SWE 训练方法 系列
📅 发表于 2025/01/02
🔄 更新于 2025/01/02
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
swe
#Self-play SWE-RL
#写Bug修Bug自我博弈JointRL
#SKyRL-Agent
#AST工具增强
#增加环境提示信息
#留一法估计优势
#InfoCode
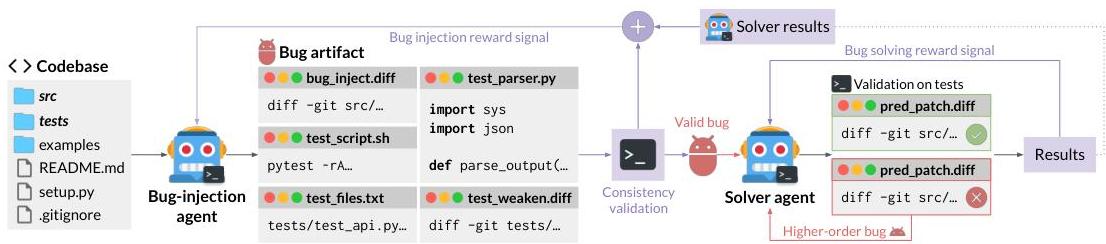
#对抗生成代码和测试
#Kimi-Dev
#Agentless训练
#SWE-Agent适配
#MidTrain
#CodeEditRL
#SWE-Swiss
#3任务SFT
#2阶段课程RL
