Code 任务Bench相关
📅 发表于 2025/12/15
🔄 更新于 2025/12/15
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
code-task
#metrics
#task
1. CodeBLEU
词汇重合度。2. CodeBERTScore / RTC
向量相似度。3. Pass@k
功能正确性,实际执行。给k次机会,只要有1个成功,就算成功。核心思想
1. ICE-Score
Rubrics打分细则,输出1个量化的分数。 2. CodeJudge/CodeJudgeBench
先思考(哪里写得好/哪里有bug),再打分。3. BigCodeReward (多模态评估)
代码和代码运行结果,去做打分,更关心实际效果。 偏好打分:给2个方案及运行结果,判断谁更好。1. ProbGen/差异测试
和标准答案是否一致。多个输入数据(探针),分别喂给2段代码;若输出结果不同,则功能不同。2. REFUTE/反例生成
3. EvaLooop/循环转换测试
1. MCTS-Judge
2. CodeVisionary
让多个模型一起打分。先收集情报,再让n个LLM进行打分。1. Incoherence/不连贯性/不一致性
2. Mean Absolute Deviation (MAD)/鲁棒性测试
1. SBC 语义相似性
原始需求描述和新需求描述是否一致。2. Copilot Arena / BigCodeArena
3. CodeCriticBench
Acc准确率:模型对不对Checklist:比如安全性达标吗、命名规范吗、效率高吗?人类均方误差:LLM打分和人类打分偏离多少。给定部分上下文,评估模型预测正确代码片段的能力。
核心点
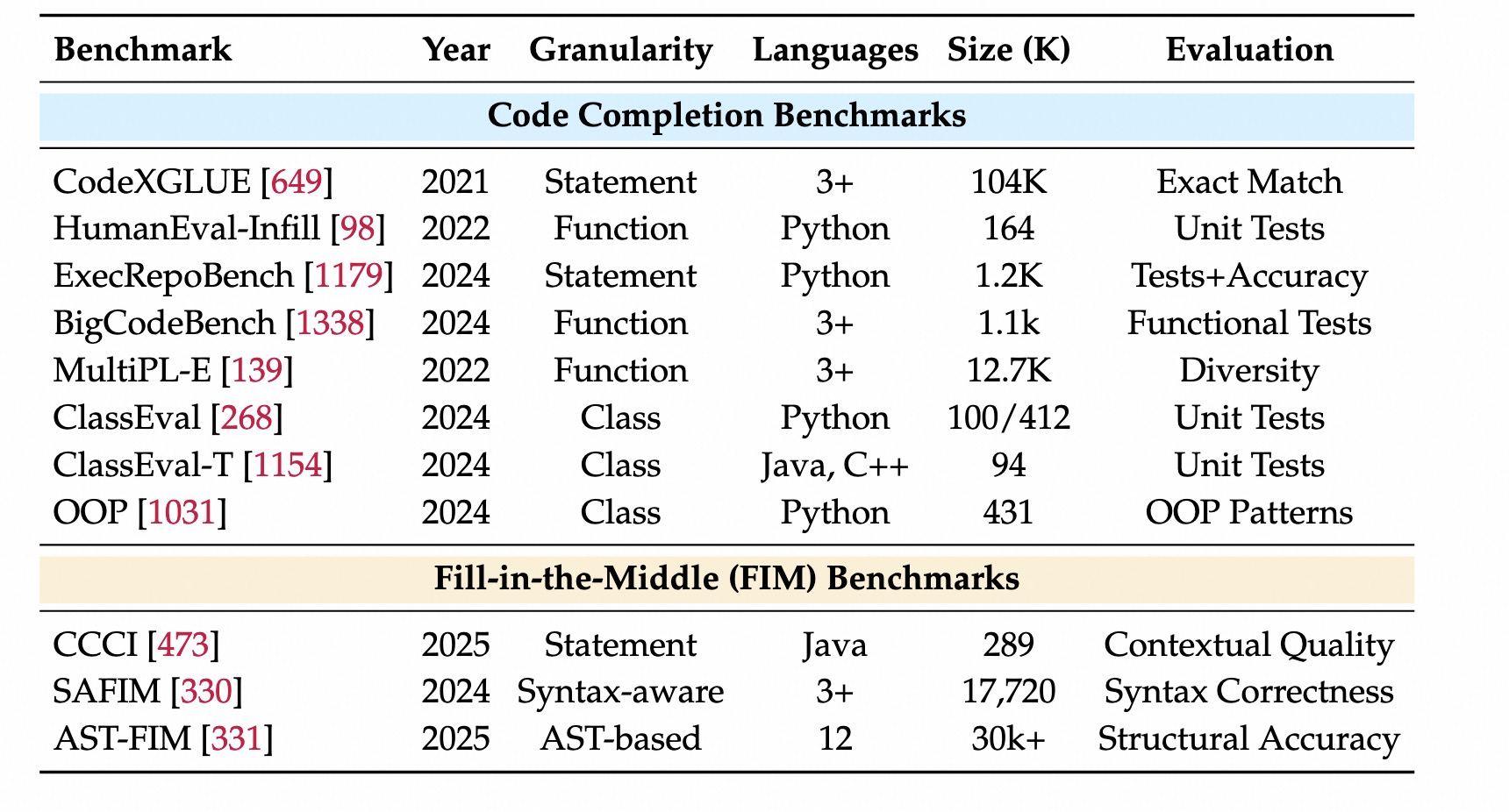
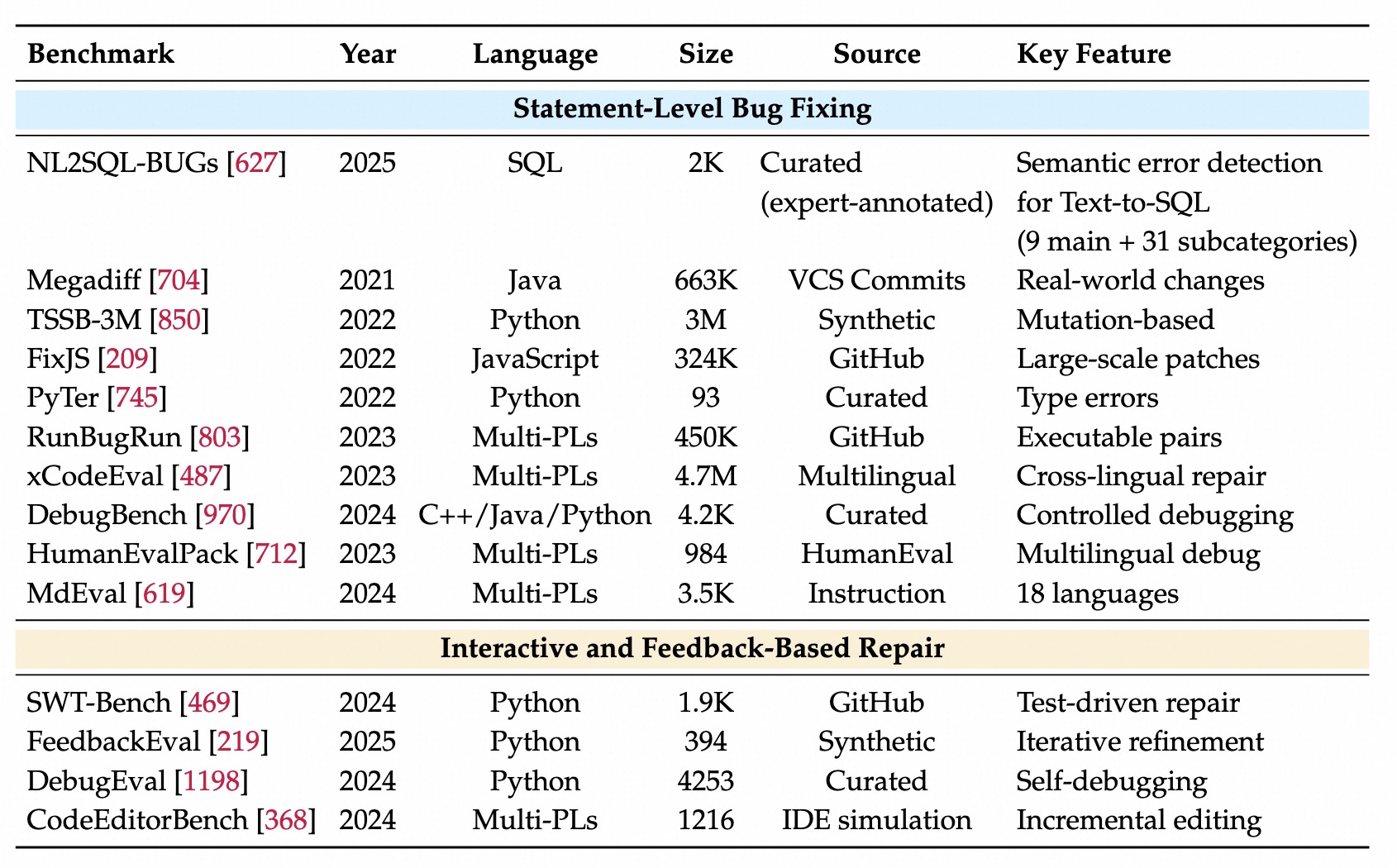
继续编写或修复代码。Statement-Level(语句级)
精准匹配作为指标。可执行、单元测试作为指标。Function-level(函数级)
