LLM位置编码和长度外推系列
📅 发表于 2025/11/24
🔄 更新于 2025/11/24
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
llm-position
#Position Embedding
#绝对位置编码
#可训练式参数
#三角式
#递归式
#绝对位置编码注意力公式
#传统相对位置编码
#旋转位置编码
#RoPE
#旋转矩阵
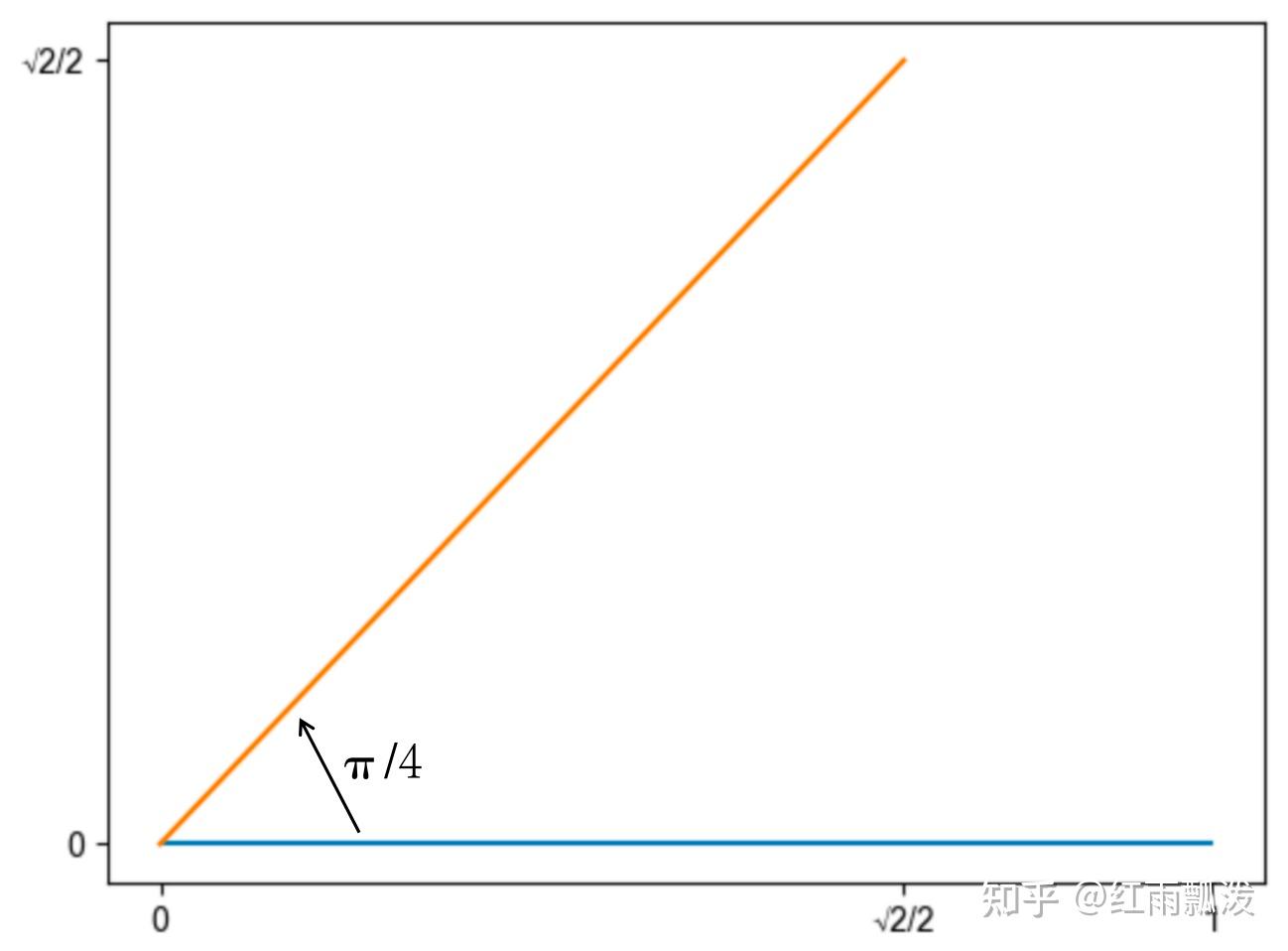
#弧度
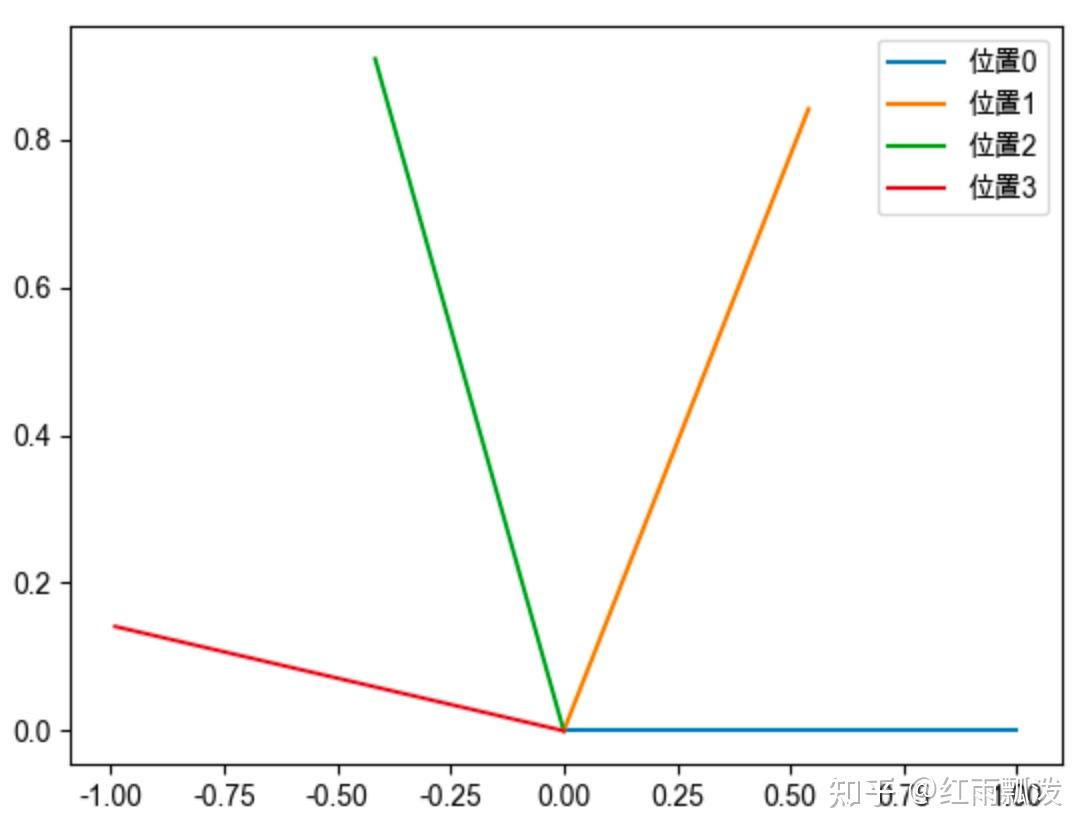
#二维旋转
#多维旋转
