Agent-Tool-RL 笔记
📅 发表于 2025/05/30
🔄 更新于 2025/05/30
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
agent-tool-rl
#ToRL
#ToolRL
#ReTool
#OTC-PO
#SkyRL-v0
#Nemotron-Tool-N1
#ARTIST
#ZeroTIR
#Tool-Use
#Agent-RL
同haotian的Zero-TIR-RL应该是同一个工作。
❓问题背景
📕核心方法
基于ZeroRL 提出 ZeroTIR
不使用工具监督示例,仅靠任务成功奖励,纯RL让模型自主编写python解决math问题。
不依赖人工示例,允许模型自主探索,实现纠正反思等能力
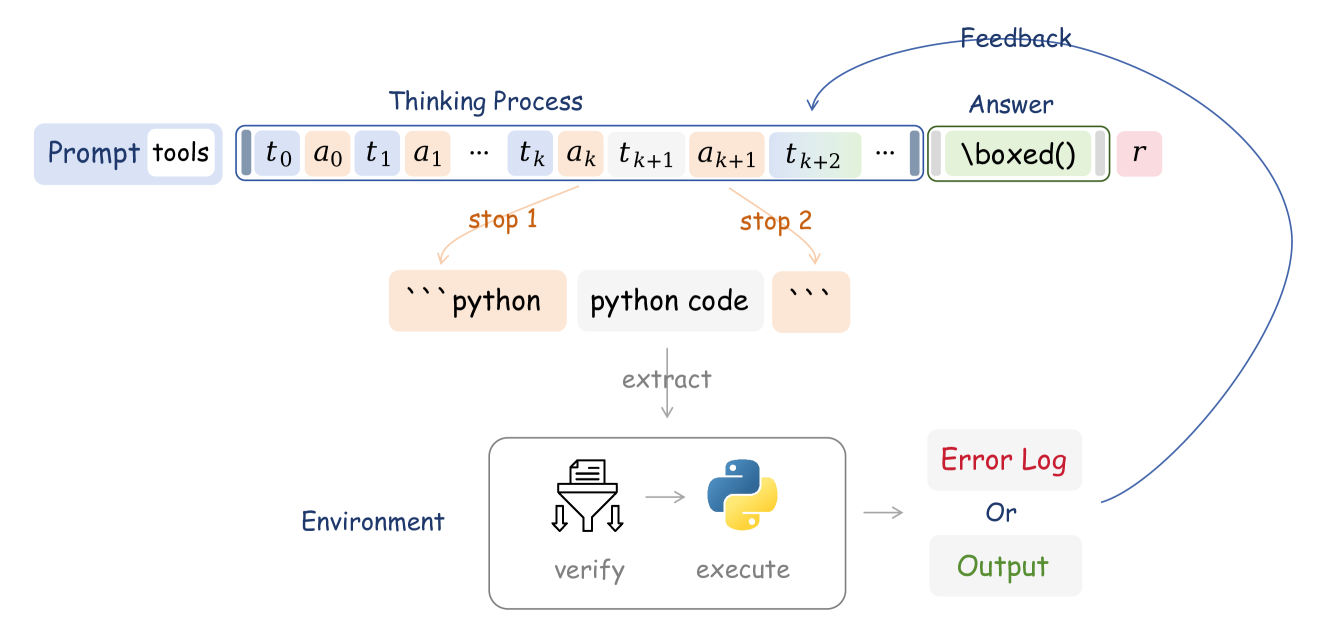
✍️实验配置
🍑关键结果
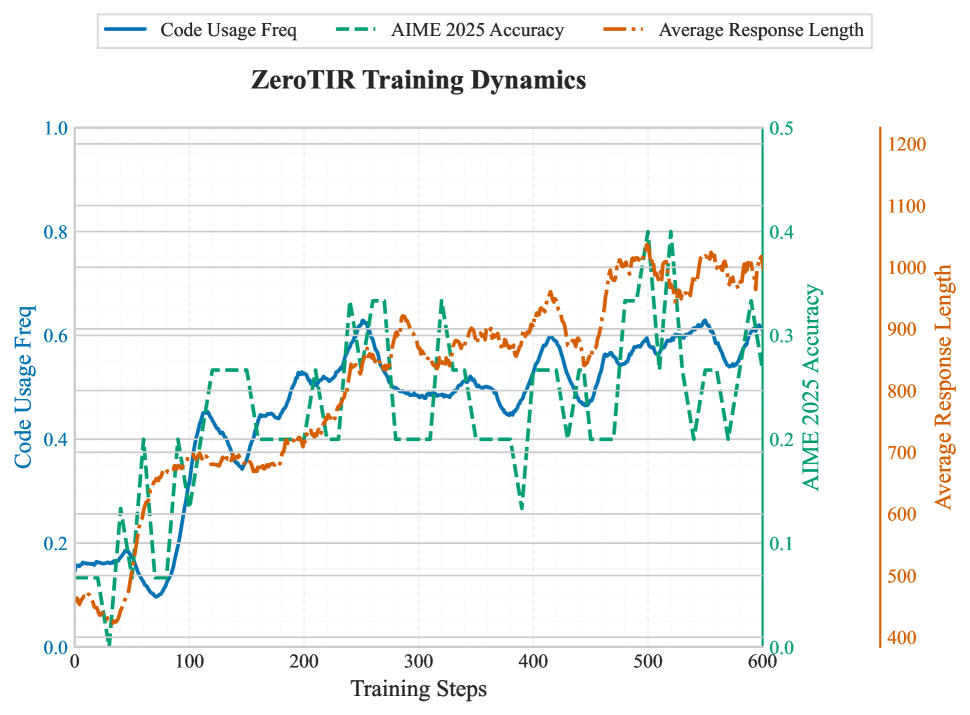
