Code Survey
📅 发表于 2025/12/06
🔄 更新于 2025/12/06
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
code
#survey

AI Coding 思想
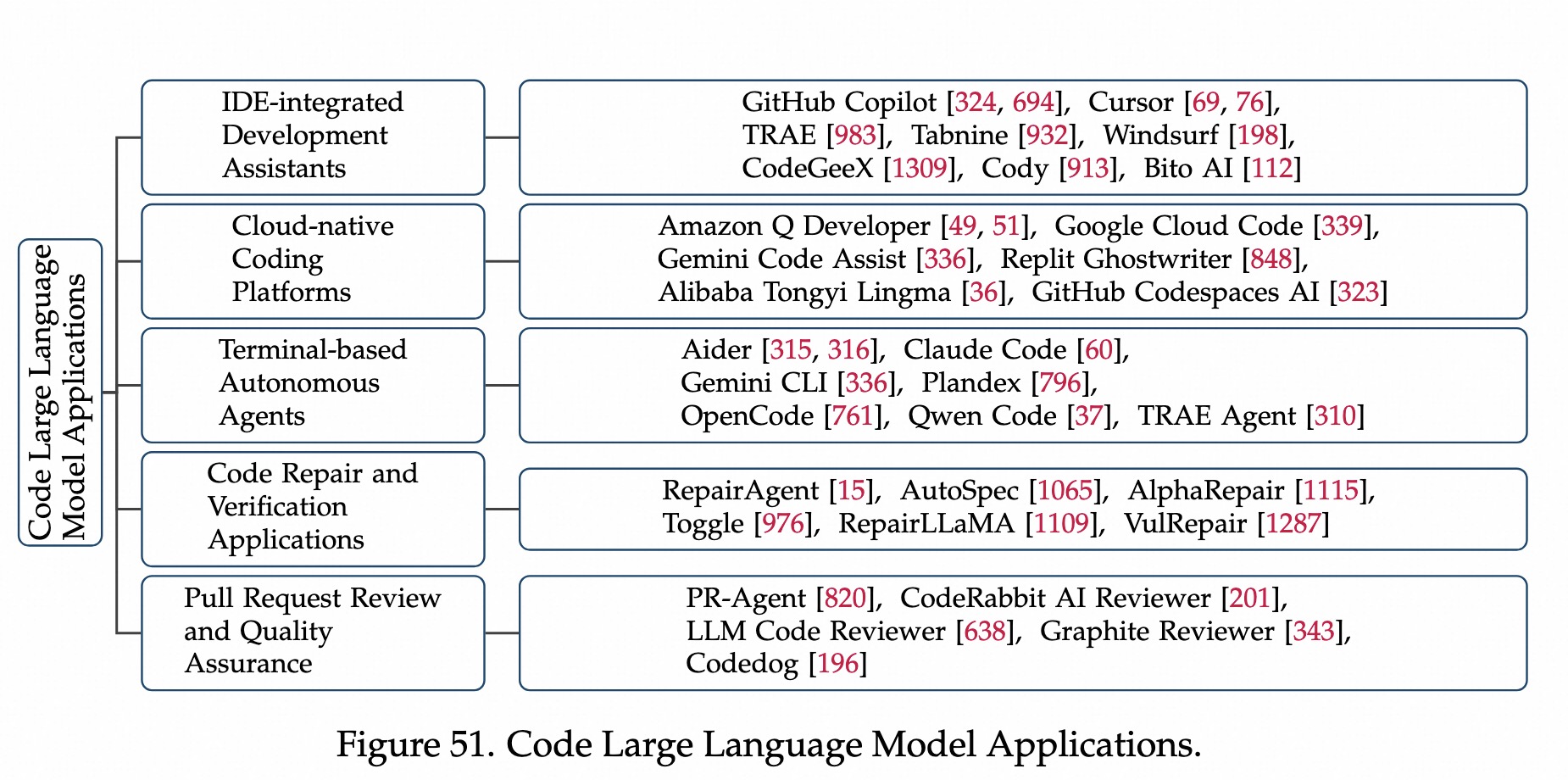
Github/StackOverflow/code网站资源,把多年编程经验提炼成指令跟随的工具。相关工具
GitHub Copilot:VSCode 插件Cursor:对话式编程Claude Code/Gemini CLI:命令行级别,agentic-coding-workflow。 两种分歧
自然语言+编程数据 混合预训练,在上下文/意图/领域知识等理解细致。编程数据预训练+算法架构优化。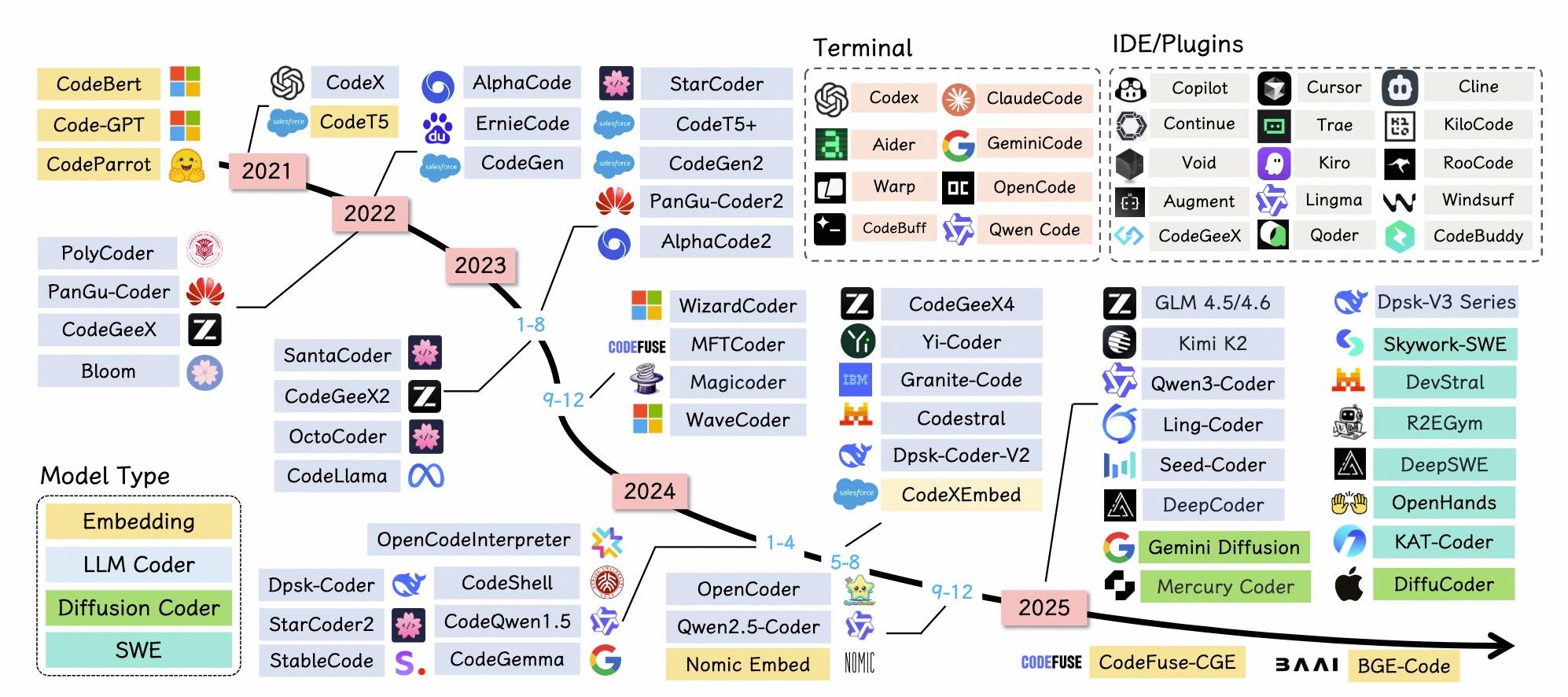
1. 数据清洗策略
平衡数据质量和数量? 指令跟随? 2. 对齐技术
符合人类习惯、是安全的,如何根据人类反馈来做对齐?3. 高级提示范式
4. 自主智能体
5. RAG
先看文档,再写代码,保证准确性。6. 评估框架
2元的(仅看正确性)。烂不烂、效率如何、可维护性如何?Transformer 和 Scaling Law
Transformer 一统江湖预训练和知识迁移,把多种统一到一个支持多种任务和模态的可扩展框架。Scaling Law 大力出奇迹LLM爆发出代码能力
代码结构 和人类自然语言在底层逻辑上是相通的。LLM + 外部工具 变身 决策agent
外部工具:计算器、搜索、代码解释器等等。思考行动观察Loop:思考 -> 行动 -> 观察 -> 思考 -> 行动 -> 观察 ....突破、局限、CodeLLM动机
通用模型 在代码领域有局限性: 准确性(复杂代码不会写)、安全性(有bug代码)、可靠性(系统级可靠性差)专有的代码大模型代码生成:HumanEval上的效果

修bug:SWE-Bench上的效果

1. Dense Model
2. MoE
3. Recurrent Models
4. Diffusion Models
5. Hybrid Architechures
视觉能力,需要查看图表、截图、UI元素等内容。核心缺点
有广度、无深度具体表现
专业和准确性不足看起来对的代码,实际可能一跑就崩安全和可靠性不足有bug仓库级理解不足lost-in-middle。 跨文件的变量引用、依赖关系,模型经常搞不清楚,导致无法理解整个项目。多模态障碍/看不懂界面细节不会用工具(Agentic限制)通用模型容易出现工具幻觉:假装调用了工具,或者编造了工具的输出。长程推理),模型很容易这就“晕”了,忘记之前的步骤或偏离目标。用模型写代码不够,需要
数据清洗:去掉不安全的代码。预训练/微调:让模型理解代码结构和跨文件依赖强化学习:教模型如何正确使用工具和进行长期规划
从通才到专才
特定领域优化有效果。继续分化Agentic训练&复杂场景攻克
被动代码生成向主动软件工程转变,在复杂、多步编程场景自主操作。Scaling Law
科学Scaling策略:是把钱花在模型参数、还是清洗更高质量数据。MoE大势所趋。目的:使预训练模型能遵循指令有效完成code任务,通用llm -> codellm。
SFT:覆盖代码生成、修复、翻译等。
RL:通过奖励信号来修正模型。
如何构造出比CodeAlpaca更好的训练数据?