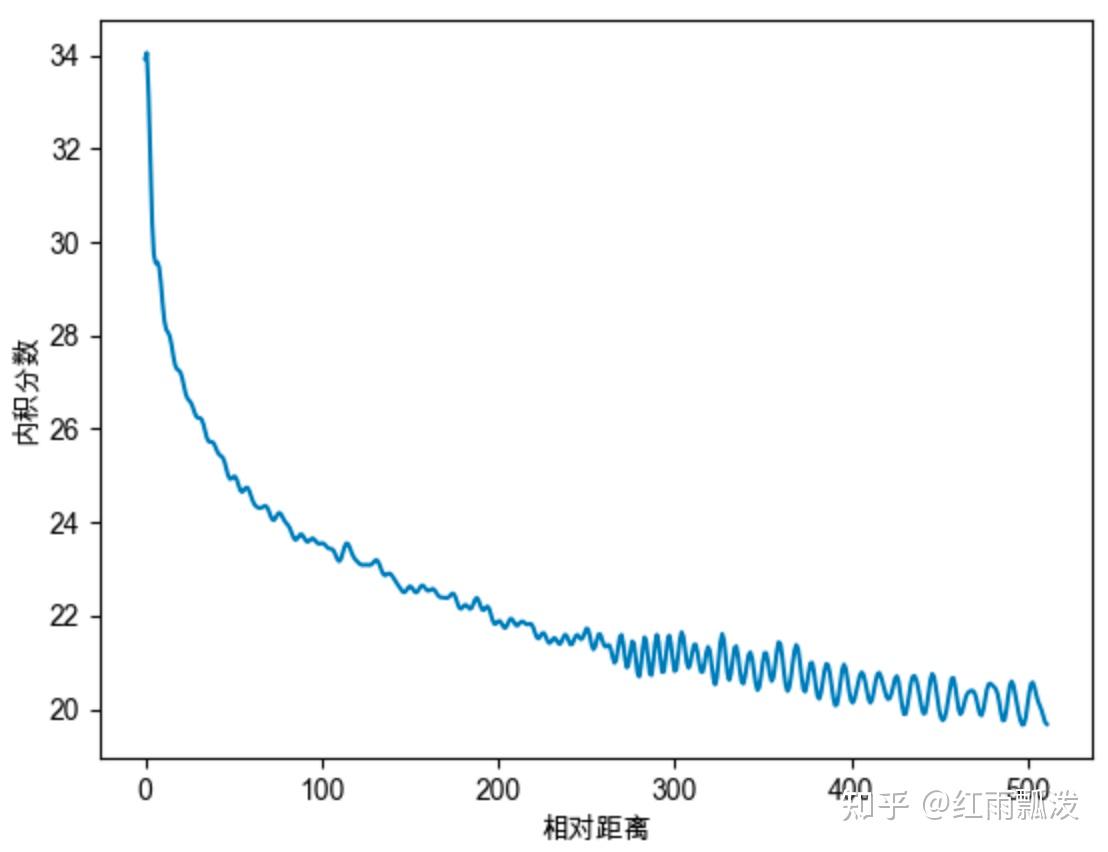
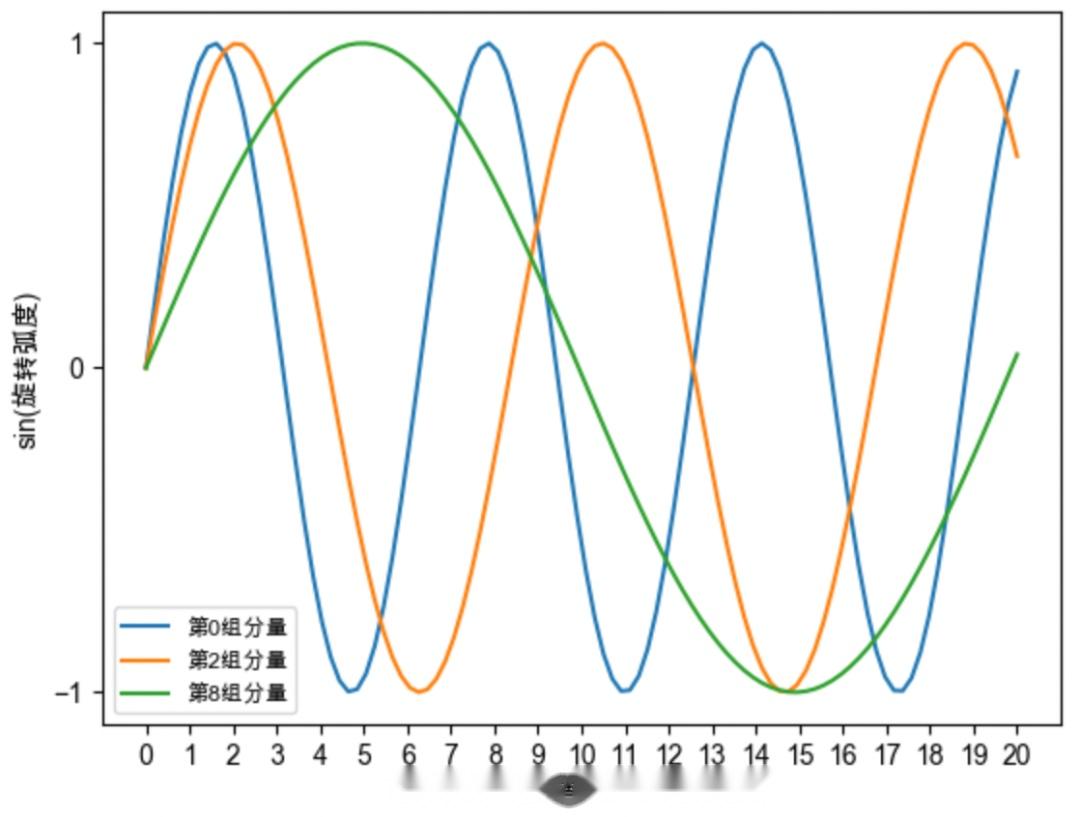
#远程衰减性
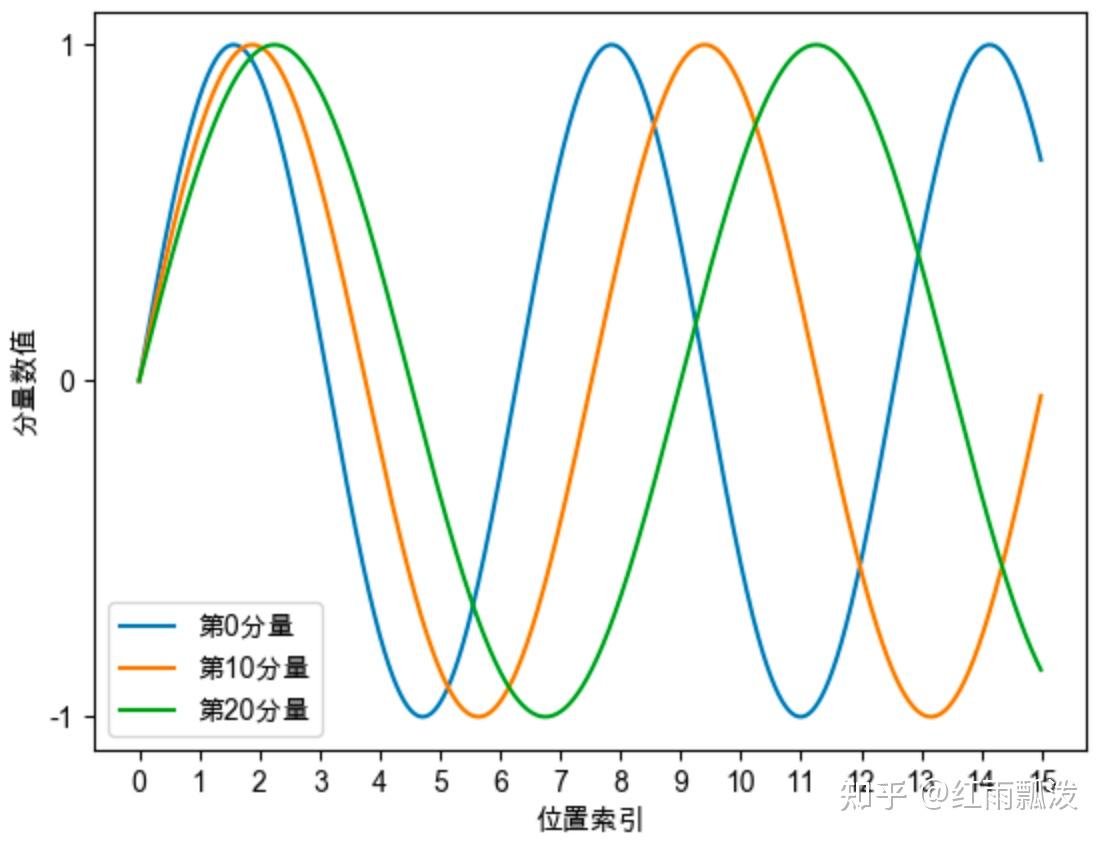