给定函数签名或部分代码,生成完整函数,关注算法逻辑。真实代码,做函数还原。评估:正确性和复杂度。多个写法。Class-Level(类级)
全局类结构理解能力。核心
主要工作
早期-简单函数生成
最流行):Prompt -> Code -> 单元测试容易过拟合增强测试严谨性
自动生成测试用例,去验证是否真的懂,避免过拟合增加难度、扩大题库、改进评估方式等。多语言扩展
真实场景/上下文/复杂性
代码库上下文、显示世界等。全方位评估框架。中文指令、多任务能力。核心思想
主要工作
写代码、还预测输入输出,测试解题能力。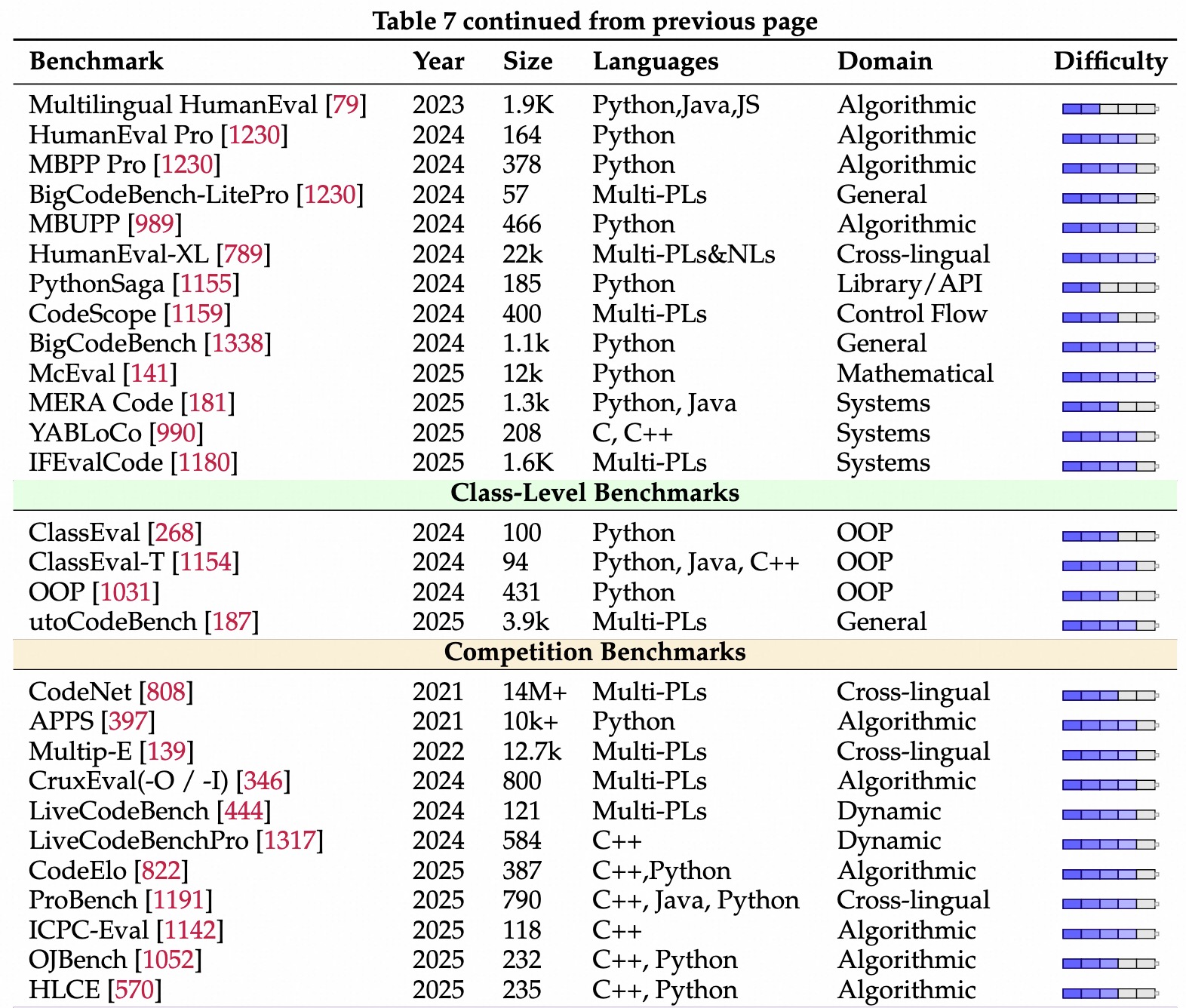
垂直技术栈
复杂结构和全栈
评测方法创新
自动构建Bench,让AI自动抓取代码、生成测试用例。看文档写代码的能力。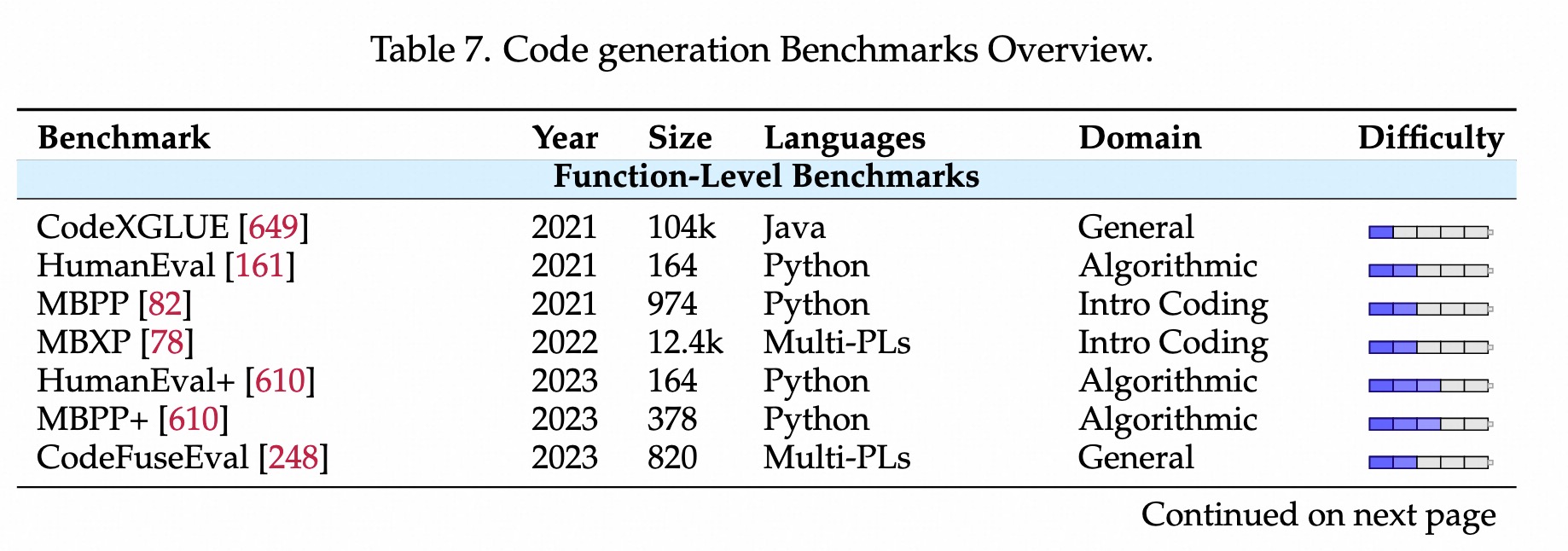
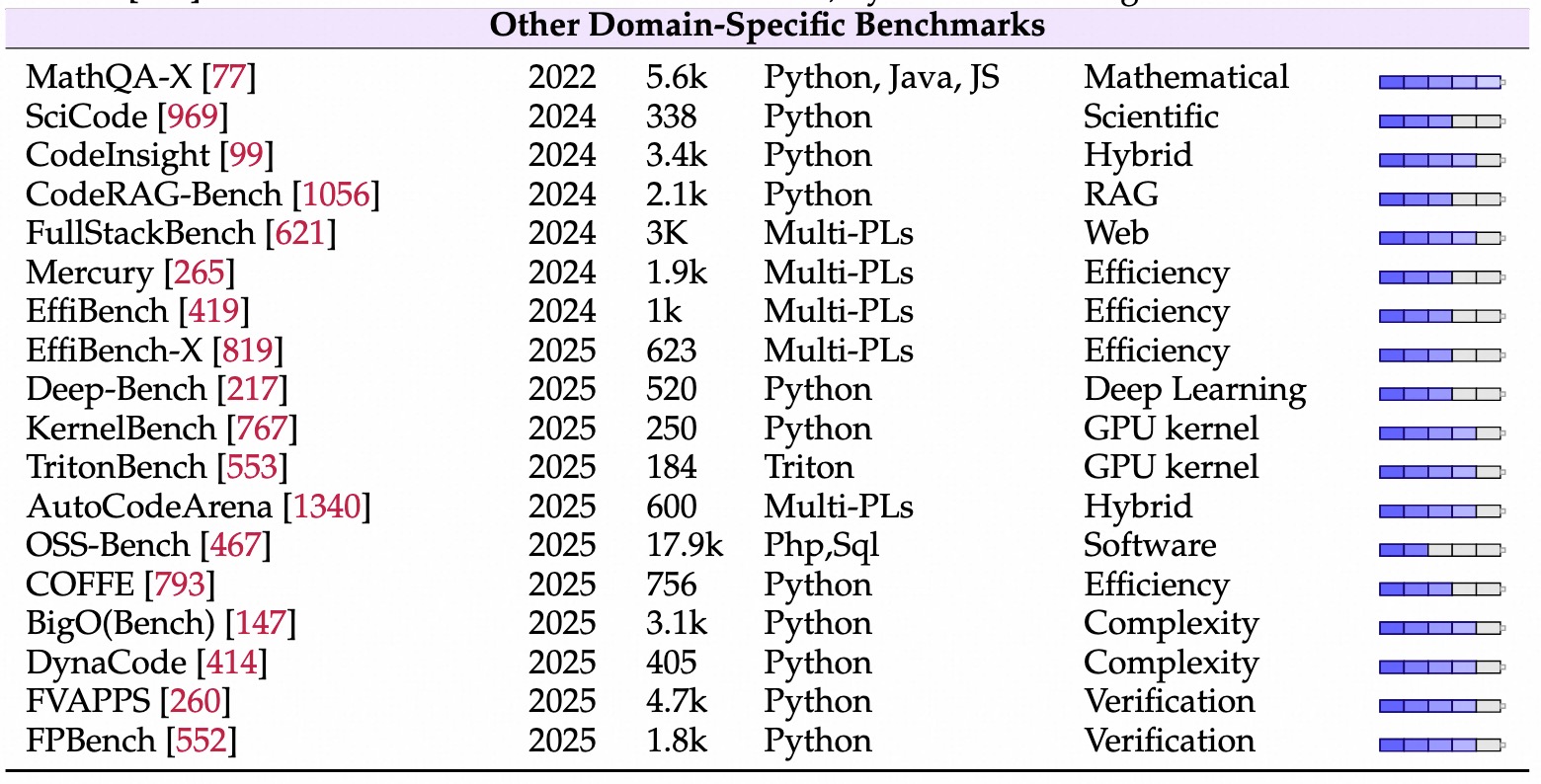
改原始代码。
语句级Bench
交互迭代式Bench