由浅入深:复杂性,解决太简单的问题
CodeAlpaca 问题太简单让GPT4把问题变难,提升问题复杂性。 由窄变宽:多样性,解决太重复的问题
引入人类编写的数据(Natrual-Instruct),来丰富多样性 启发式规则和语义相似度,筛选出多样化的数据。验证数据的正确性。由粗到细:精细度,解决不听话的问题
如输出格式)。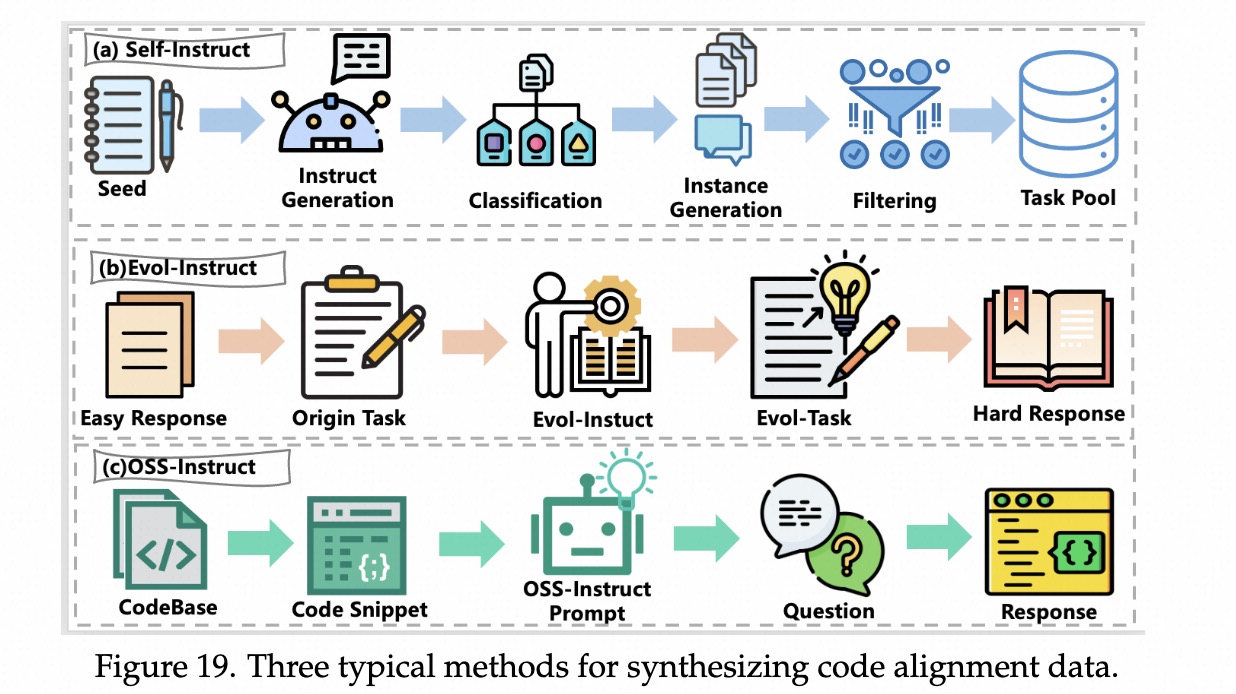
执行反馈
Multi-Agent
训练多轮 预测单轮的问题 总结轮。初期,模型全看,学习中间修改过程;后期:逐渐屏蔽中间过程。背景
跨文件依赖、多文件编辑、长上下文推理等实际软件工程的场景。SWE 数据集
SWE数据是训练自主编程agent的基石数据。SWE-任务 笔记可扩展流程,从Github仓库生成大量的任务实例,数据量比之前提高一个数量级。可验证的bug修复数据。 bug修复对、测试用例和结构化的修复轨迹。feature功能开发,1.4万训练数据,500评估数据代码补全和仓库导航
自动补全,10k Python和14k Java库。代码编辑,预测编辑位置,5种语言,471项目、180k的提交。挑战
AI黑客/进攻网络安全型 数据
大模型扮演环境,脑补输入这个命令,输出可能的结果推理范式
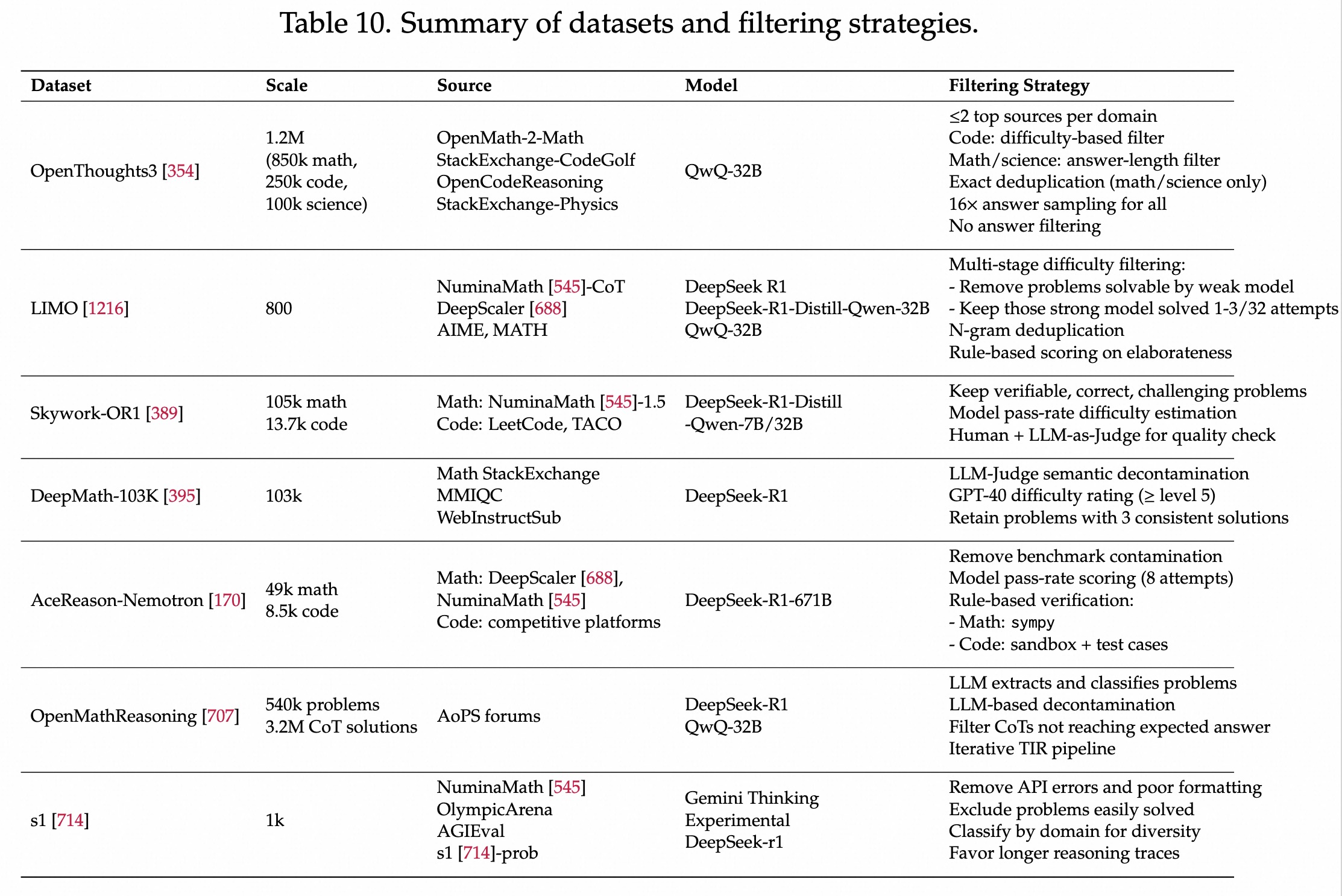
面向推理的SFT
质量 > 数量难题,特点:包含探索、回溯、自我验证等。干练精简。避免CoT输出废话。训练数据剔除没用的废话。拒绝采样FT和RL
数据质量筛选
多任务平衡
去噪策略
数据泄露
数据偏差
多语言不足、数据不平衡
少数高质量比数量更重要
发展方向
目的
推理轨迹,提供认知模板,指导模型学习。方法:大模型蒸馏 + 格式处理
代表工作
具体工作
总结
高难度可验证的数据集。背景
基于元推理的评分