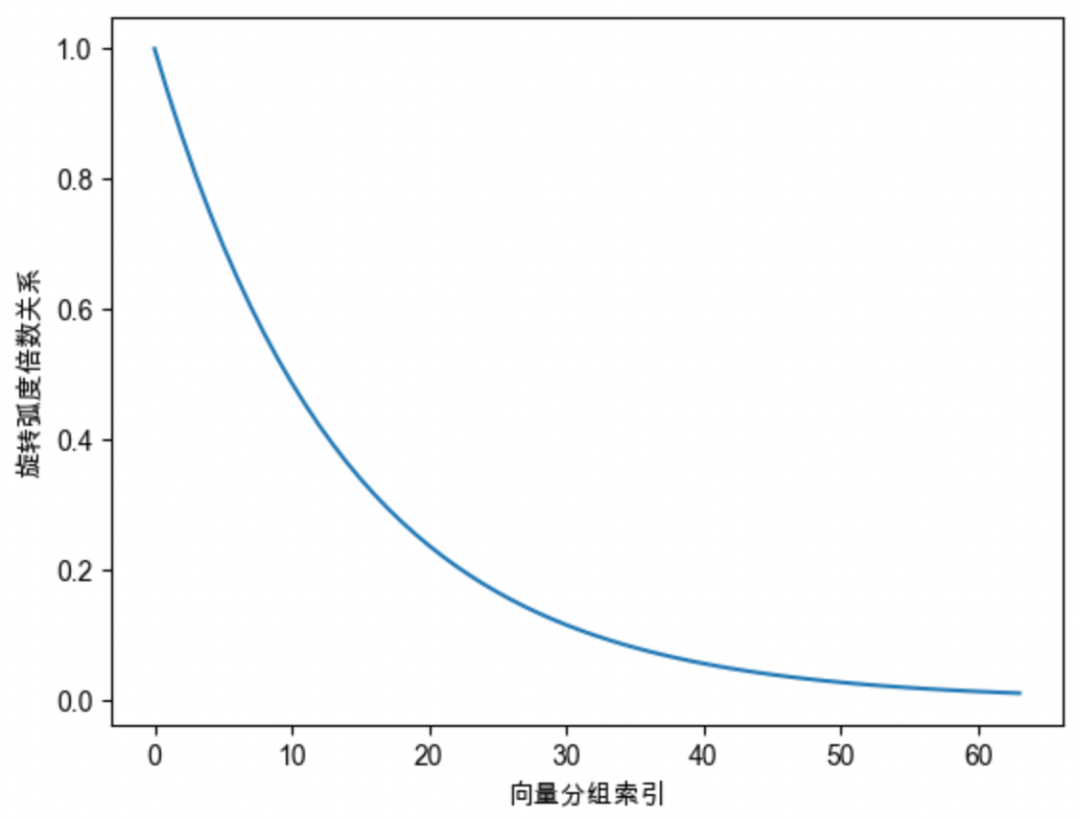
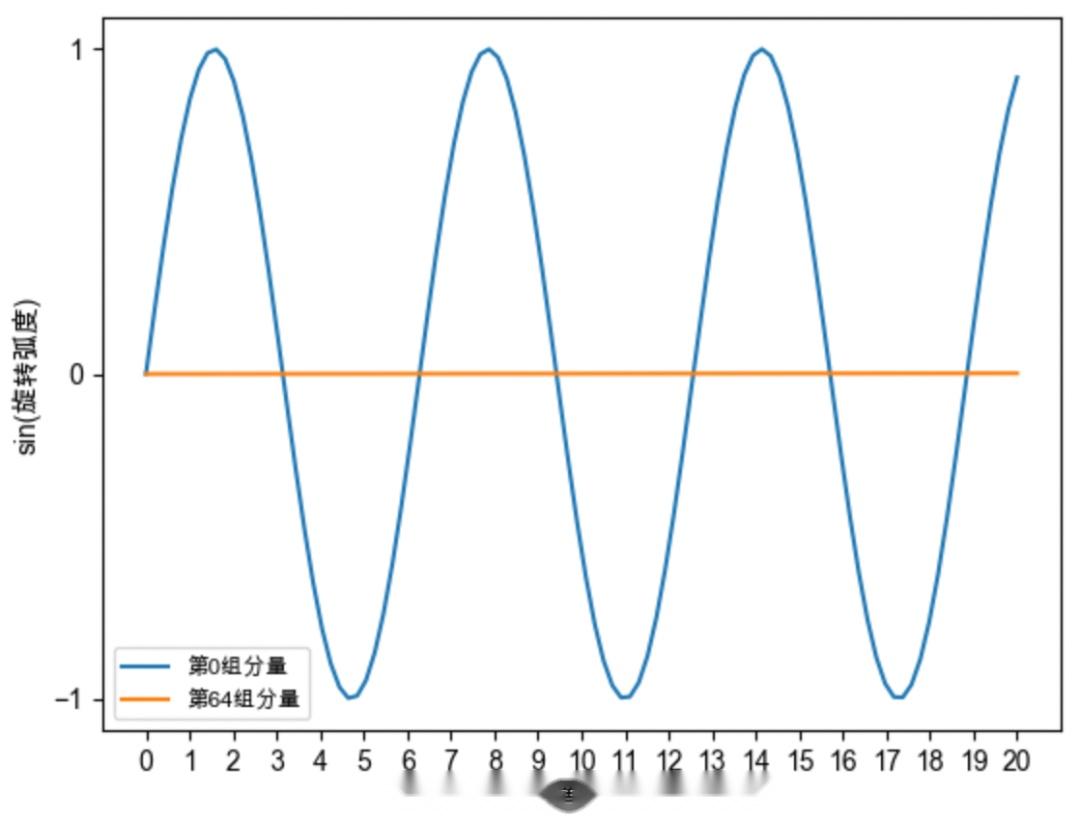
#高频分量
#低频分量
