Code 预训练相关
📅 发表于 2025/01/02
🔄 更新于 2025/01/02
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
codellm
#KAT-Dev
#Seed-Coder
拓展模型的推理、规划、交互等能力。
Train Recipe
PR、Issue、Commit、Patch等。Plan-Action-Observation轨迹。可验证逻辑和结构的指令跟随数据集。📕核心方法
原始数据
处理步骤 (预处理+过滤)
精确去重和近似去重不相关或非代码数据数据分为4类文件级代码 + 仓库级代码 + Github Commits + 代码相关的web数据处理结果
核心预训练数据继续预训练数据:高质量数据 + 长上下文数据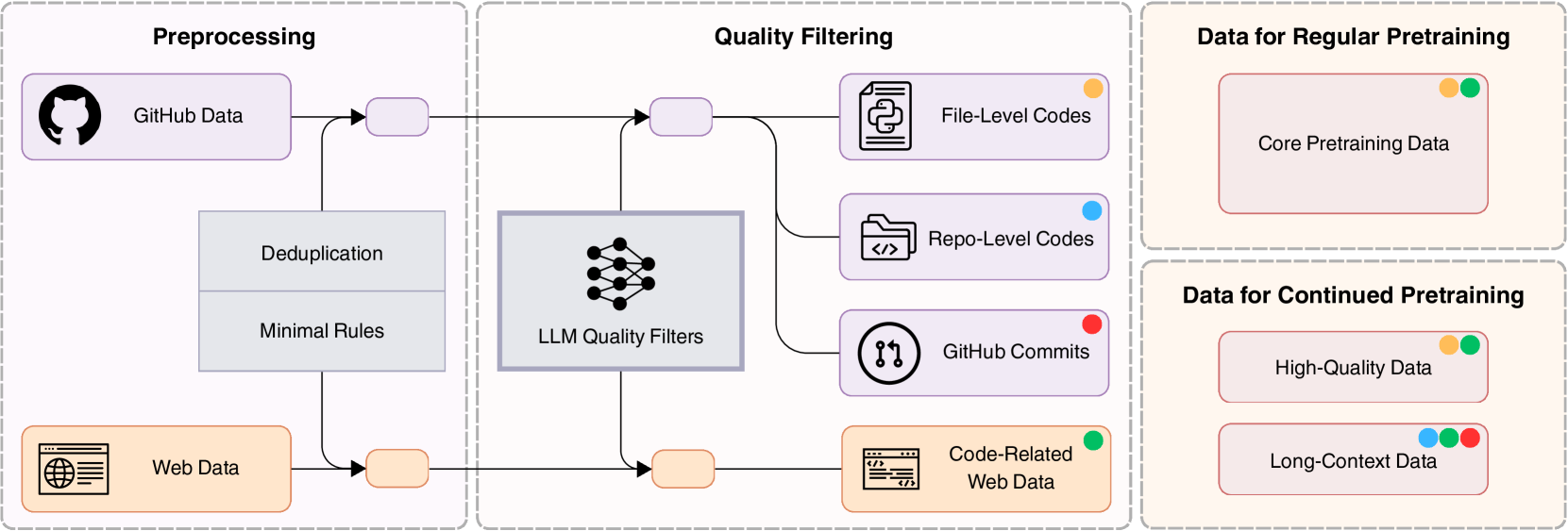
数据预处理
文件级去重 + 仓库级去重精准去重(SHA256)、近似去重(MinHash)短上下文学习;仓库级:保留项目结构,长上下文学习。去掉存在语法错误的文件减少98%原始数据。质量过滤
规则过滤存在挑战:需要多个专家共同编辑,很难一致,而且很难去评估。
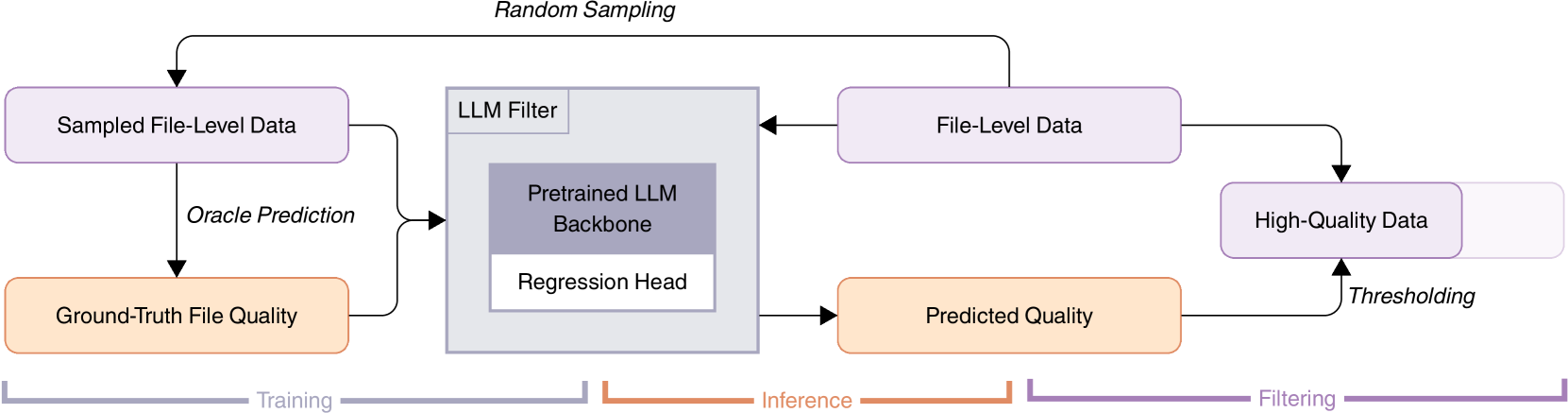
文件级质量评分模型
四维度:可读性(注释合理)、模块化(结构好)、清晰度(少冗余)、复用性(易集成)。
输出0-1分,过滤低质量代码文件,无需复杂标准。过滤一些自动生成的代码。
微调1.3B模型,回归Head,训练1个epoch,MSEloss,类别平均MAE观测指标。
训练数据:21种语言,使用GPT-4/DeepSeek-Coder-33B(V2-Chat)构造GT。
最终去除10%数据
Commit原始数据
