神经网络基础-反向传播-激活函数
📅 发表于 2017/11/23
🔄 更新于 2017/11/23
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#神经网络
#反向传播
#激活函数
cs224n神经网络基础,前向反向传播,激活函数等
很多数据都是非线性分割的,所以需要一种非线性non-linear决策边界 来分类。神经网络包含很多这样的非线性的决策函数。
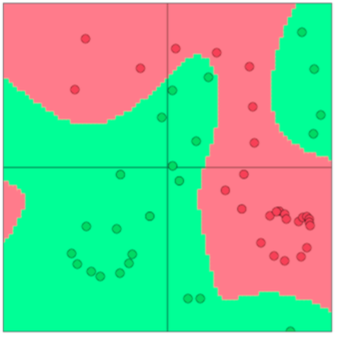
神经元其实就是一个计算单元。
sigmoid, relu等,后文有讲。Sigmoid神经元
传统用sigmoid多,但是现在一定不要使用啦。大多使用Relu作为激活函数。
一个网络层有很多个神经元。输入
输入是
激活函数的意义
每个神经元
最后会把所有的神经元的所有
输入
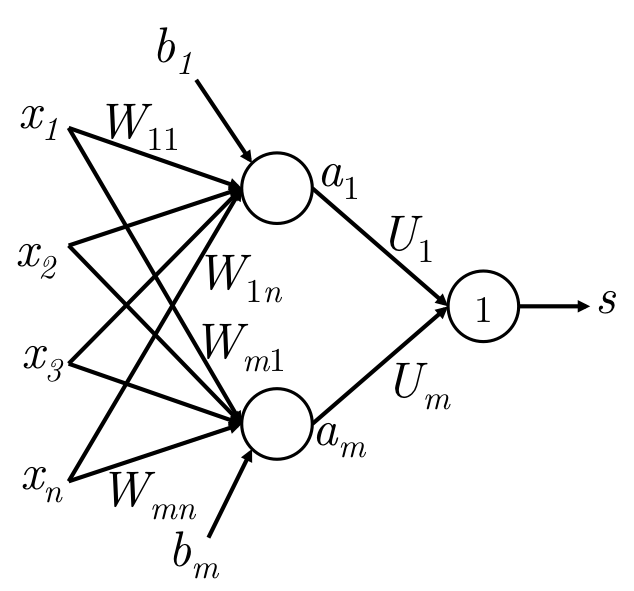
下面是一个简单的全连接,最后的圆圈里的1代表等价输出。
NER例子
NER(named-entity recognition),命名实体识别。对于一个句子Museums in Paris are amazing。 要判断中心单词Paris是否是个命名实体。
