卷积神经网络总结
📅 发表于 2018/04/11
🔄 更新于 2018/04/11
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
深度学习
#卷积
#1*1卷积
#分组卷积
#可分离卷积
#LeNet
#AlexNet
#InceptionNet
#ResNet
#XceptionNet
#ShuffleNet
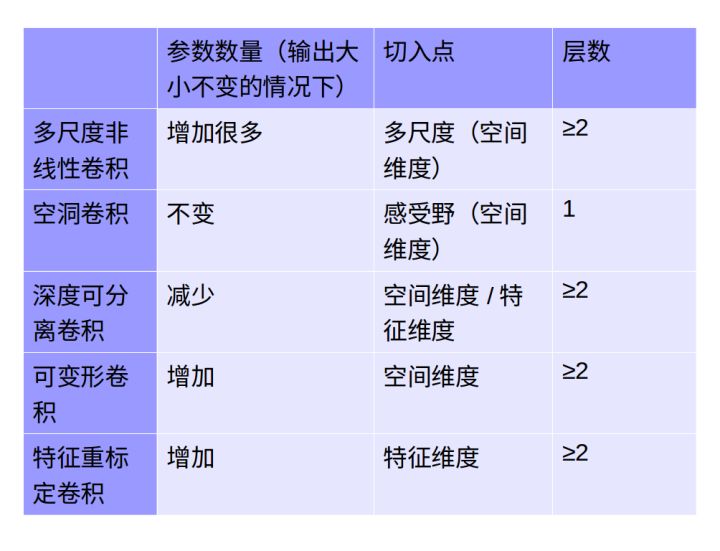
卷积基本概念和常见的卷积神经网络
全连接网络的两个问题:
1. 局部性
图片特征只在局部。图片特征决定图片类别,这些图片特征在一些局部的区域中。
