循环神经网络
📅 发表于 2017/10/19
🔄 更新于 2017/10/19
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
深度学习
#RNN
#LSTM
#GRU
RNN, LSTM, GRU图文介绍,RNN梯度消失问题等
模型
人类在思考的时候,会从上下文、从过去推断出现在的结果。传统的神经网络无法记住过去的历史信息。
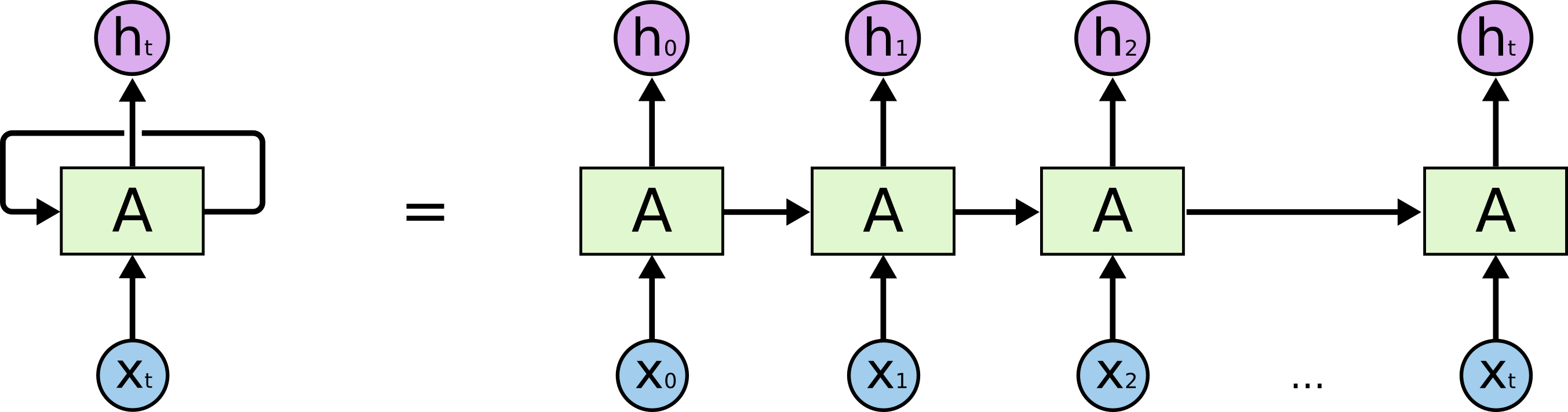
循环神经网络是指随着时间推移,重复发生的结构。它可以记住之前发生的事情,并且推断出后面发生的事情。用于处理时间序列很好。所有的神经元共享权值。如下图所示。
