Word2vec之公式推导笔记
📅 发表于 2017/11/02
🔄 更新于 2017/11/02
👁️ 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#word2vec
#深度学习
cs224n word2vec 简介和公式推导
词的意思就是idea,如下:
传统使用分类学去建立一个WordNet,其中包含许多上位词is-a和同义词集等。如下:
| 上义词 | 同义词 |
|---|---|
| entity, physical_entity,object, organism, animal | full, good; estimable, good, honorable, respectable |
离散表达的问题:
每个单词使用one-hot编码,比如hotel=settle hotel的时候也应该去匹配包含settle motel的文章。 但是我们的查询hotel向量和文章里面的motel向量却是正交的,算不出相似度。
通过一个单词的上下文去表达这个单词。
You shall know a word by the company it keeps. --- JR. Firth
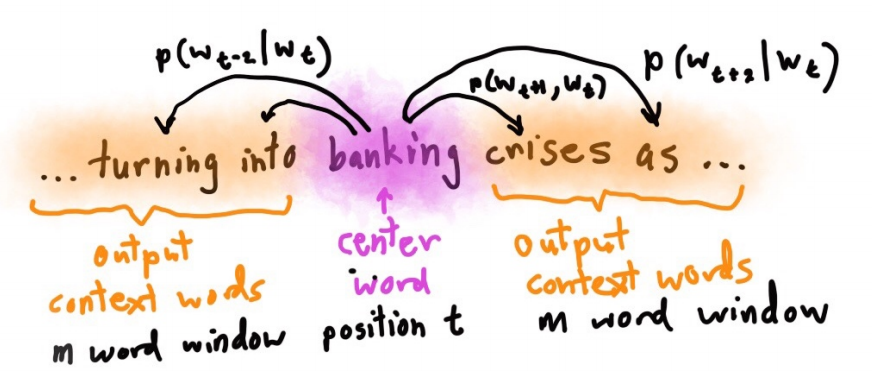
例如,下面用周围的单词去表达banking :
government debt problems turning into banking crises as has happened in saying that Europe needs unified banking regulation to replace the hodgepodge
稠密词向量
一个单词的意义应该是由它本身的词向量来决定的。这个词向量可以预测出的上下文单词。
比如lingustics的词向量是
构建一个模型,根据中心单词
损失函数如下,
在每个单词和其上下文之间进行预测。
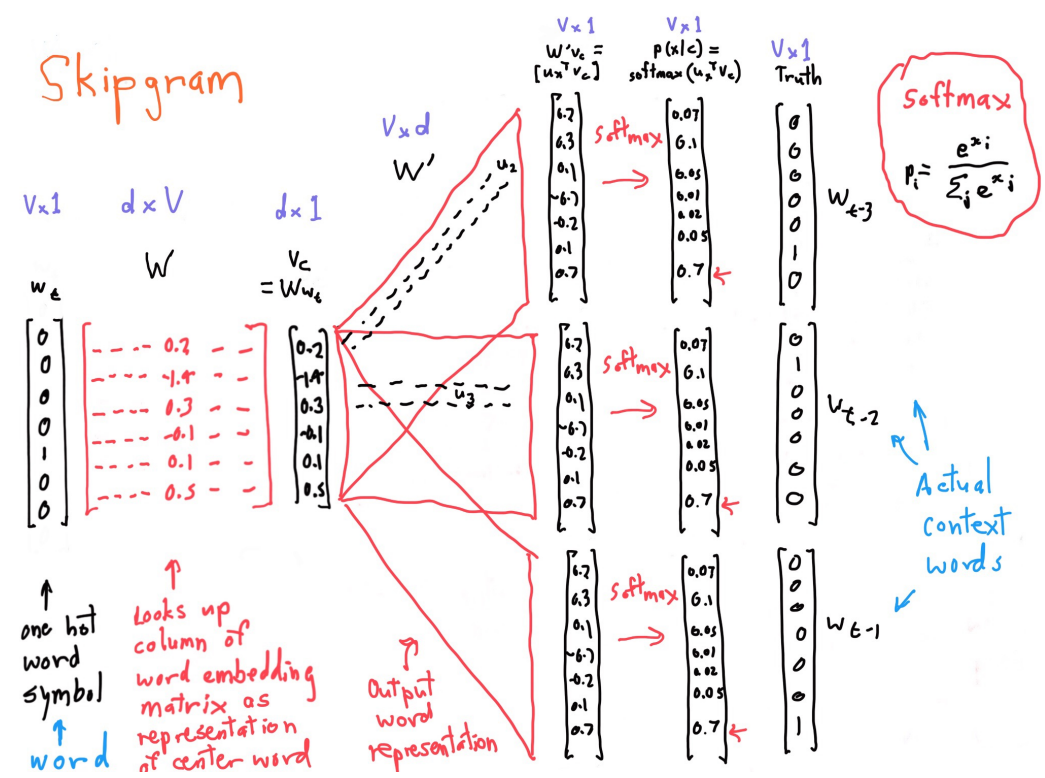
有两种算法:
两个稍微高效的训练方法:
课上只是Naive softmax。两个模型,两种方法,一共有4种实现。这里是word2vec详细信息。
对于每个单词
目标函数
一般使用negative log likelihood :负采样教程。
要最大化目标函数,就得得到损失函数。对于对数似然函数,取其负对数就可以得到损失函数,再最小化损失函数,其中
词汇和词向量符号说明:
计算
两个单词越相似,点积越大,向量点积如下:
softmax之所以叫softmax,是因为指数会让大的数越大,小的数越小。类似于max函数。下面是计算的详细信息:
一些理解和解释:
设
这里只计算
用
向量偏导计算公式,
函数偏导计算,链式法则,
最小化损失函数:
这里只计算
部分1推导
部分2推导
所以,综合起来可以求得,单词o是单词c的上下文概率
实际上偏导是,单词
在一个window里面,对中间词汇
比如句子We like learning NLP。设
有了梯度之后,参数减去梯度,就可以朝着最小的方向走了。机器学习梯度下降
随机梯度下降
预料会有很多个window,因此每次不能更新所有的。只更新每个window的,对于window t: