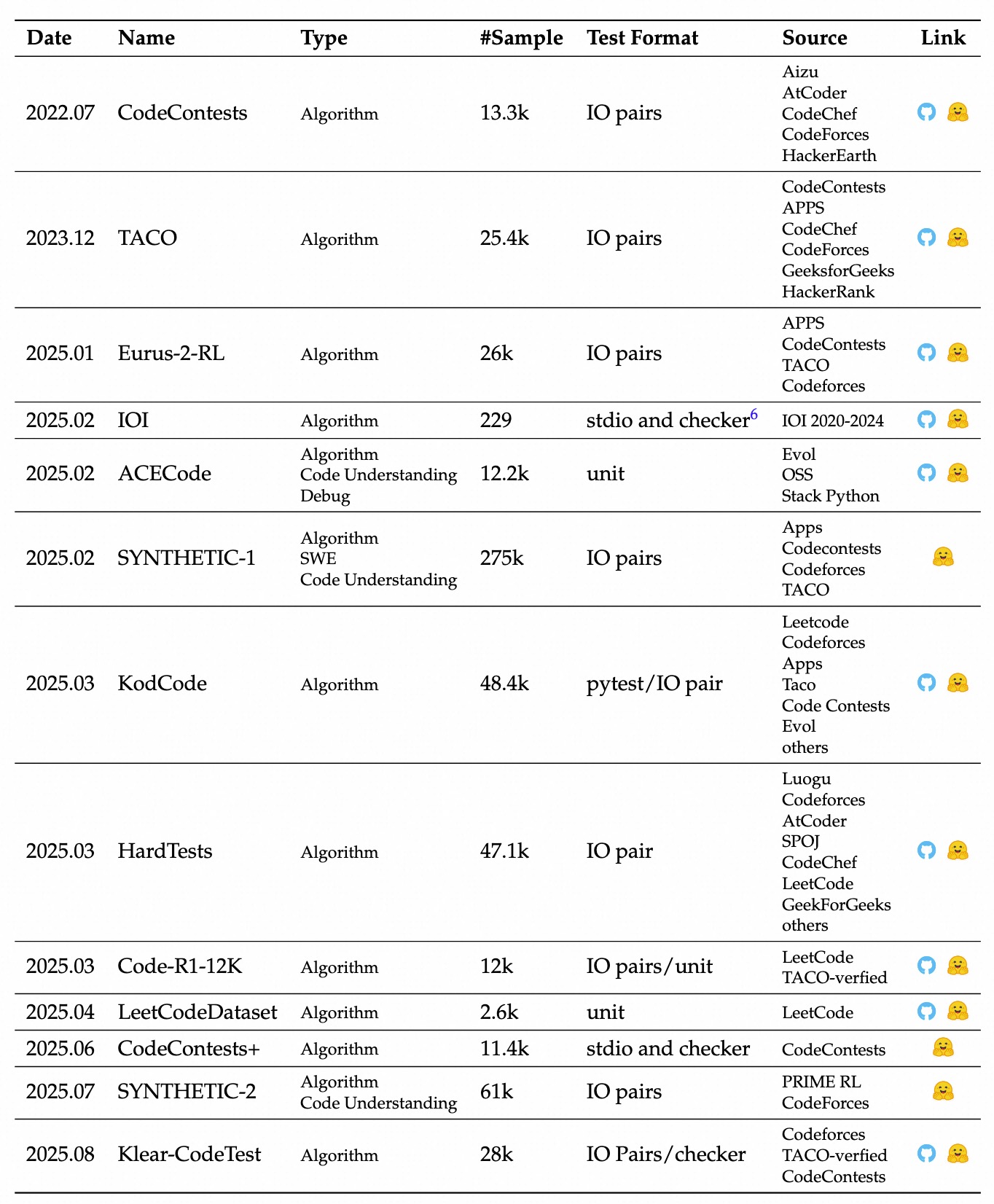
Code RL 任务
📅 发表于 2025/12/18
🔄 更新于 2025/12/18
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
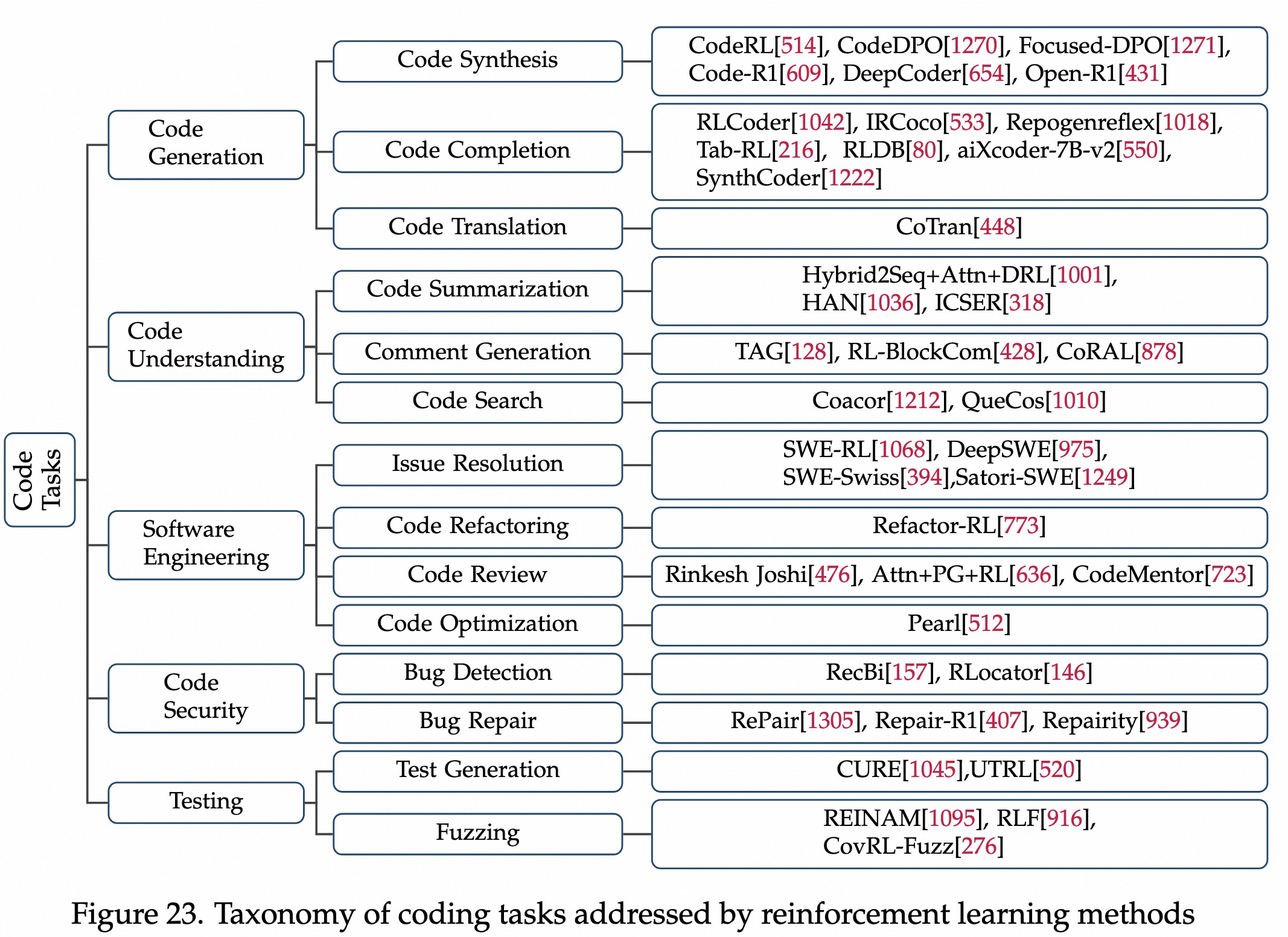
PPO 时代