#NEBIUS-SWE
#Mask错误动作SFT
#DeepSWE
#GRPO++
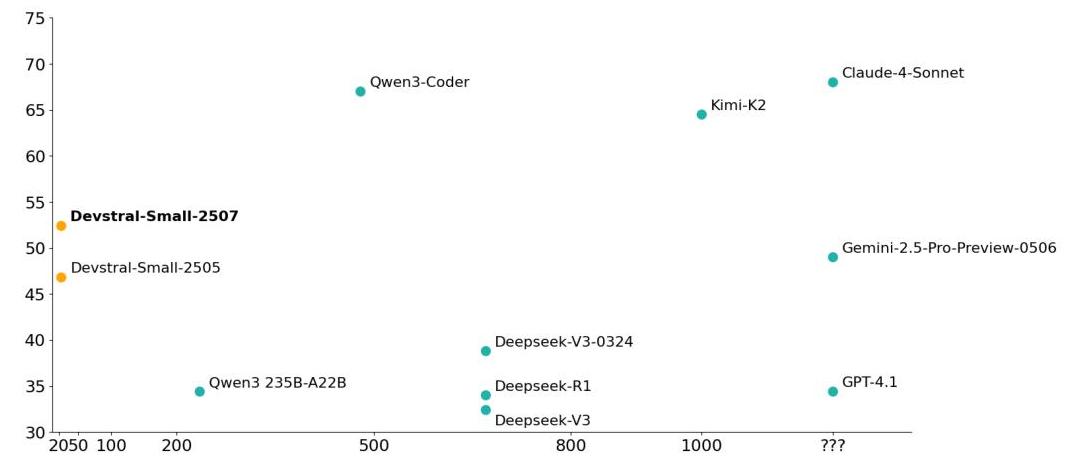
#Devstral2
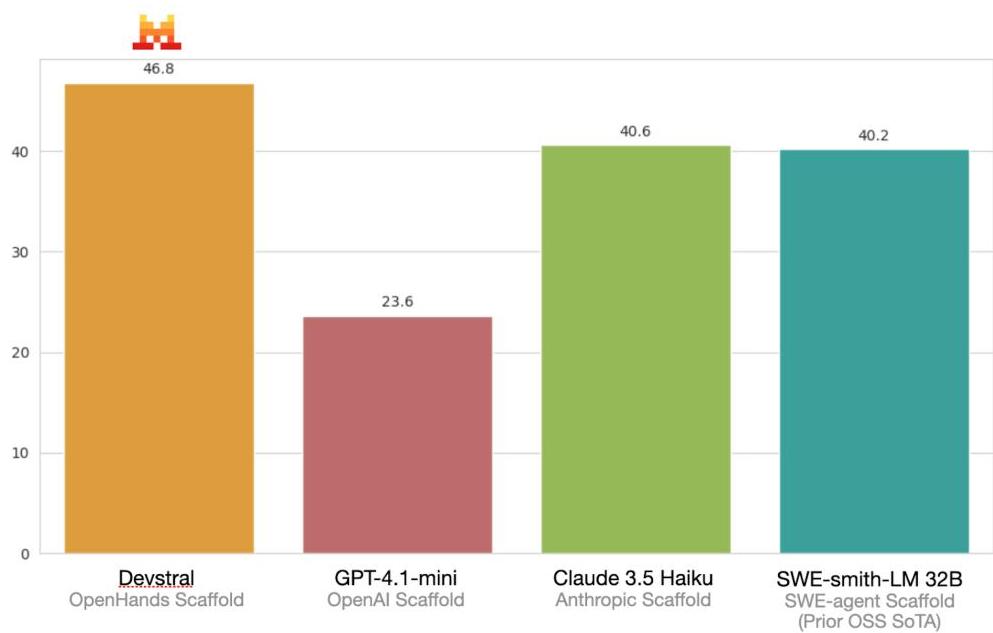
#Devstral
#SWE-RL
#Patch相似度奖励信号
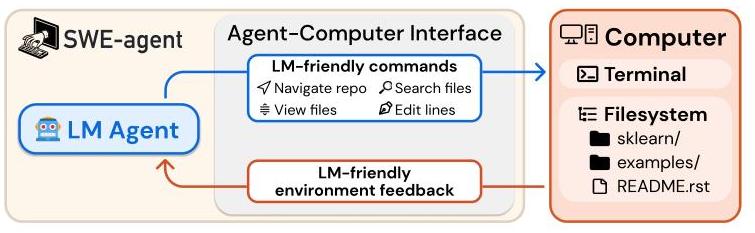
#SWE-Agent
#ACI
#Agent-Computer-Interface
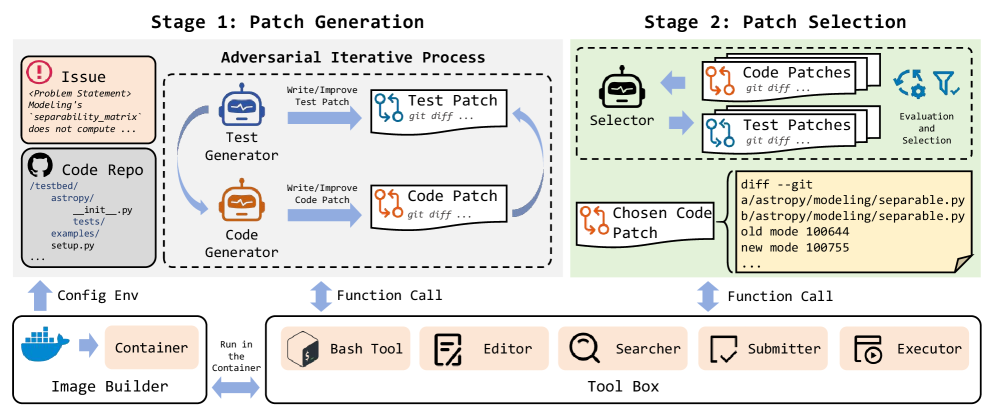
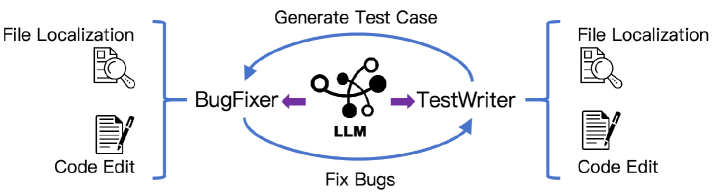