一致性验证
反直觉:不过滤也很好
数据效率高、计算成本低多种任务。发展
数据
大规模多源数据 (10TB+)生态
近期趋势
早期:python为主
多语言爆发
趋势:复杂真实
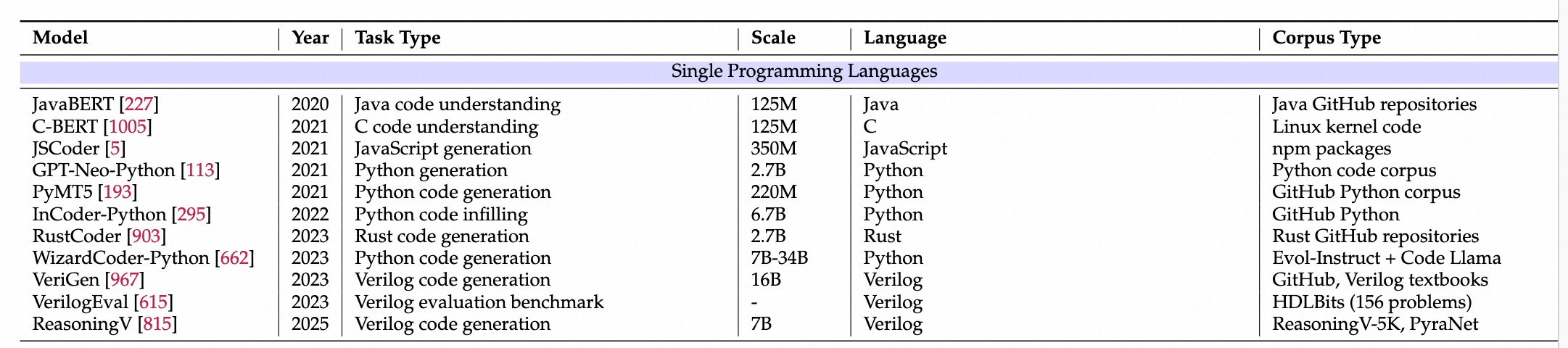
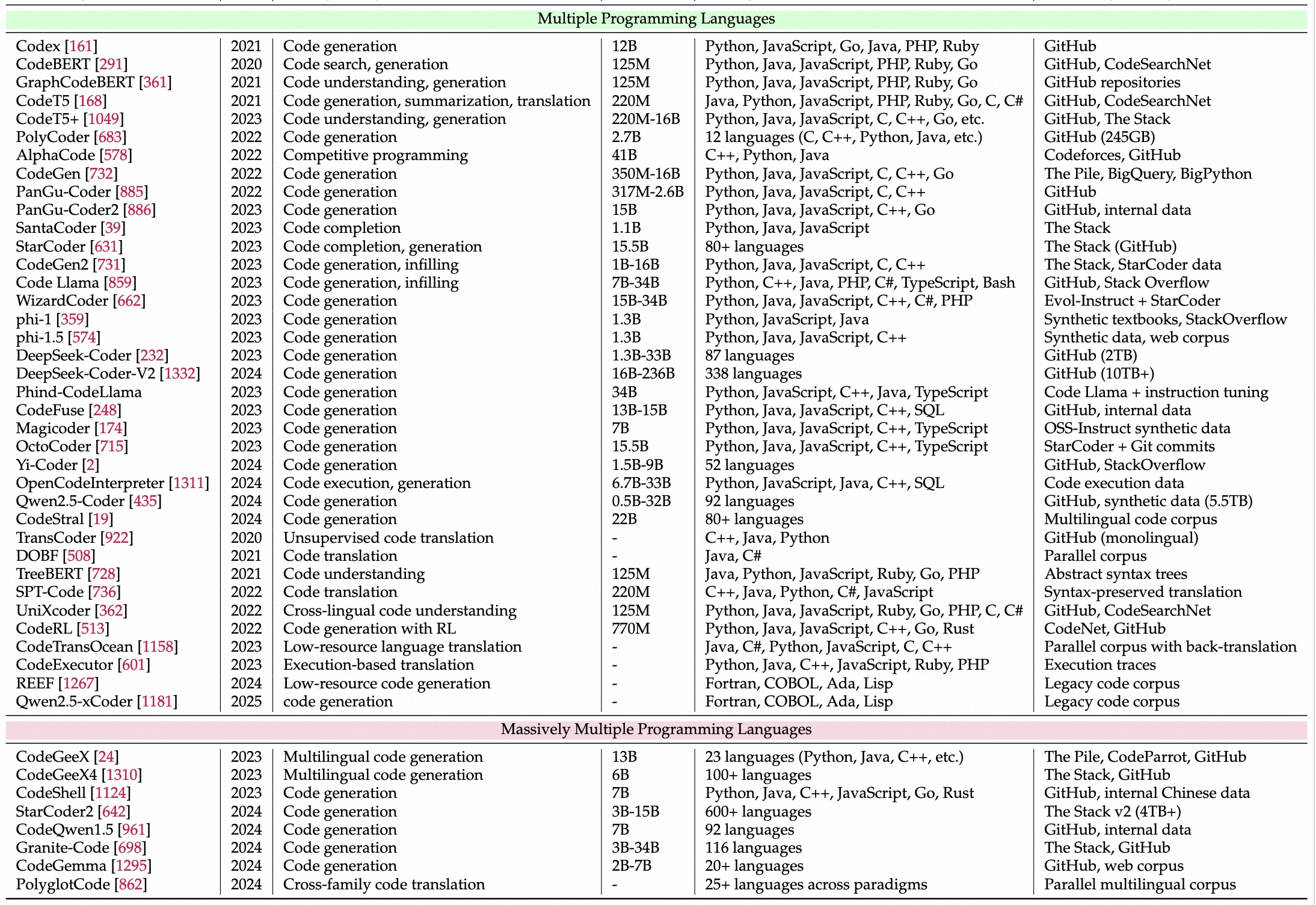
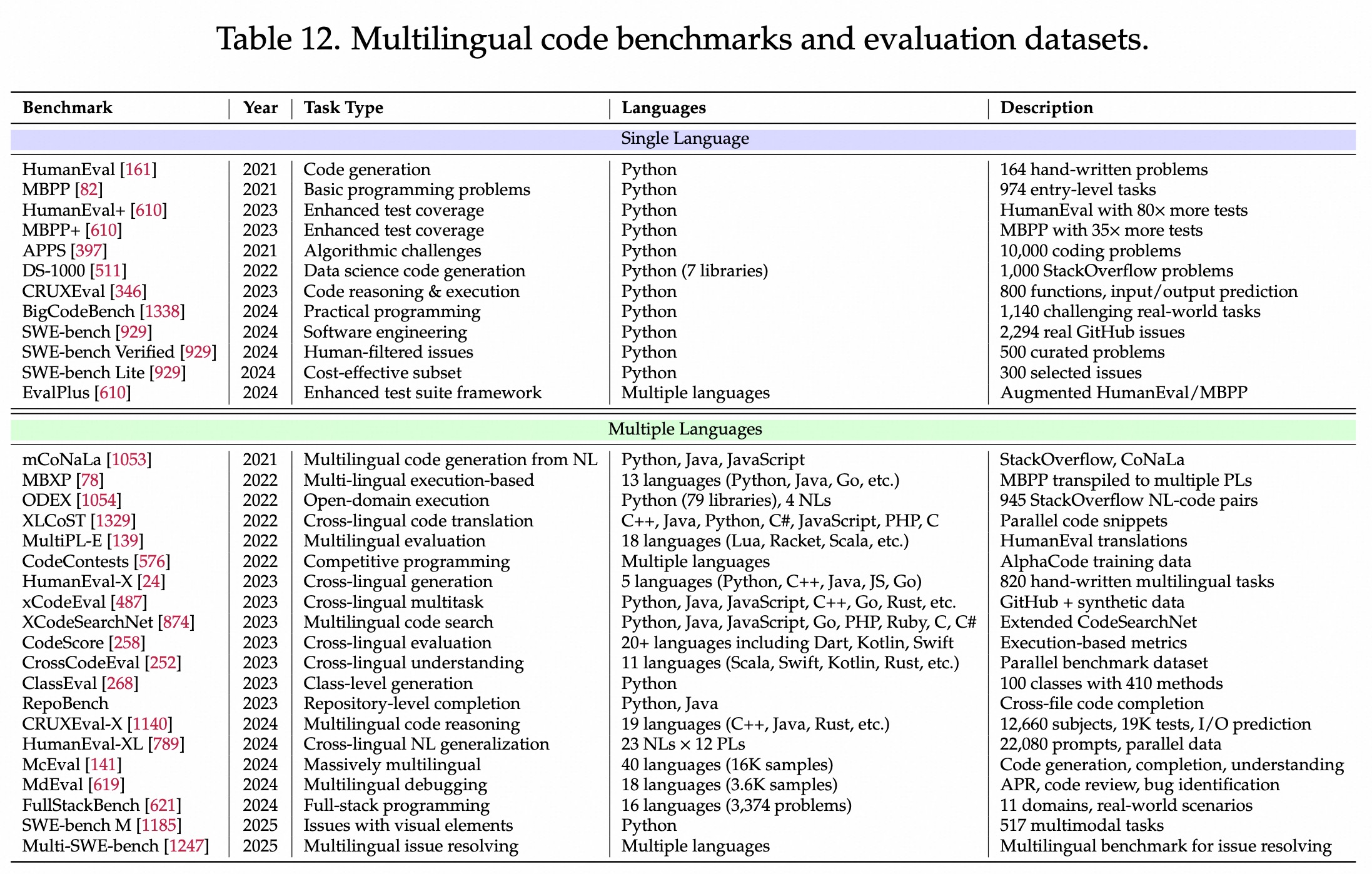
整体benchmark
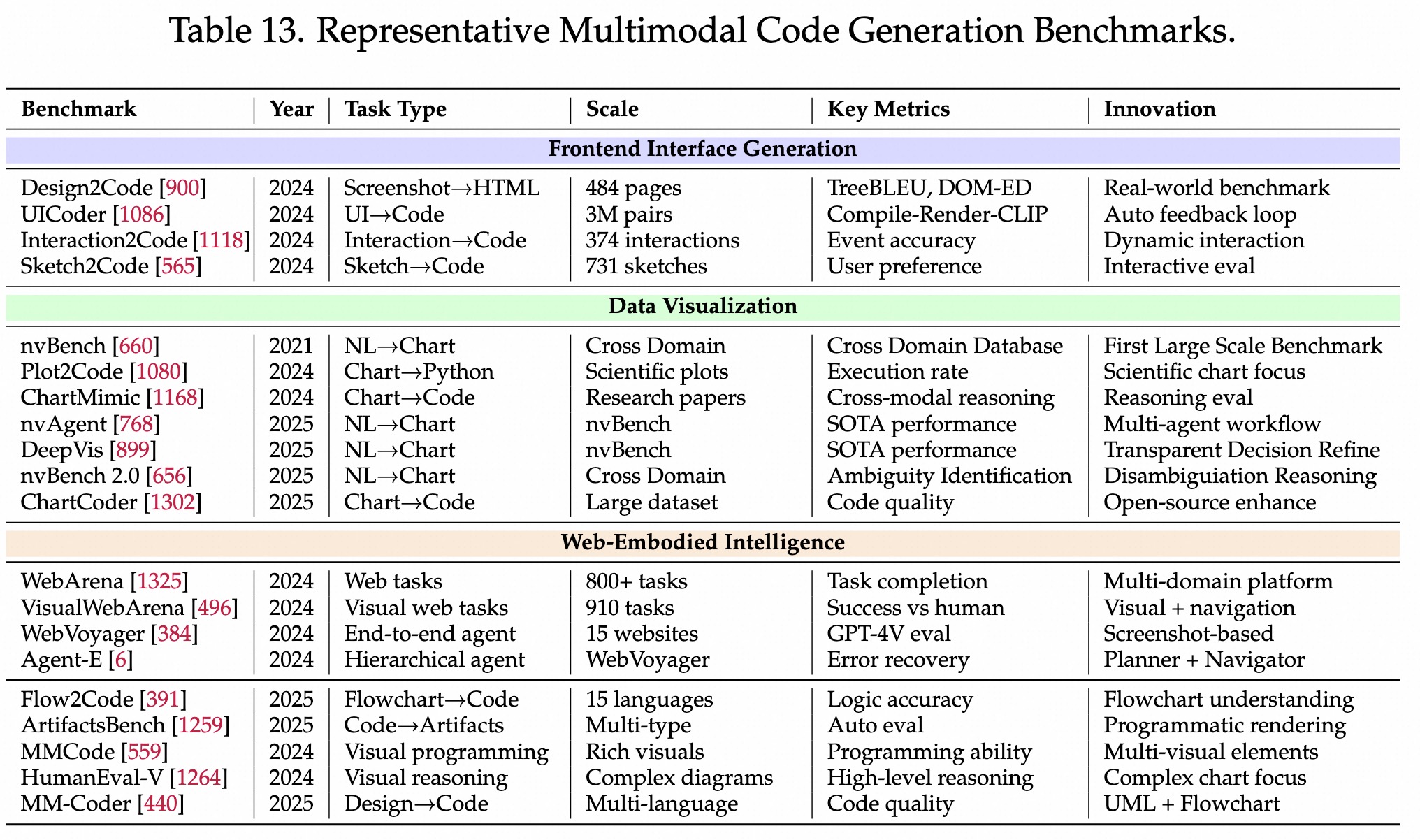
对齐和桥接高分辨率挑战grounding(操作UI)、OCR(看清截图)、动态分辨率能力。3个维度scaling。MoE架构,针对真实世界截图、文档、图表等。原生多模态能力多模态Code
挑战
分类
Image2Code(早期)
Design2Code (标准化,意图实现)
Design2Code:43k <网页截图, HTML>数据,系统评估9种MLLM能力 Prototype2Code:使用Figma API 来构建9k <真实原型, ReAct代码> 数据Sketch2Code (草图)
Interaction2Code (动态)
技术1:分而治之。分层生成和布局建模:
先画骨架、再填细节。降低上下文长度需求。技术2:看着改。自动反馈和自我修正Loop
Compile-Render-Clip流程检查代码能不能运行,再浏览器运行截图,再使用CLIP对比相似度。浏览器截图+视觉编码器来修复样式和无效逻辑。生成-诊断-修复循环,利用MLLM做critic训练。技术3:像产品经理一样去思考。Agentic 工作流
草图 -> PRD -> 代码
核心
observe-reason-act。阶段1:基础框架
阶段2:特定任务