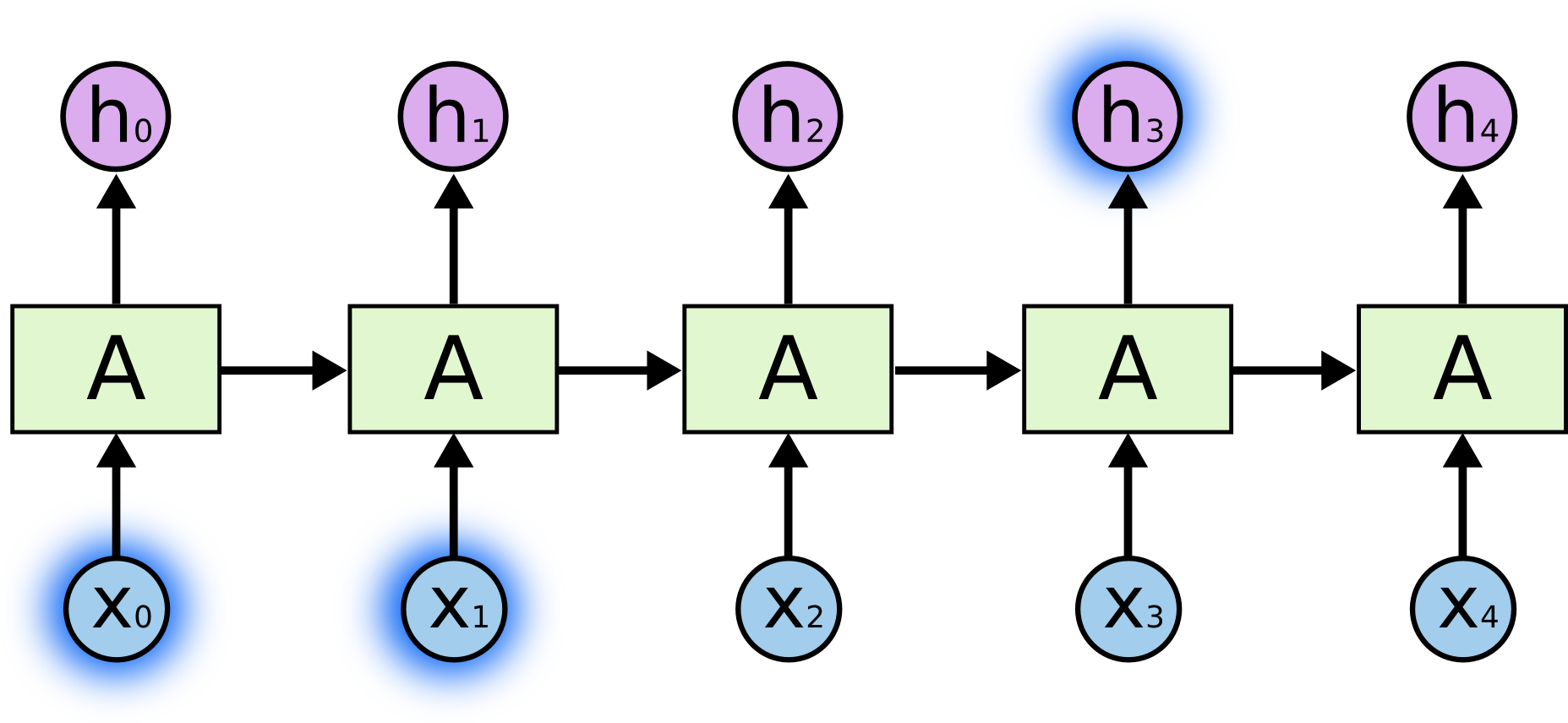
记住短期信息
比如预测“天空中有__”,如果过去的信息“鸟”离当前位置比较近,则RNN可以利用这个信息预测出下一个词为“鸟”
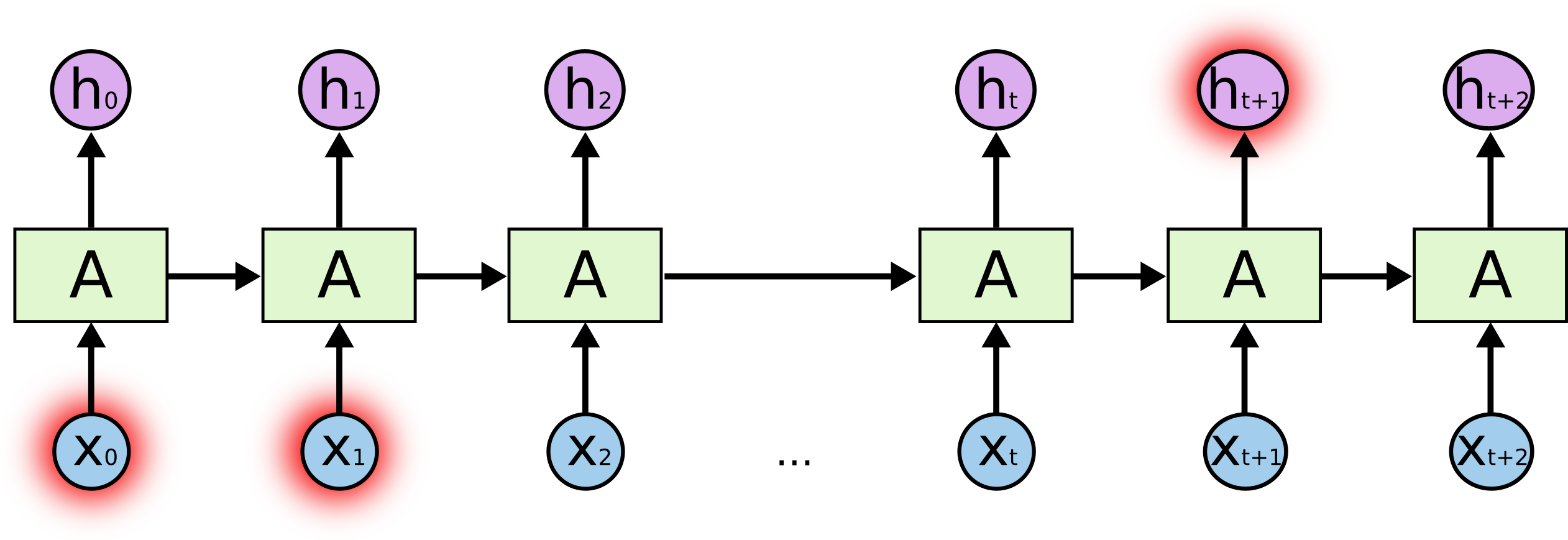
不能长期依赖
如果需要的历史信息距离当前位置很远,则RNN无法学习到过去的信息。这就是不能长期依赖的问题。
见后面GRU解决梯度消失
总览
所有的RNN有着重复的结构,如下图,比如内部是一个简单的tanh 层。