局部连接。
2. 相同性
用同样的检测模式去检测不同图片的相同特征。只是这些特征出现在图片的不同位置。
参数共享。
3. 不变性
对于一张大图片,进行下采样,图片的性质基本保持不变。
下采样保持不变性。
- 一维卷积:卷积核、步长、首位0填充
- 三种卷积:窄卷积、宽卷积、等长卷积
- 二维卷积
1. 一维卷积
卷积核 或 滤波器
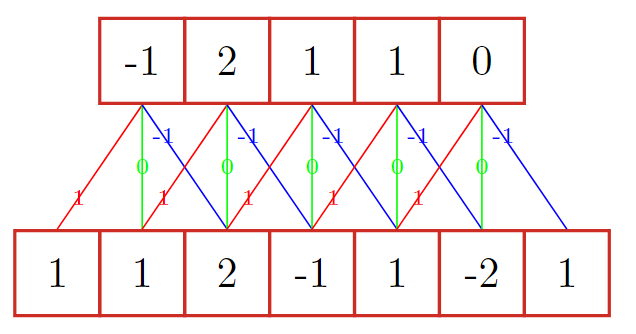 **2. 三种卷积**
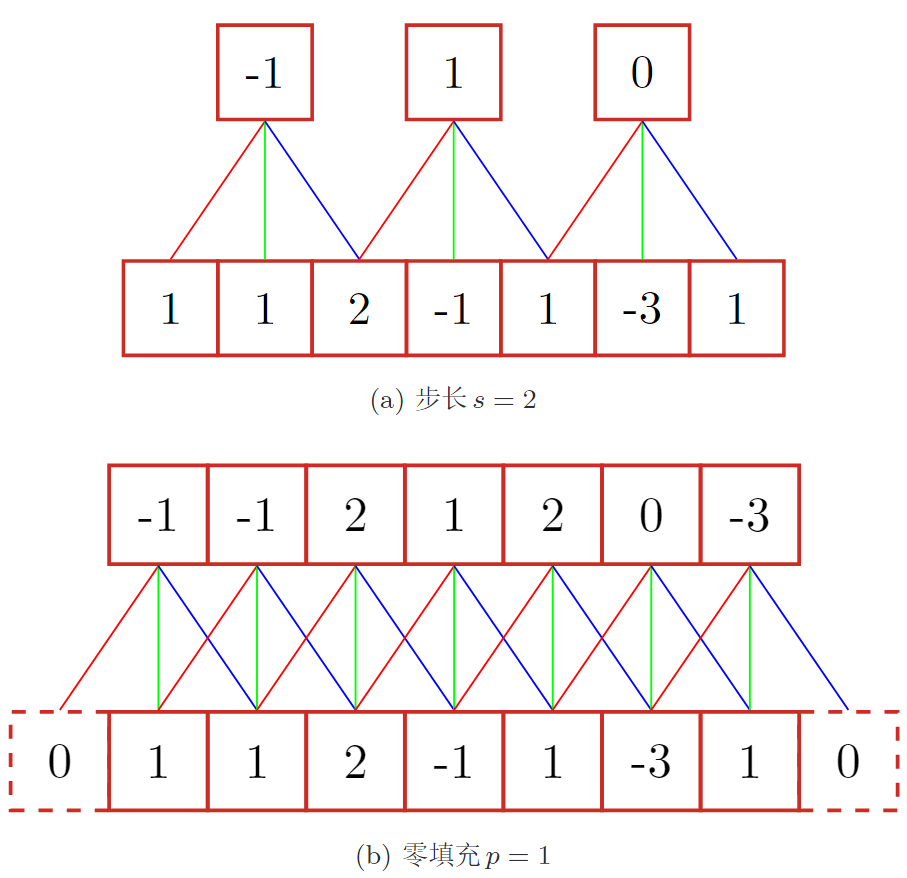
**2. 