写代码 -> 报错 -> 改代码 -> 跑通IDE环境,涉及增量编辑和文件间依赖。模型生成调试信号来指导多步修复。使用debug工具(pdb),包括打断点、单步执行、查看变量值等。SFT/RL教模型使用有状态工具,解决预训练此类数据稀缺问题。背景
效率很低,希望写对代码->写好代码。性能和复杂度测试
能耗和效率优化
训练时干预 (Training Objective)
把效率信号加入损失函数。强化学习 (RL):
事后修补 (Post-generation Refinement):
背景
正确、快、安全、易读).方法1:硬指标打分法
方法2:竞技场LLM-as-a-Judge法
代码+各自沙盒运行结果,来打分。背景
基于QA的评估
把代码注释转换成问答对,10w的数据集。真实软件项目中细粒度的代码语义推理任务。 基于代码语义推理的评估 (更具体的任务)
输出预测和输入预测s。多模态维度
早期方法:语法结构驱动
基于执行反馈的方法 (测试用例)
Prompt工程
安全
数据与评估的进化
面向软件工程
面向程序竞赛
单一代码刷题 -> 写工程代码。整个代码库上下文(多文件/项目结构/依赖关系/跨文件关系),来预测/补全或生成代码片段。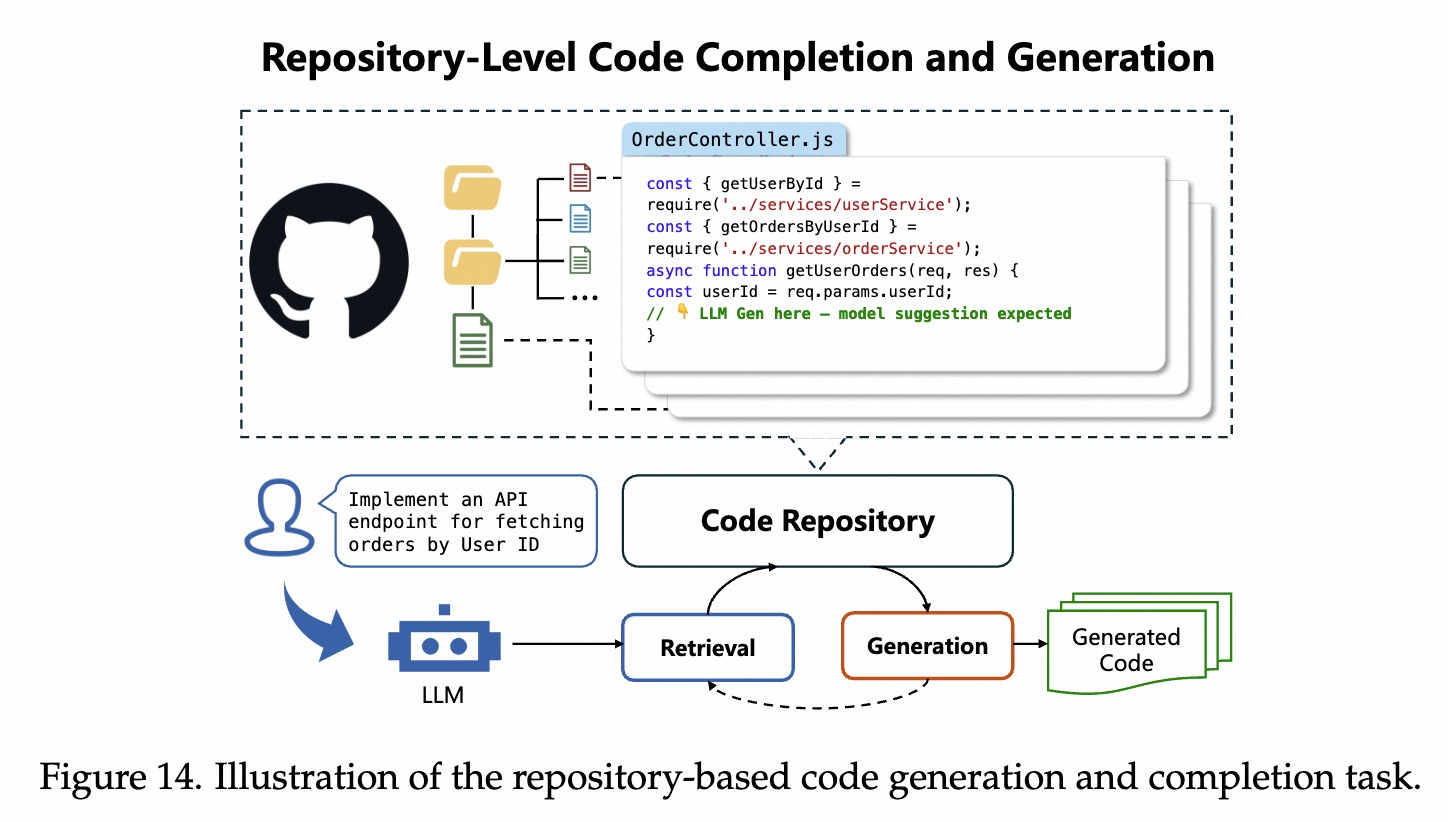
补全任务上评估模型。22年之前的代码;测试集:22年之后的代码。RepoCoder利用完整仓库上下文,效果好于其他模型。单元测试来评估14个真实代码仓库的代码补全。多粒度(表达式/语句/函数)的masked spans,来评估 LLM 的仓库级补全能力仓库测试文件进行验证;并在其上微调Qwen2.5-Coder以增强补全性能。非独立函数,需要调用其他文件代码等。 跨文件上下文的需求。AST(抽象语法树)来做标注的。工业数据评估repo补全能力。 不完整后缀场景效果都不好。评估依赖推理,4语言,581仓库。顶级模型效果也不好。分层评估 仓库级依赖,8种语言,15k仓库。沙盒测试构建仓库级环境。 REPOST-TRAIN训练的模型在HumanEval/RepoEval 有效果REPOST-EVAL 效果一般。安全代码生成(318 个任务,C/C++ 中的 15 种 CWE 类型)。