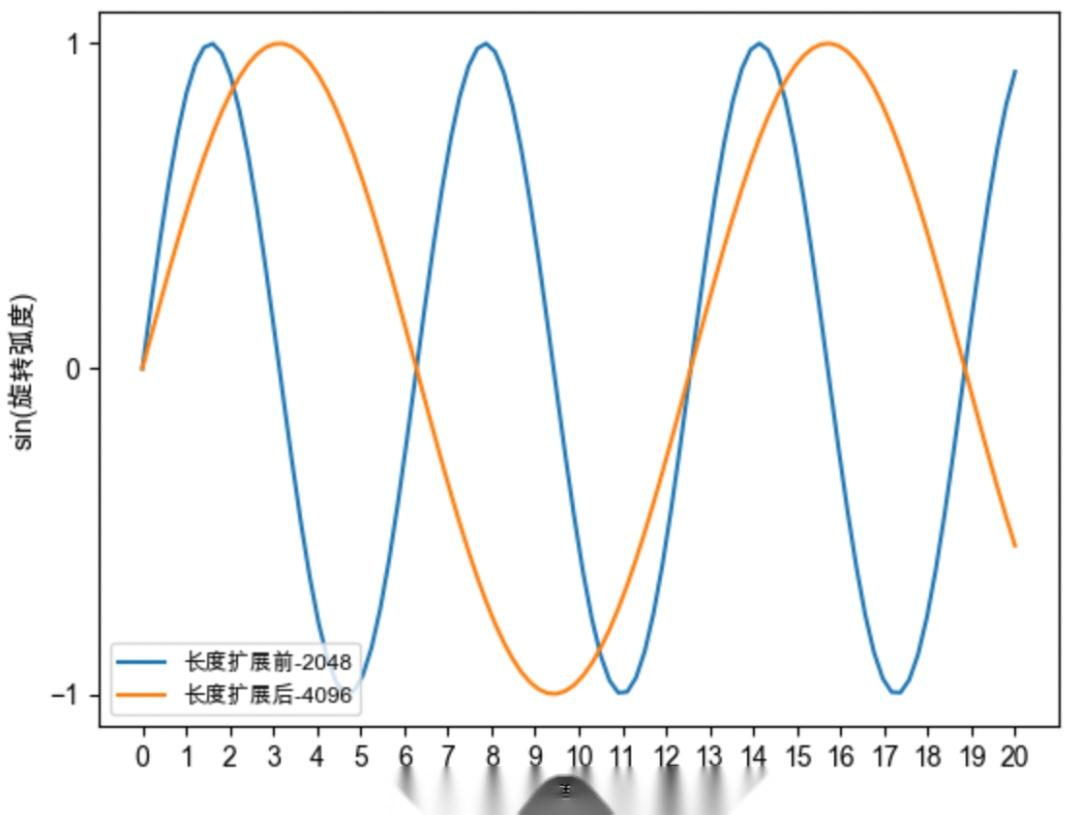
#周期性
#旋转速度
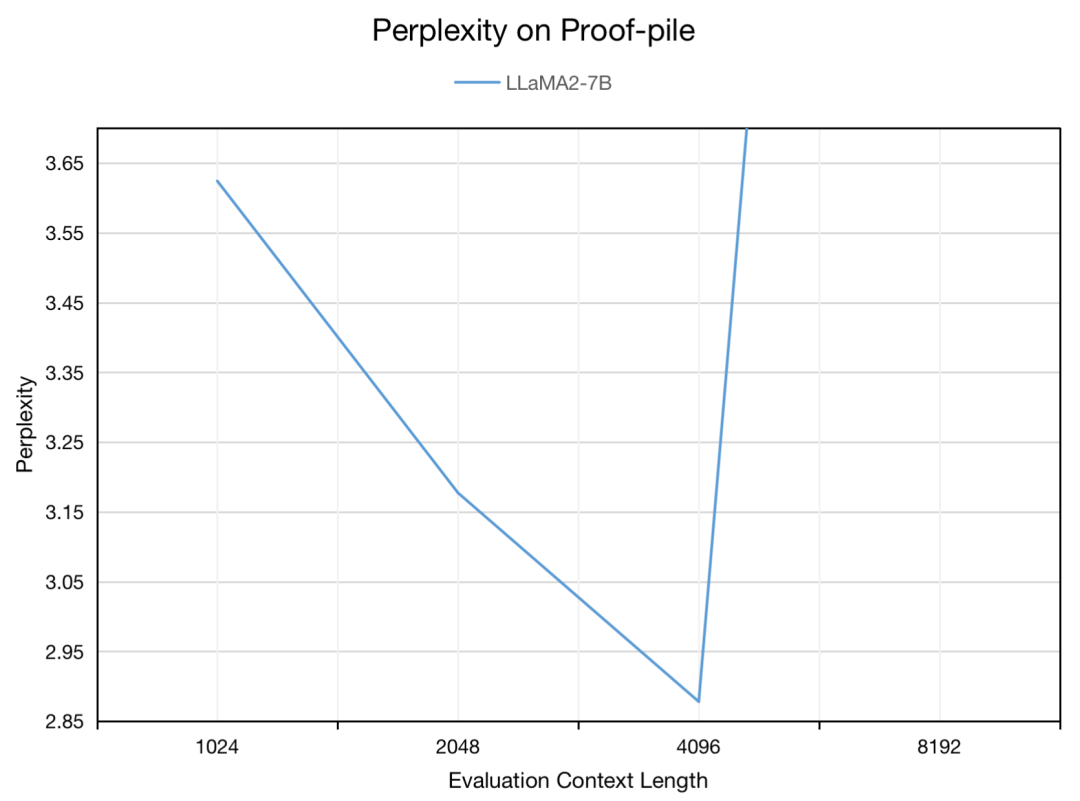