三种卷积** 输入n,卷积大小m,步长s,输入神经元各两端填补p个0
s=1,不补0,输出长度为n-m+1s=1,两端补0,n+m-1s=1,两端补0,n一般卷积默认为窄卷积。
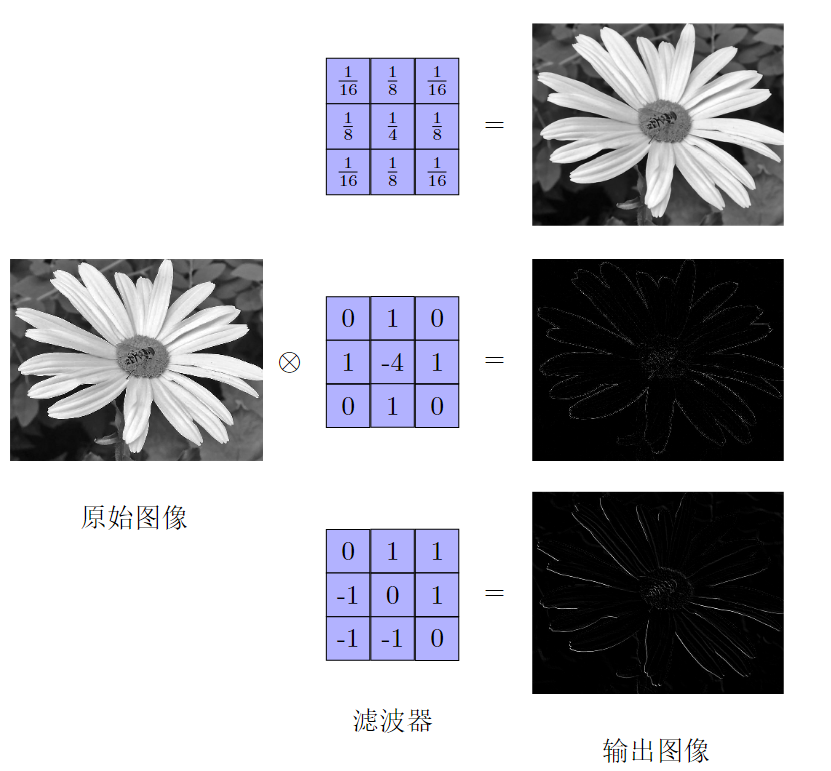
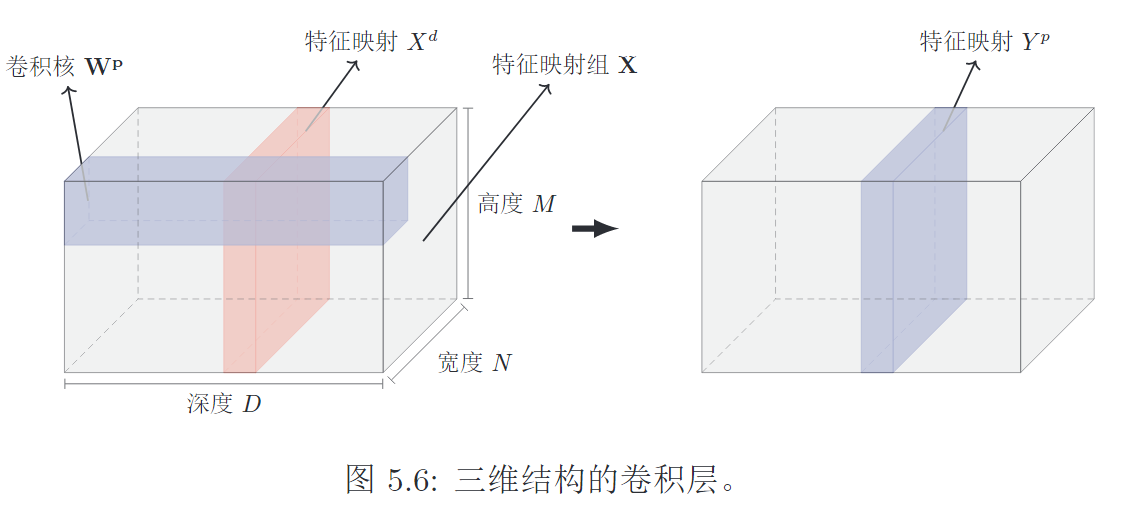
3. 二维卷积
输入一张图片(假设深度为1),
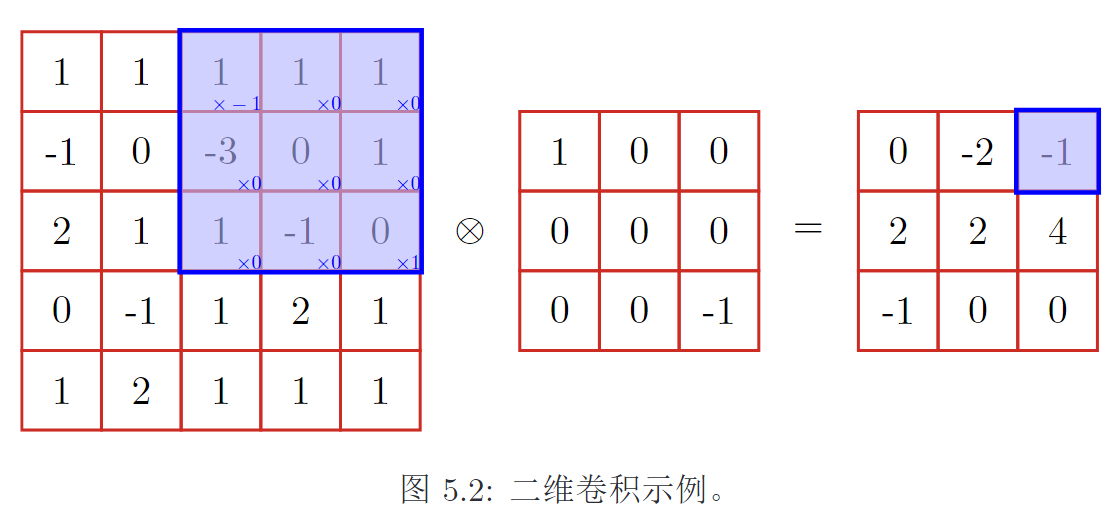
一个卷积核提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器。
卷积后的结果称为特征映射(feature map)。
一个卷积核
