SWE 合成数据 系列
📅 发表于 2026/01/06
🔄 更新于 2026/01/06
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
swe-data
#SWE-Lego
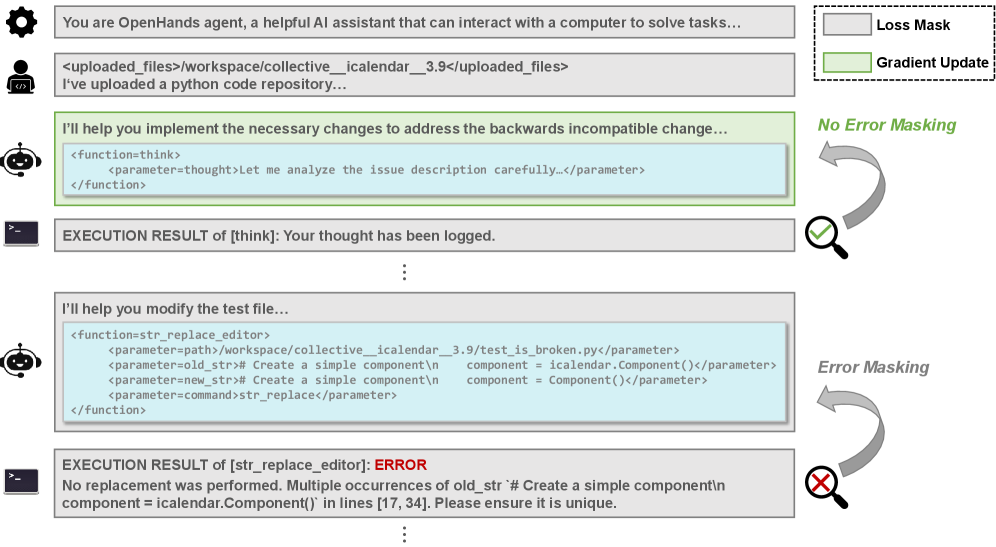
#Mask错误动作
#SFT课程学习
#BugPilot
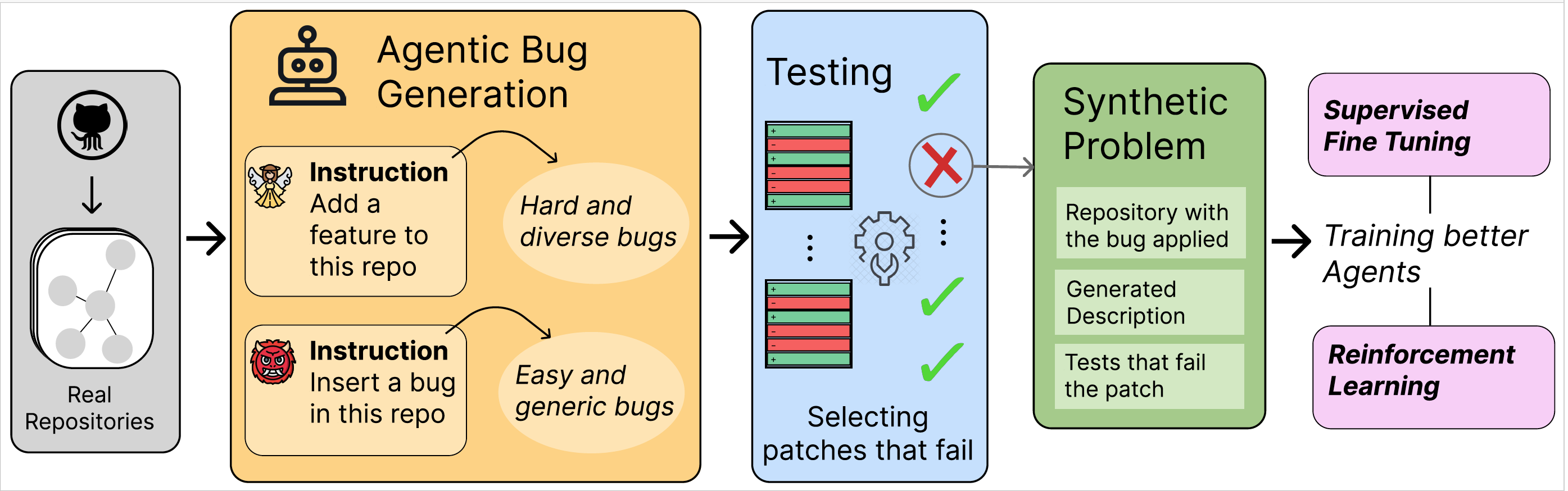
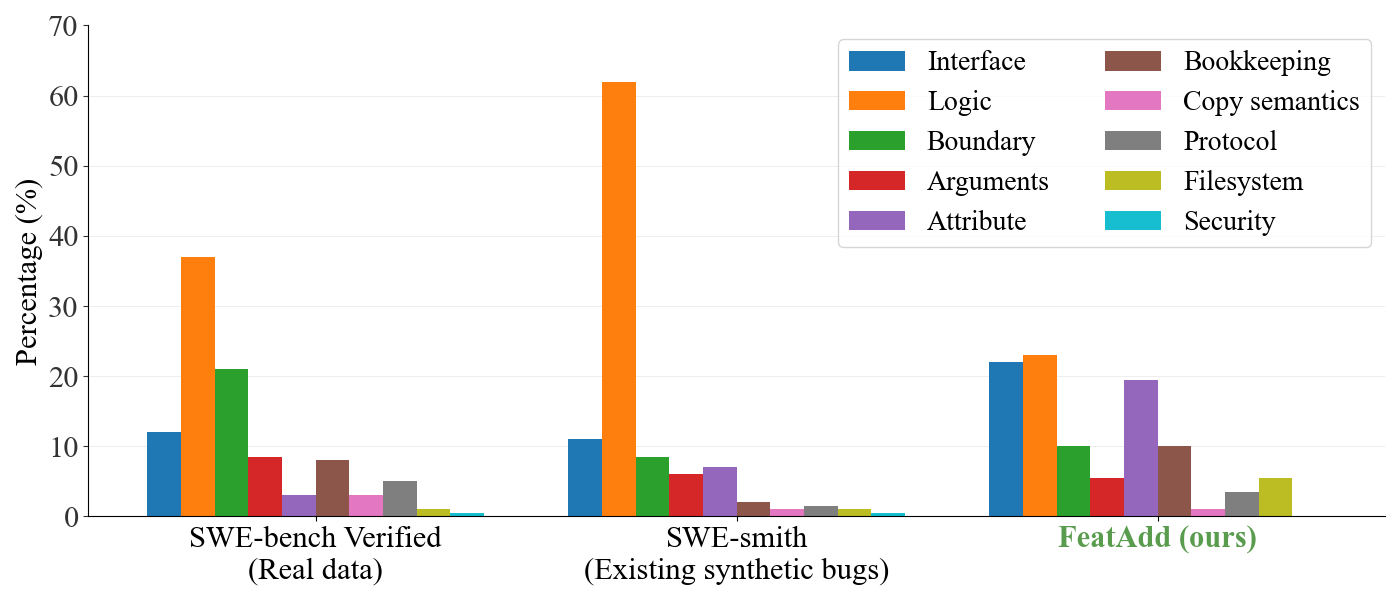