长规划任务。截图,模拟人类操作网页。GPT-4v做评估。阶段3:游戏环境
人类视频中学习如何行动,利用少量逆动力学标注数据。视觉游戏生成,2219 Pygame Benchmark。多模态评估:代码正确性、视觉质量、游戏动态方面。阶段4:架构升级
planner + browser navigator阶段5:Multi-Agent:群体智能
阶段6:工具增强的多模态推理
LLM控制,调用视觉模型完成多步推理。除了代码以外,Artifacts在整个软件工程周期,都很重要
数据可视化: 最活跃领域
软件图表和模型生成
多模态软件工程任务
视觉bug修复,js开发,问题
ArtifactsBench:像用户一样评估
多模态评估:使用GPT-4v或Gemini多模态大模型做评估。 代码正确性、视觉保真度(颜色、字体、布局)、交互完整性(选题、点击、拖拽)广泛应用 Agentic Workflow
自我修正&迭代优化
编译-渲染-Clip 三重反馈,DesignCoder 浏览器截图自查生成-诊断-精炼。Code-in-the-Loop 评估
多模态渲染评估。分层生成

痛点:需求是模糊的
最难的是搞清楚到底要写什么。人类客户说的话往往是模糊、矛盾、不完整的。
传统做法: 靠产品经理(PM)和业务分析师(BA)去开会、吵架、画图、确认。
Agent 做法: 用 AI 扮演不同角色来模拟这个过程。
Agent 如何解决四个阶段的问题
总结:AI 在软件工程中的角色跃迁
软件工程 Agent 正在向左移(Shift Left)。
以前的 AI(如 Copilot):帮你补全代码(开发阶段)。
现在的 AI(如 SWE-Agent):帮你修 Bug(测试/维护阶段)。
未来的 AI(本节内容): 帮你做产品设计、需求分析(需求阶段)。
这意味着 AI 开始具备了同理心(模拟用户)、批判性思维(多智能体辩论)和全局规划能力(端到端流程)。