, 对D个通道做卷积,结果相加求和,过激活函数,得到一个特征图 多个卷积核:得到P个特征图
输入图片(feature map)是
1. 一个卷积核
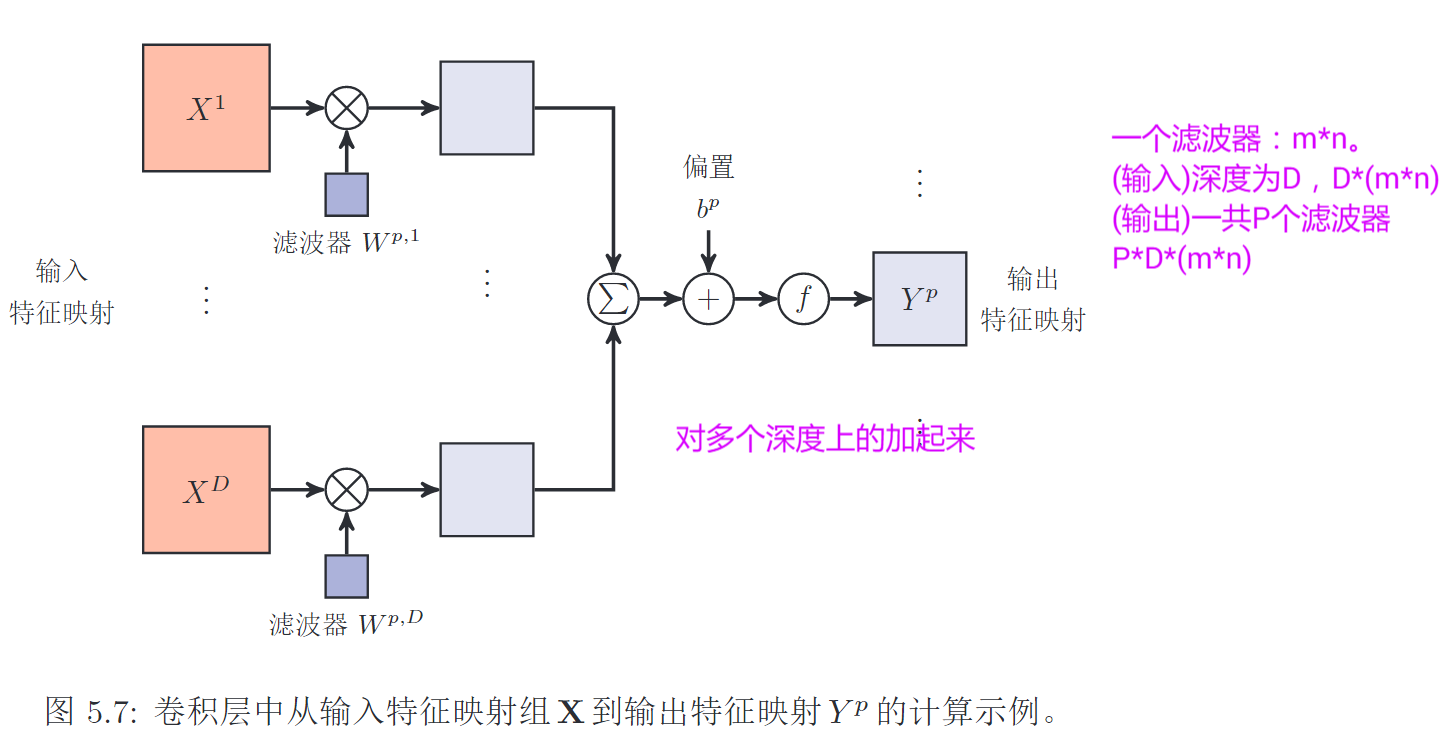
2. 多个卷积核
多个卷积核可以提取出多种不同的特征。输入图片是
in_channel、out_channel
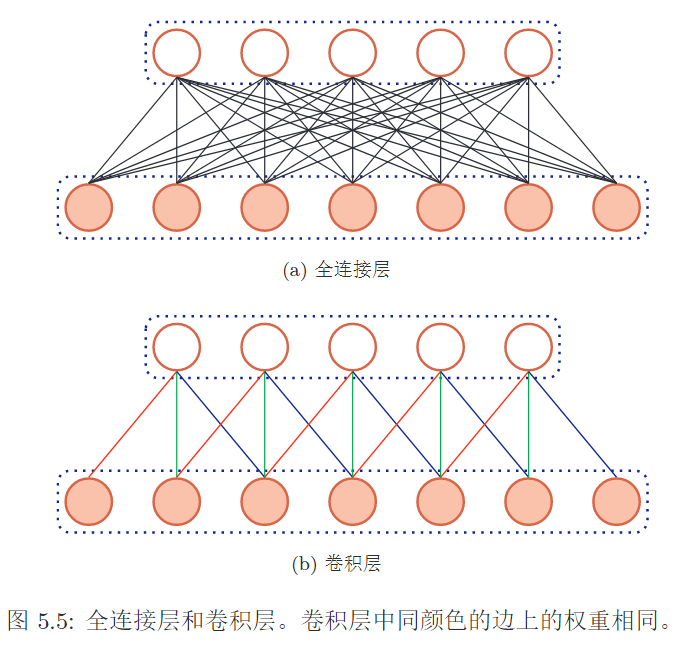
- 局部连接:卷积核只与输入的一个局部做连接,计算出FM中的一个值,局部性
- 权值共享:同一个卷积核与图片的各个位置进行连接,权值是一样的,提取出同样的特征
1. 局部连接
2. 权值共享
- 卷积层的不足:FM的维数很高