#FeatAddBug
#SWE-Mirror
#Issue迁移
#生成测试用例
#生成Bug源码,Issue描述生成
#AgentSFT 数据蒸馏
#SWE-Mirror-LM-32B
#Skywork-SWE
#SWE-rebench
#自动Issue-PR 收集
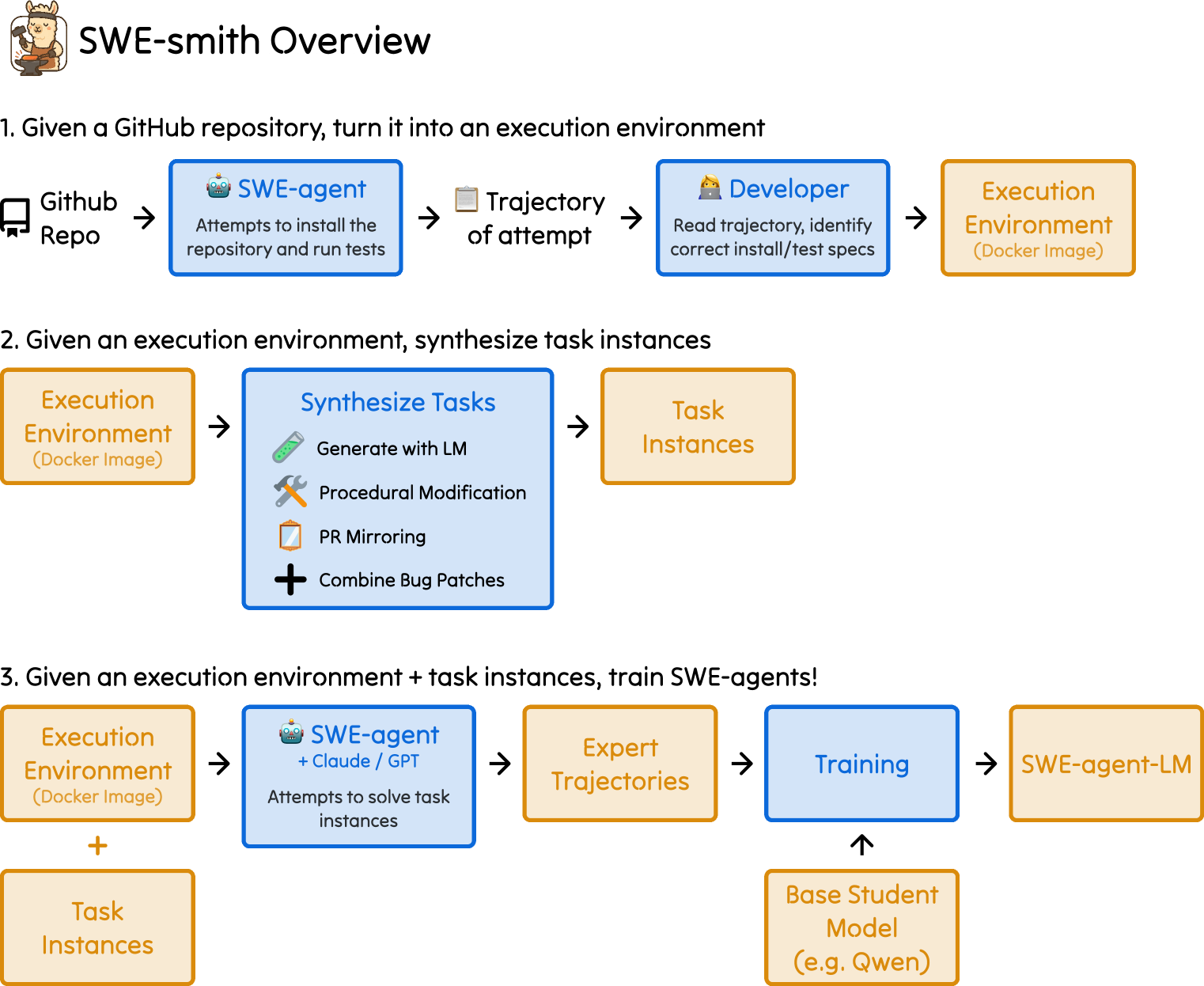
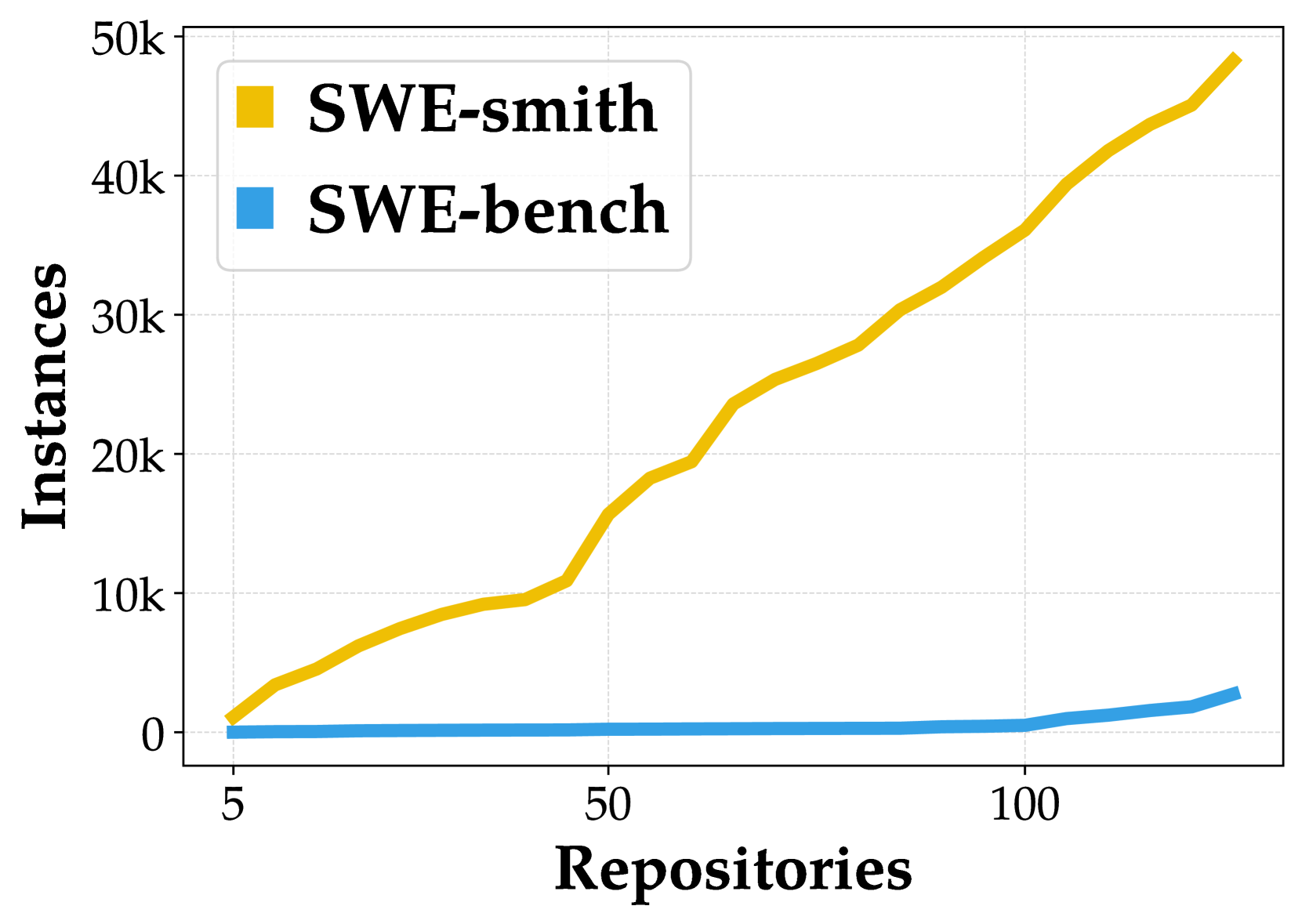
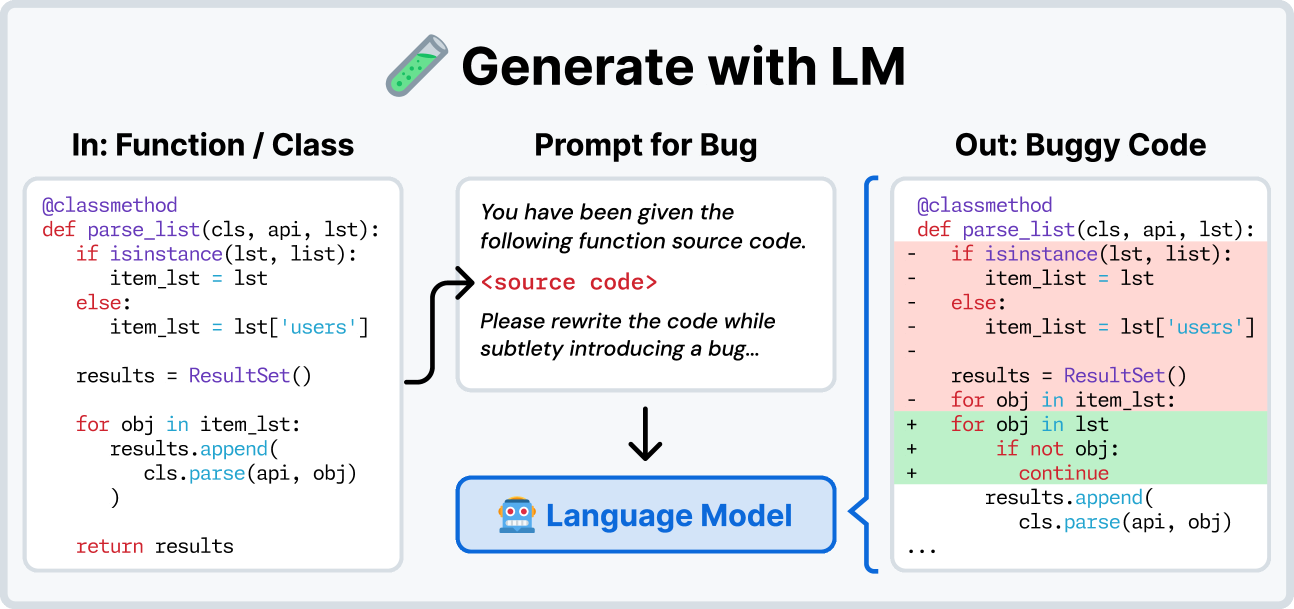