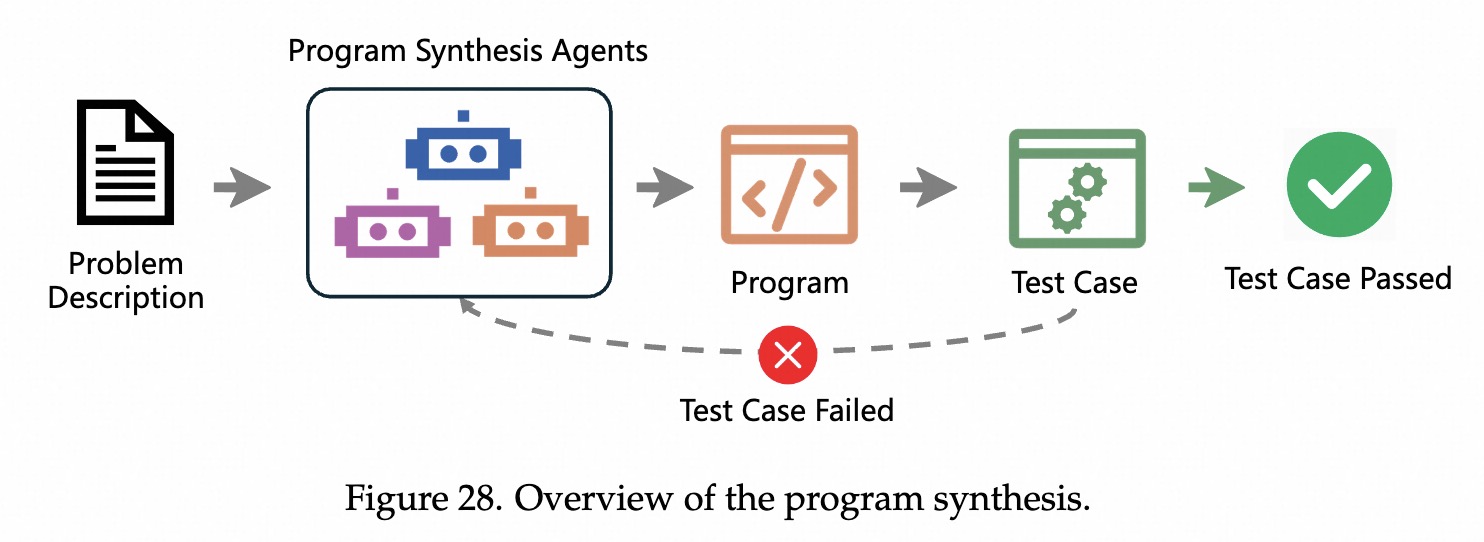
程序合成
程序合成 Agent 远不止是我们在 IDE 里见到的代码补全(如 Copilot)。它们通过引入多步推理、基于测试的验证和反馈驱动的优化循环,试图从零开始构建完整的程序,而且尽量不需要人插手。
1. 问题定义(图 28):
2. 架构设计:一个好汉 vs 三个帮 目前的 Agent 架构主要分两派:
3. 核心引擎:反馈驱动的代码搜索 (Feedback as the Engine) Agent 成功的秘诀不在于一次写对,而在于怎么改对。反馈(Feedback)就是把“生成”变成“搜索”的关键。 文中提出了四种“改代码”的策略:
4. 进阶挑战:从函数到仓库 (Scaling to Repository-Level) 写一个函数容易,写一个完整的 GitHub 仓库(Repository)很难。
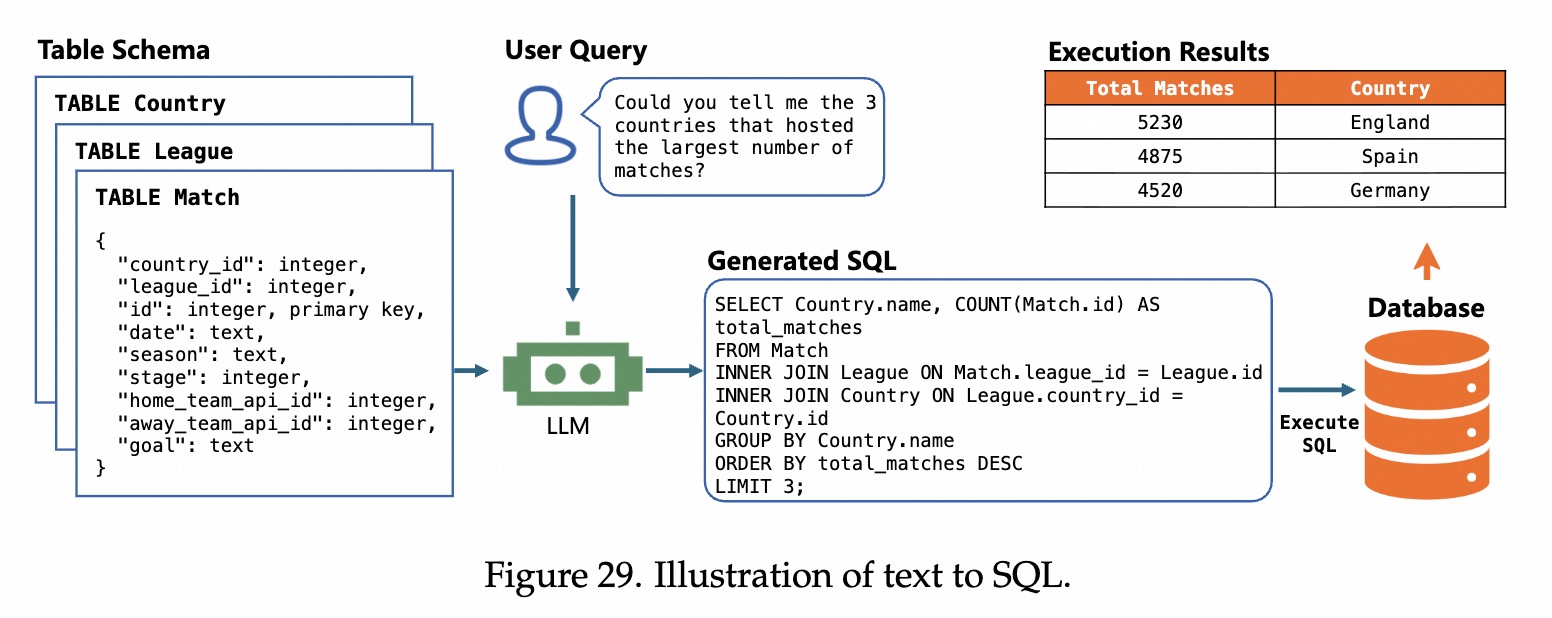
程序分析
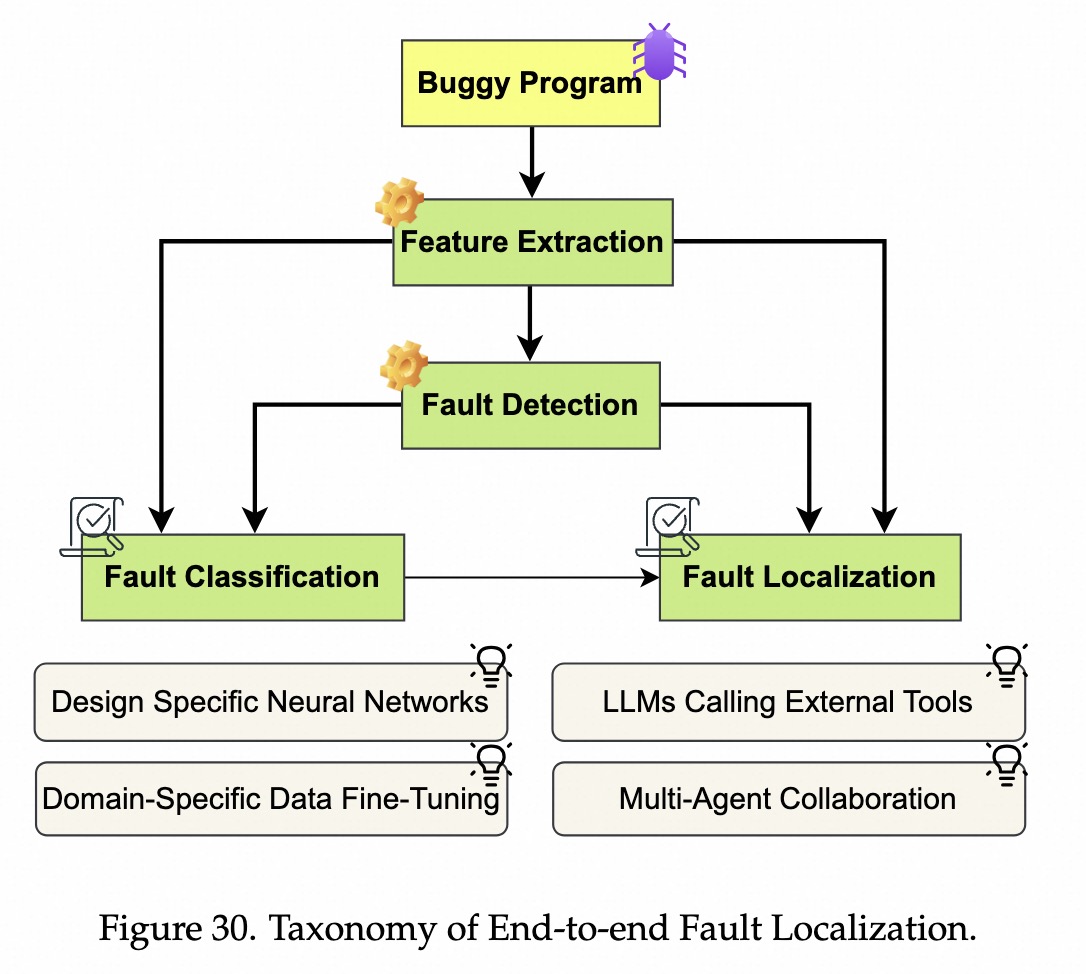
分为补丁生成(Patch Generation)和问题解决(Issue Resolution)。
任务定义
修复补丁Patch。最核心步骤。技术演进1:微调和Prompt工程
bug-patch数据做SFT提升能力,或使用CoT Prompt引导模型一步步推理Bug原因。技术演进2:任务转化
技术演进3:静态分析和模板指导
技术演进4:RAG增强
技术演进5:多智能体和对话流
最前沿方向。bug定位、Patch生成、测试验证到一个循环,协调多个agent或工具去动态修复。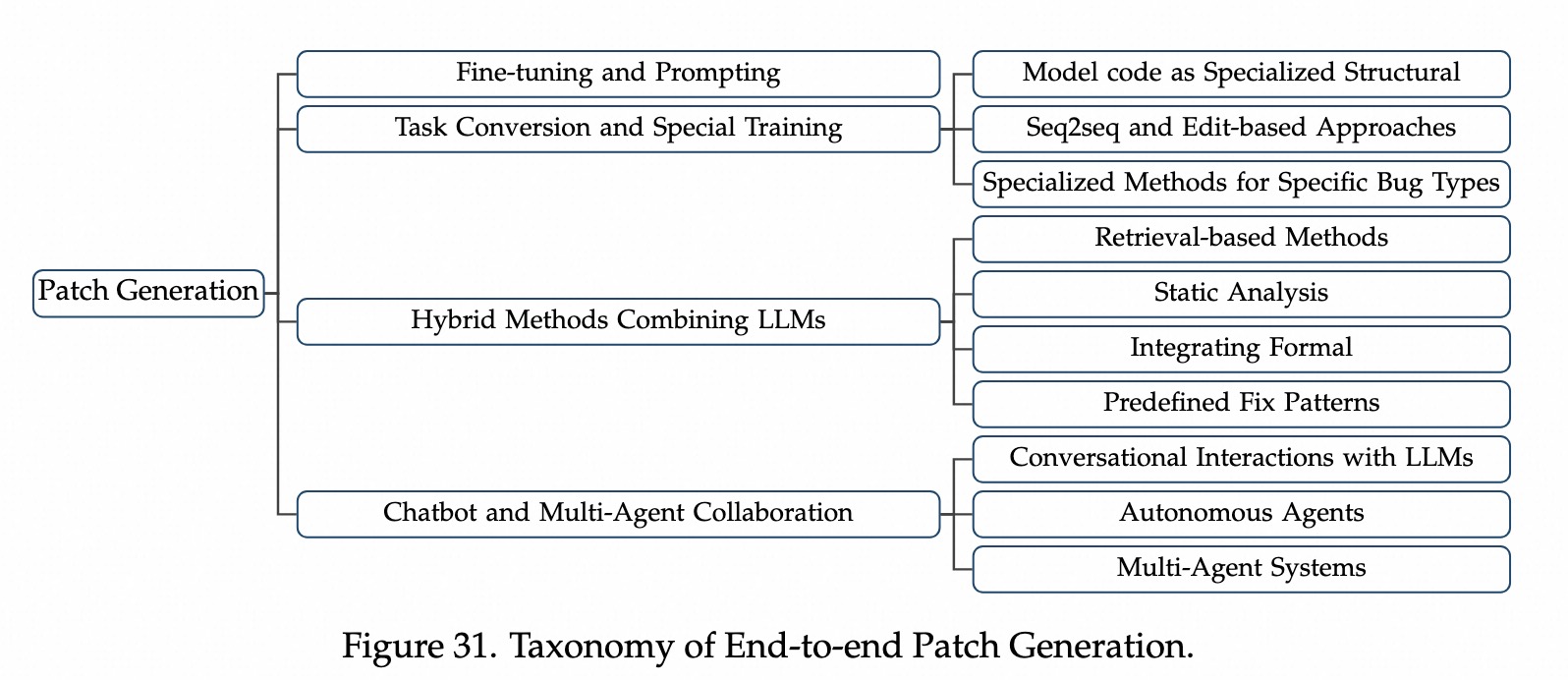
问题定义