❓问题背景
📕核心方法


✍️实验配置
🍑关键结果
❓问题背景
当前SFT让模型使用工具(蒸馏/死记硬背),存在问题
📕核心方法
Rule-based RL方法:让模型自己学会推理,不是简单记忆模仿
<think>...</think>一下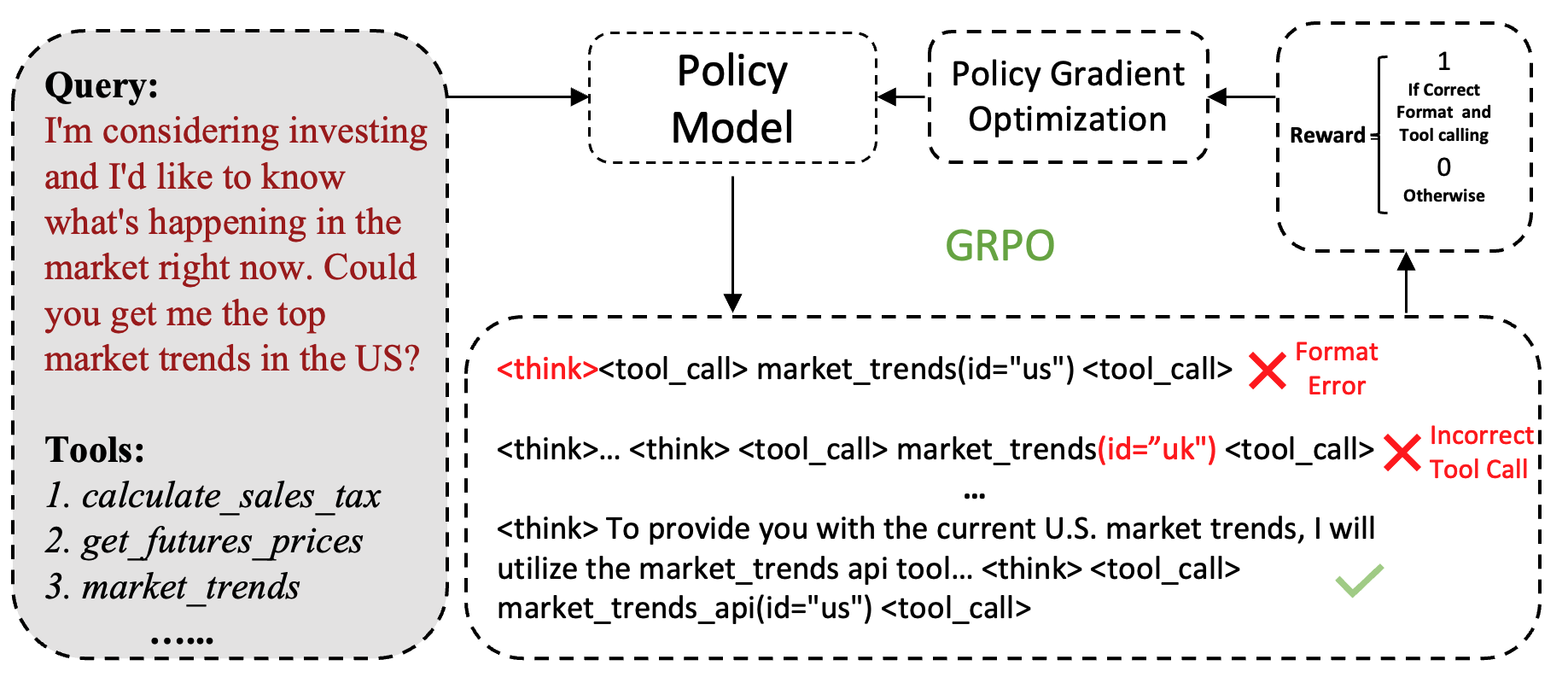
✍️实验配置
🍑关键结果
API-Bank
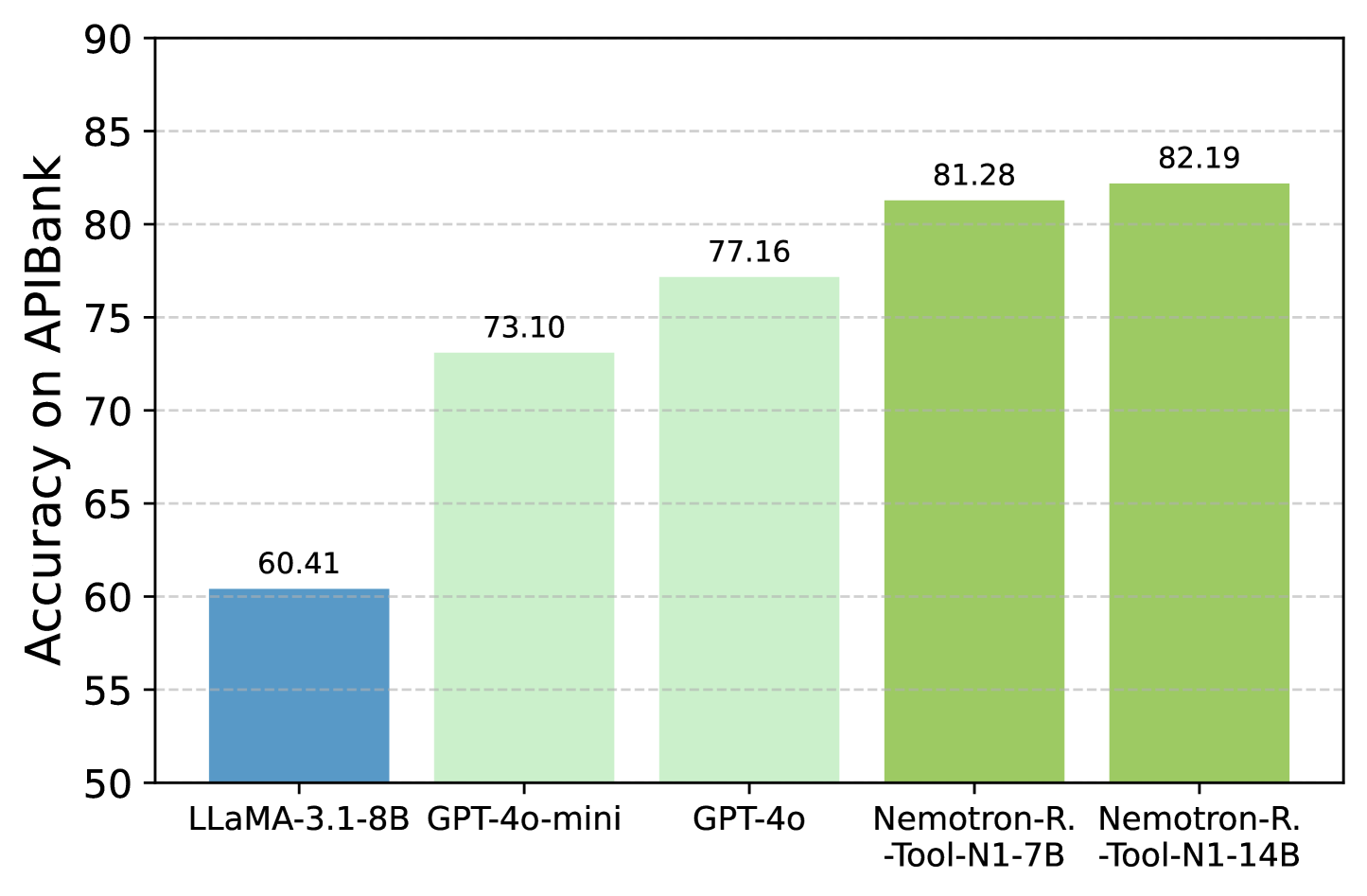
BFCL(new sota)
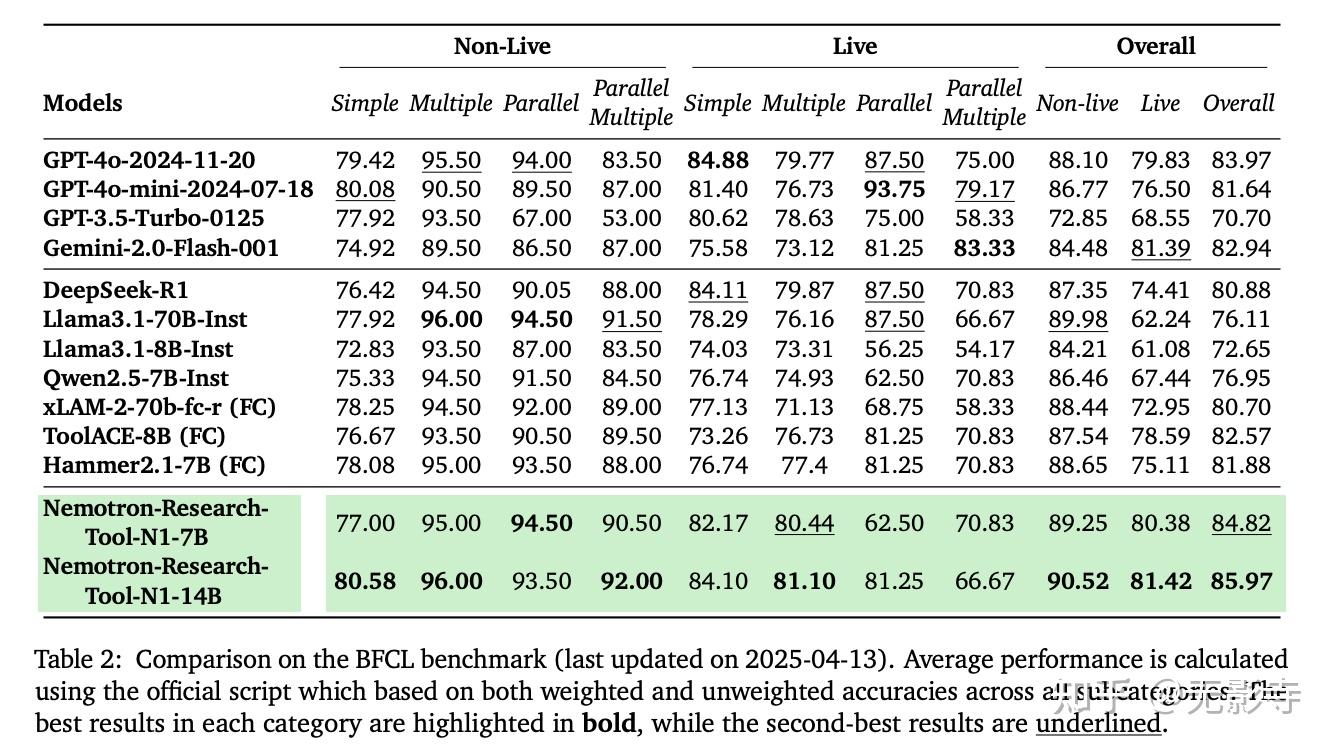
❓问题背景
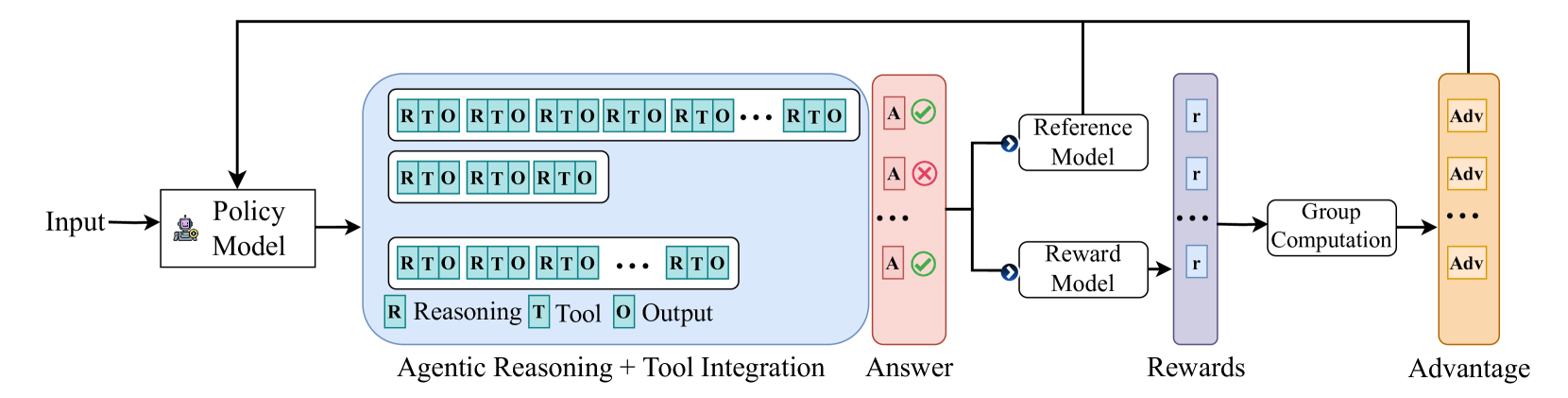
现有RL任务大多单轮、短期、无状态交互(简单搜索/代码等)。但复杂真实任务需要高级agent能力(如多工具调用、code、测试、长期规划等)。
online-rl 训练具有挑战
📕核心方法