- 汇聚层的作用:选择特征、降低特征数量、减少参数数量、避免过拟合
- 两种汇聚方式:最大和平均。
1. 卷积层的不足
2. 汇聚层的作用
汇聚层(pooling layer),也作子采样层(subsampling layer)。作用是:
不变性3. 两种汇聚方式
过大采样区会急剧减少神经元的数量,造成过多的信息损失!
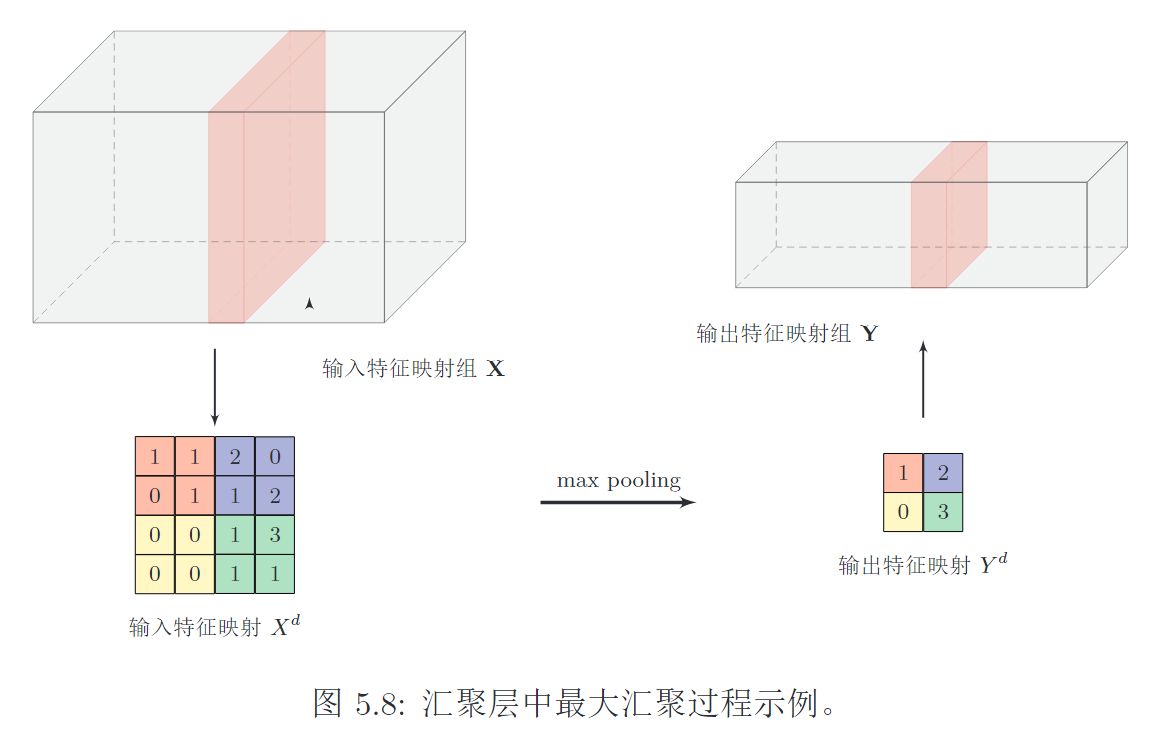
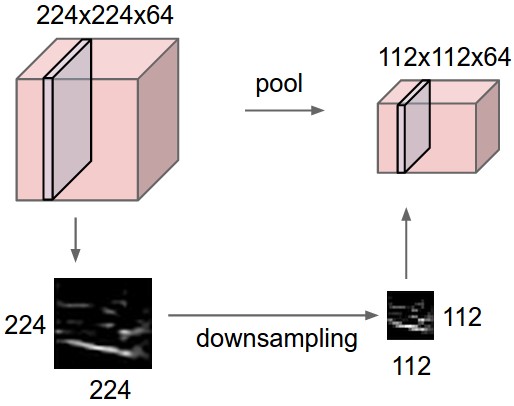
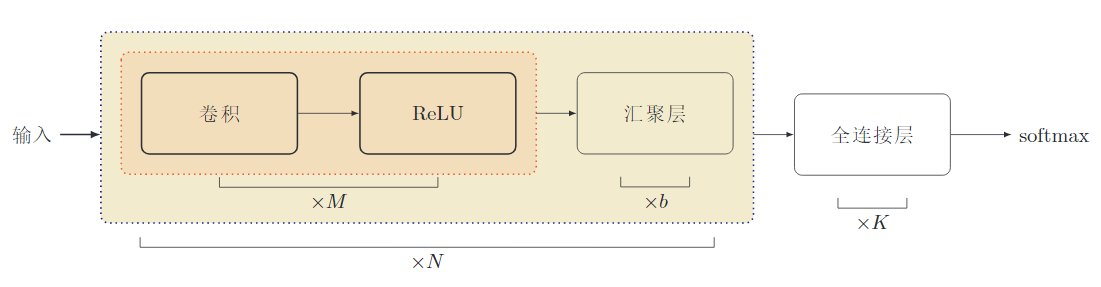