找代码、找定位、修复、测试、提交PR。全局的。Fault Localization:在几百个文件里,找到哪一行代码导致bug。最难。Program Editing:修改代码,生成补丁。Validation:跑测试用例,确保bug修好、且没有新bug。技术演进
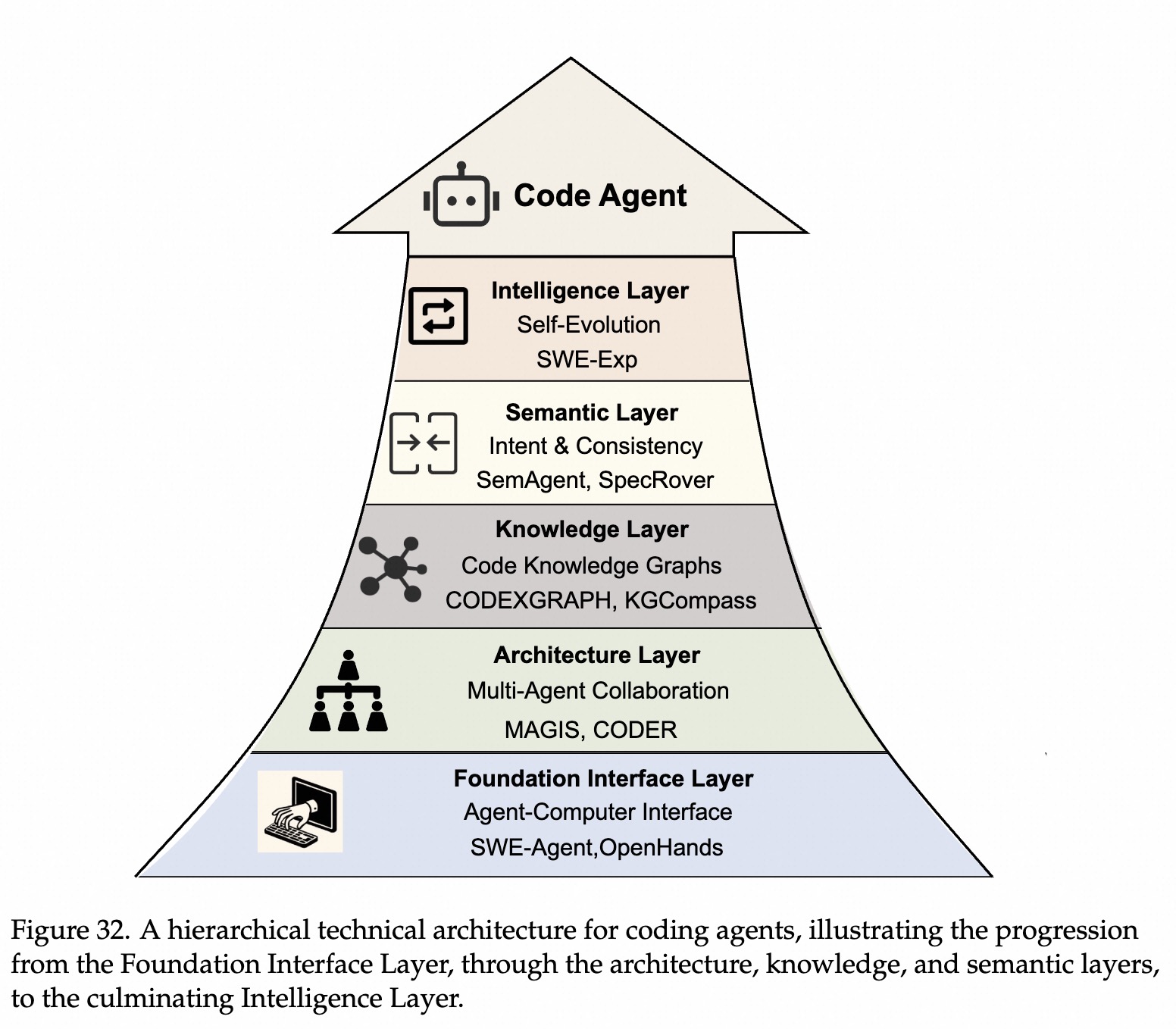
基础接口层
LLM容易理解且不容易写错的特殊指令。筛选关键错误信息给到模型,并非给全部错误,解决上下文爆炸问题。自动回滚:AI改坏代码导致环境崩溃,ACI能自动检测并恢复到上一个版本。动态历史折叠:历史记录会变长,ACI可以自动总结隐藏不必要历史操作,只保留关键记忆。架构层
代码理解、依赖分析、故障定位、补丁生成、验证。知识层
结构化知识建模,特别是把代码库表示成图,有用。语义层
智能层
持续学习和自我进化。ACI 接口 示意图
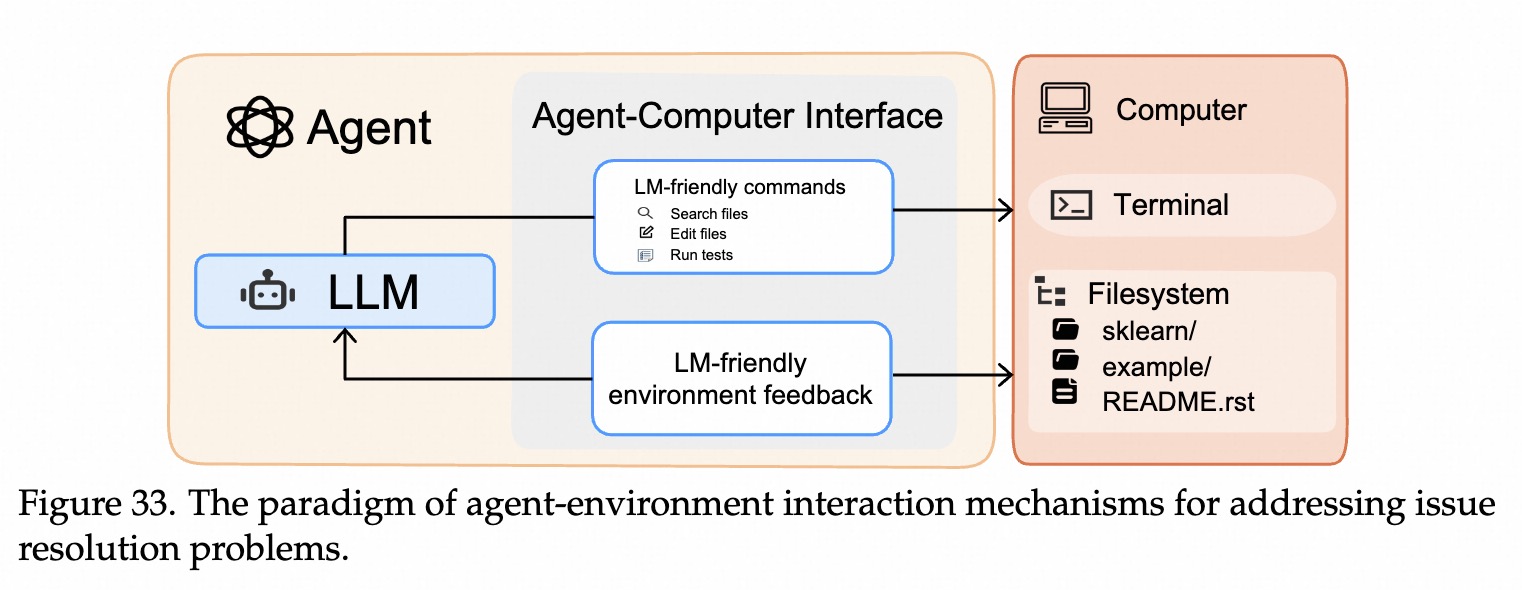
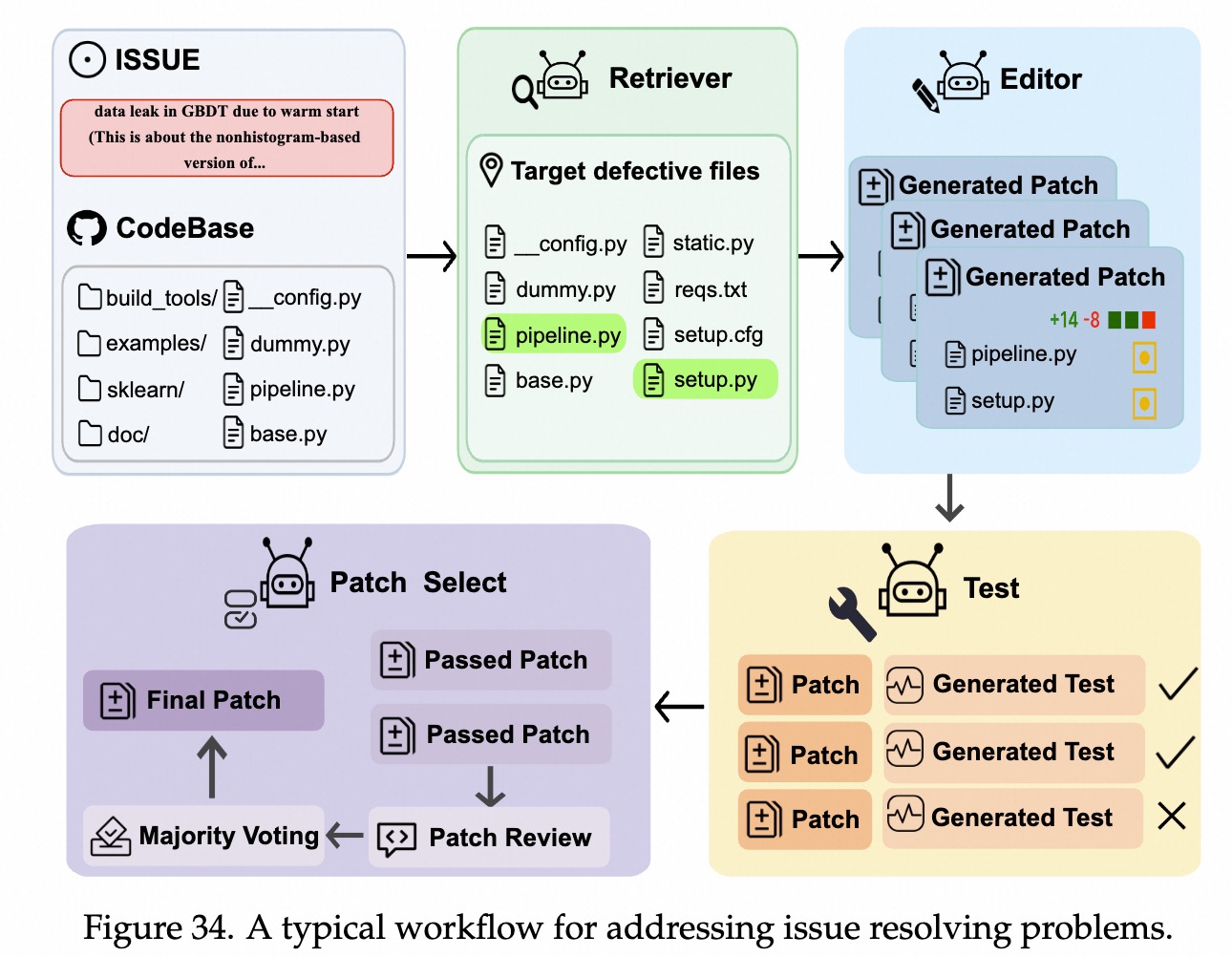
Issue Resolving 典型workflow示例:
背景
核心技术
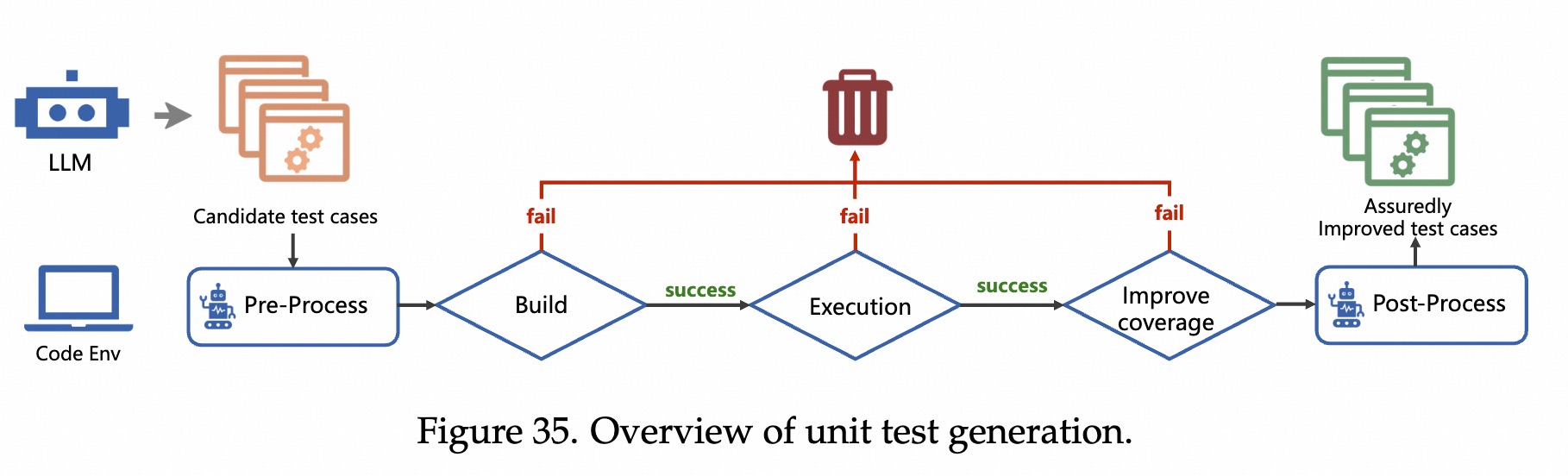
if (x == "magic_string") 检查。LLM 擅长理解代码逻辑。CodaMosa 结合两者,当传统工具卡住时,让 LLM 生成代码来突破覆盖率瓶颈。NameError,然后自己读取报错,修正代码,直到测试通过。这就是文中提到的从 One-shot 到 Multi-step 的转变。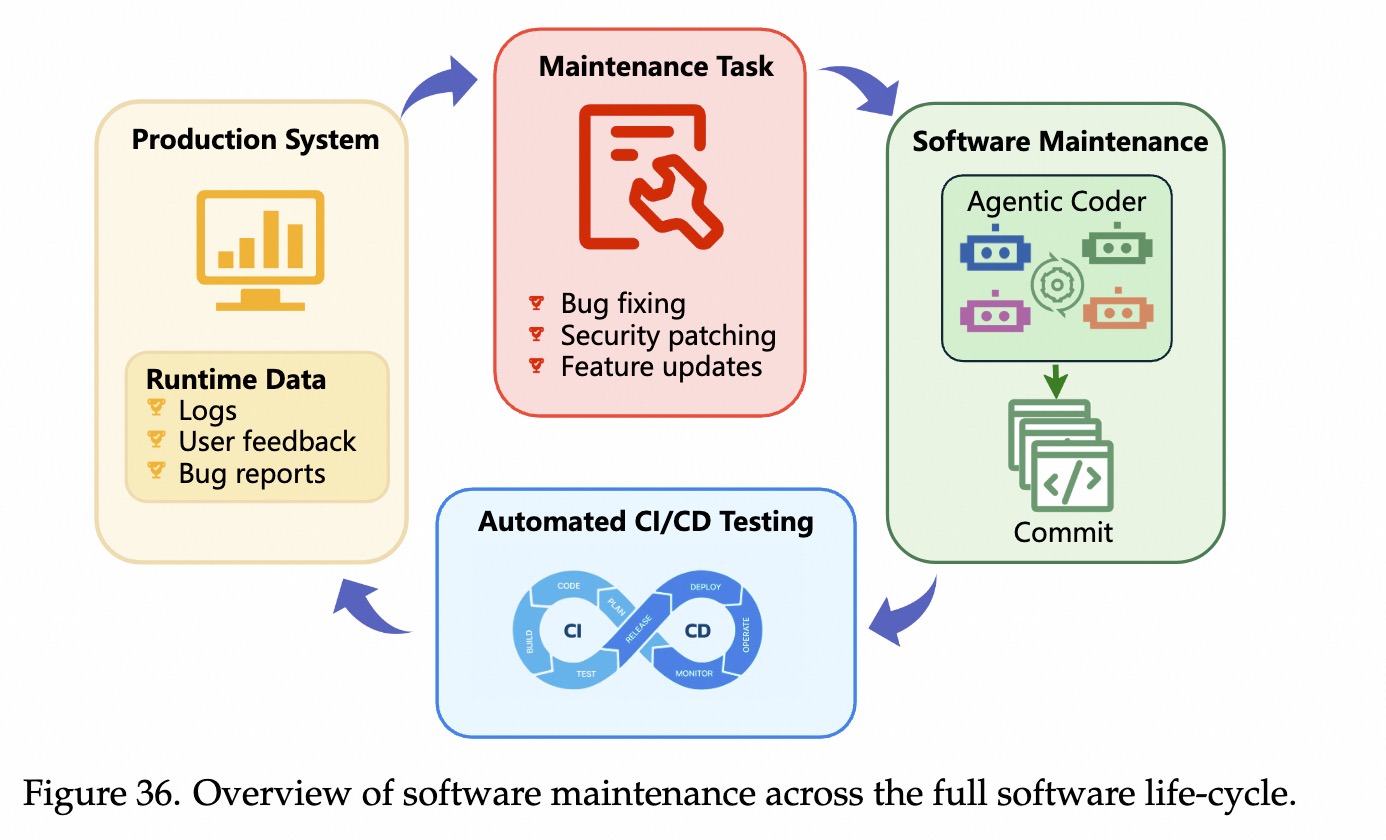
A. 从“翻译”到“理解”:反编译与日志分析