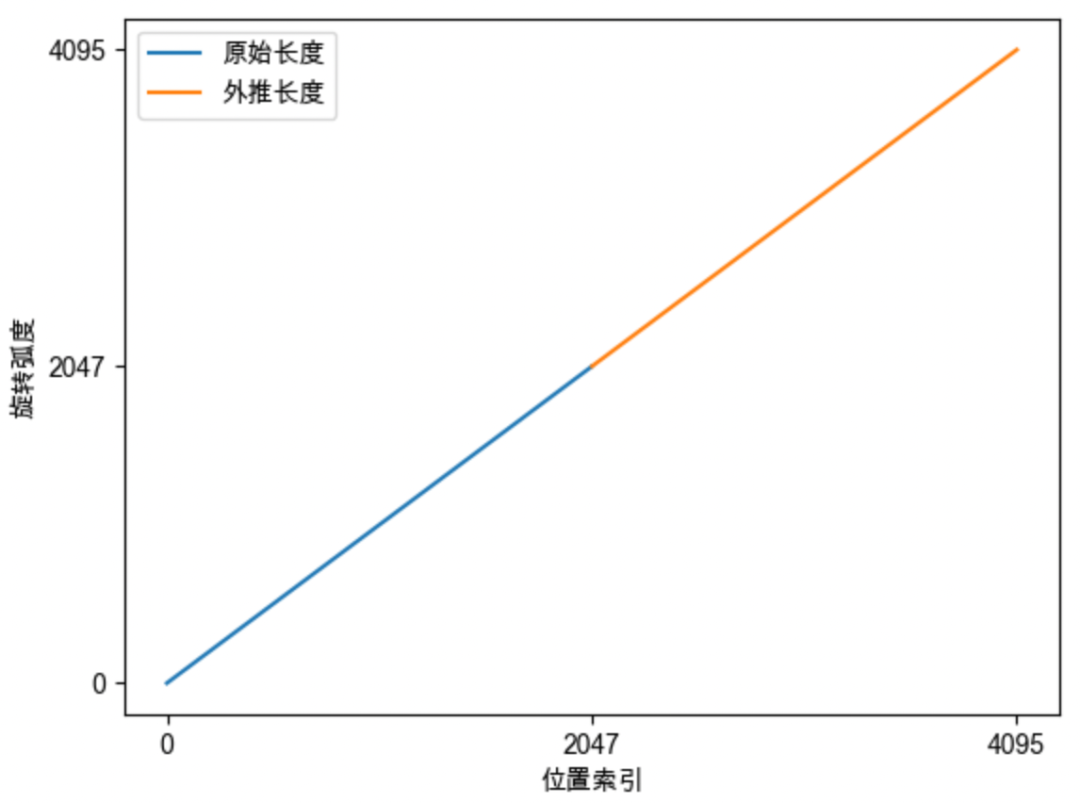
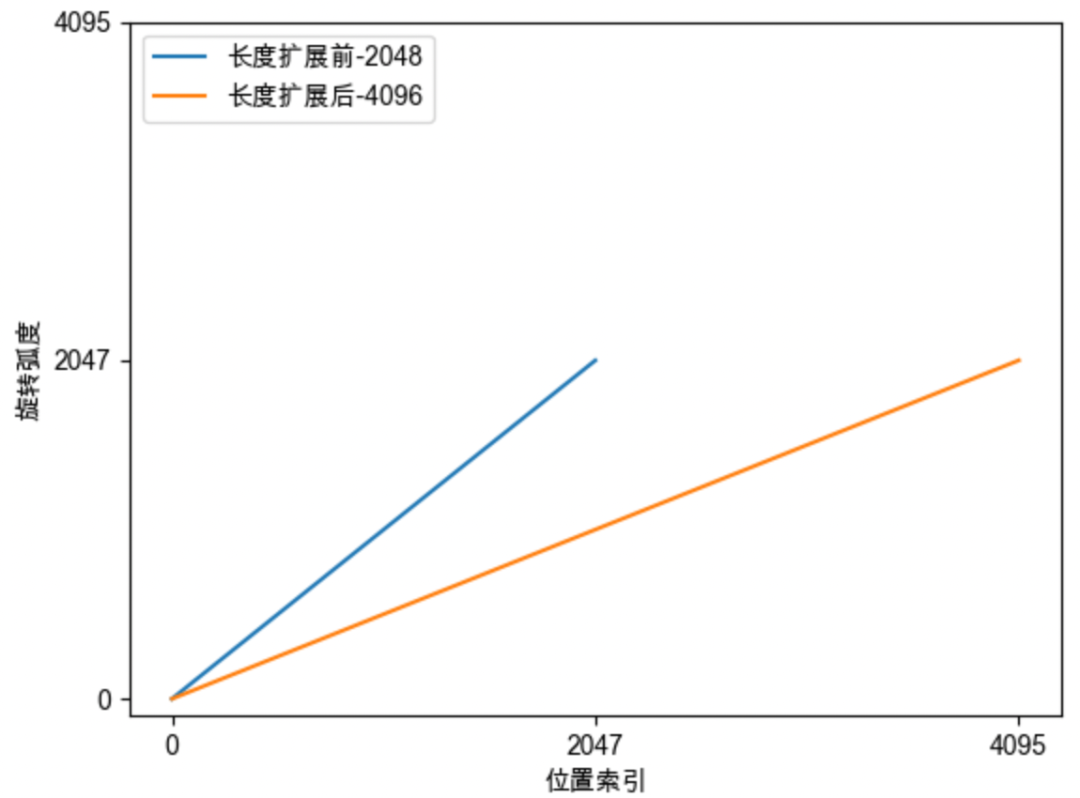
#长度外推
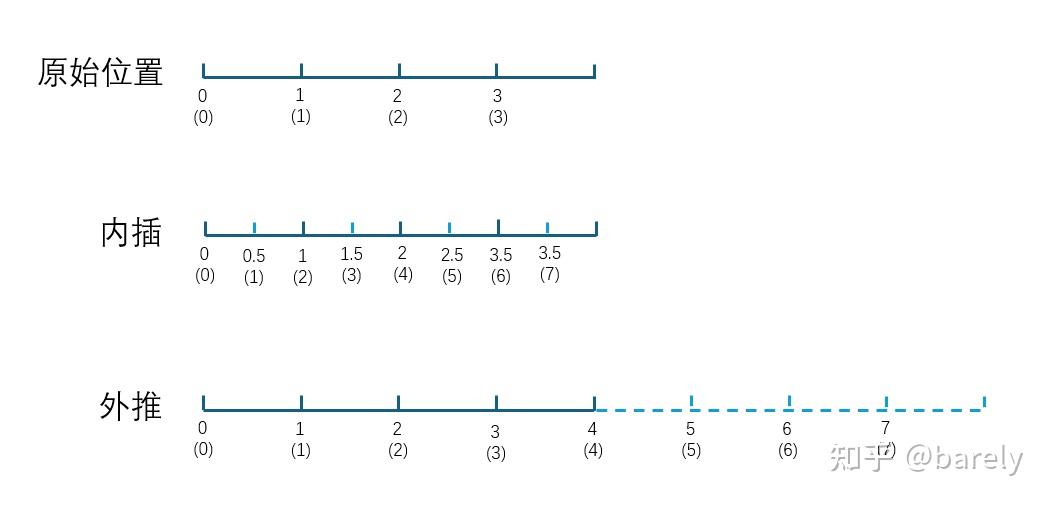