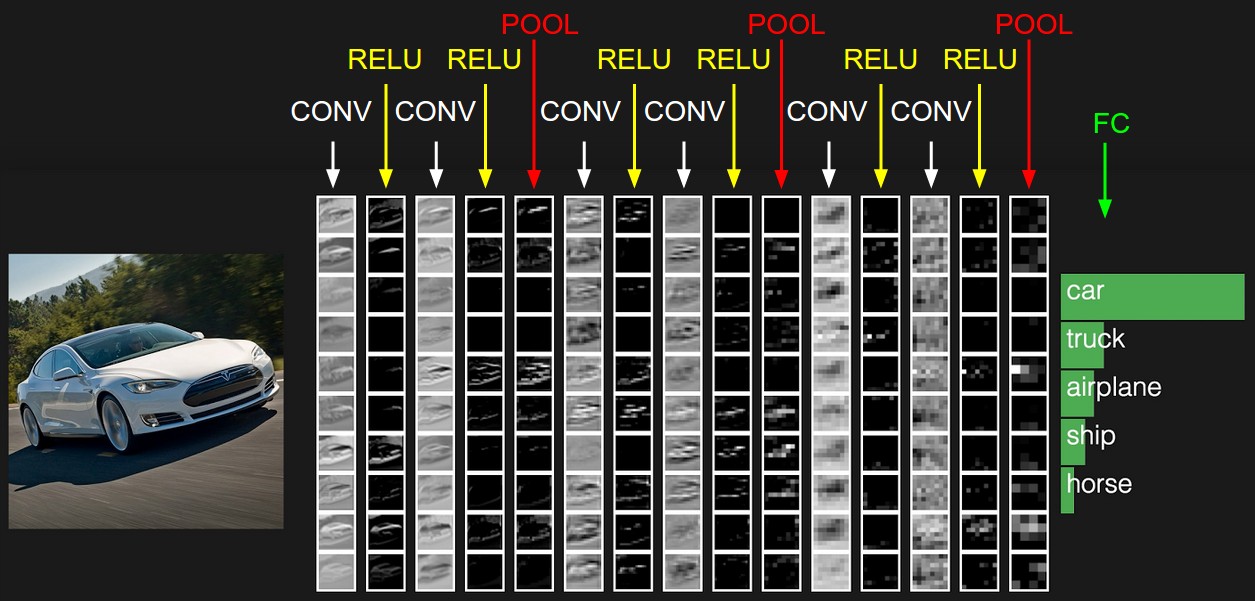
由多个卷积块组成,一个卷积块:
目前,趋向于使用更小的卷积核,比如
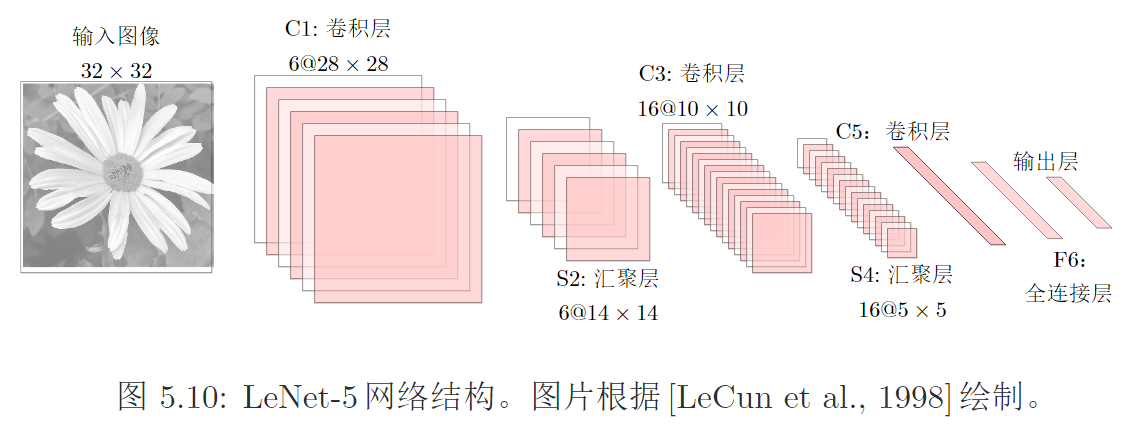
使用ReLU作为非线性激活函数、Dropout防止过拟合、数据增强提高模型准确率。
AlexNet分组卷积
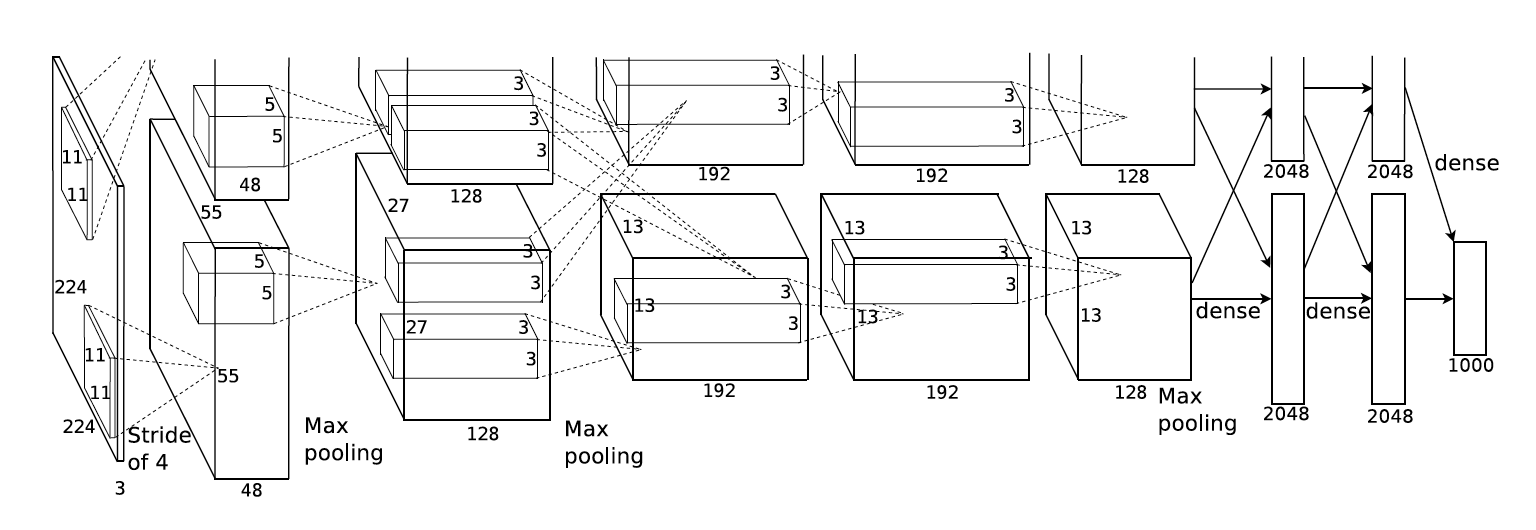
如何选择卷积核大小非常关键:
Inception Net由多个Inception模块堆叠而成。一个Inception同时使用
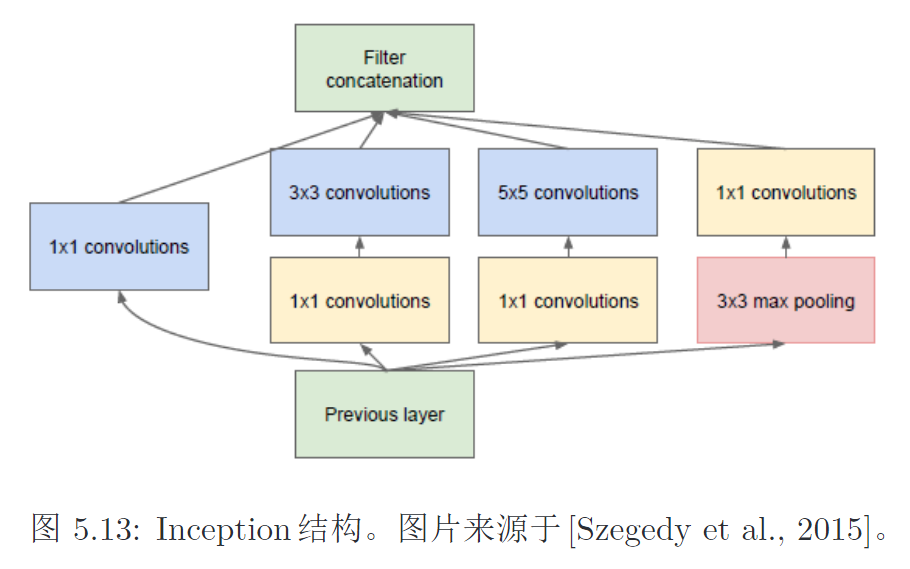