DPO 时代
RLVR 时代
多个沙盒实现不同奖励函数14B+RL训练,在LiveCodeBench上达到O3-mini效果。检索/RL
仓库级代码补全,学习检索有用信息,在CrossCodeEval和RepoEval上提升12.2%优化检索。DPO
工业应用
摘要
注释生成
搜索
生成提高检索区分度的注释。改写扩充query搜索结果的准确性。解决github Issue核心挑战
RL 工作
2阶段训练策略挑战
工作
背景
自动评估代码、反过来帮助训练模型。关键工作
协同优化,代码生成和单元测试生成的能力。对抗训练,测试用例生成(找bug) + 代码生成(写出健壮代码)。背景
关键工作
整体流程
生成 -> 运行 -> 调试主要算法
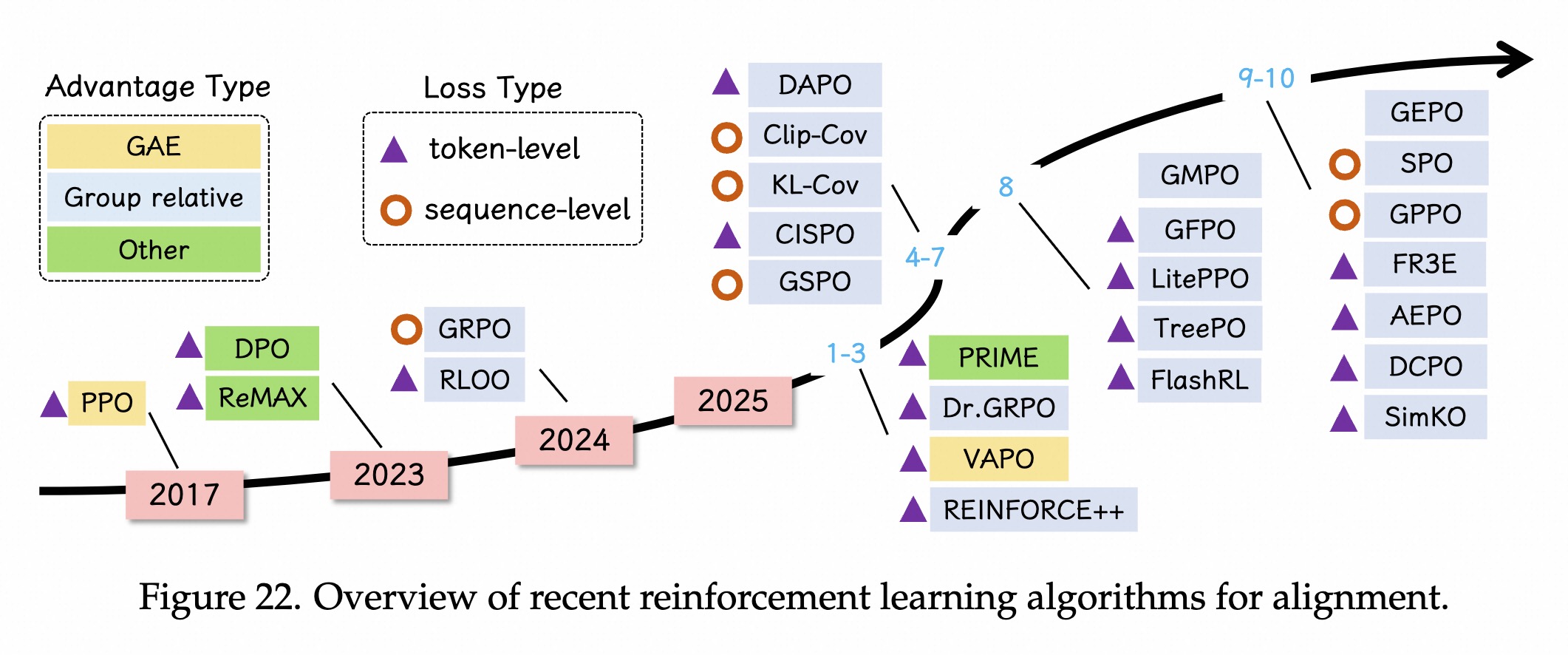
背景
三个层次