人工注释的Bench(1.8k样本,117 仓库);有难度,当前 LLM 表现很差。需要特别的领域知识,逻辑复杂、多重依赖等。
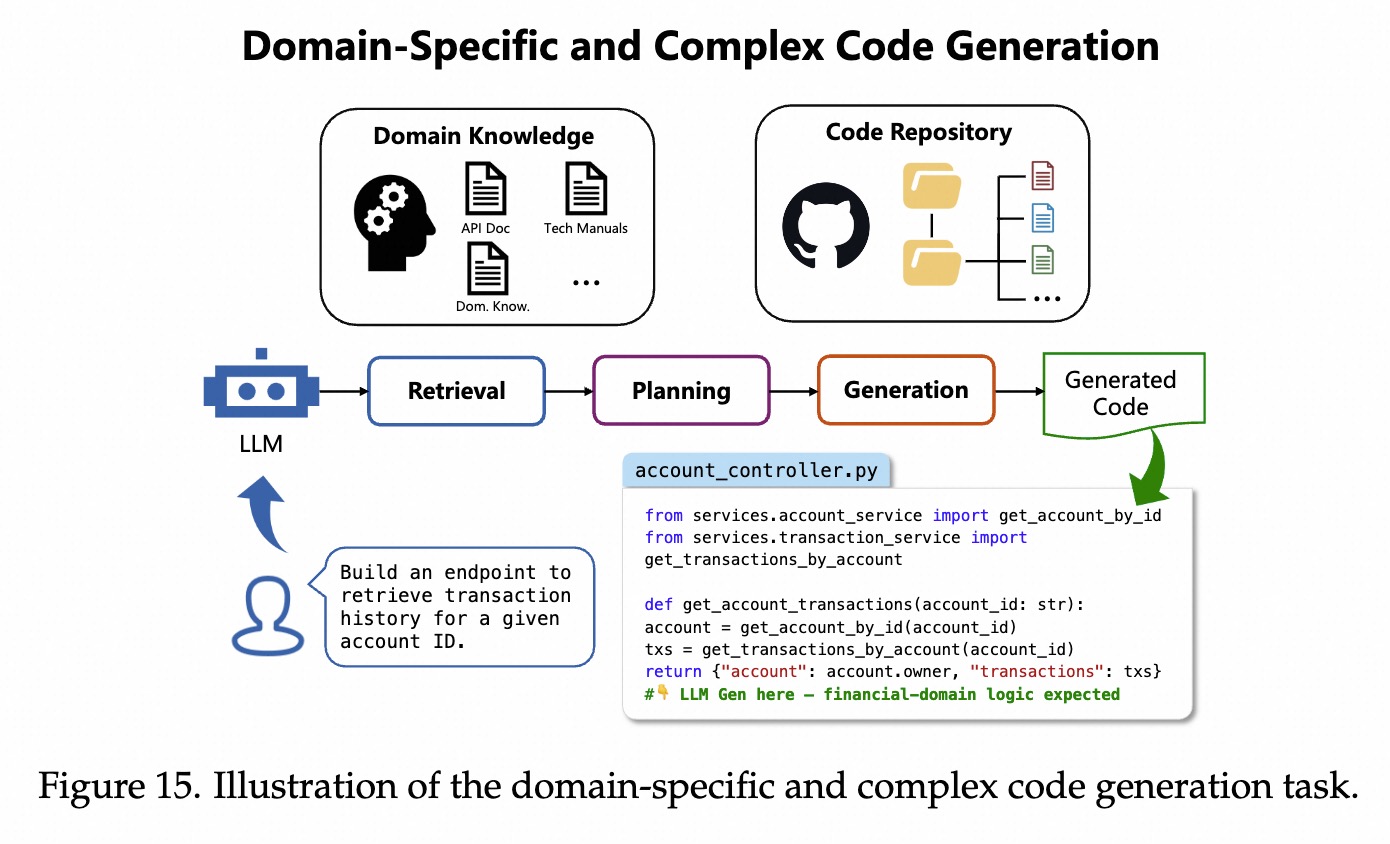
BioCoder
生物学代码生成Bench,1.7k生物学仓库、2.2k高质量代码问题。PaperBench
去复现论文,20篇ICML2024的论文。 评分树(Rubric Tree):不只看最终结果,而是把大任务拆解为8.3k个小步骤子任务,一步步打分。 Commit0
文档和空函数体,从0开始编写代码库,实现所有函数,通过单元测试。54个python库。HackerRank-ASTRA
ProjectEval
用户交互,来测试repo-level 代码生成能力,284个测试用例,共3级输入 NL Prompt;Level2:NL Checklist;Level3:Skeleton。系统性思维和全项目理解的任务上表现很差。DA-Code
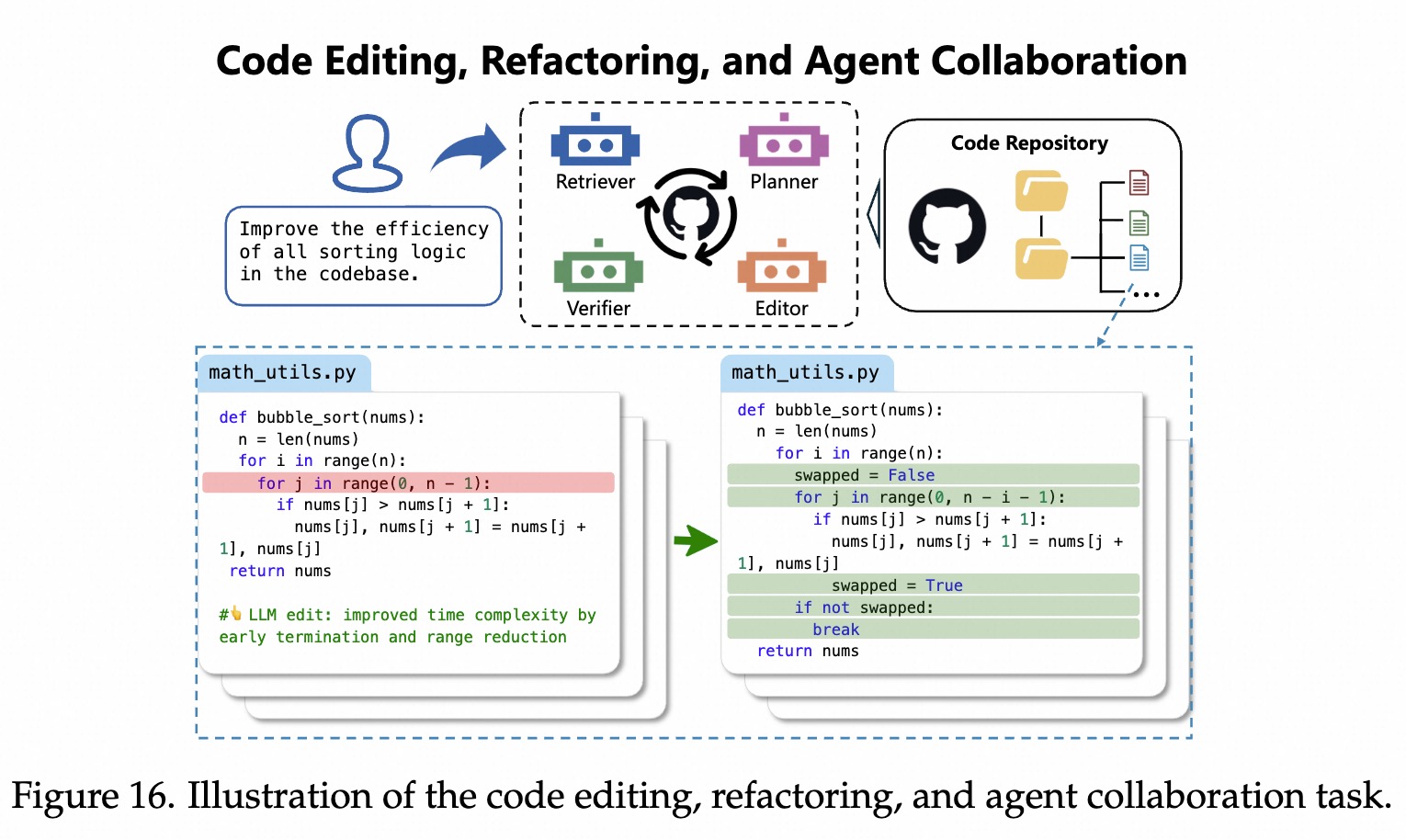