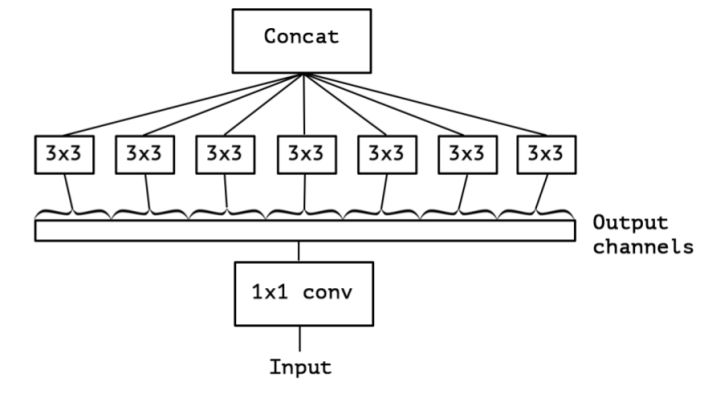
后续还有各种各样的Inception Net,最终演变成Xception Net。
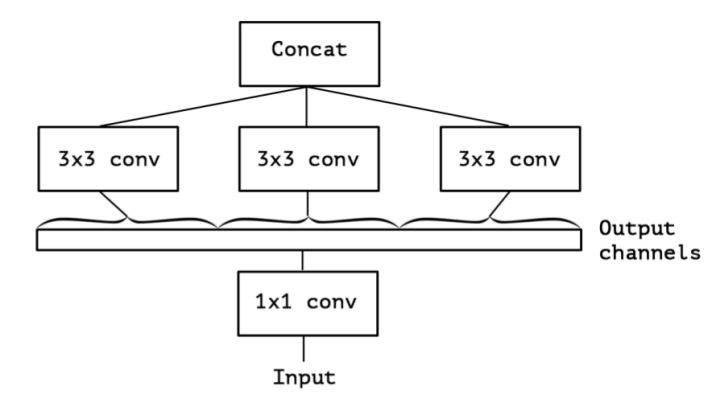
Inception Net的极限就是,对每个channel做一个单独的卷积。
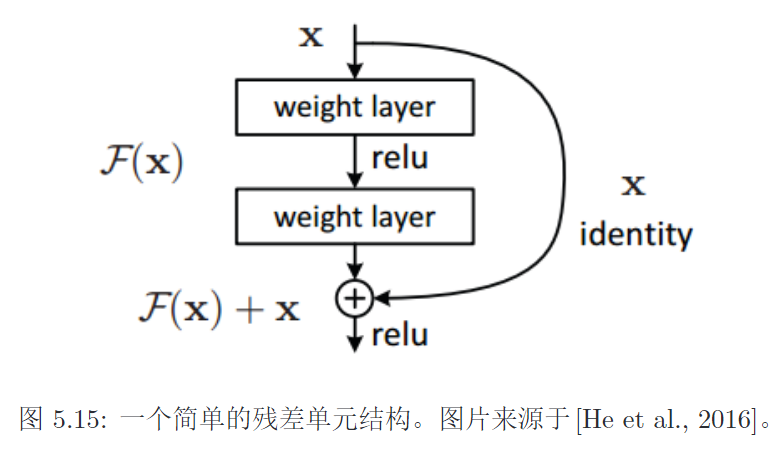
越深的网络可以用ResNet来训练。ResNet可以很深的原因
残差连接通过给非线性的卷积层增加直连边的方式
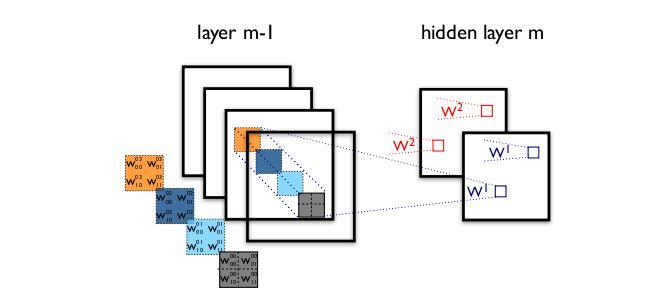
卷积需要同时考虑所有通道吗?