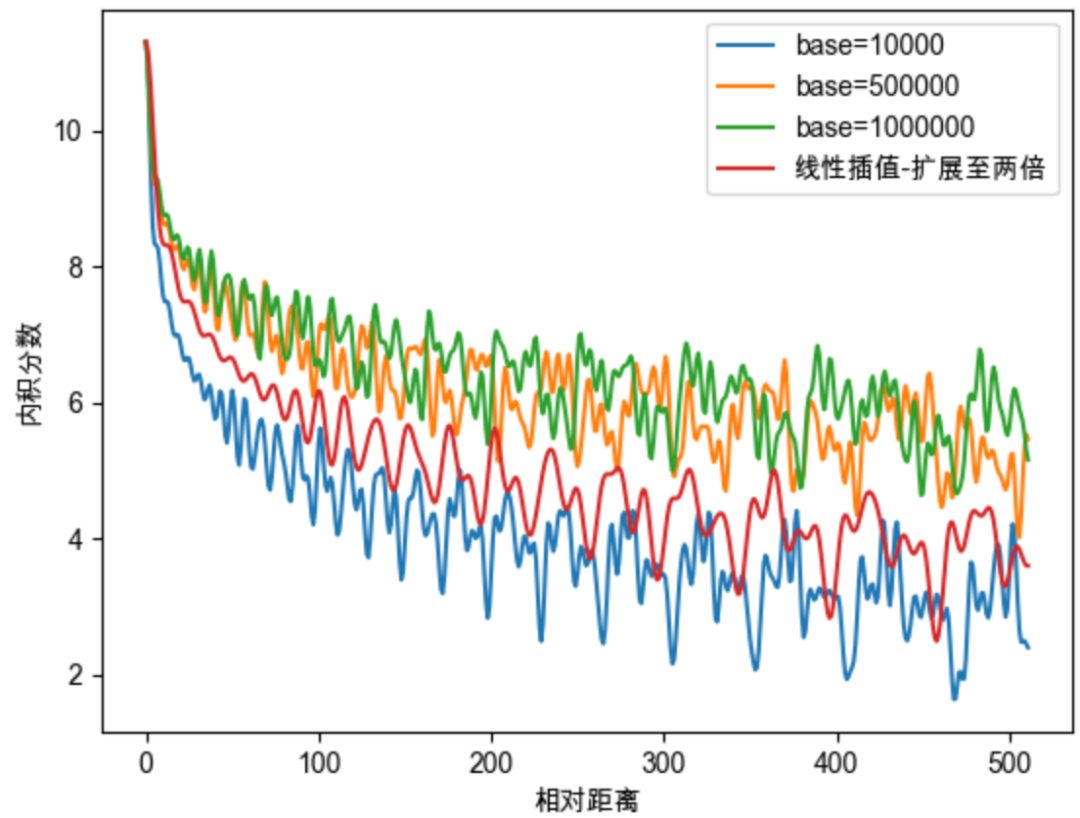
#线性位置插值
#NTK-Aware 插值
#NTK-by-parts插值
#Dynamic NTK
#YaRN
#注意力修正