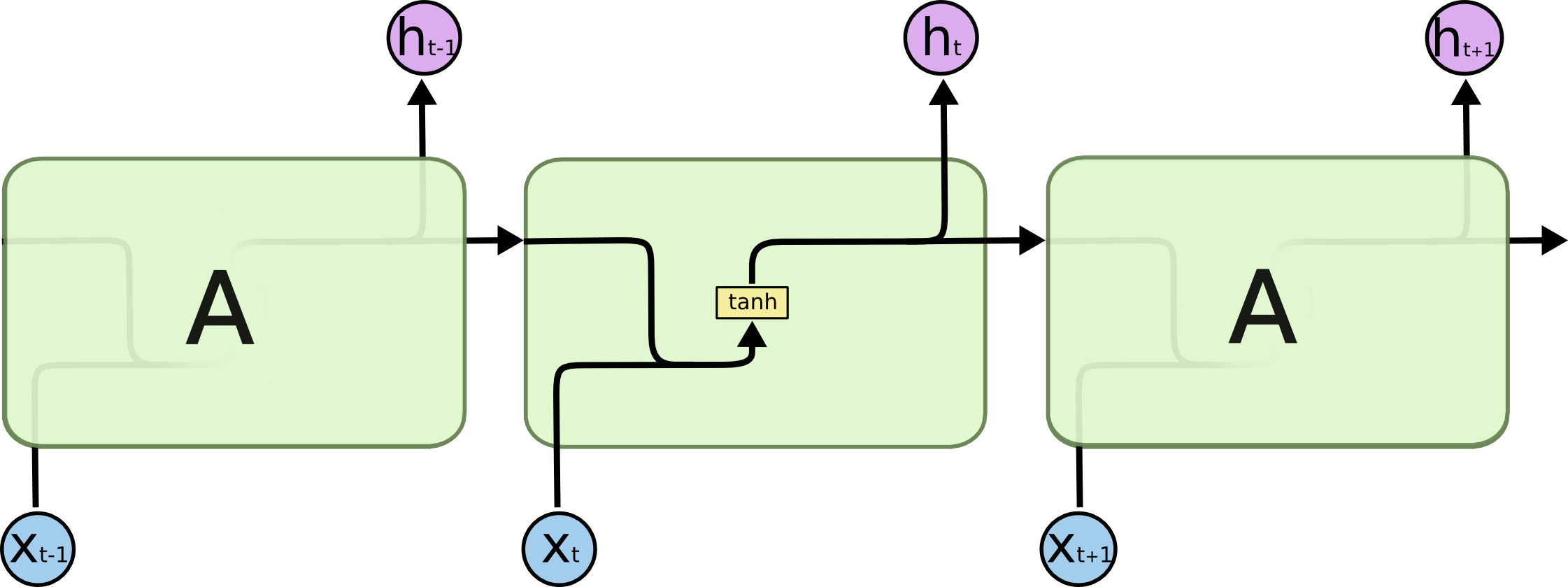
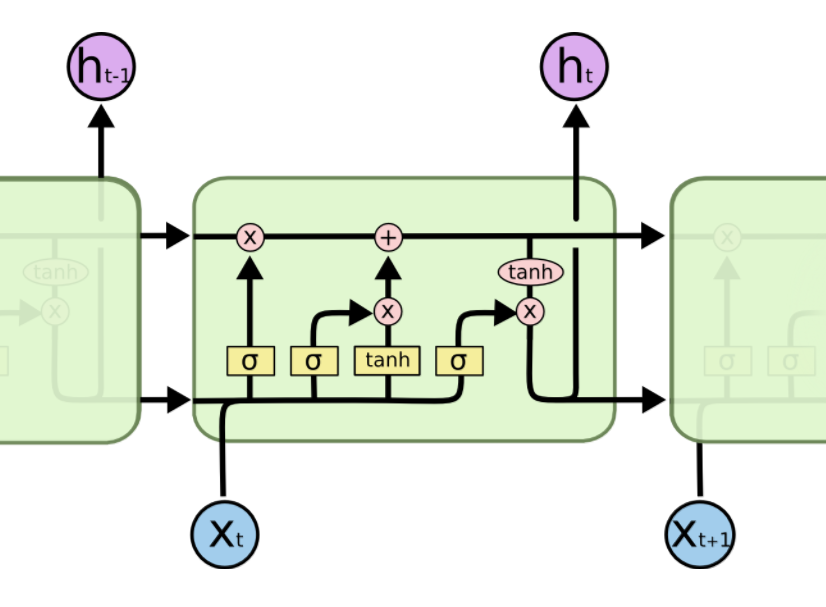
LSTM也是一样的,只不过内部复杂一些。
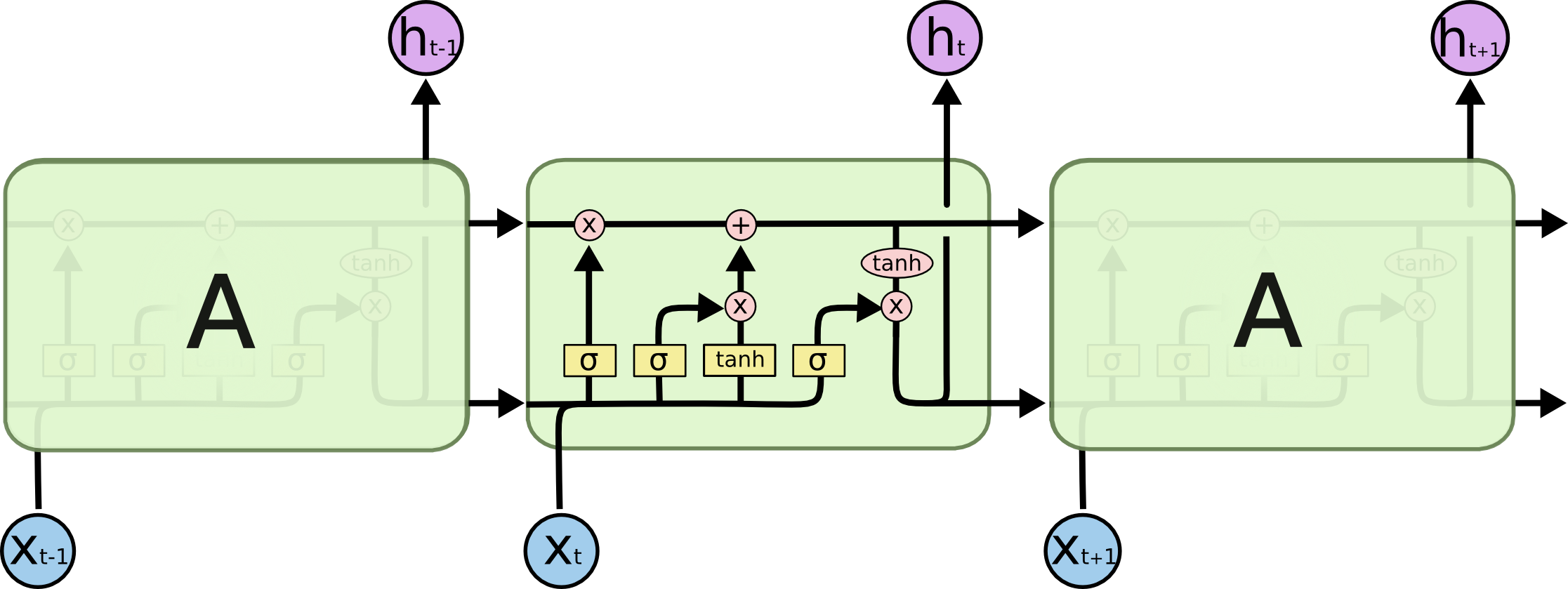
单元状态
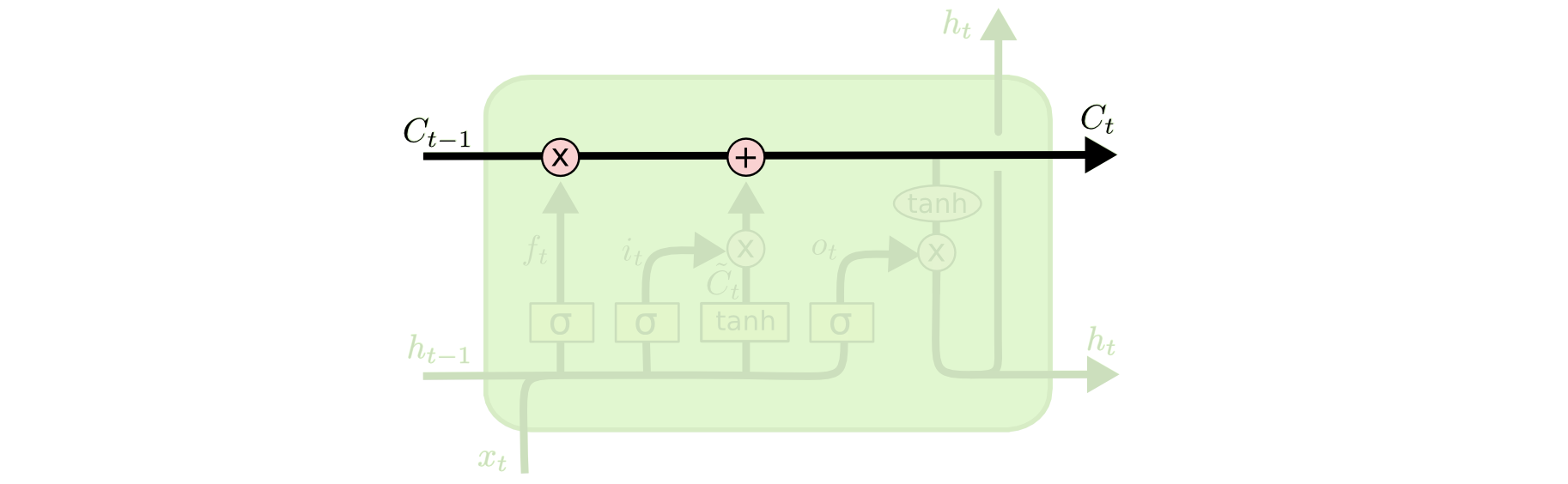
单元状态像一个传送带,通过整个链向下运行,只有一些小的线性作用。信息就沿着箭头方向流动。
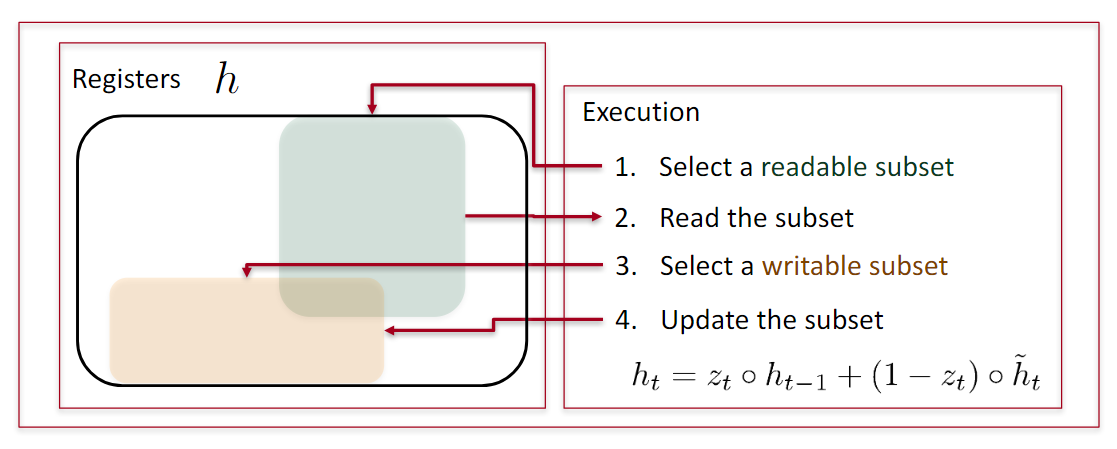