SkyRL(基于VeRL+OpenHands构建):在真实环境中执行多轮工具使用的RL训练流程
通过agents层扩展了verl

Reward设计
系统设计

✍️实验配置
数据集📚:从SWE-Gym2.4k真实问题中过滤构建3个子集。(该数据非常难,gpt-4o仅4.55%-9.13%)
模型 🤖:
评估📊 :
bash_execute, finish, str_replace_editor🍑关键结果
三个尺寸模型:7B、8B、14B,四种实验方法:Zero-Shot, Zero-Shot(推理)、SFT、RL。具体如下表所示:
| Resolved Rate | Technique | |
|---|---|---|
| Qwen3-14B | 18% | Zero-Shot (Thinking) |
| SkyRL-Agent-14B-v0 (Best👍) | 21.6% | Outcome based Reinforcement Learning |
| Qwen3-8B | 3.6% | Zero-Shot (Non thinking) |
| SkyRL-Agent-8B-v0 | 9.4% | Outcome based Reinforcement Learning |
| Qwen2.5-Coder-Instruct | 1.8% | Zero-Shot |
| OpenHands-7B-Agent | 11.0% | Supervised Fine-tuning |
| SkyRL-Agent-7B-v0 | 14.6% | Outcome based Reinforcement Learning |
❓问题背景
📕核心方法
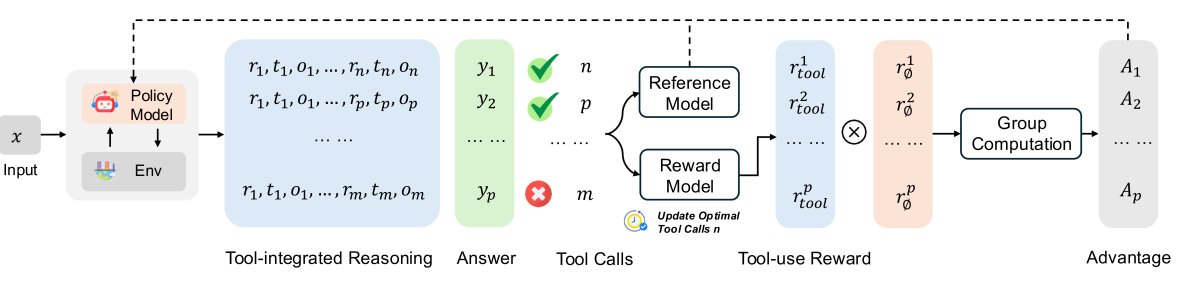
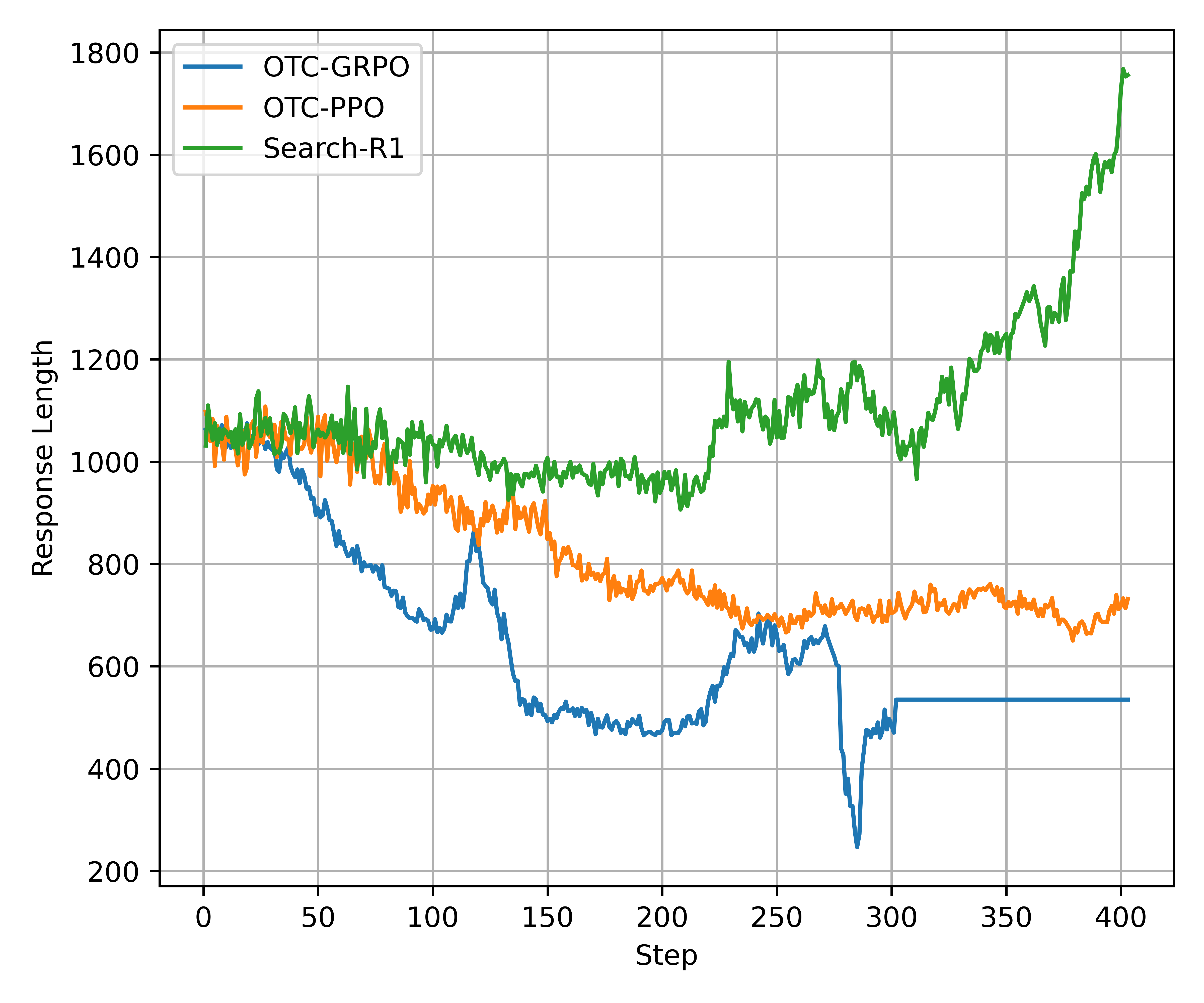
工具生产力奖励随工具调用次数增多而减少(c为不同交互次数)
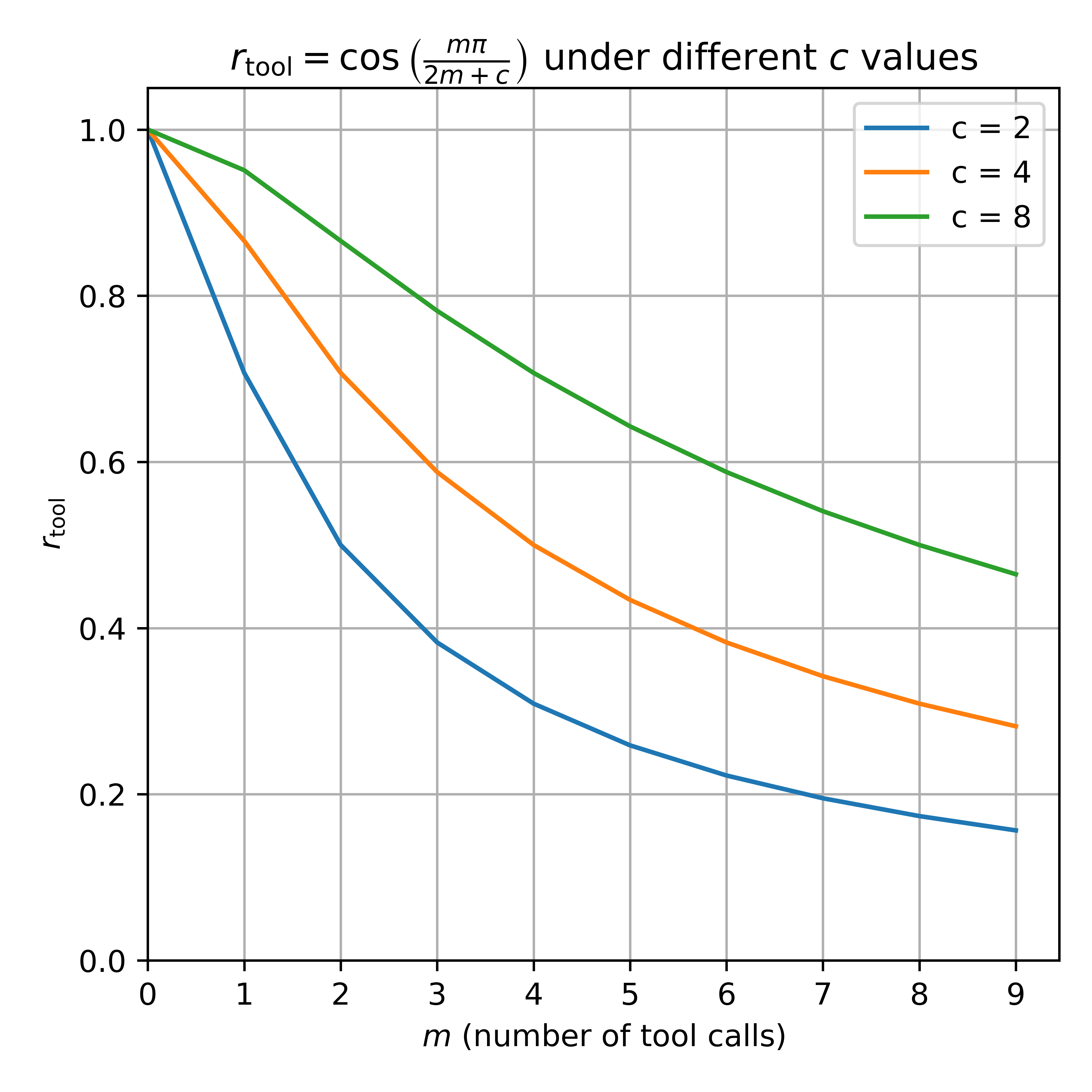
✍️实验配置
