🧱 基础建设
🔄 强化学习
🌟 行业方向
🏹 领域任务
🤖 Agent
📦 其他
🧩 刷题
⚙️ 配置
🧘 心得
🗣️ NLP
🧬 基础理论
🧮 算法专栏
☕ 其他
Appearance
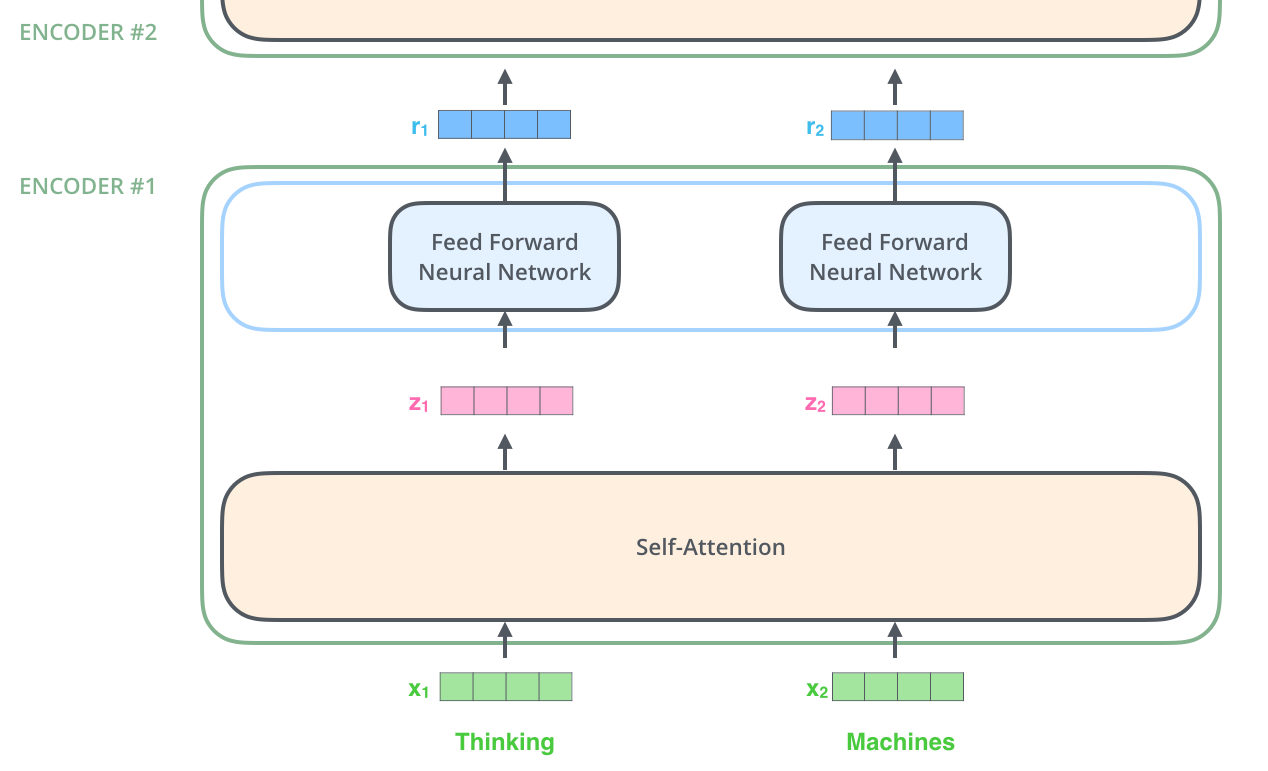
旧笔记:大名鼎鼎的Transformer
残差连接&层归一化
1、Transformer vs RNN
2、Encoder 并行化
3、Decoder 并行