,初始权值是0.1。
输入\(x=1\), 正常更新: \[ z = wx = 0.1, \quad a(z_1) = 0.1 \quad \to \quad a^\prime(z) = 0.99 \] 但是如果一开始输入 \(x=20\) ,会导致梯度消失,不更新参数。 \[ z = wx = 2 ,\quad a(z) \approx 1 \quad \to \quad a^\prime(z) = 0 \] 同样地,如果再输入\(x=100\) ,神经元的输出依然是接近于1,不更新参数。 \[ z = wx = 10 ,\quad a(z) \approx 1 \quad \to \quad a^\prime(z) = 0 \] 对于一个变化范围比较大特征维度,神经网络在初始阶段对它已经不敏感没有区分度了!
这样的问题,在神经网络的输入层和中间层都存在。
BN算法
BN算法在每一次迭代中,对每一层的输入都进行归一化。把数据转换为均值为0、方差为1的高斯分布。 \[
\hat x = \frac{x - E(x)} {\sqrt{D(x) + \epsilon}}
\] 非常大的缺陷:强行归一化会破坏掉刚刚学习到的特征。 把每层的数据分布都固定了,但不一定是前面一层学习到的数据分布。
牛逼的地方 :设置两个可以学习的变量扩展参数\(\gamma\) ,和平移参数 \(\beta\) ,用这两个变量去还原上一层应该学习到的数据分布。(但是芳芳说,这一步其实可能没那么重要,要不要都行,CNN的本身会处理得更好)。 \[
y = \gamma \hat x+ \beta
\] 这样理解:用这两个参数,让神经网络自己去学习琢磨是前面的标准化是否有优化作用,如果没有优化效果,就用\(\gamma, \beta\)来抵消标准化的操作。
这样,BN就把原来不固定的数据分布,全部转换为固定的数据分布,而这种数据分布恰恰就是要学习到的分布。从而加速了网络的训练。
对一个mini-batch进行更新, 输入一个\(batchsize=m\)的数据,学习两个参数,输出\(y\) \[
\begin{align}
& \mu = \frac{1}{m} \sum_{i=1}^m x_i & \text{求均值} \\
& \sigma^2 = \frac{1}{m} \sum_{i=1}^m (x_i - \mu)^2 & \text{求方差} \\
& \hat x = \frac{x - E(x)} {\sqrt{\sigma^2 + \epsilon}} & \text{标准化} \\
& y = \gamma \hat x+ \beta & \text{scale and shfit}
\end{align}
\] 其实就是对输入数据做个归一化: \[
z = wx+b \to z = \rm{BN}(wx + b) \to a = f(z)
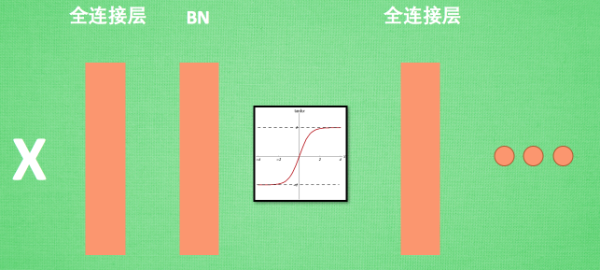
\] 一般在全连接层和激活函数之间添加BN层。
在测试的时候,由于是没有batch,所以使用固定的均值和标准差,也就是对训练的各个batch的均值和标准差做批处理。 \[ E(x) = E(\mu), \quad D(x) = \frac{b}{b-1} E(\sigma^2) \]
BN的优点
1 训练速度快
2 选择大的初始学习率
初始大学习率,学习率的衰减也很快。快速训练收敛。小的学习率也可以。
3 不再需要Dropout
BN本身就可以提高网络泛化能力,可以不需要Dropout和L2正则化。源神说,现在主流的网络都没有dropout了。但是会使用L2正则化,比较小的正则化。
4 不再需要局部相应归一化
5 可以把训练数据彻底打乱
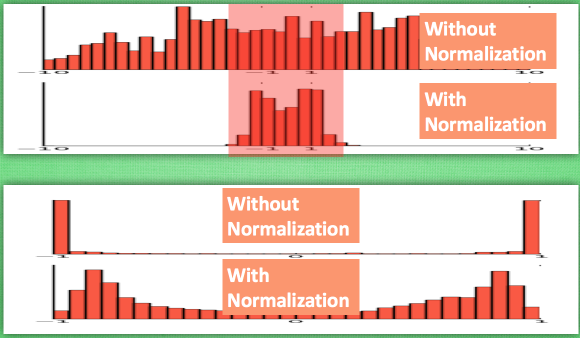
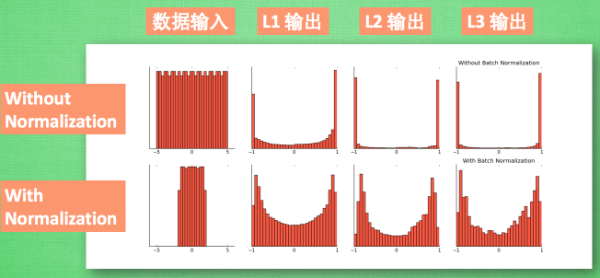
效果图片展示
对所有数据标准化到一个范围,这样大部分的激活值都不会饱和,都不是-1或者1。
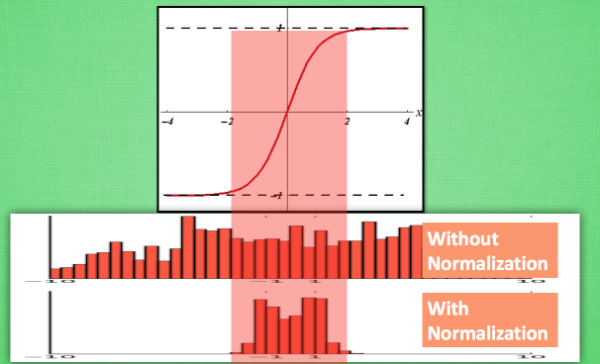
大部分的激活值在各个分布区间都有值。再传递到后面,数据更有价值。