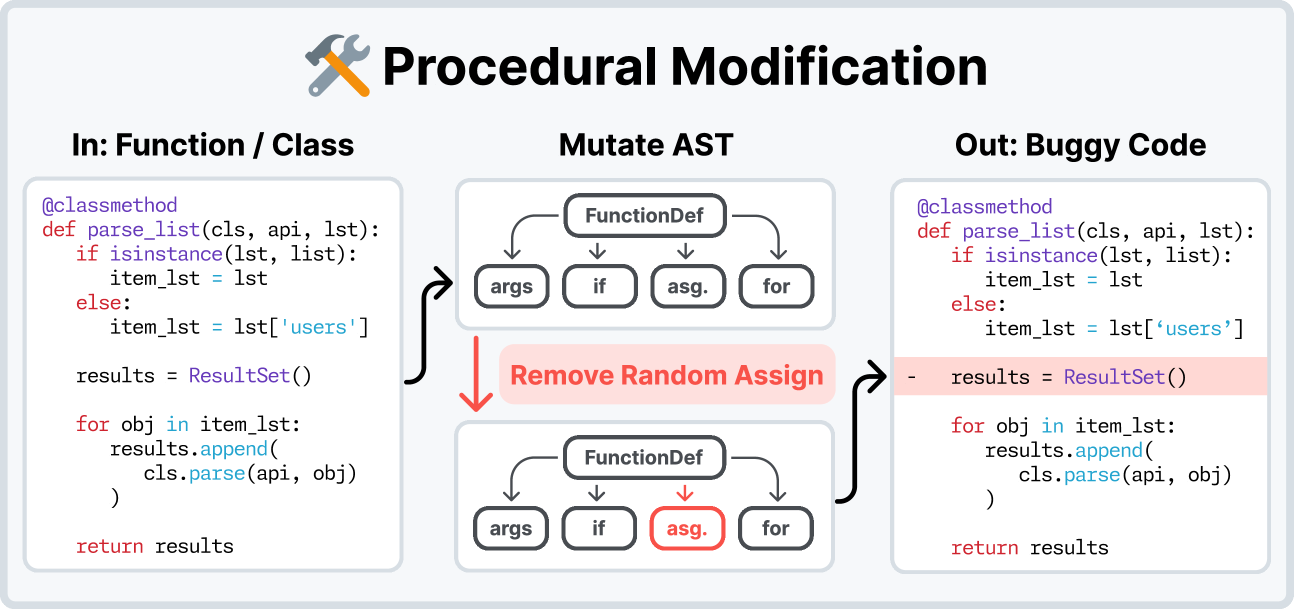
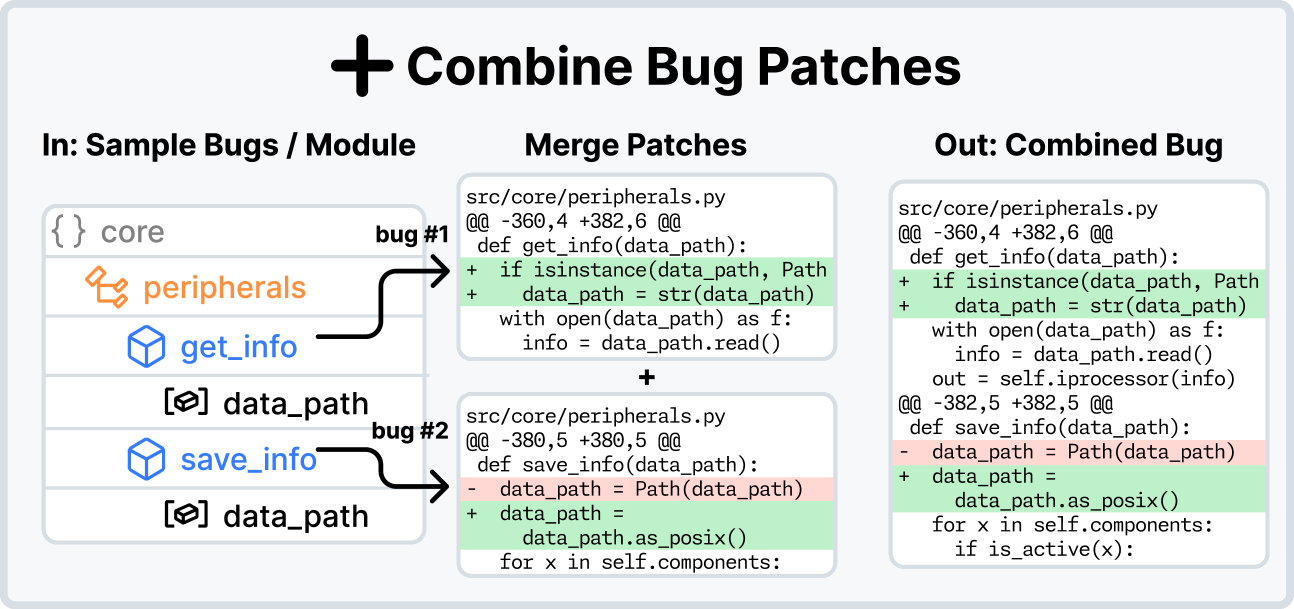
#SWE-smith
#SWE-Agent-LM-32B