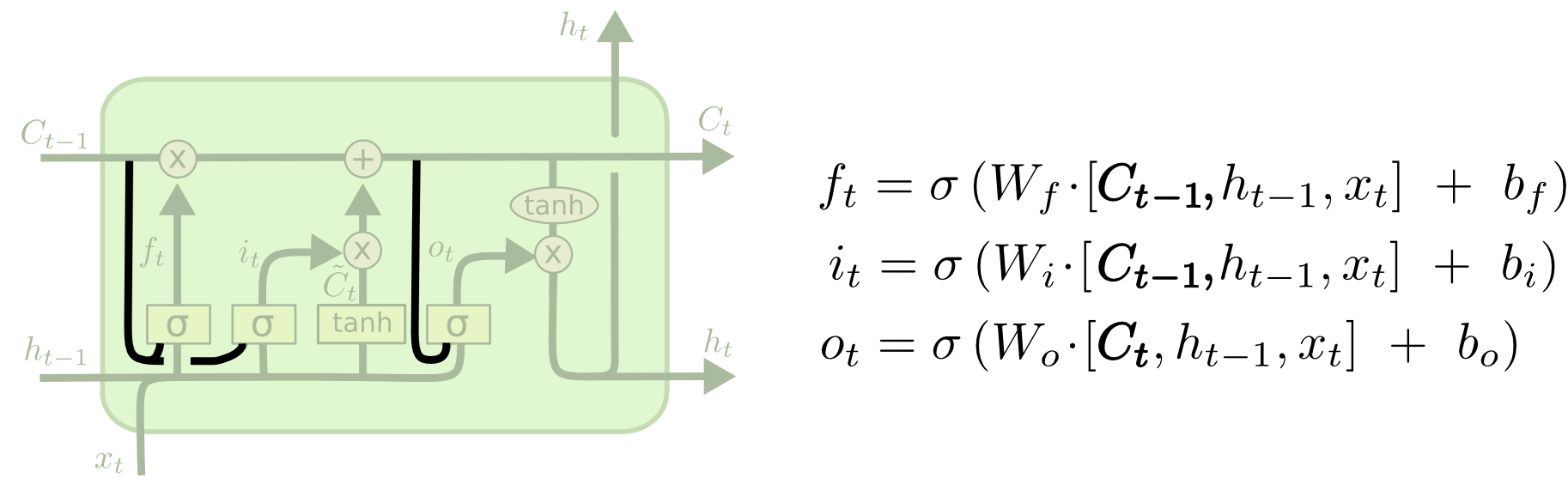
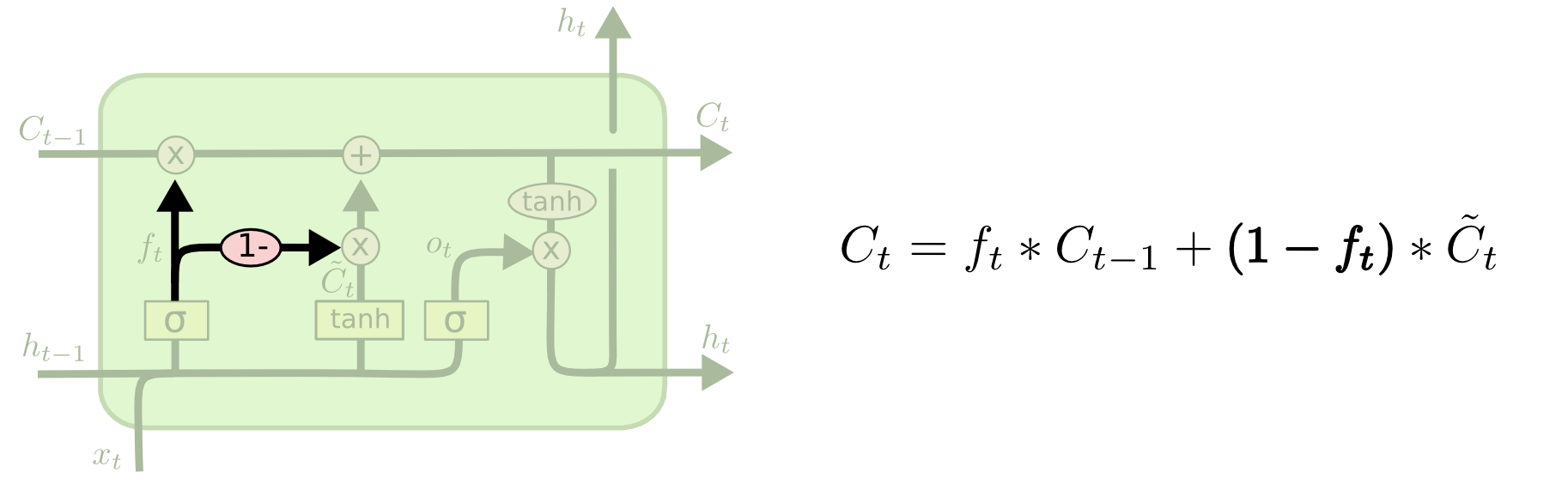
LSTM的门结构
LSTM的门结构 可以添加或者删除单元状态的信息,去有选择地让信息通过。它由sigmoid网络层 和 点乘操作组成。输出属于
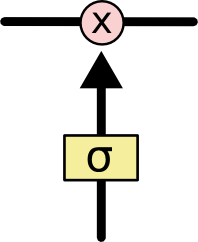
一些符号说明,都是
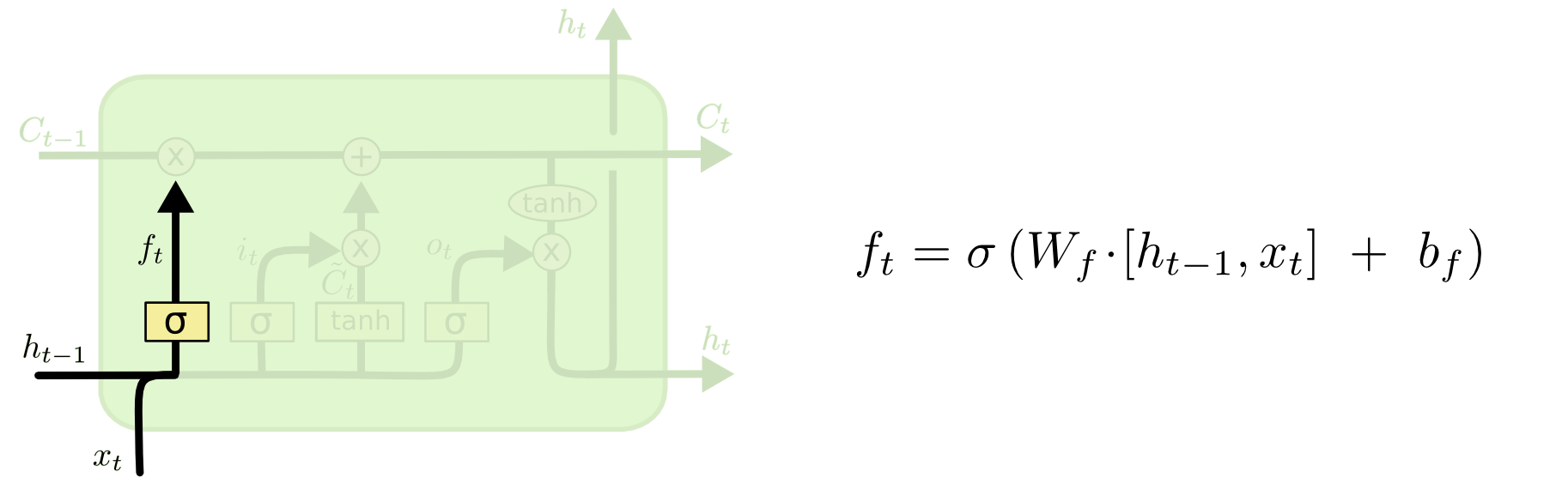
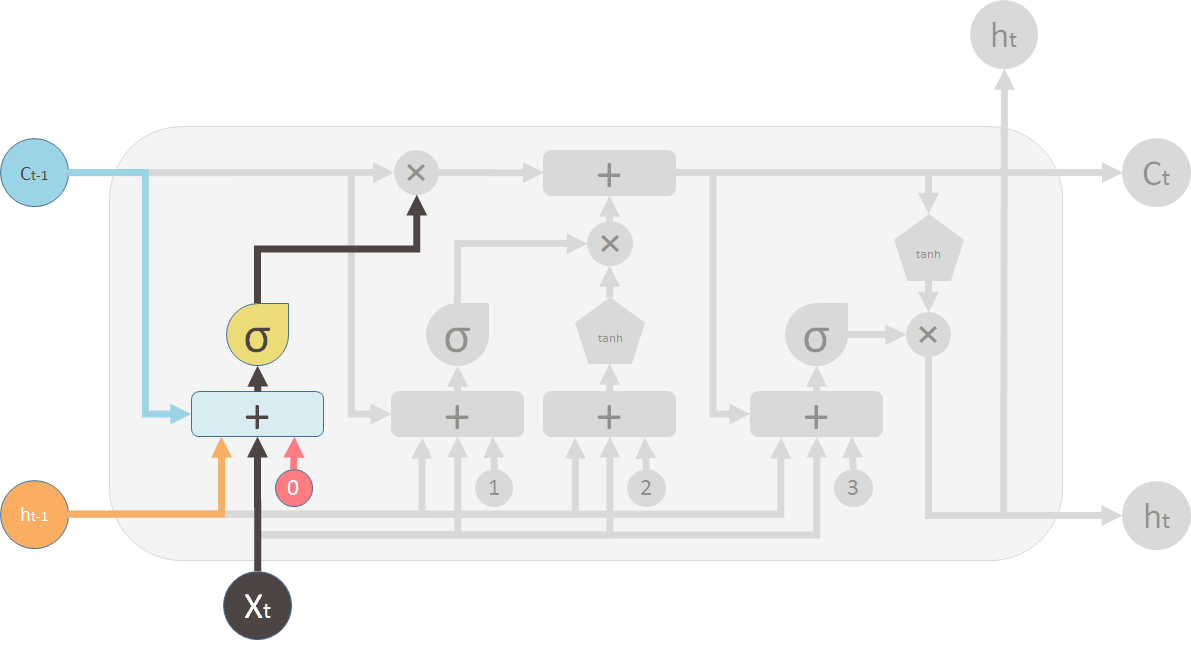