14w 高质量仓库、7400w次提交。 Code Change 预测任务
Code change prediction 任务数据格式: 提交信息、上下文,模型预测被修改的文件、代码变化。README、目录结构、BM25算法检索的top5相关文件真实Code变化 强监督信号核心
web数据(common crawl等)中,提取出高质量、代码相关的数据。预处理
代码提取:带有显示<code></code>>标签的数据,非显示代码标签的数据。去重:使用精确去重和近似去重,同github数据一样。启发式过滤方法:去掉低质量文档(如低于10个单词)。质量过滤
识别代码相关内容 + 评估内容质量。FastText 召回代码内容没有代码标签的数据中召回代码内容训练fastText模型,识别和检索代码内容。99%召回率、45%精确率。约3%识别为代码内容 (common crawl)LLM 过滤低质数据:打0-10分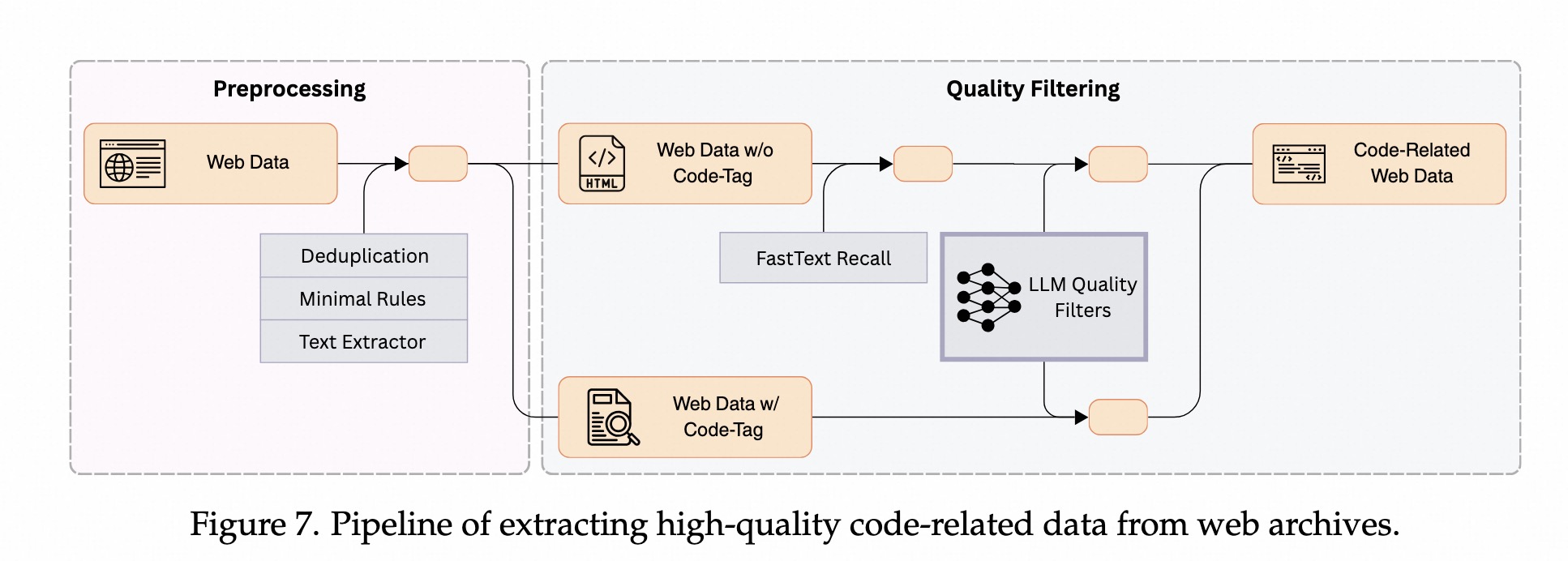
高质量fastText 检索高质量数据小且多样的高质量种子数据,10w样本,作为正样本,训练fastText模型10w正样本,负样本由随机选择和精心构建2部分组成。迭代训练:训练->召回新数据->把最好的加入种子库->重新训练2-3轮fastText模型训练逐渐扩充正样本,最终得到130b高质量数据,用作CPT文件级:结合LLM过滤,从中筛选出长上下文数据。仓库级:根据文件的平均质量分数选择高质量仓库。 主流语言(python/java/c):基于文件依赖关系做拼接其他语言(HTML/SQL/Shell):随机拼接。原始 -> 8k -> 32k模型架构
上下文长度
Token和学习率参数