既要看window里的所有词向量,也要看这些词的交互关系。比如:Paris出现在in的后面。 因为可能有Paris和Paris Hilton。这就需要non-linear decisions。
如果直接把input给到softmax,是很难获取到非线性决策的。所以需要添加中间层使用神经网络。如上图所示。
维数分析
每个单词4维,输入整个窗口就是20维。在隐层使用8个神经元。计算过程如下,最终得到一个分类的得分。
维数如下:
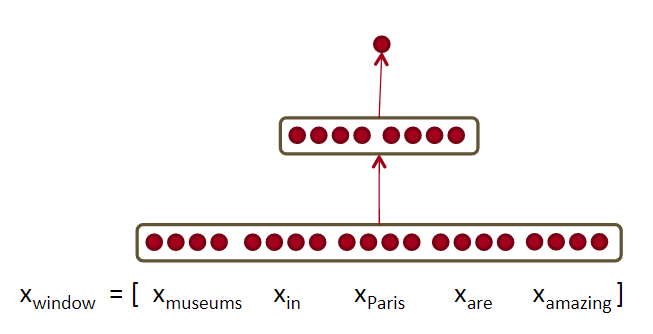
正样本Museums in Paris are amazing ,负样本Not all museums in Paris 。
只关心:正样本的得分高于负样本的得分, 其它的不关注。即要
优化目标函数如下:
上式其实有风险,更需要
给具体间距优化目标函数:详情见SVM。
其中
梯度下降 ,或者SGD:
反向传播 使用链式法则 来计算前向计算中用到的参数的梯度。
如下图,一个简单的网络:
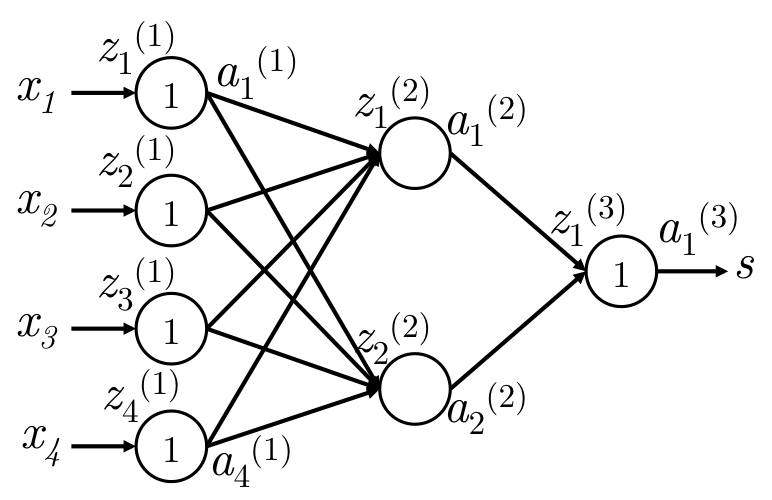
网络在输入层和输出层是等价输入和等价输出,只有中间层会使用激活函数进行非线性变换。
| 符号 | 意义 |
|---|---|
| 网络输入,这里是4维 | |
| 网络输出,这里是1维,即一个数字 | |
| 第 | |
| k+1层的 | |
