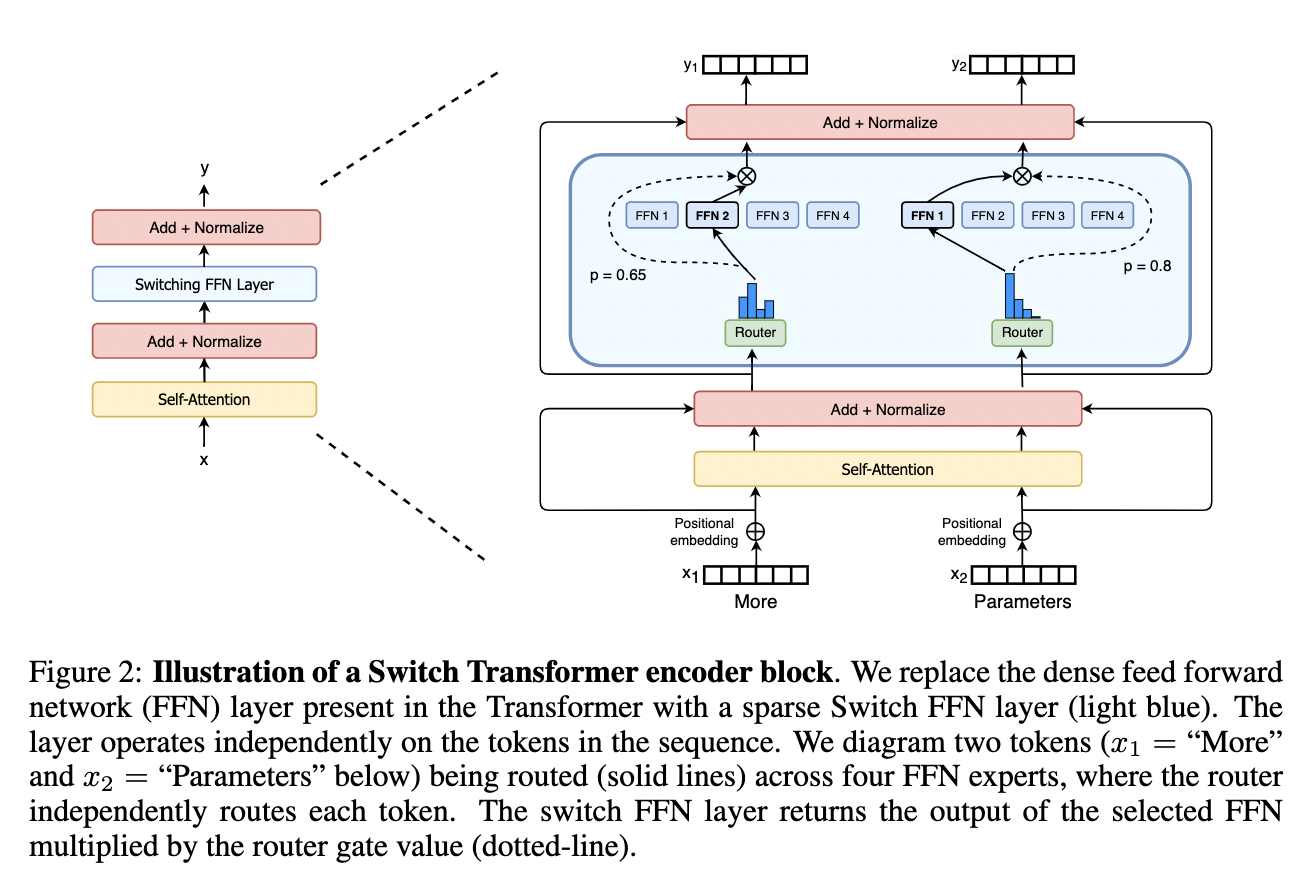
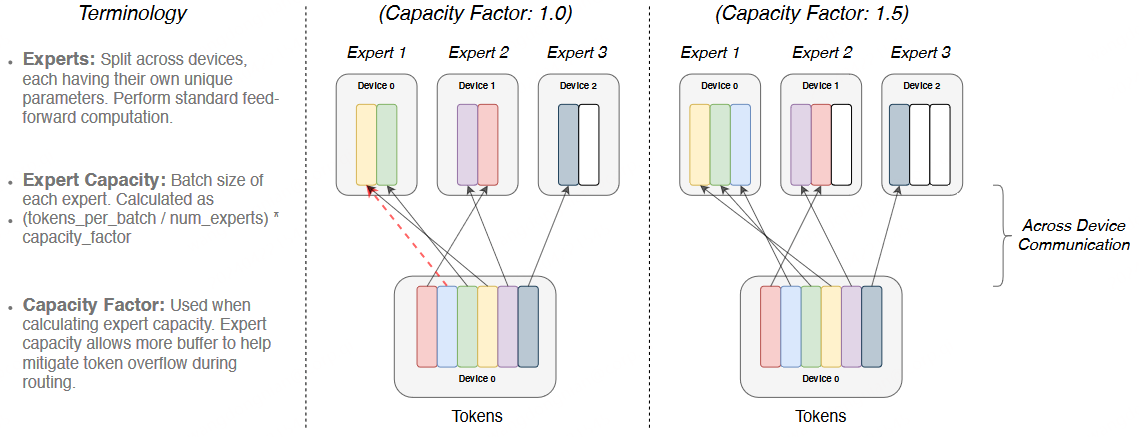
LLM 架构相关
📅 发表于 2025/07/09
🔄 更新于 2025/07/09
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
llm-architecture
#Decoder-only
#Encoder
#Dense Model
#MoE Model
#工业级大模型标准方案
#专家
#门控网络
#Recurrent Model
#RWKV
#Mamba
#DeltaNet
#Gated DeltaNet
#Diffusion-LLM
#DiffSeq
#SSD-LM
#LLaDA
#Gemini Diffusion
#Hybrid Architectures
#Jamba
#Qwen3-Next
#DeepSeek