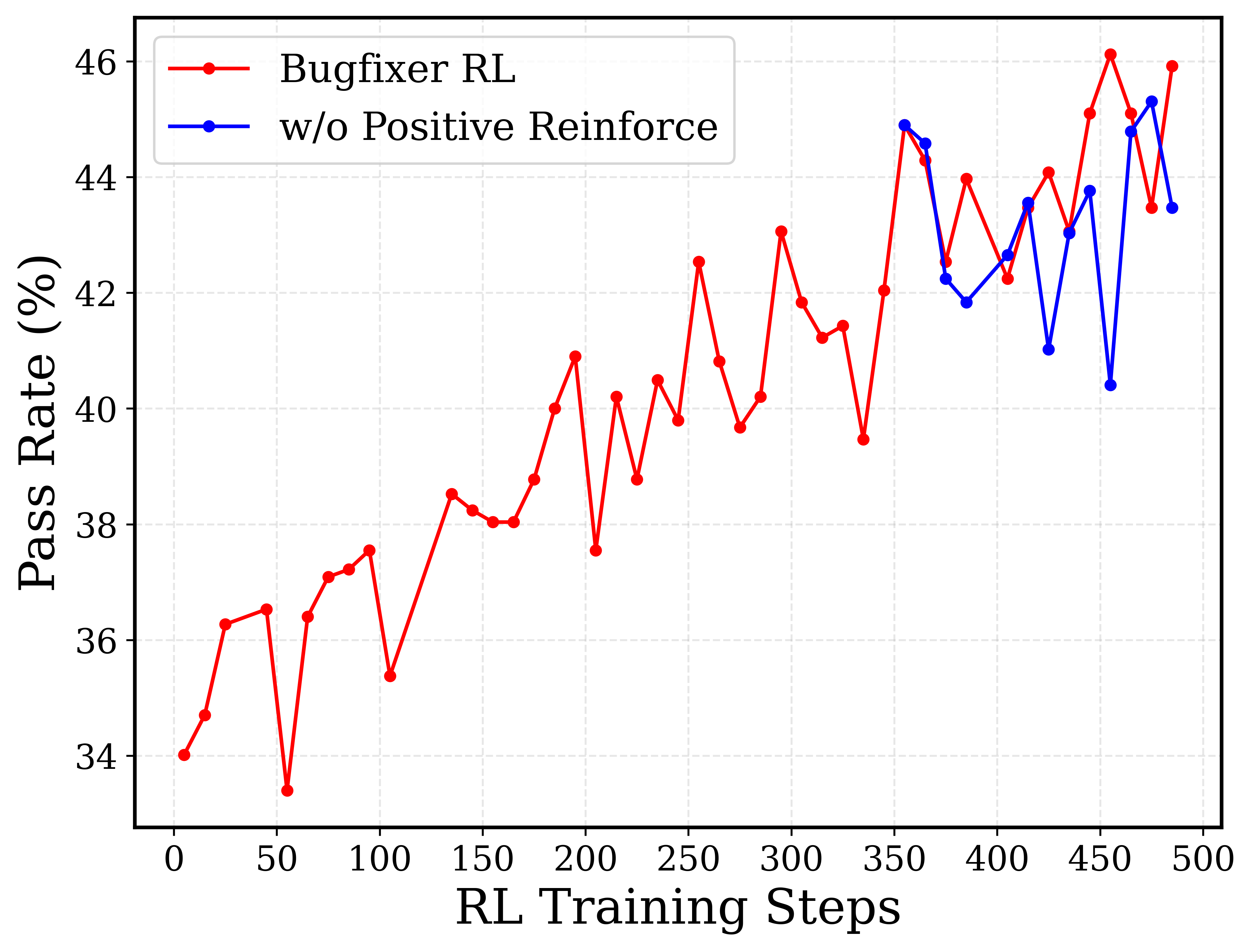

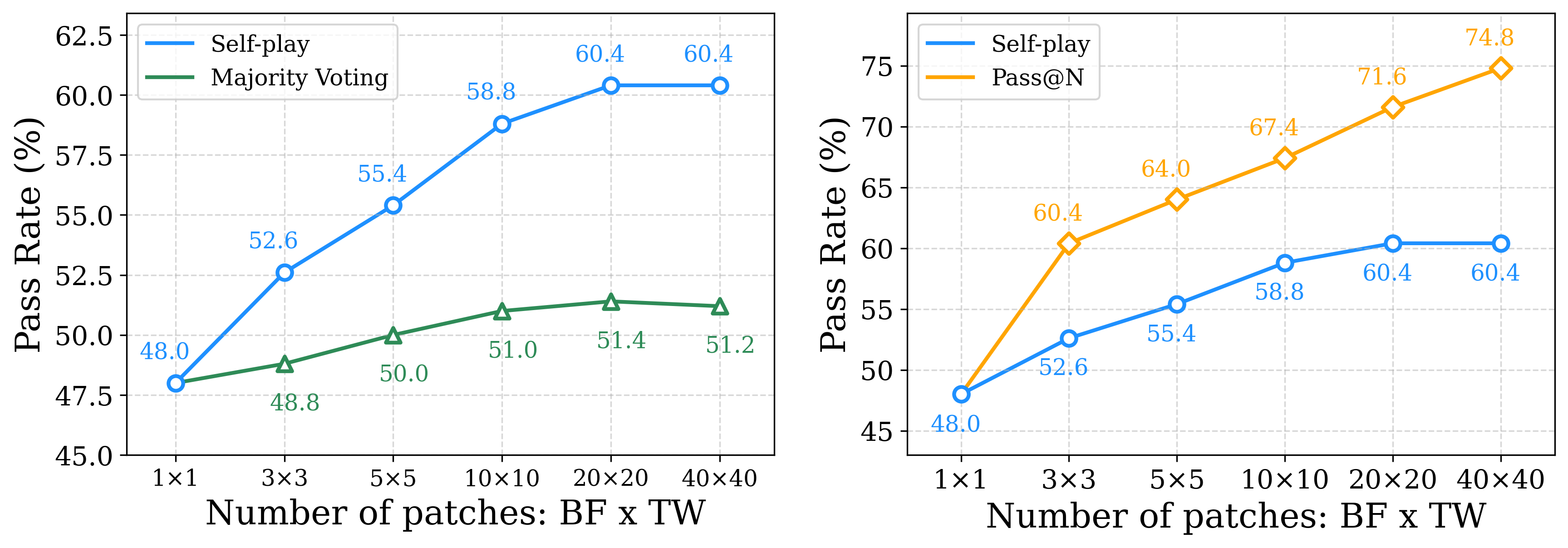







.svg?table=block&id=22281902-c146-81bb-a3a8-ed7613a539ff&spaceId=3dea8845-5afd-4ee7-97ee-480e9ce47ccd&userId=&cache=v2)
.svg?table=block&id=22281902-c146-81bf-a11a-d3167a168c43&spaceId=3dea8845-5afd-4ee7-97ee-480e9ce47ccd&userId=&cache=v2)