| 第 | |
| 计算输入 | |
| 第 | |
| BP时,在 |
误差函数
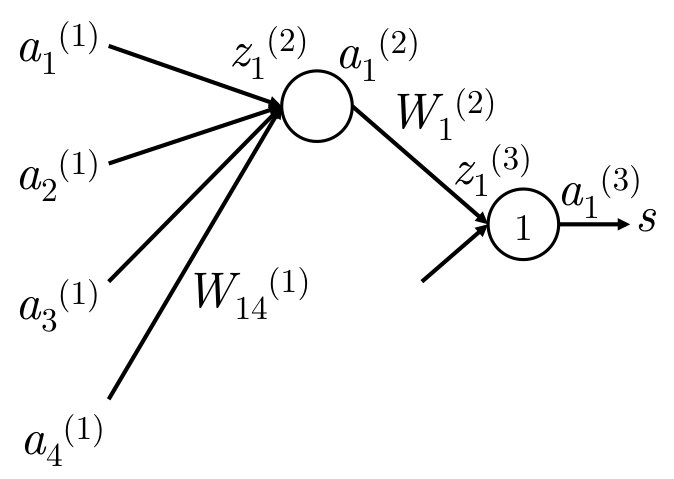
反向传播时,必须知道参数在前向时所贡献所关联的对象,即知道路径。
这里是等价输出:
这里对
结果分析
我们知道
反向时,反向传播。 传来的梯度也作error signal。 反向过程也是error sharing/distribution。
| 步骤 | 梯度 |
|---|---|
| 梯度 | |
| 在 | |
对于上式的梯度计算,有两种理解方法,通过这两种思路去思考能更深入了解。
链式法则error sharing and distributed flow approach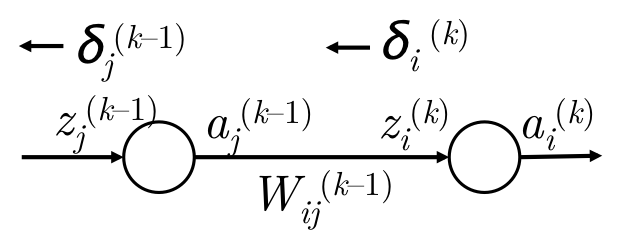
但是更多时候,当前层的某个神经元的信息会传播到下一层的多个节点上,如下图:
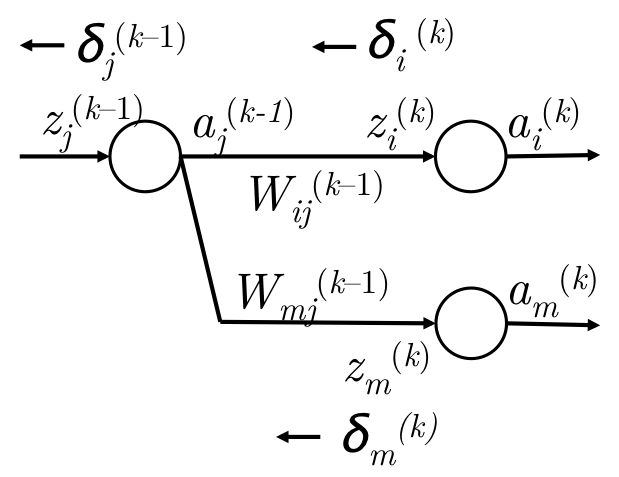
梯度推导公式如下:
很明显,不能一个一个参数地去更新element-wise。所以需要用矩阵和向量去表达,去一次性全部更新matrix-vector level。
梯度计算,
梯度传播,
其中element-wise,是各个位置相乘, 即
计算效率
很明显,在计算的时候要把上一层的