Aider Edit Bench
编辑python源文件,完成133个Exercism的编程练习。Aider Refactor Bench
89个大方法。长上下文能力。Aider Polyglot Bench
RES-Q
LiveRepoReflection
系统来收集仓库数据,RepoReflect数据集,包含580个reflection实例。RepoExec
可执行环境来分析上下文如何影响代码的质量。CodePlan
解决复杂任务,Planning + Multi-step Edits。
多步计划,再一步步编辑,确保每一步的依赖关系都正确。仓库级编码的框架。自动化了需在整个仓库中进行广泛编辑的任务。
任务
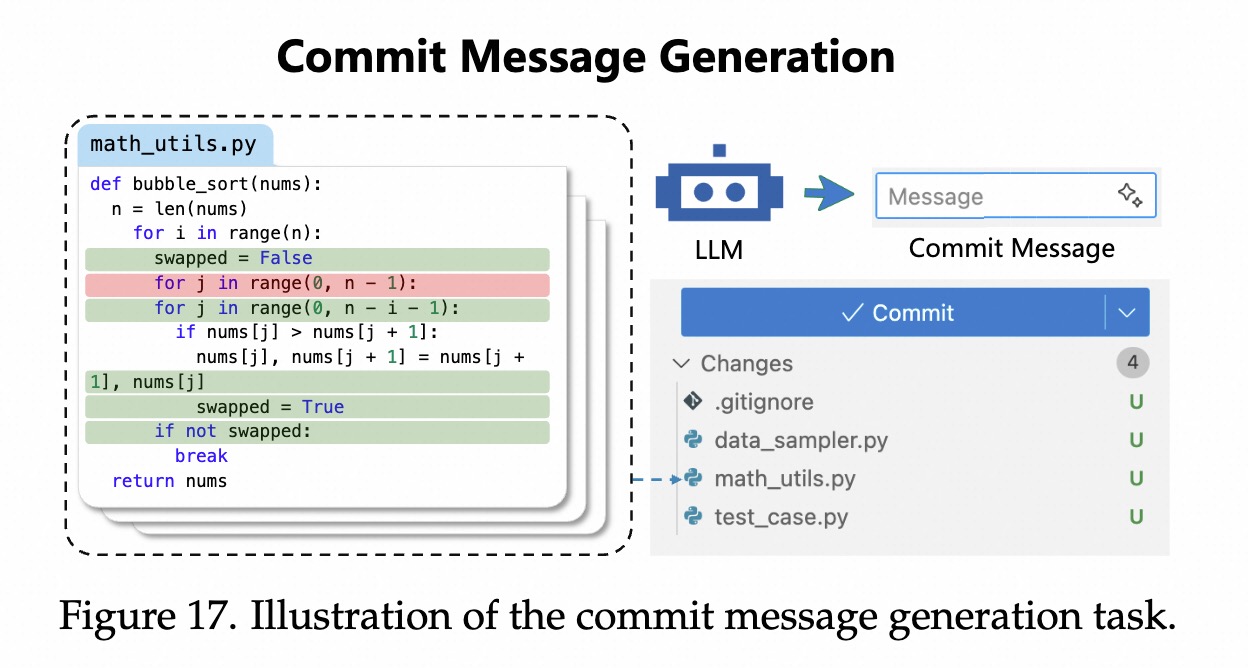
代码差异,自动生成简单、信息丰富的文本描述。早早期方法:统计和规则
早期方法:检索&NMT
Bert/大模型
评估的挑战
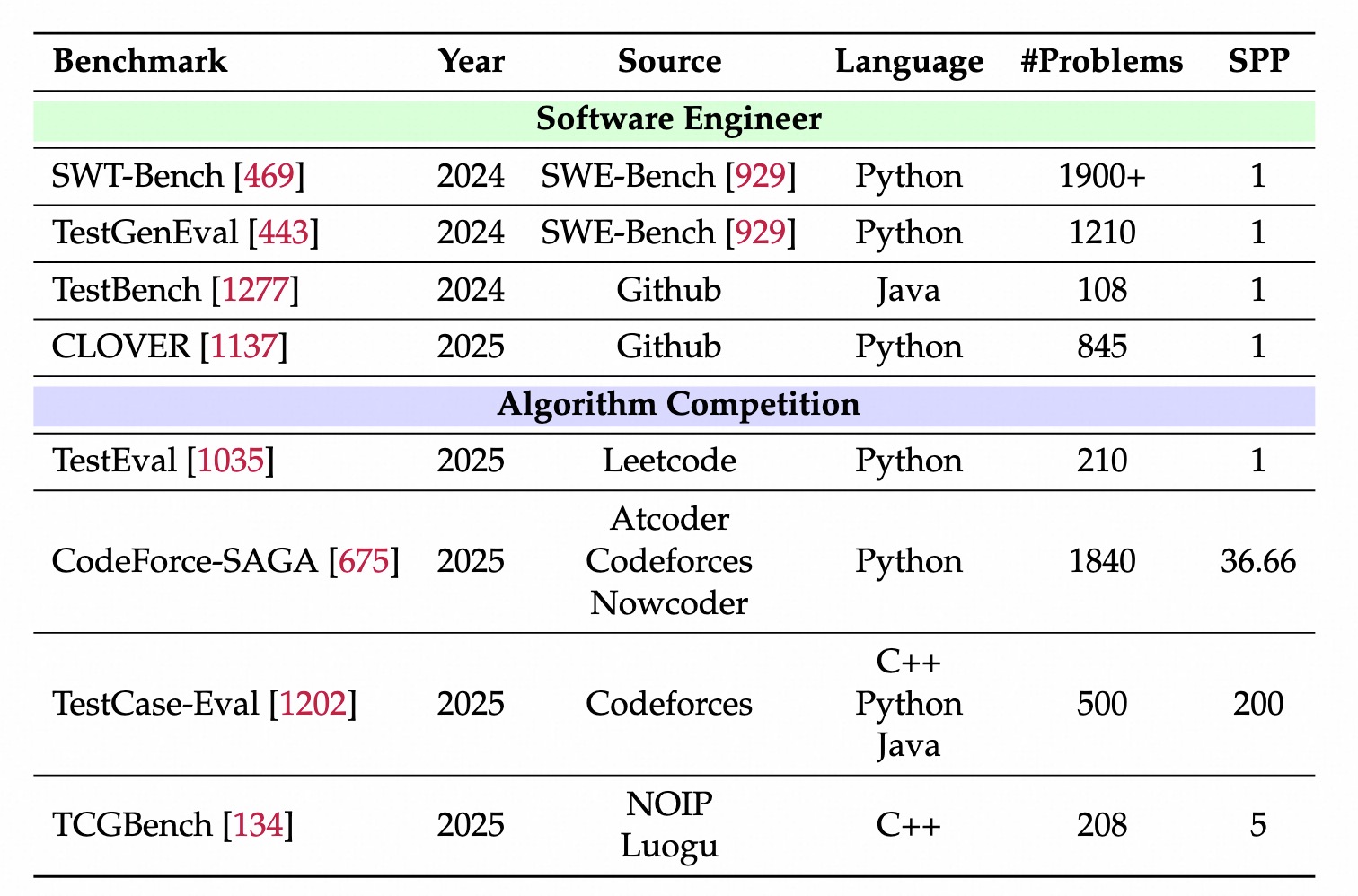