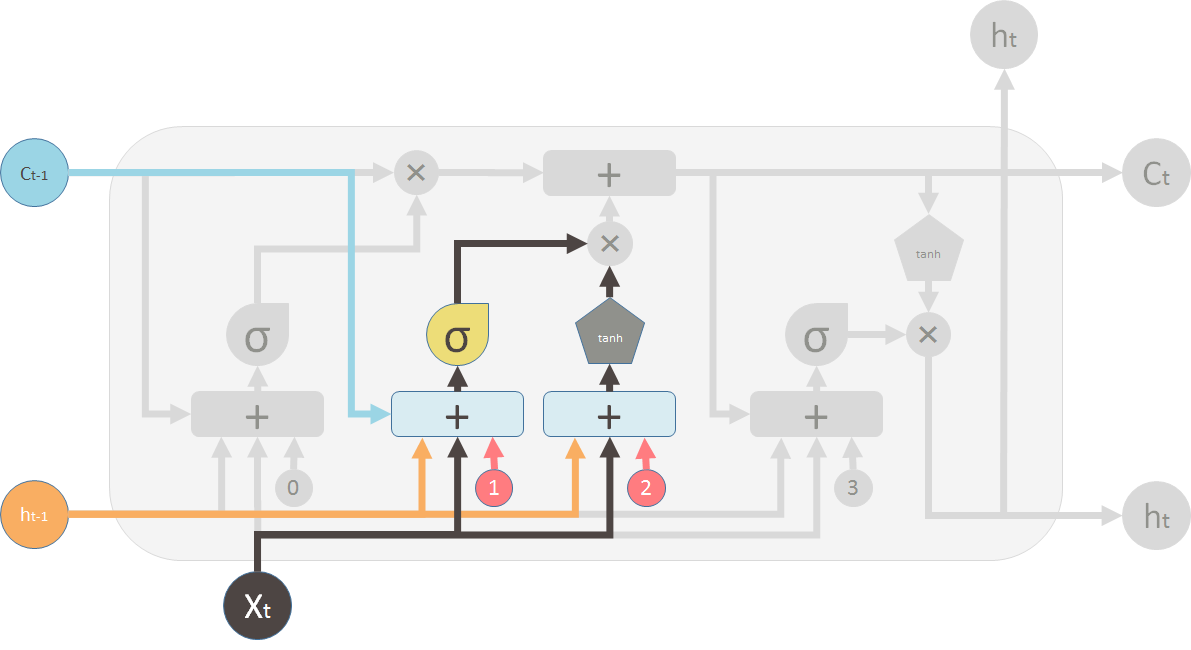
1 遗忘旧信息
对于
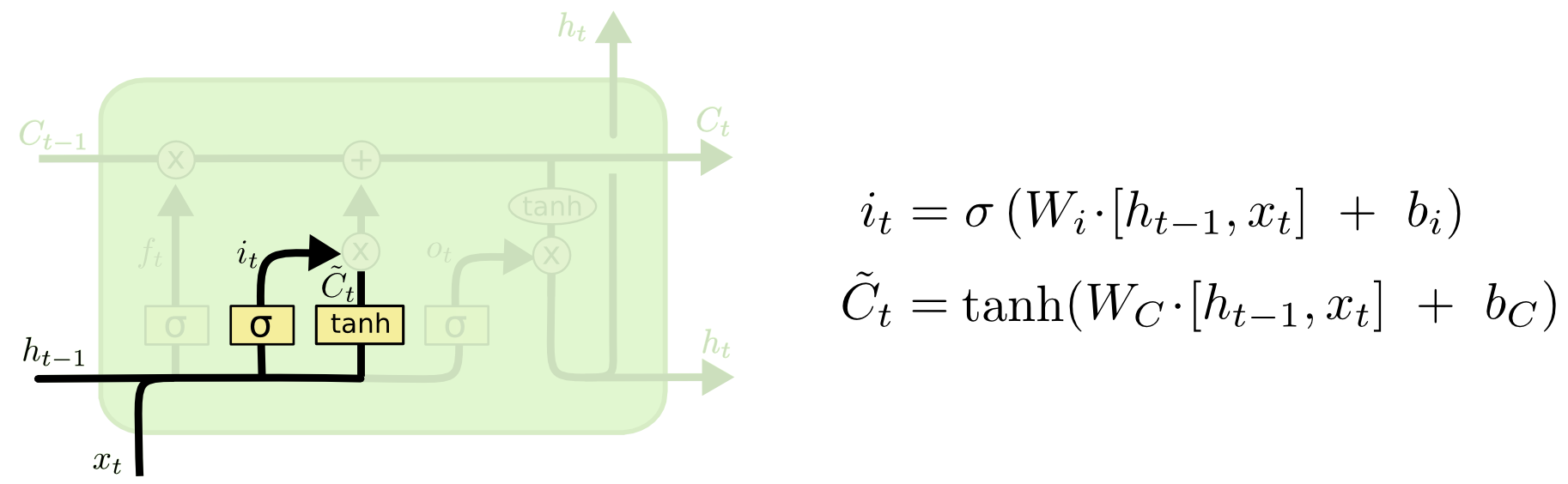
2 生成候选状态和它的更新比例
生成新的状态:tanh层创建新的候选状态
输入门:决定新的状态哪些信息会被更新
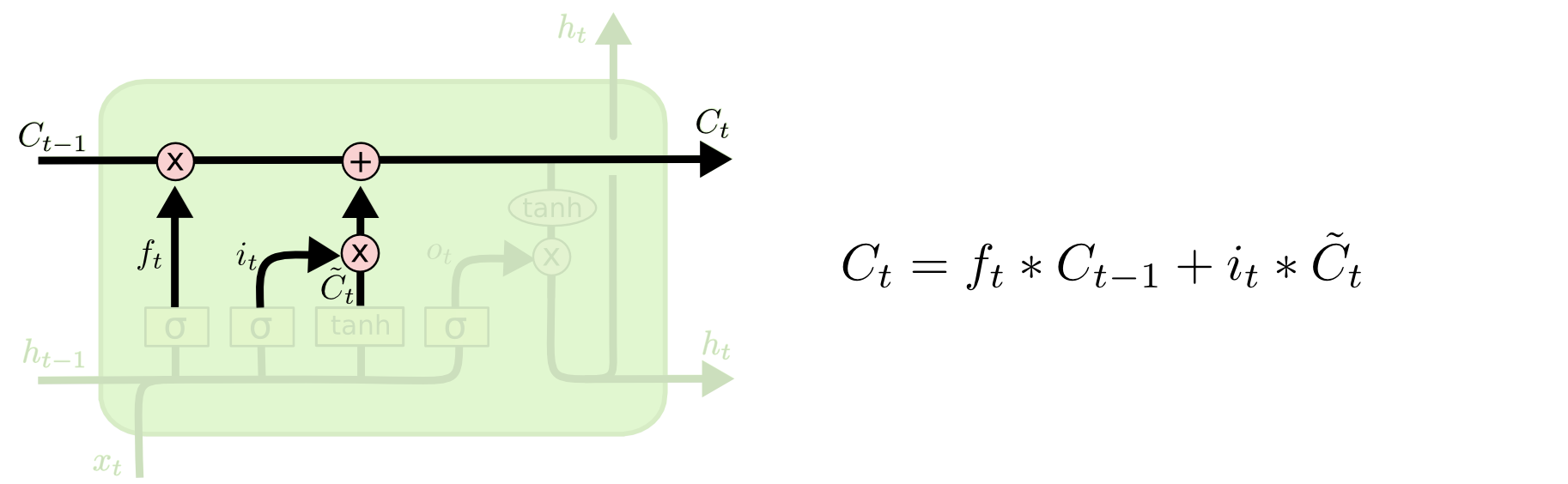
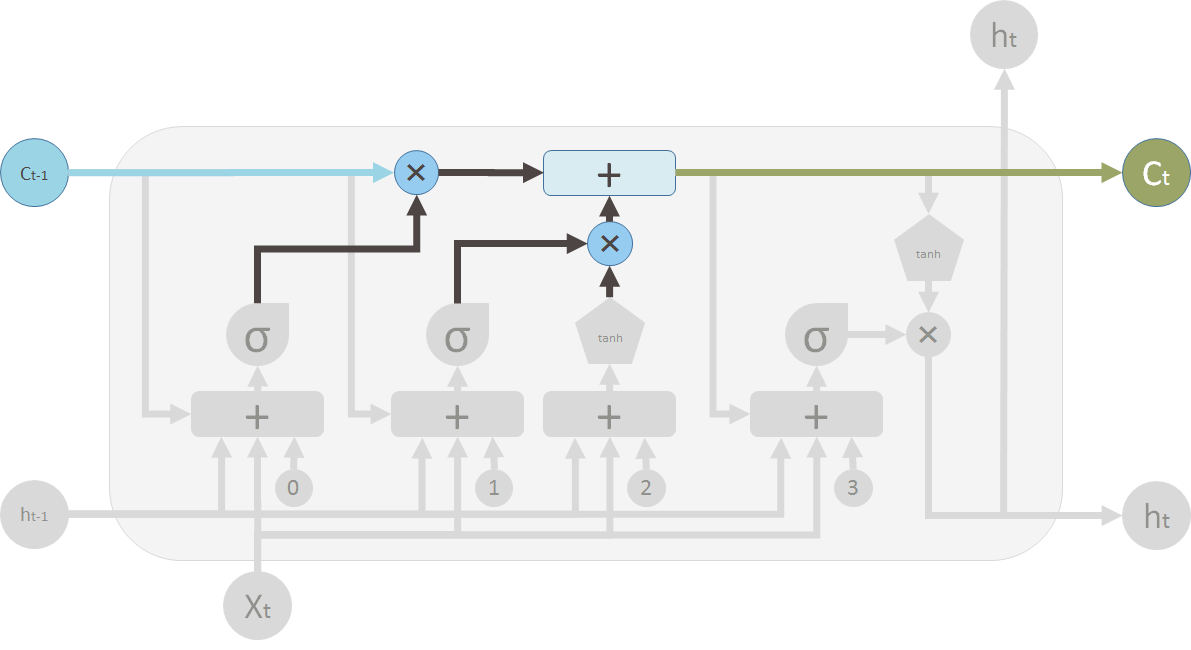
3 新旧状态合并更新
生成新状态
旧状态
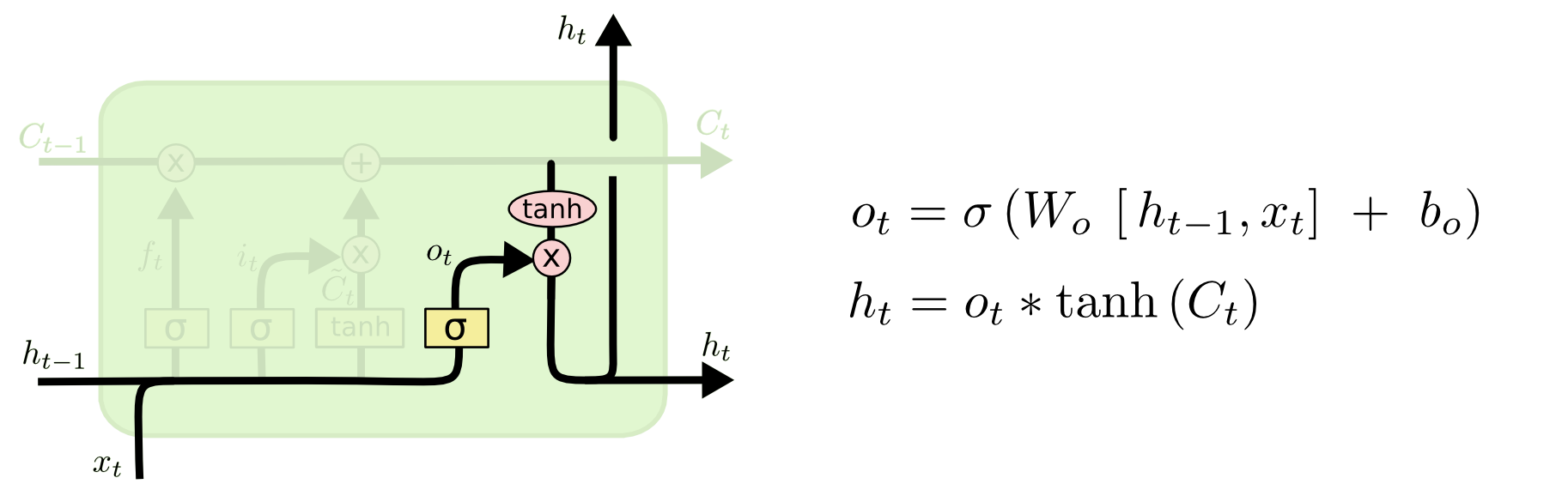