输入图片(feature map)是
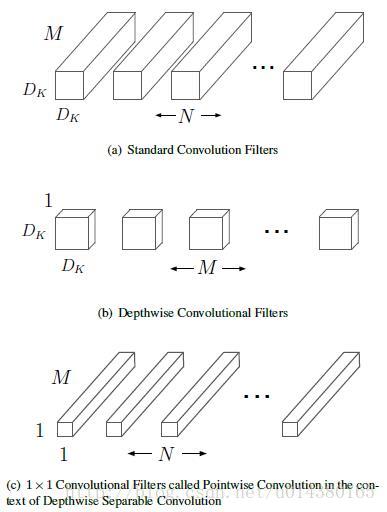
1. 传统卷积核会同时考虑所有通道
2. 深度可分离卷积核
Depth Separable Convolution
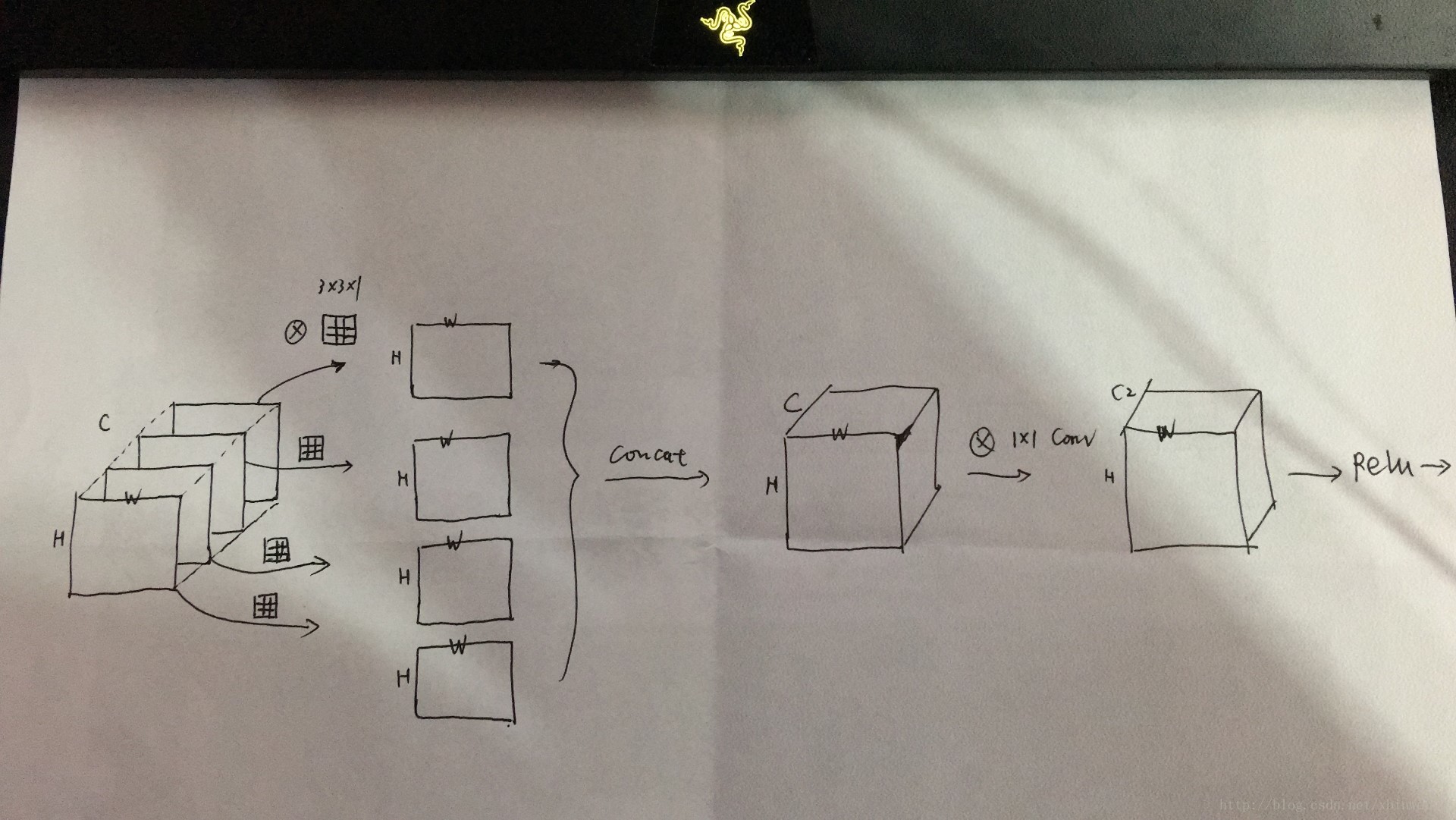
输入数据有D个FM,输出P个FM。深度可分离卷积(DepthWise Convolution) 如下:
PointWise Convolution),卷积操作不一定需要同时考虑通道和区域。可分离卷积。
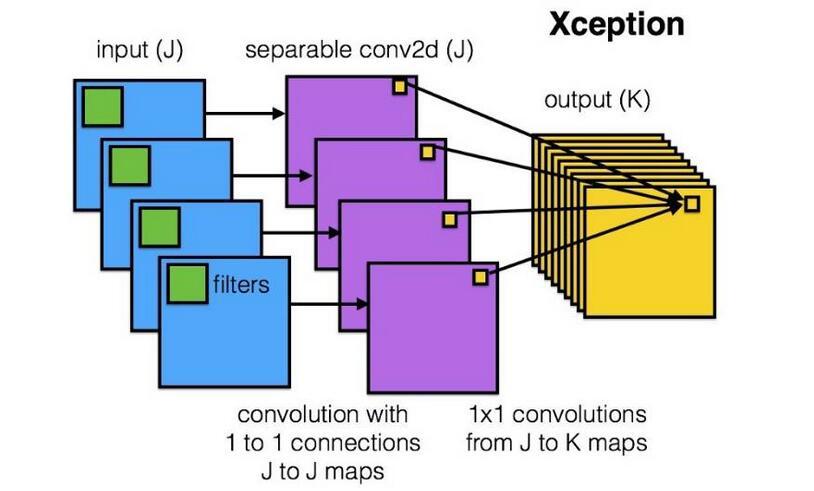
3. 可分离卷积参数大大减小
输入通道
同时,效果更好。
1. AlexNet分组卷积
2. ShuffleNet 分组卷积
ShuffleNet = 分组卷积(通道分组)+ 深度可分离卷积(Depthwise+PointWise)
对通道进行分组卷积时

Inception、ShuffleNet等网络中,对所有通道产生的特征都是不分权重直接相加求和的。
为什么所有通道的特征对模型的作用是相等的呢?
1. 卷积核
2. 卷积层通道
3. 卷积层连接