🍑关键结果
效果好、效率高 👍
泛化性好 🌟

训练更快更稳定 🚀
❓问题背景
📕核心方法
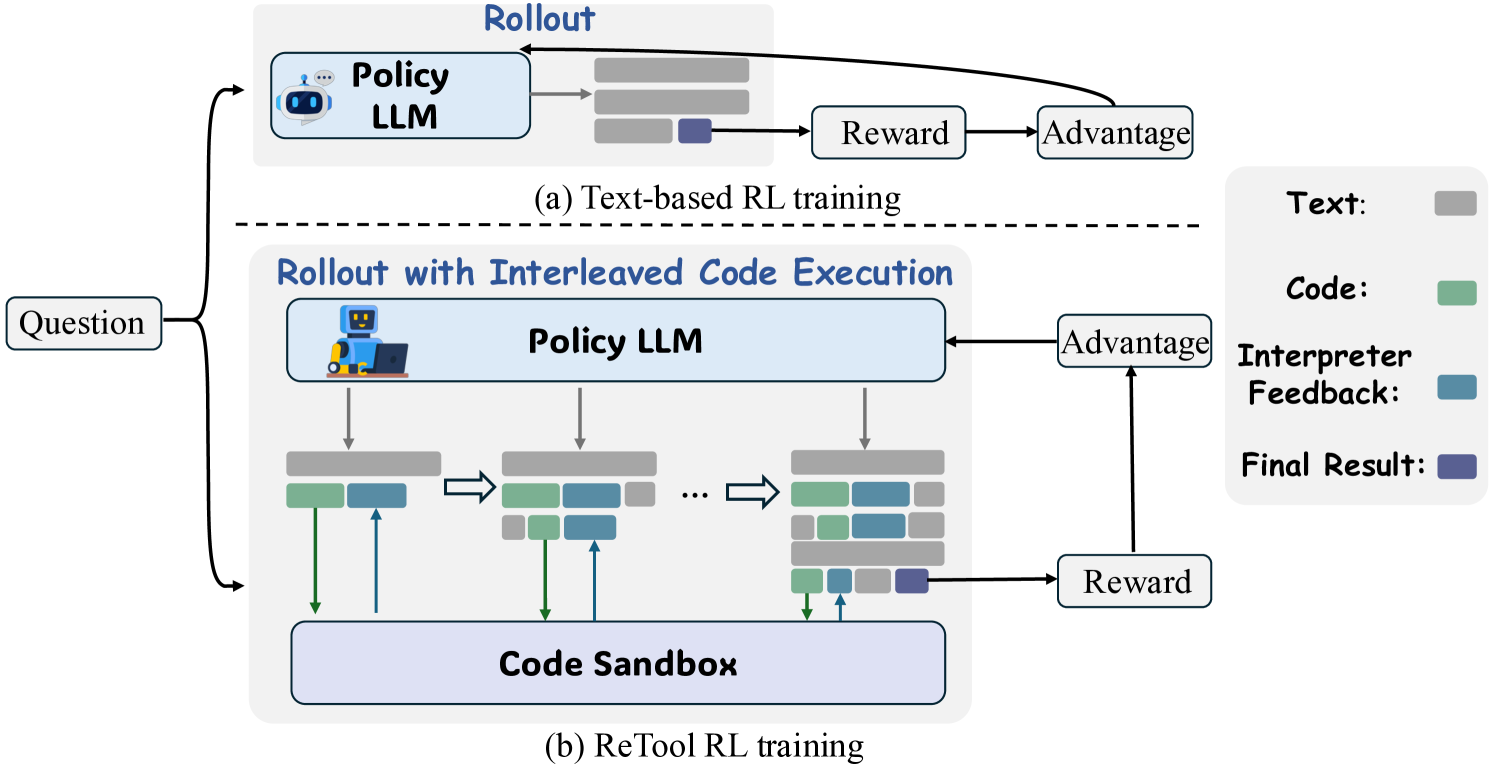
提出ReTool RL框架,模型自行决定何时调用工具、通过RL进行强化、代码执行和内部推理动态交替。
SFT 冷启动阶段 👨🎓
dual-verify: 结合人工专家和DeepSeek-R1来过滤,得到RL 强化阶段 🤖
✍️实验配置
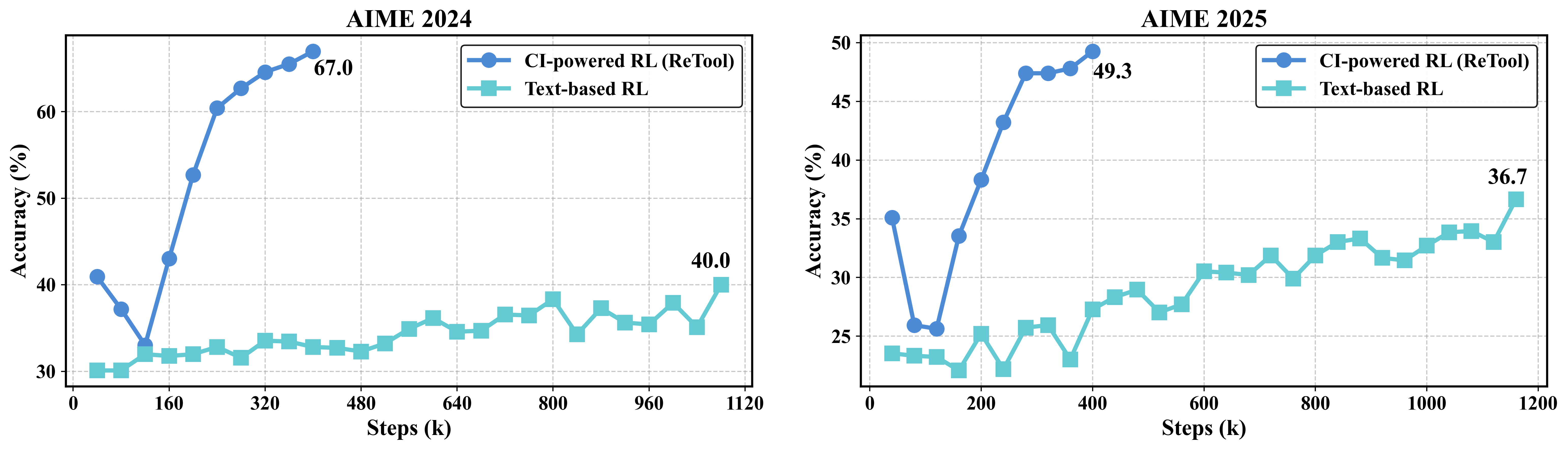
🍎关键结果
❓问题背景
📕核心方法
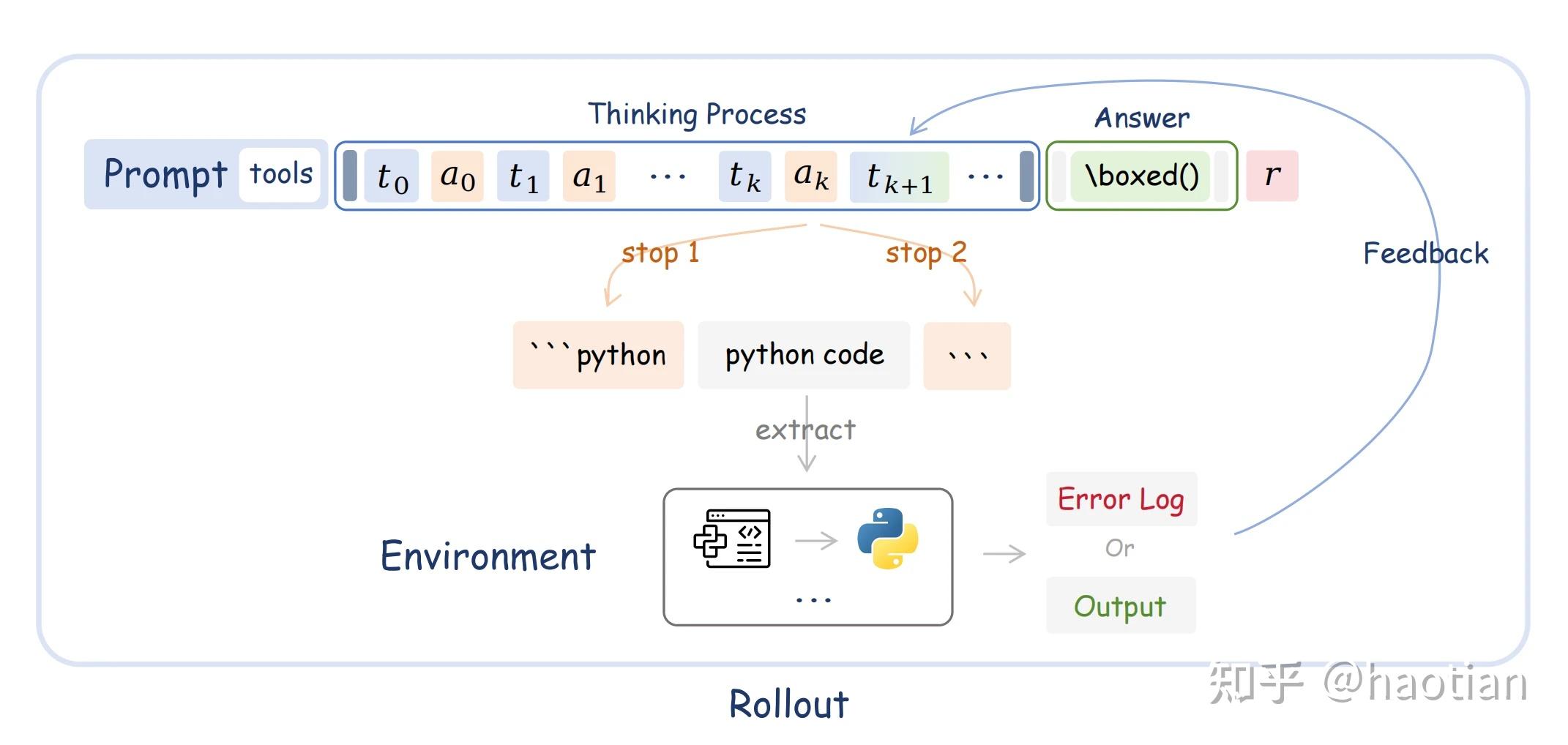
Tool-Intregrated Reasoning (TIR) 任务定义
给定n个工具:
第k步推理轨迹:推理->工具->结果,
模型策略
Reward定义:格式 0, 1;正确性 [-3, 3],整体[-3, 4]。
✍️实验配置
🍑关键结果
❓问题背景
📕核心方法