Error 就报警)。现在的 Agent 是**“运维侦探”**。它看到报错后,会自己去查知识库、去对比历史日志、去分析代码变更,然后告诉你:“这个错误是因为昨天张三提交的 DB 配置改动导致的。”v1 = v2 + v3,结合上下文发现这是个银行转账逻辑,它会把代码重构成 balance = old_balance + deposit。这极大地降低了逆向工程的门槛。B. 编译器优化:AI 的“炼丹炉”
编译器优化本质上是一个在一个巨大的搜索空间里找最优解的问题。
C. DevOps:从脚本到“数字员工”
| 特性 | 瀑布流模式 (Waterfall) | 敏捷迭代模式 (Agile) |
|---|---|---|
| 代表 | ChatDev, MetaGPT | AgileCoder, LCG |
| 工作方式 | 线性流水线 (A -> B -> C -> D) | 循环迭代 (Plan -> Code -> Test -> Plan...) |
| 优点 | 结构清晰,SOP 标准化,适合明确的小任务 | 灵活,容错率高,适合复杂、需求模糊的任务 |
| 缺点 | 上游犯错,下游买单;缺乏灵活性 | 流程复杂,Token 消耗大,管理难度高 |
| 人类隐喻 | 传统外包工厂 | 现代互联网创业团队 |
希望构建一个Agent,能跨越整个软件开发周期,而不是只为一个任务做的agent。
核心能力
直接让模型写代码,再结合解释器去执行代码。Docker沙盒环境。可写代码、操作终端和浏览。多智能体,Plan+Build+General Agent,推理和行动解耦,提高稳定性。
整体思想
数据过滤
不可操作/无实质内容的,仅保留明确指出错误的comment。数据合成
多任务和课程学习
混合训练:MLM、Diff Tag 预测、Code 去噪等任务。结构感知:分而治之
专门的学习范式
策略梯度
Offline RL