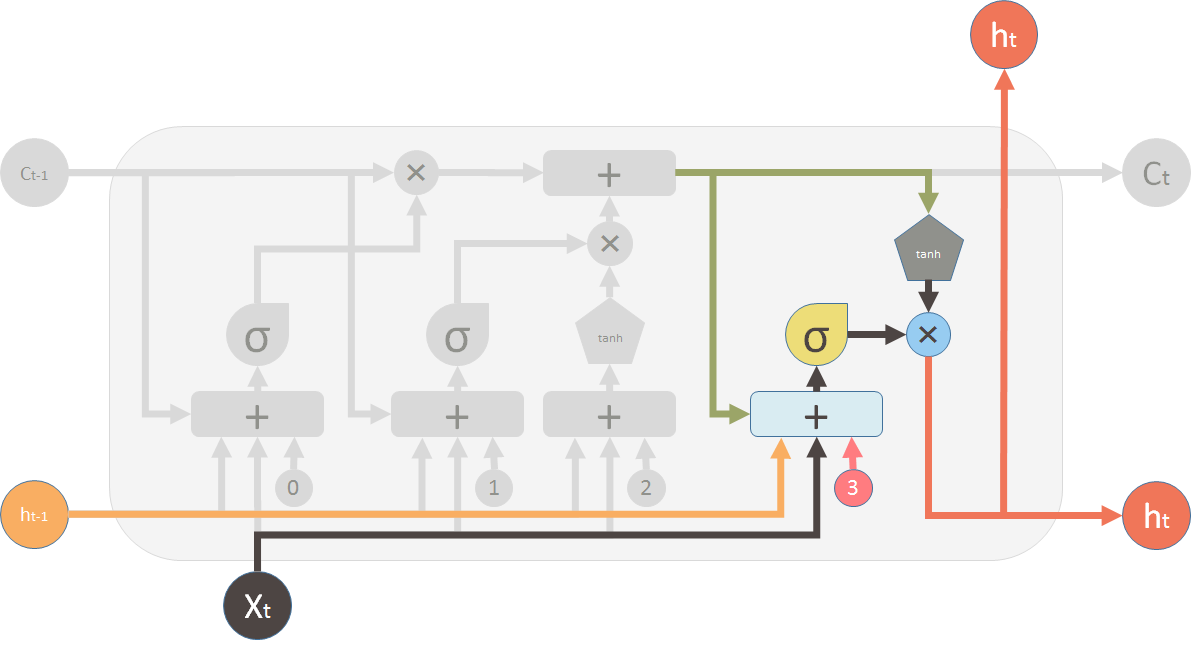
4 输出特别的值
sigmoid:决定单元状态
tanh: 把单元状态
核心结构如下图所示
要忘掉部分旧信息,旧信息
新的信息来了,生成一个新的候选
新信息留多少呢,新候选
合并旧信息和新信息,生成新的状态信息
输出多少呢,单元状态
把
单元架构
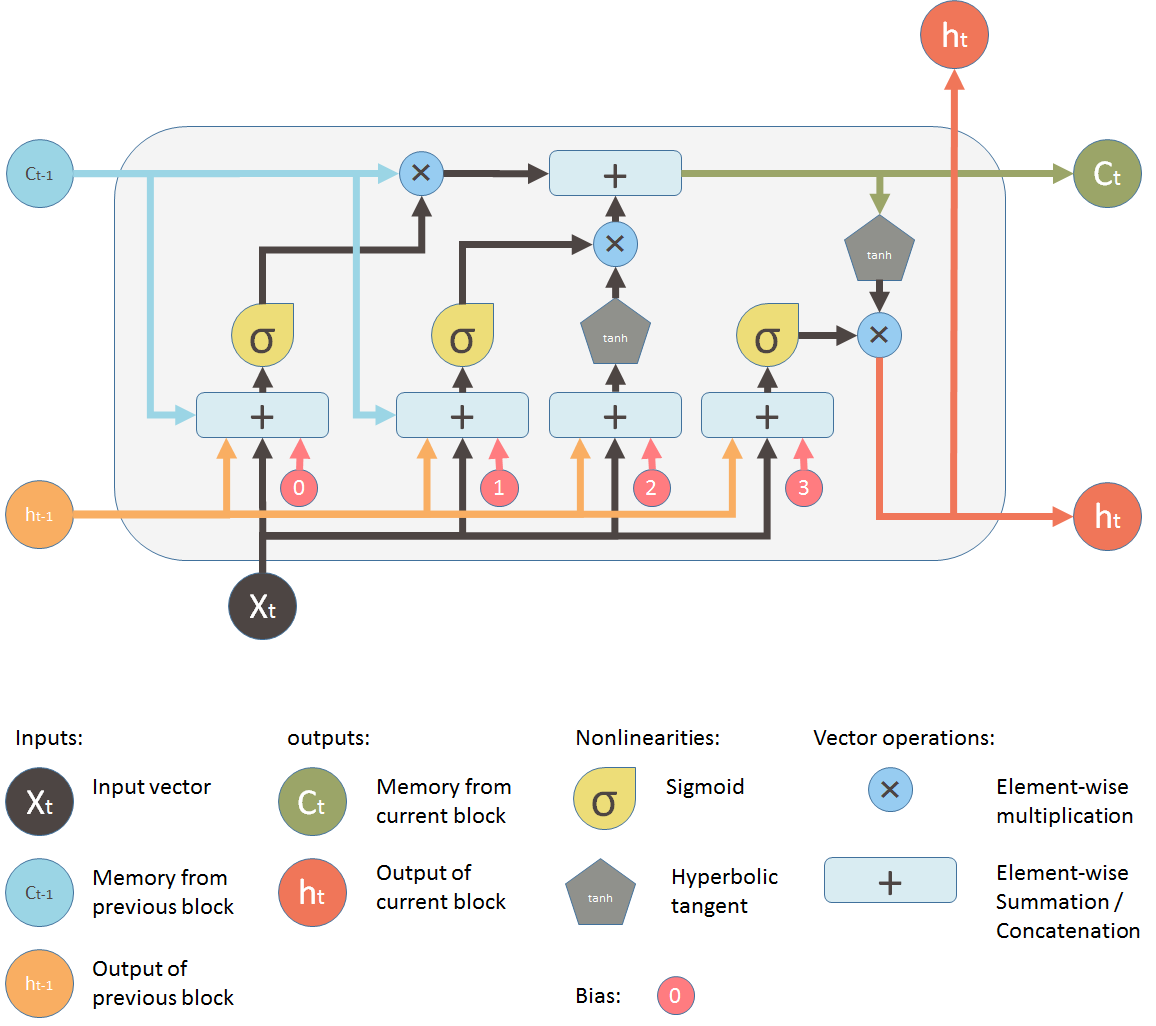
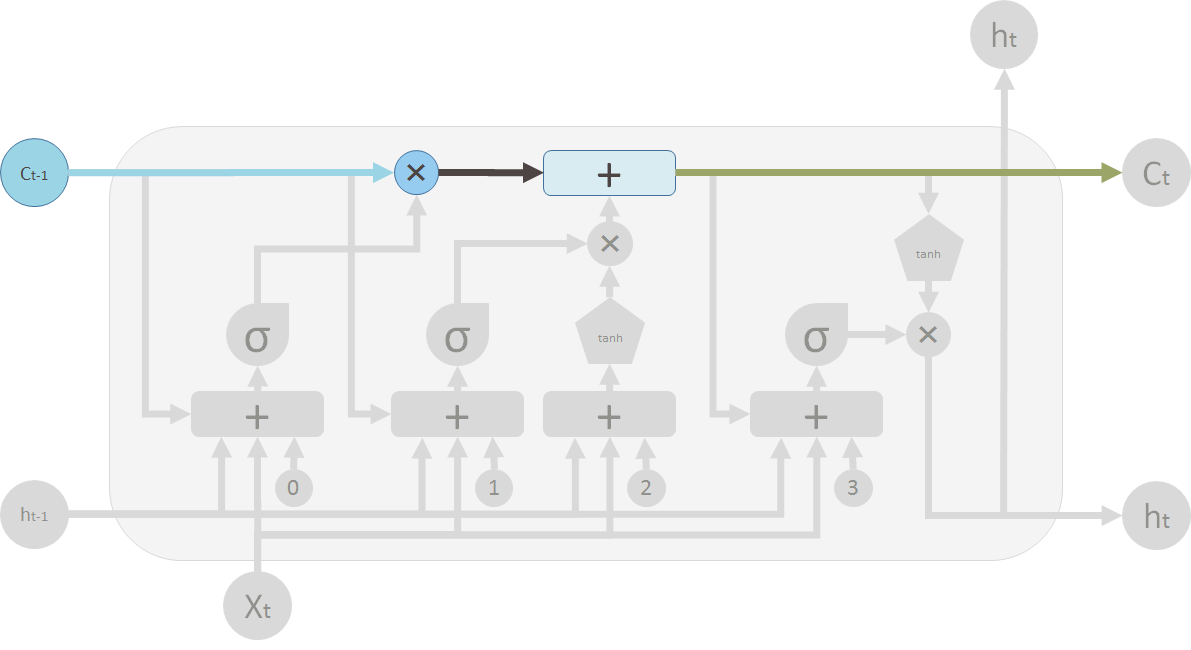
流水线架构

圆圈叉叉代表着遗忘
框框加号代表着数据的合并。旧信息
