图文介绍RNN注意力机制
📅 发表于 2017/10/10
🔄 更新于 2017/10/10
👁️ 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#自然语言处理
#Attention Model
#Encoder-Decoder
#注意力
#机器翻译
用图文简单介绍基于RNN的Encoder-Decoder中注意力机制
举个翻译的例子,原始句子
现在采用Encoder-Decoder架构模型,如下图
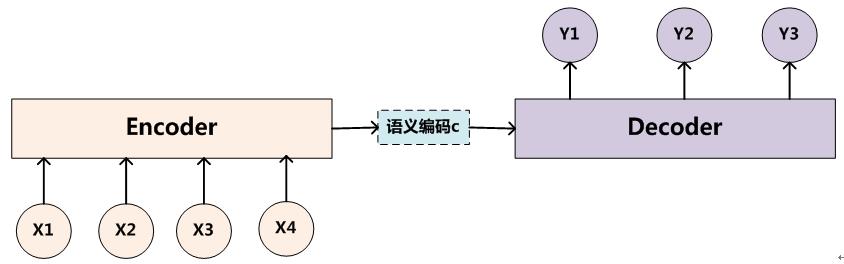
Encoder会利用整个原始句子生成一个语义向量,Decoder再利用这个向量翻译成其它语言的句子。这样可以把握整个句子的意思、句法结构、性别信息等等。具体框架可以参考Encoder-Decoder框架。
Encoder对中间语义向量c :
Decoder根据语义
Encoder-Decoder是个创新大杀器,是个通用的计算框架。Encoder和Decoder具体使用什么模型,都可以自己选择。通常有CNN,RNN,BiRNN,GRU,LSTM, Deep LSTM。上面的内容任意组合,只要得到的效果好,就是一个创新,就可以毕业了。(当然别人没有提出过)
在生成目标句子
句子较短时问题不大,但是较长时,所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,会丢失更多的细节信息。
例子
比如输入Tom chase Jerry,模型翻译出 汤姆 追逐 杰瑞。在翻译“杰瑞”的时候,“Jerry”对“杰瑞”的贡献更重要。但是显然普通的Encoder-Decoder模型中,三个单词对于翻译“Jerry-杰瑞”的贡献是一样的。
解决方案应该是,每个单词对于翻译“杰瑞”的贡献应该不一样,如翻译“杰瑞”时:
Attention Model的架构如下:
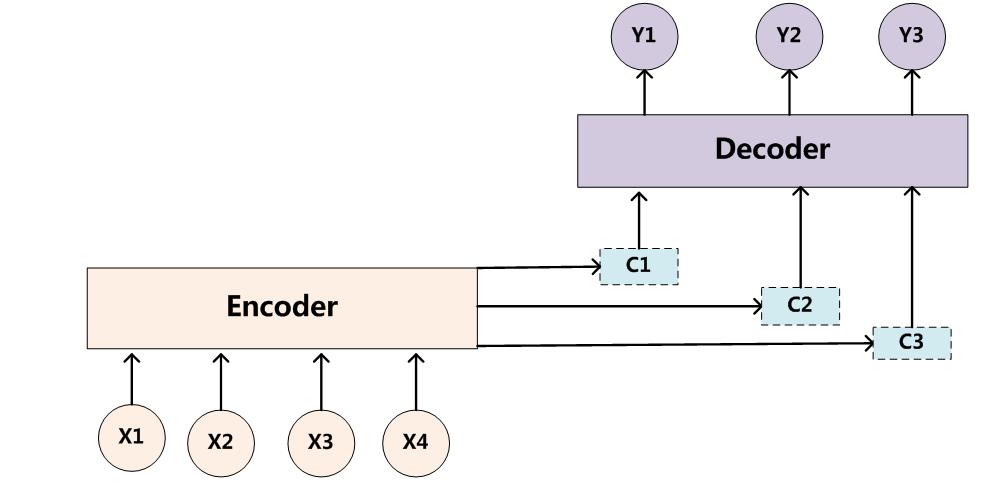
如图所示,生成每个单词
例如,前3个单词的生成:
注意力分配概率
例如汤姆 收到来自Chase的注意力概率是0.2。
有下面的注意力分配矩阵:
第
g函数 表示注意力分配后的整个句子的语义转换信息,一般都是加权求和,则有语义向量计算公式:
其中
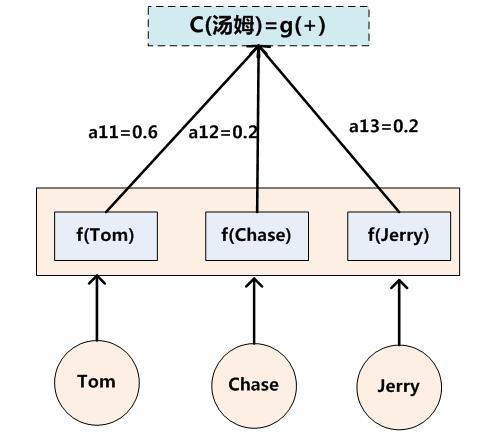
语义向量需要注意力分配概率和Encoder输入单词变换函数来共同计算得到。