#Agent安装环境
#4策略合成Bug
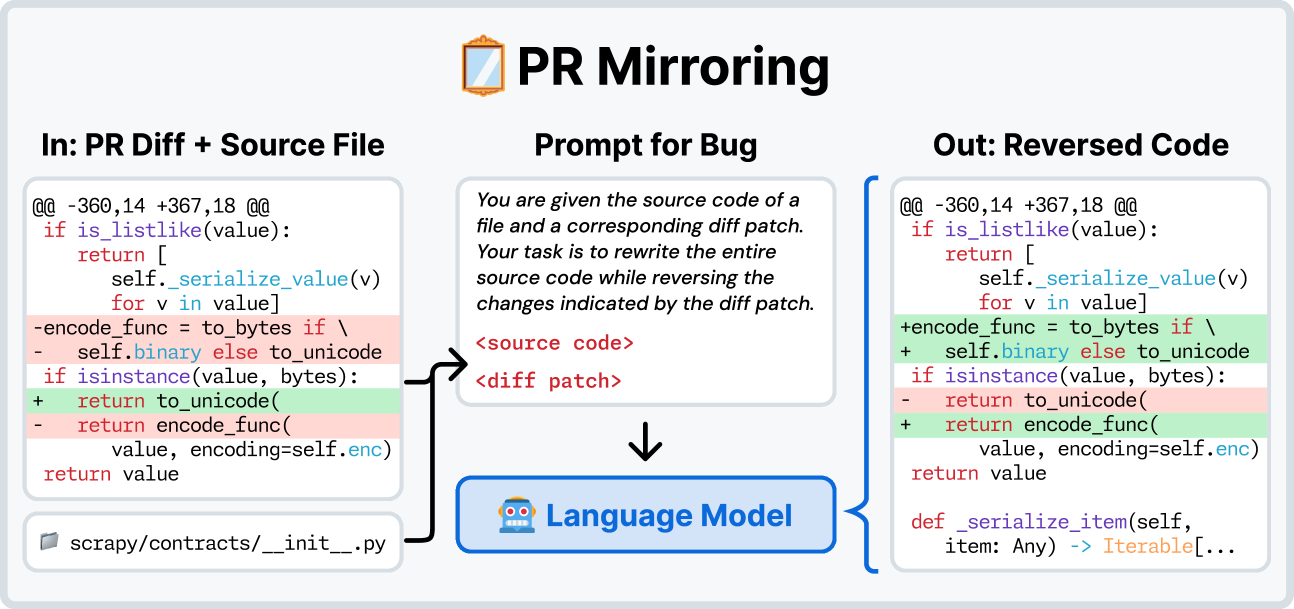
#PR Mirror
#执行验证
#逆向合成Issue
#R2E-Gym
#Hybrid TTS
#挖掘Commit数据
#SWE-Gym