上一个LSTM的输出
新信息门
新信息门决定着新信息对旧信息的影响力。和遗忘门一样
sigmoid:生成新信息的保留比例。tanh:生成新的信息。
旧信息
把新生成的状态信息
传统LSTM阀门值比例的计算,即更新、遗忘、输出的比例只和
观察口连接,把观察到的单元状态也连接sigmoid上,来计算。即遗忘、更新比例和
如下图所示,计算好
LSTM有隐状态
更新门
候选隐藏层
重置门
新记忆
最终记忆

更新门
重置门
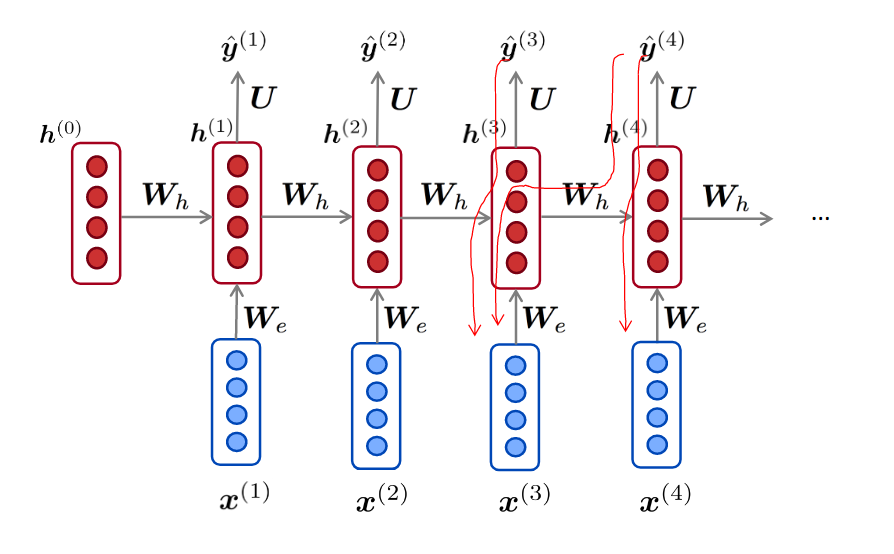
简单点
总的误差是之前每个时刻的误差之和
每一时刻的误差又是之前每个时刻的误差之和,应用链式法则