初期(基础):3e-4,1万亿token,代码web+数学web数据中期(专业数据):4万亿token,精选代码数据CPT(冲刺):高质量和长上下文数据Prefix Suffix Middle vs Suffix Prefix Middle
SPM效果更好,可能和Attention机制有关系,Prefix后面紧接Middle。FIM训练比例
50%时间在训练FIM,非常重视代码补全能力降到10%,需要探索长文本和整体生成能力数据收集和处理
预训练
CPT
在预训练模型基础上,喂大量代码数据 做继续预训练,做领域适配等等。退火策略
SFT
RL

NTP
MTP
Fill-in-the-Middle (FIM)
前面的代码prefix,也要看后面的代码suffix。代码模型的特有能力之一,增强代码补全能力。Diffusion Coder Training Task
好代码随机替换成乱码/噪声。把乱码逐步还原成清晰的代码。| 任务名称 | 核心逻辑 | 典型应用场景 | 优势 |
|---|---|---|---|
| NTP (Next Token Prediction) | 猜下一个词 | 所有的 GPT 类模型 | 基础能力,学会语法和逻辑 |
| MTP (Multi-Token Prediction) | 猜下面 N 个词 | 高级模型训练 | 提高推理速度,增强逻辑连贯性 |
| FIM (Fill-in-the-Middle) | 完形填空 | IDE 里的光标补全 | 能同时看上下文,补全更准 |
| Diffusion (扩散任务) | 降噪去模糊 | 探索性架构 | 生成多样性高,可并行生成 |

整体趋势
Github 数据
Software Heritage,加入PR&Issues,包含人类如何讨论和修改代码的逻辑过程。StarCoder 数据
其他数据