SWE-Bench 家族
SWE-bench:2.2k issuse-PR对,真实github python 问题 ,fail-to-pass 单元测试。SWE-bench-verified:500个人工策划的例子,基于docker评估,确保一致性。SWE-Bench 扩展
功能实现,1.4万个训练数据和500个评估数据。LLM添加新功能而非直接插入bug,来合成更逼真的bug。 Qwen3在swe-bench-verified达到SOTA。最小单文件代码。视觉调试,17个JS项目,619个视觉issue。很有挑战。超越SWE-Bench
大规模、去重的源代码数据,对提高真实任务性能很重要。思想
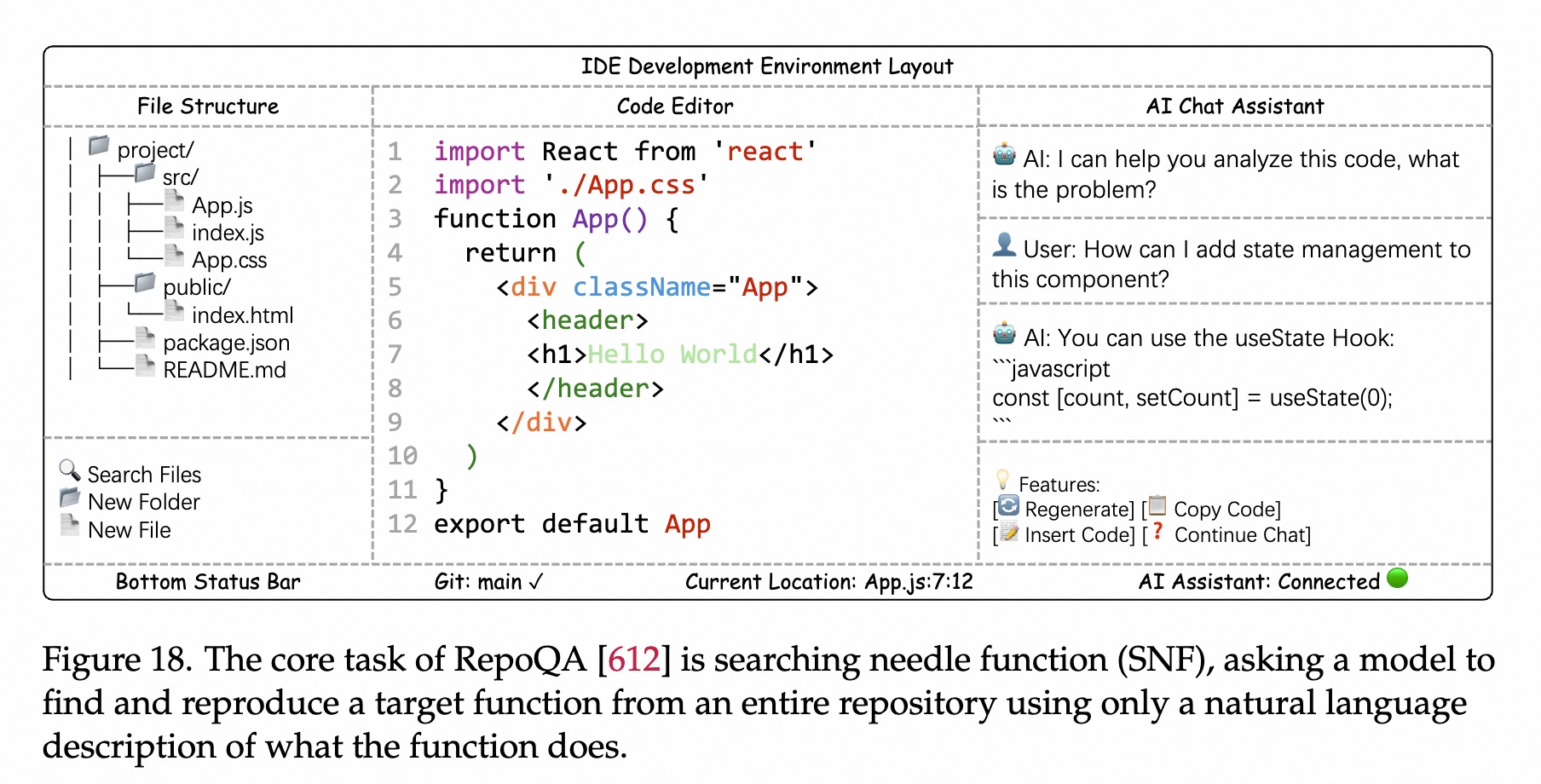
基准测试:海量代码大海捞针
多个文件进行检索和推理。长上下文压缩
核心
入门级
多轮交互
领域任务
核心
Bench
核心
Bench
找信息和根据信息推理2步。网页之间的跳转,像人逛维基百科一样。核心
前端导航Bench
前端开发Bench
核心
Bench