使用导数的定义来估计导数,去和BP算出来的梯度做对比。
由于这样计算非常,效率特别低,所以只用这种办法来检查梯度。具体实现代码见原notes。
激活函数有很多,现在主要用ReLu,不要用sigmoid。
用ReLU学习率一定不要设置太大!同一个网络中都使用同一种类型的激活函数。
数学形式和导数如下:
图像
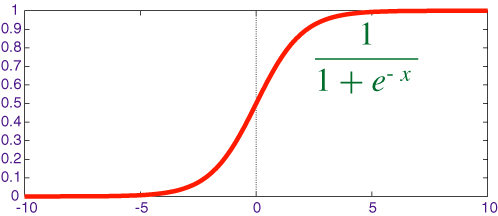
优点是具有好的解释性,将实数挤压到
Sigmoid会造成梯度消失
Sigmoid输出不是以0为均值
Sigmoid梯度消失的问题最严重。
数学公式和导数如下:
图像:
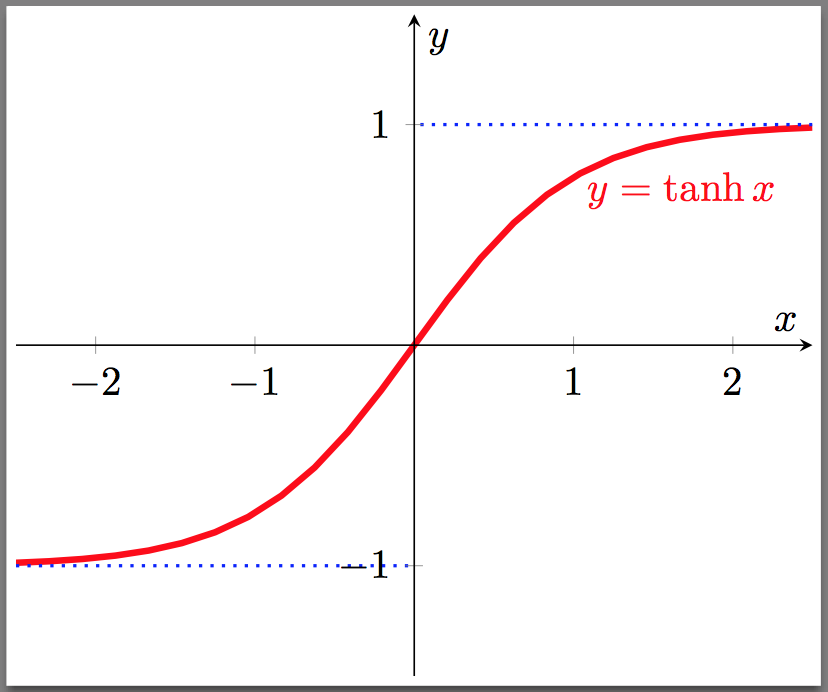
Tanh是Sigmoid的代替,它是0均值的,但是依然存在梯度消失的问题。
ReLURectified Linear Unit 最近越来越流行,不会对于大值
其实ReLU是一个关于0的阈值,现在一般都用ReLU:
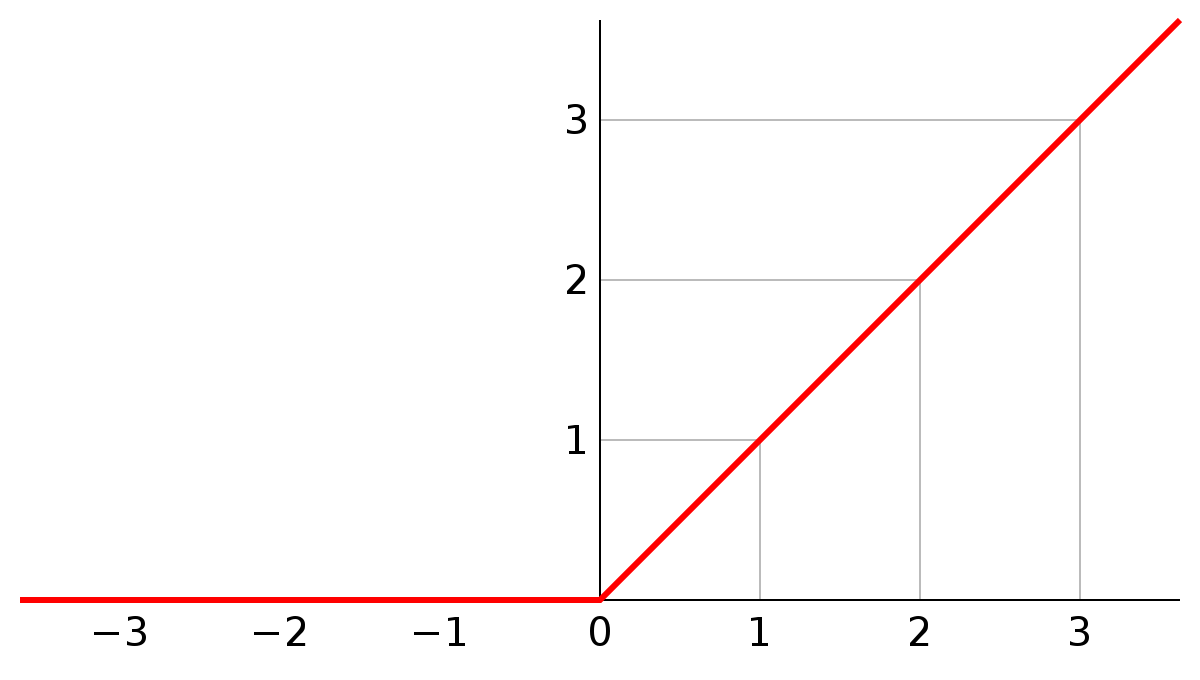
ReLU的优点
ReLU的缺点
训练的时候很脆弱
总结也就是:大梯度
当然可以使用比较小的学习率来解决这个问题。
maxout 有ReLU的优点,同时避免了它的缺点。但是maxout加倍了模型的参数,导致了模型的存储变大。