设计ToRL框架,通过RL训练模型自主利用工具,探索、发现最佳工具使用策略,比SFT好。
ToRL 设计
✍️实验配置
模型:Qwen2.5-Math 1.5B、7B,
算法:VERL框架,GRPO算法,
数据集:利用LIMR,抽取高质量样本,均衡难样本分布,从75k -> 筛选到28k,数据来源于NuminaMath/Math等竞赛题。
参数:bs=128,temperature=1, 忽略KL散度
🍑关键结果
ToRL-7B 在AIME24上达43.4%,比无工具RL模型提升14%,超越现有TIR(Qwen-2.5-Math-指令-TIR)17%。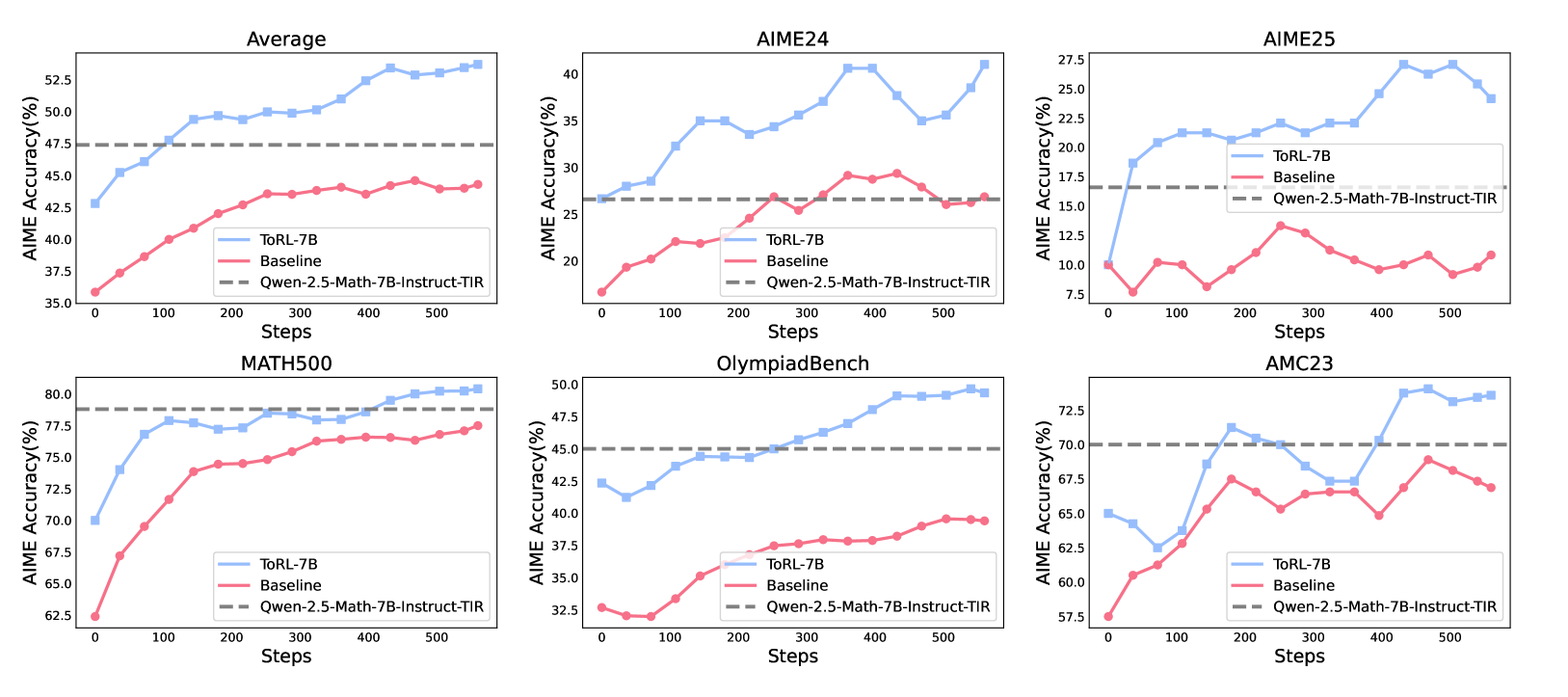
async-rollout提速1.6倍,比sync-rollout快4倍,能更好支持更多实验及更大尺寸的zero-tir实验。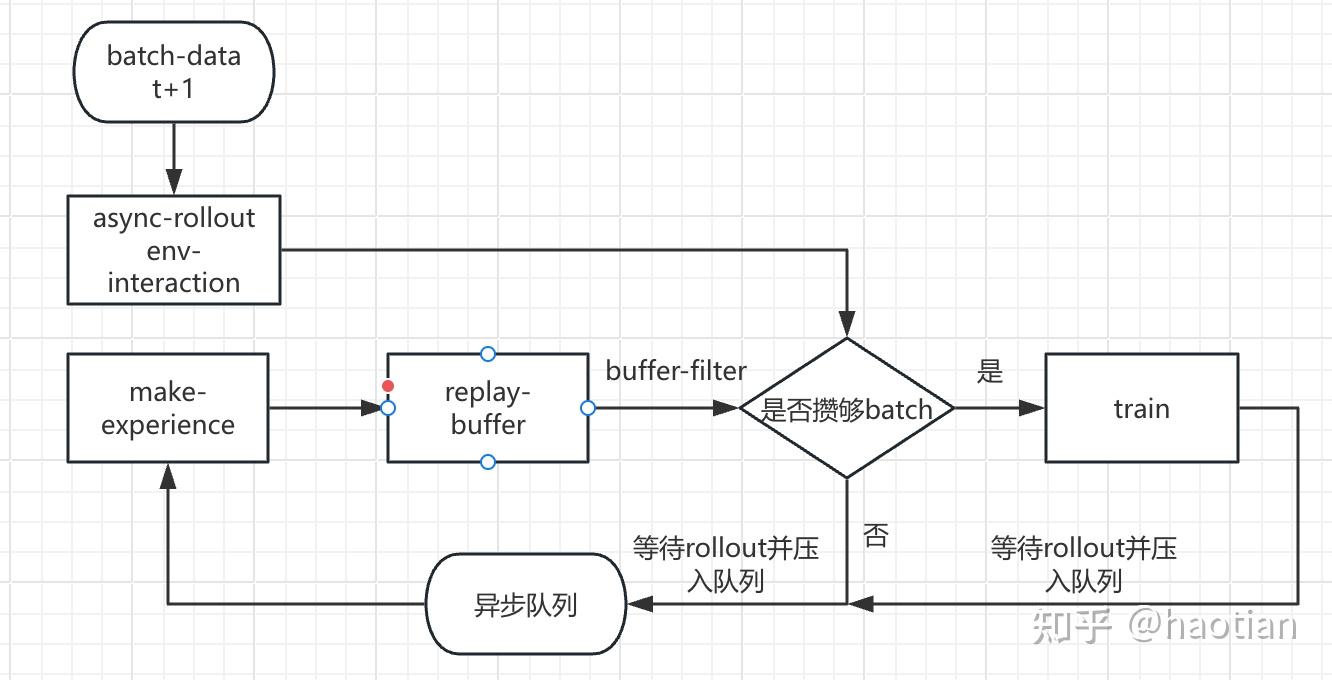
✍️实验配置
🍎 关键结果