而
而导数矩阵雅克比矩阵
合并起来,得到最终的
两个不等式
所以有,会变得非常大或者非常小。会产生梯度消失或者梯度爆炸问题。
梯度 是过去对未来影响力的一个度量方法。如果梯度消失了不确定
原始梯度
如果
RNN的前向和反向传播,都会经过每一个节点

GRU可以自动地去创建一些短连接,也可以自动地删除一些不必要的连接。(门的功能)
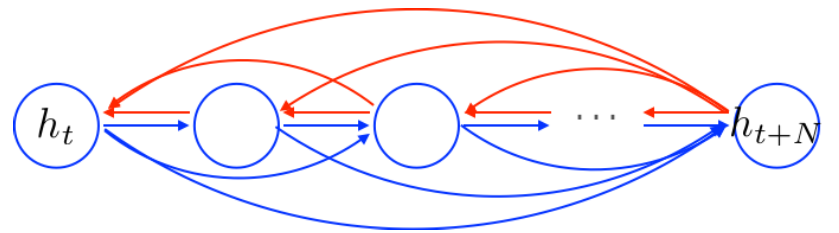
RNN会读取之前所有信息,并且更新所有信息。
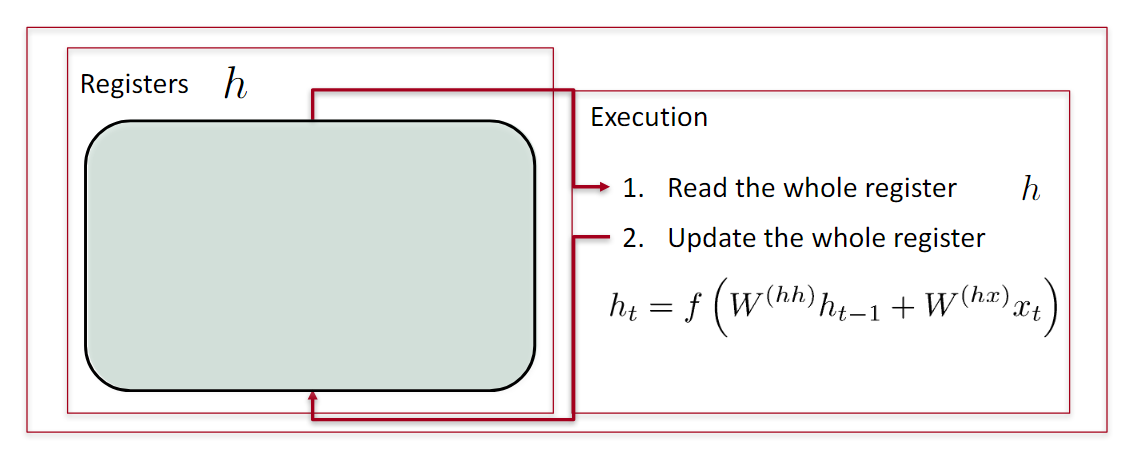
GRU