但是比如汤姆收到的分配概率
这里采用RNN作为Encoder和Decoder来说明。
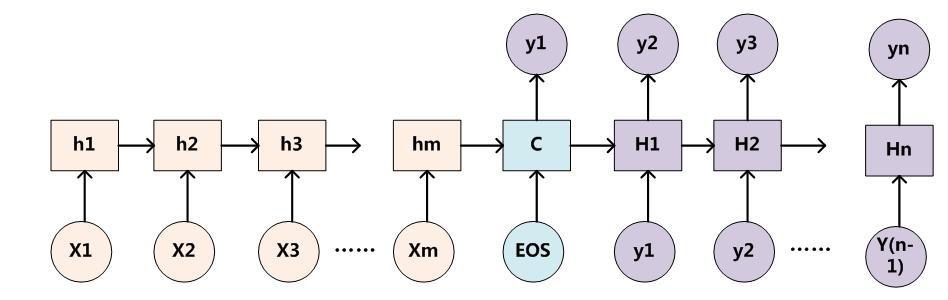
注意力分配概率如下图计算
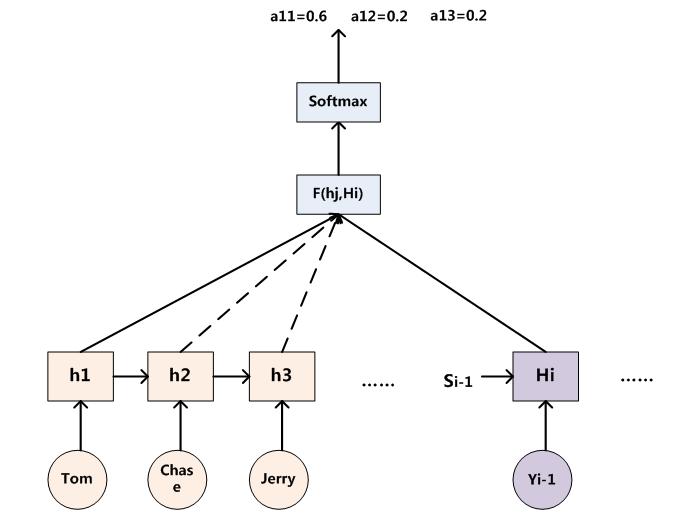
对于对齐函数F来进行计算的,两个参数:输入节点
softmax就得到了注意力分配概率。
一般地,会把AM模型看成单词对齐模型,输入句子单词和这个目标生句子成单词的对齐概率。
其实,理解为影响力模型也是合理的。就是在生成目标单词的时候,输入句子中的每个单词,对于生成当前目标单词有多大的影响程度。
AM模型有很多的应用,思想大都如此。
比如文本摘要的例子,输入一个长句,提取出重要的信息。
输入"russian defense minister ivanov called sunday for the creation of a joint front for combating global terrorism"。
输出"russia calls for joint front against terrorism"。
下图代表着输入单词对输出单词的影响力,颜色越深,影响力越大,注意力分配概率也越大。
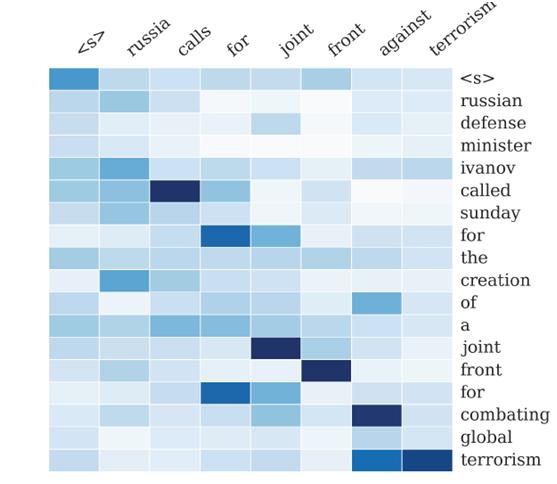
参考这篇论文 。
生成目标单词
符号意义说明
隐层状态
求当前Decoder隐层状态
语义向量
语义向量:分配权值
分配概率
注意力分配概率
分配能量
Decoder由4层组成
Decoder输入
Embedding Layer
输入
# y(i-1)
embedded = embedding(last_rnn_output)Attention Layer
输入
attn_weights[j] = attn_layer(last_hidden, encoder_outputs[j])
attn_weights = normalize(attn_weights)计算语义向量
求语义向量
context = sum(attn_weights * encoder_outputs)RNN Layer
输入
rnn_input = concat(embeded, context)
rnn_output, rnn_hidden = rnn(rnn_input, last_hidden)输出层
输入
output = out(embedded, rnn_output, context)