7b-base-zero-tir
32b-base-tir(知乎博主还没跑完,后续跟进)
Aime24在step300,可以跑到53.33,而text-co则需要参数更新上千次才能达到类似效果。
Replay-buffer需要根据acc选择数据,训练到后期:
Agent能力已成标配,从以下2方面考虑:
Actor和环境
final reward或 step feedback两种scale
agent-rl框架(实现)
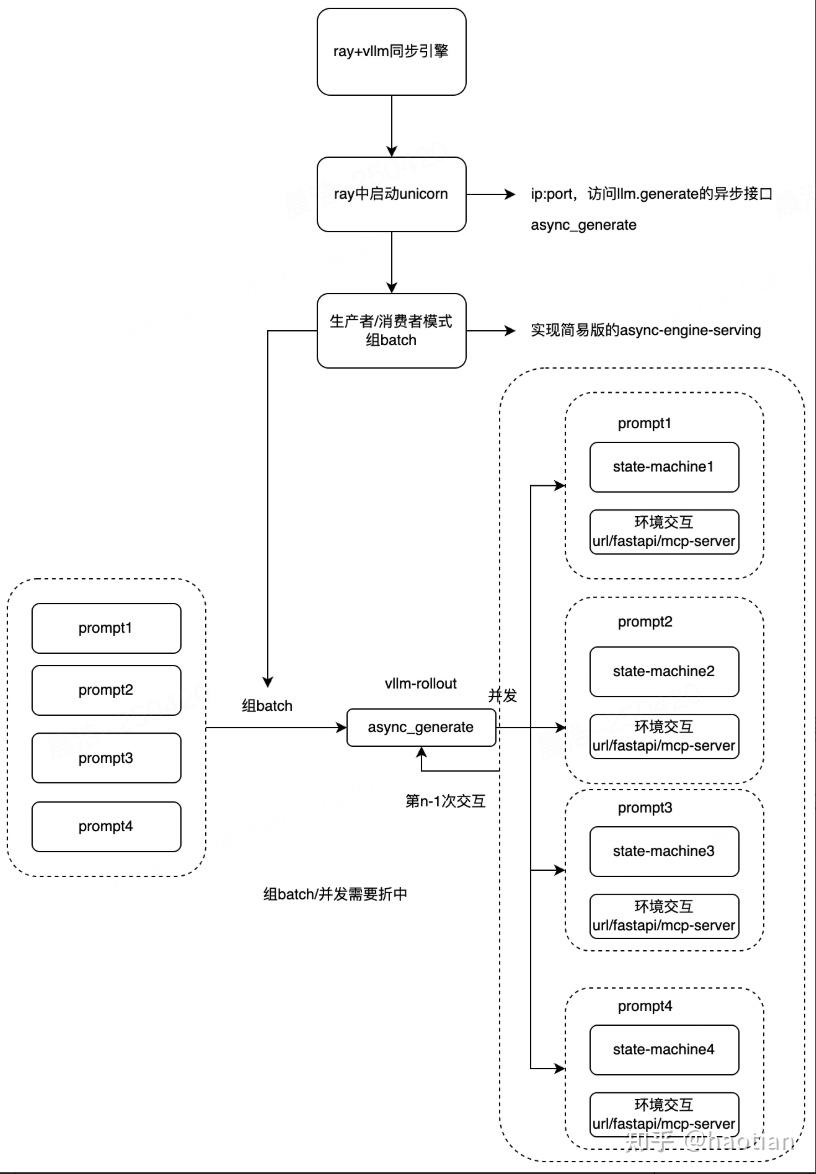
openrlhf/verl的rollout是同步引擎,直观就是同步改成异步好了,rollout变成server,做异步消息队列。
基于该实现,博主测试了math+tir场景下rollout+环境交互耗时:(tool=为python code)
同ZeroTIR-论文一样,在math场景引入code来解题,效果自然比不带工具的RL要好。
Tool-Integrated Reasoning(TIR),注意TIR不仅限于Code环境。
常见Agent-RL为搜索场景,比如search-r1, r1-searcher等,其使用向量检索作为tool,基于base跑zero-rl提升模型问答能力。
| 方法 | 特点。 |
|---|---|
| TIR-SFT | 强制模型每道题都是有code解决。这类工作比较多。 |
| TIR-RL | 不强制,通过RL自行决定是否使用python-code解题。 |
📕核心方法
同论文Agent RL Scaling Law一致,引入code环境,生成python code来解题,把结果(环境反馈)拼接回去。
:
✍️实验设置
you can use python-code to solve your problem。Code-reward:response中出现code的比例Code-in-correct:response中出现code且答案正确的比例🍑实验结果
dreamer 或 world model。