世界模型:基于历史数据训练世界模型,从世界模型中学习,避免真实交互。CompilerDream。从历史数据中学习:把历史数据构建成一个大的数据集,从中学习。RewardReapair。 Value-based & 偏好学习
偏好/主观打分。如CodeMentor。自动程序修复 Auto Program Repair
编译器优化
安全和漏洞管理
SFT 是RL的地基/冷启动
SFT 和 RL的战略平衡
循环式改进数据驱动
专用agent到全周期的通用Agent
实现深度上下文和长期记忆
多智能体、自我进化
人机协作
信任、安全、可验证
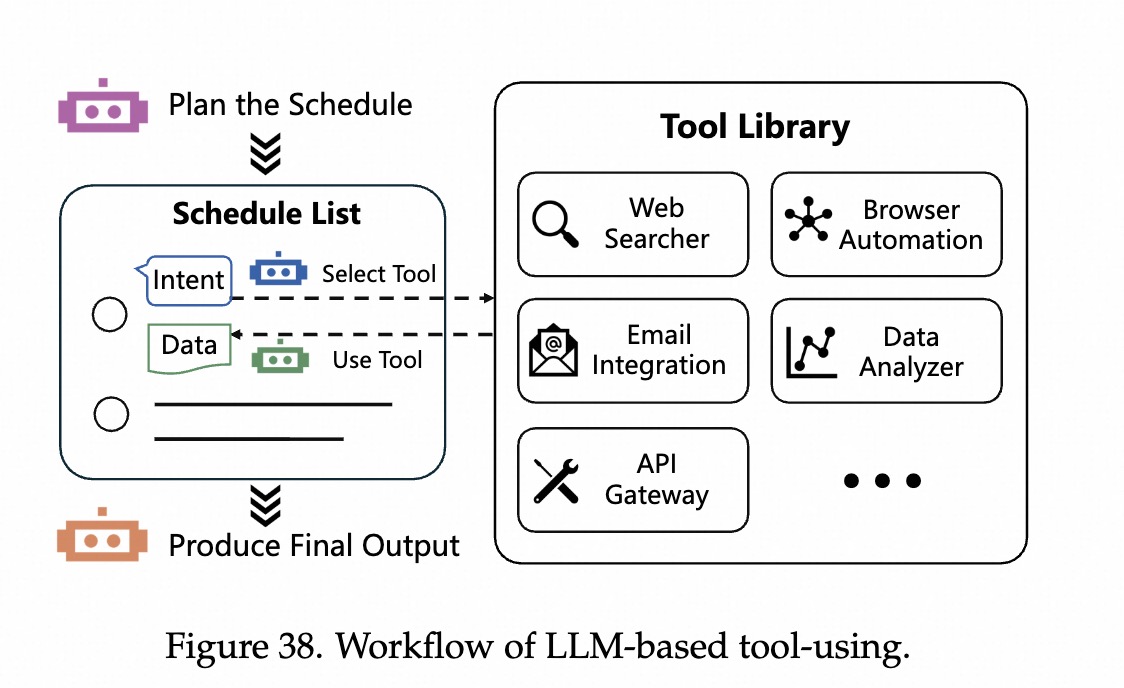
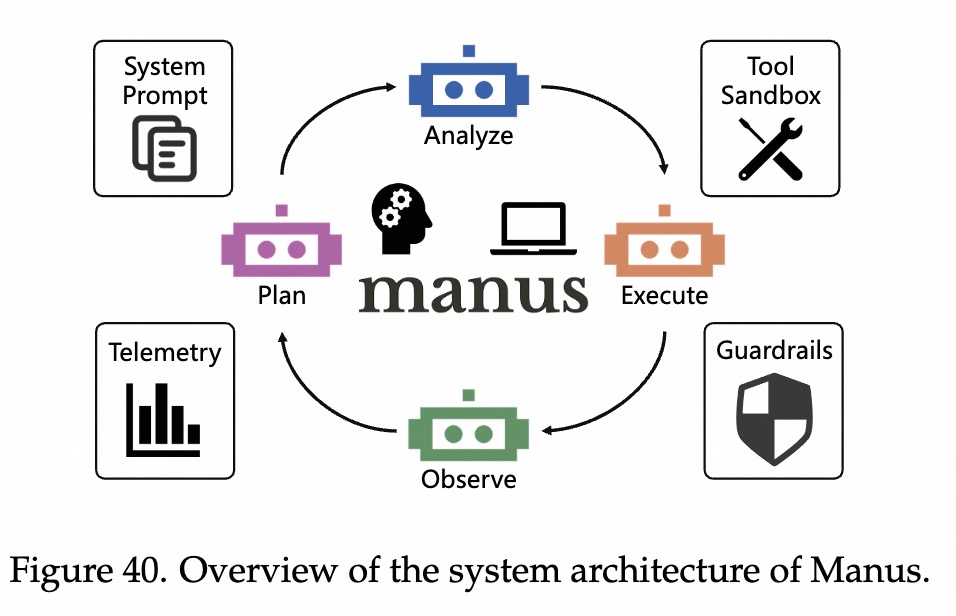
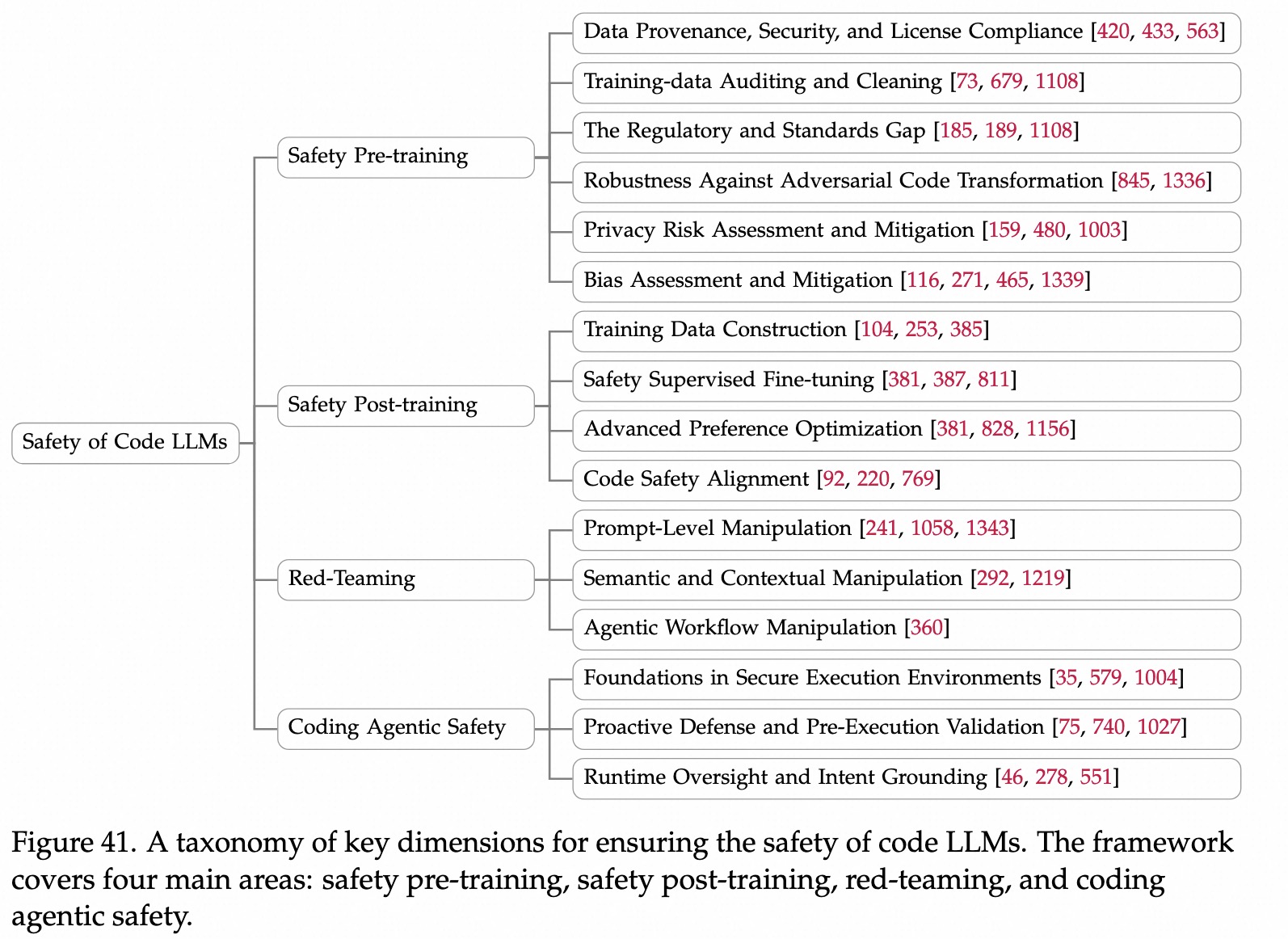
代码模型的挑战
训练流程
Megatron-LM
TP + SP,支持超长上下文。PP 1F1B策略,降低气泡。DeepSpeed
Pytorch-FSDP
TorchTitan
Colossal-AI
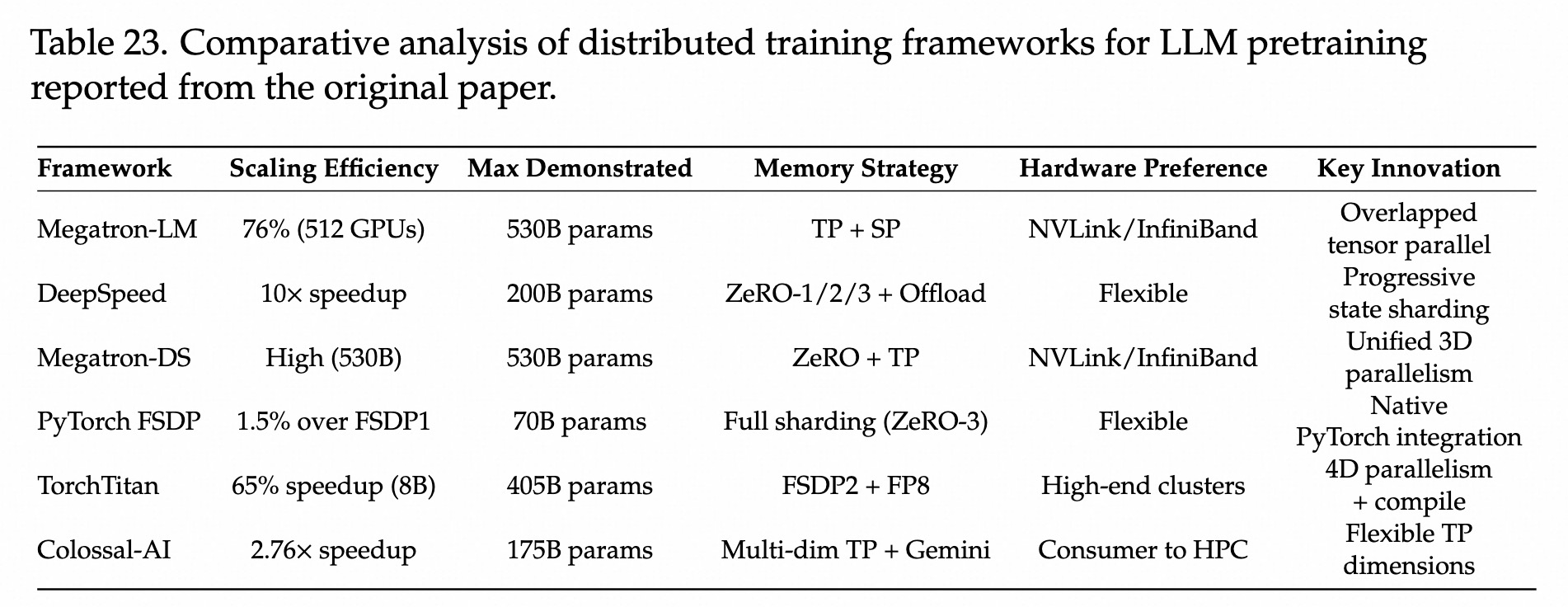
Scaling Law
代码比通用模型需要更高的数据参数比,参数敏感。
N:模型参数;D:训练tokens;
不可约减loss;
每种语言的Scaling Law
python最难学,比其他语言更吃算力,形式灵活。
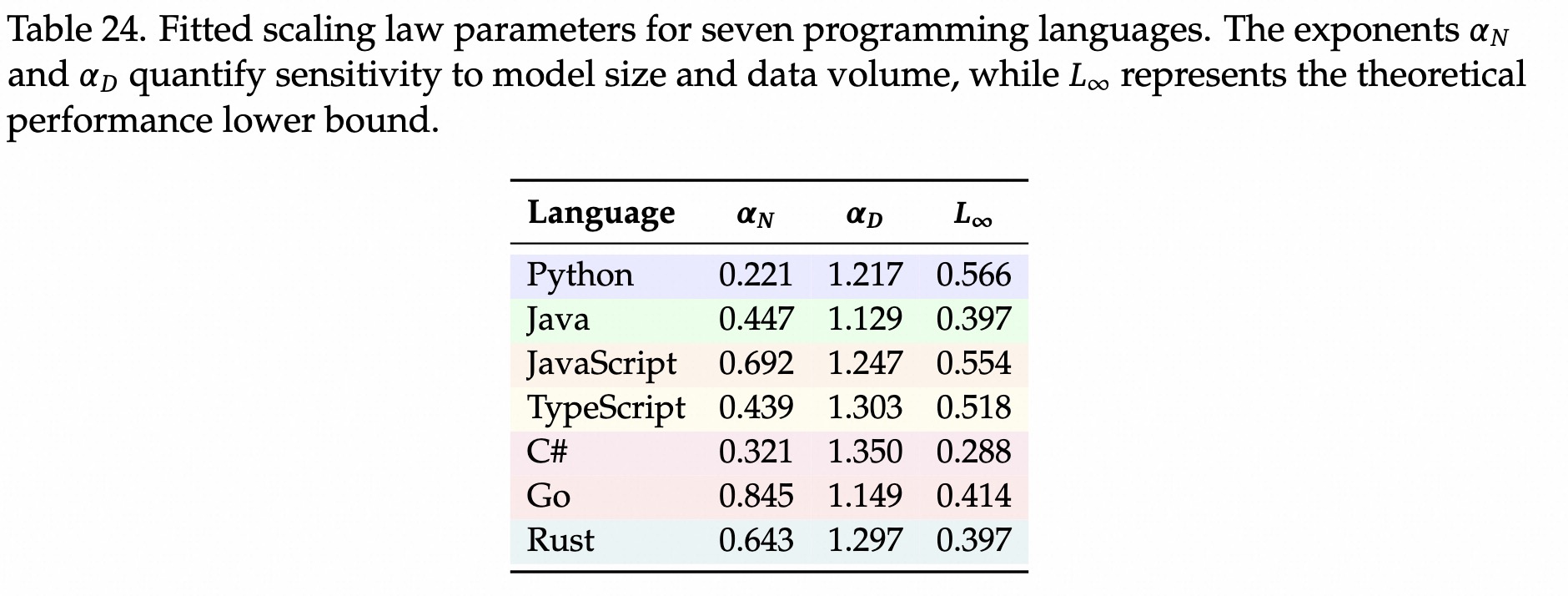
多语言混合
预训练策略
基础配置
框架说明
Dense:更稳健
MoE:超参敏感
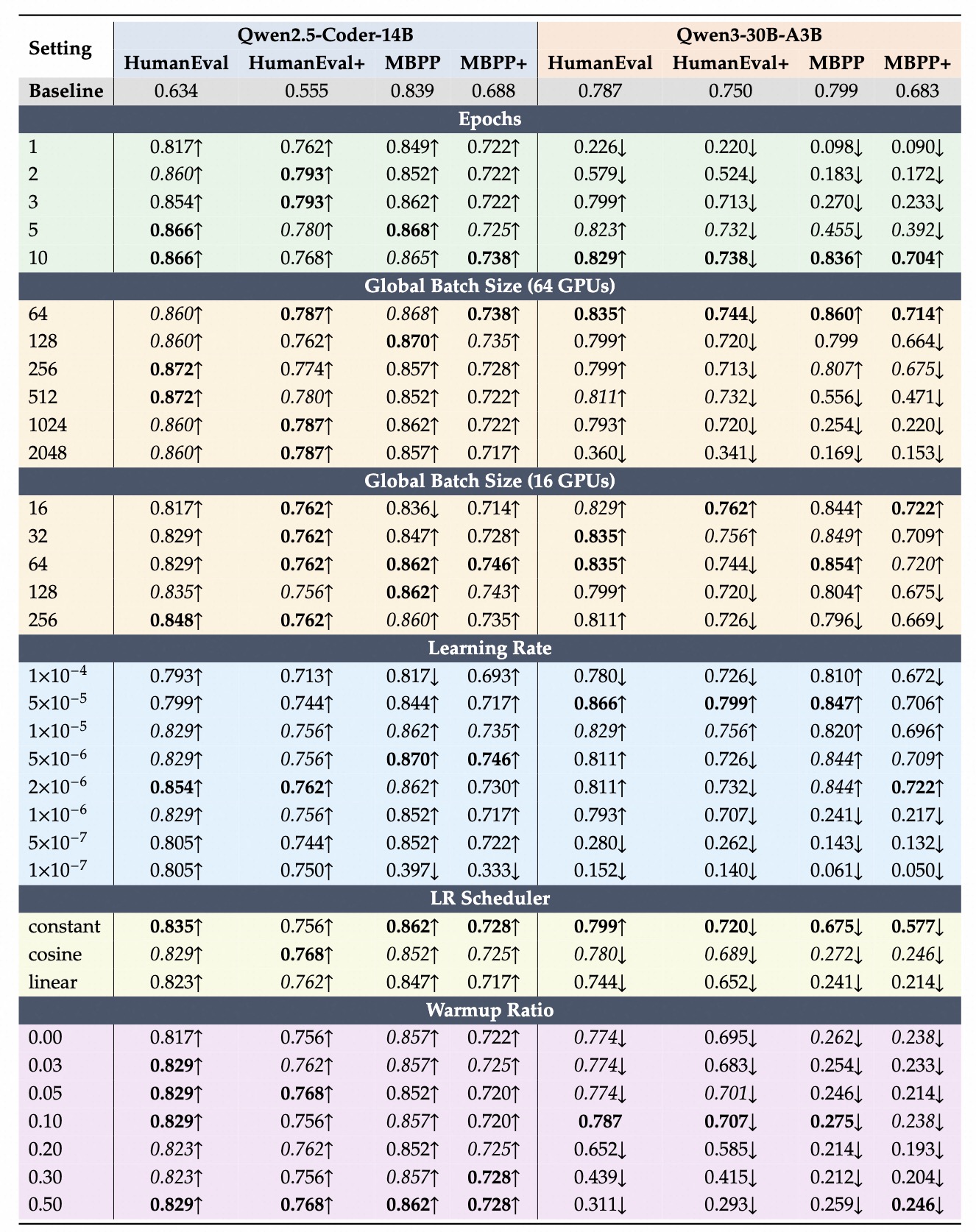
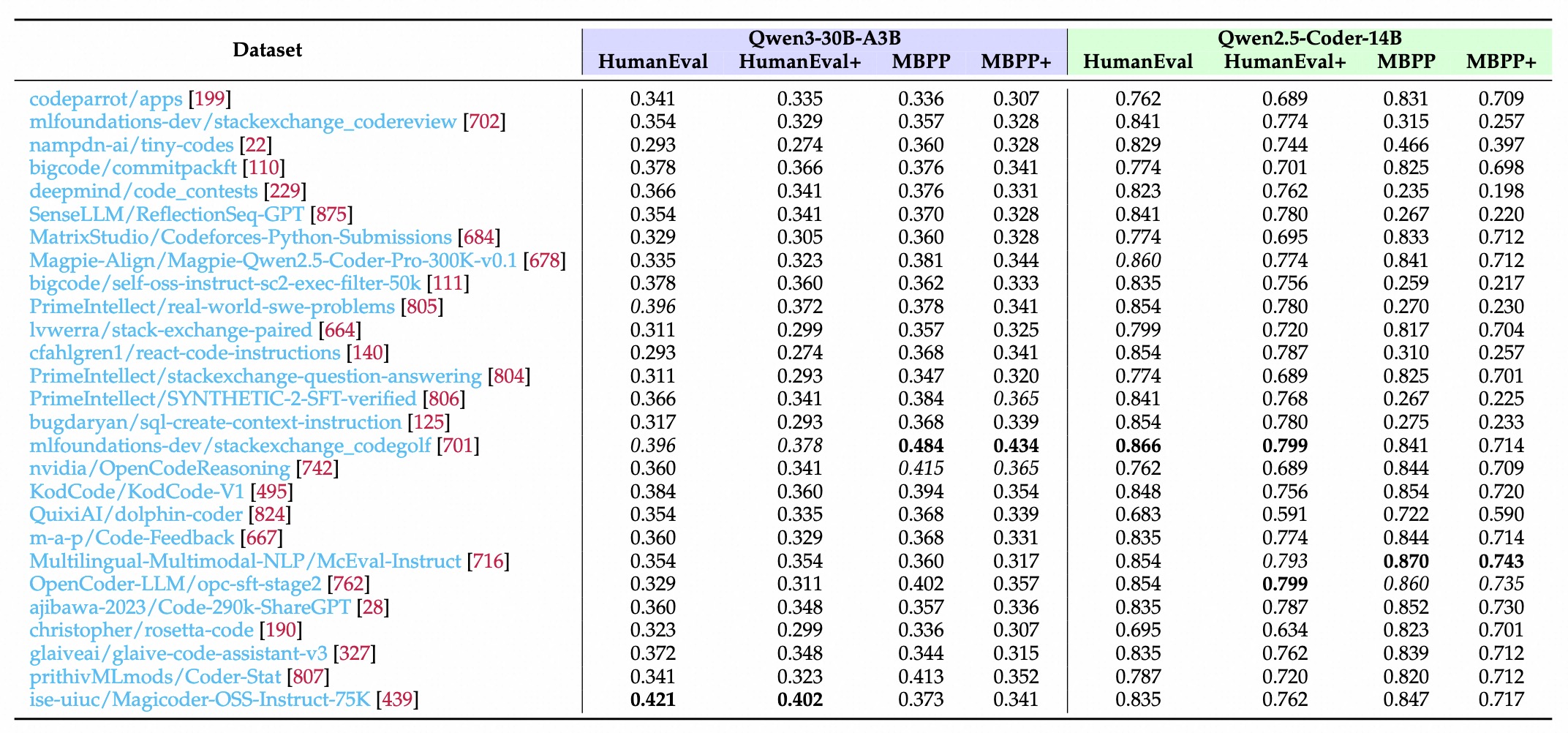
基础配置
分数最高。训练快,比RLOO低一点点。