奖励稀疏问题,只看结果,有时候代码逻辑正确、仅最后一步错误,可能会判0分。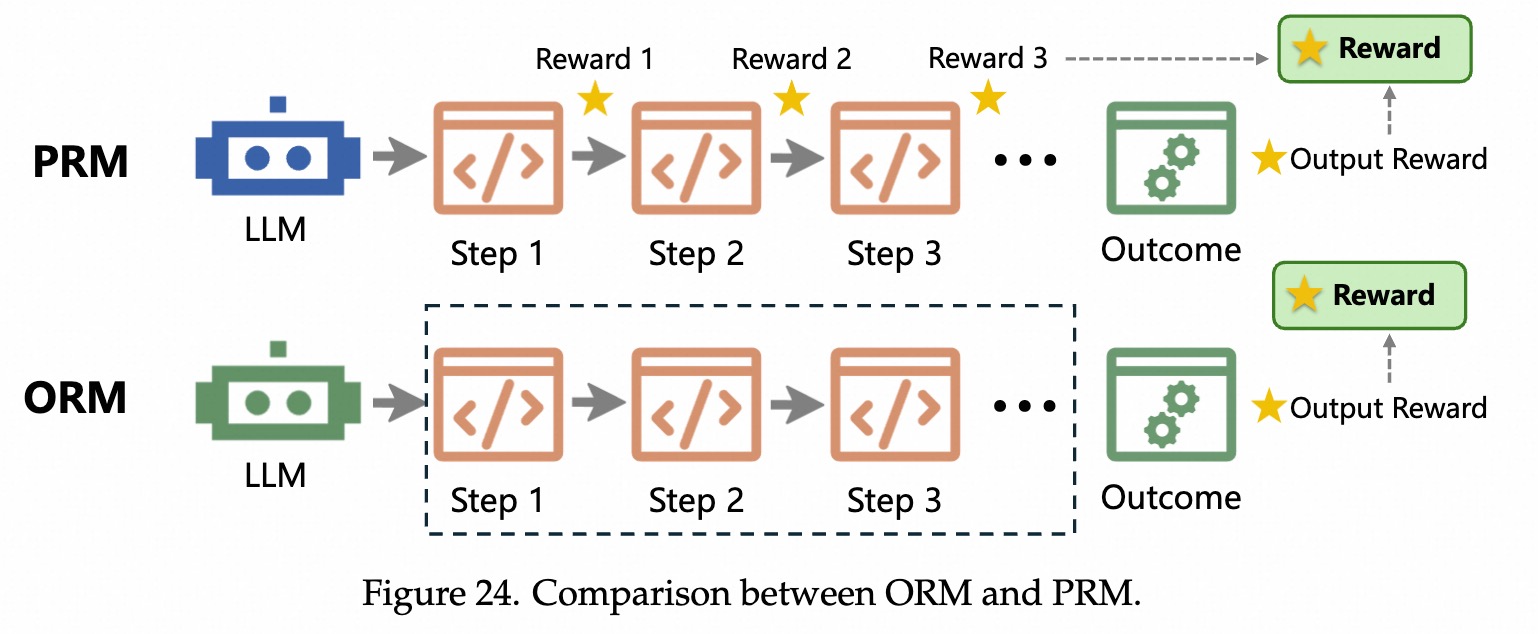
面向任务正确的奖励
语法和规范逻辑和功能
除正确性以外,还需满足软件工程标准。
硬指标奖励
软指标奖励:RLHF
可读性、清晰度、风格等审美维度。偏好比较过程奖励:PRM
奖励稀疏问题。 语法正确性。问题+解决方案+测试 三元组。