Agent-Search-RL 笔记
📅 发表于 2025/05/30
🔄 更新于 2025/05/30
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
Agent-Search-RL
#R1-Searcher
#Search-R1
#ReSearch
#DeepResearcher
#WebSearch
❓问题背景
📕核心方法
WebDancer四阶段框架

✍️实验设置
🍑关键结果
⛳未来方向
❓问题背景
📕核心方法
MaskSearch框架:RAMP预训练任务 + 完善的训练策略。
[mask]标签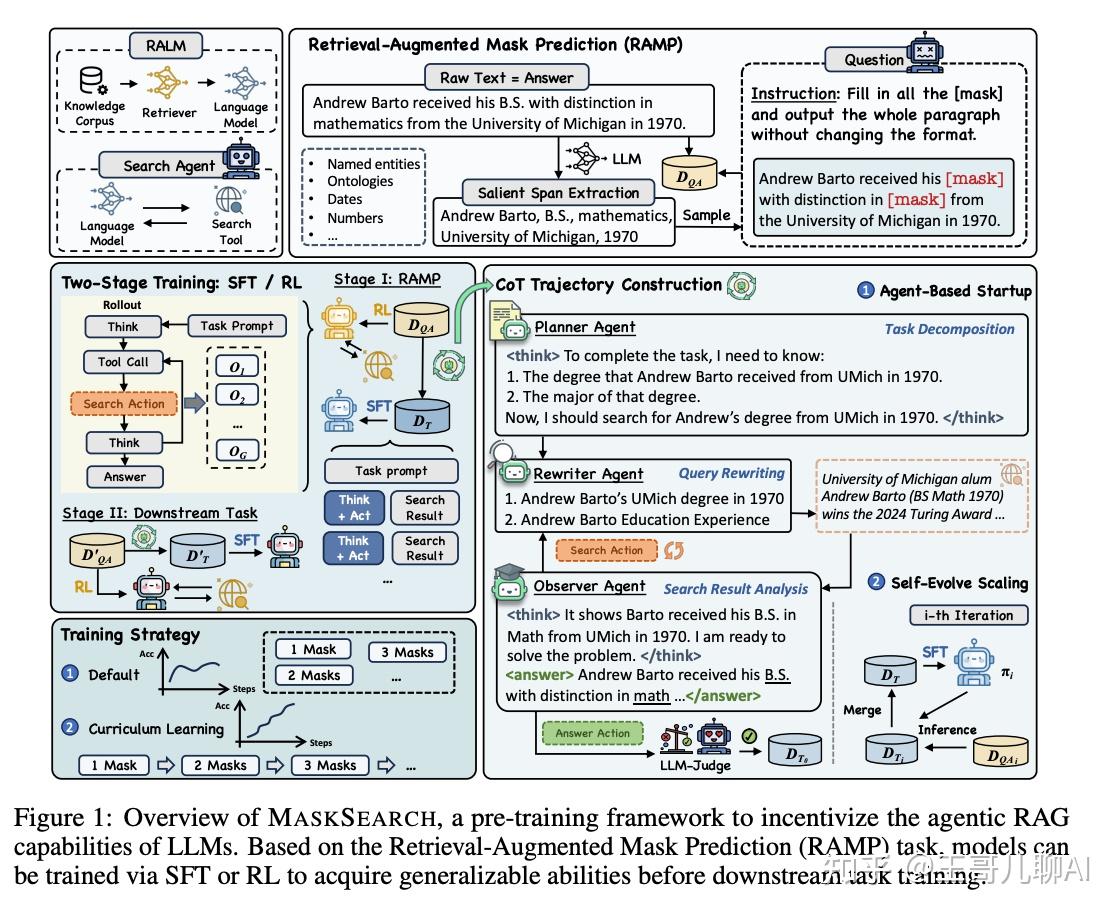
✍️实验设置
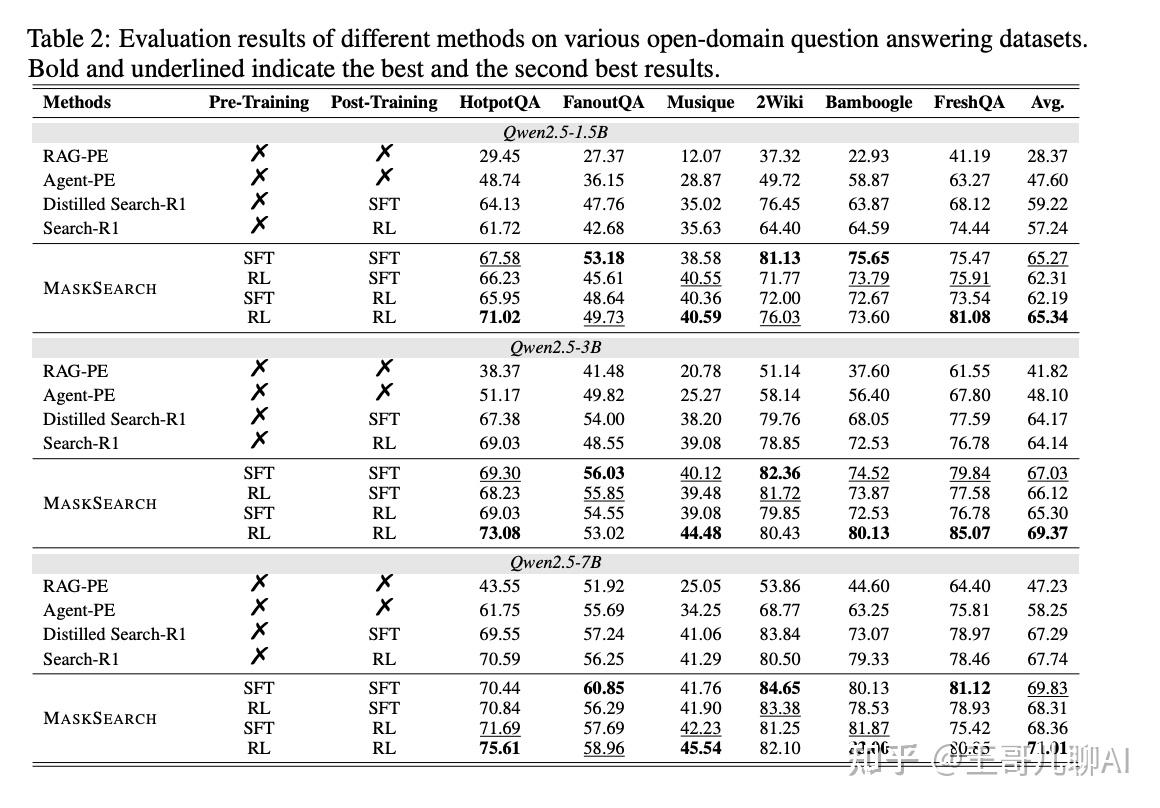
🍑关键结果
⛳未来方向
❓问题背景
📕核心方法
提出ZeroSearch方法
qwen-14b):LLM模拟搜索引擎qwen-3b/7b):Curriculum Rollout,由易到难,逐步学习推理
✍️实验设置
🍑关键结果
⛳未来方向
❓问题背景
封闭式问答 vs 开放式问答

📕核心方法
O2-Searcher由多个组件组成,实现有效知识获取和答案生成。
<think>, <search><query>, <answer>

✍️实验设置
🍑关键结果
⛳未来方向
❓问题背景
📕核心方法
WebThinker框架

✍️实验设置
🍑关键结果

⛳未来方向
R1-Searcher团队的工作❓问题背景
📕核心方法

✍️实验设置
🍑关键结果
❓问题背景
LLM+搜索很有潜力,但当前方法(Prompt/RAG)有限,创建强大可靠的Agent仍具有挑战。
📕核心方法
DeepResearcher是一个Agent框架,主要应对真实搜索的复杂性。
整体流程
<think>,判断是否需要搜索<web_search_tool>,得到搜索结果 标题、url、摘要,前k个。web browser agent,为每个query维护1个短期记忆库,根据query、短期记忆、搜索结果,来行动: <think>,判断信息是否足够❓ <answer>奖励设置
主要是f1,

✍️实验设置
🍑关键结果

实验细节
prompt示例:
<|im_start|>system
## Background information
* Today is 2025-06-10
* You are Deep AI Research Assistant
The question I give you is a complex question that requires a *deep research* to answer.
I will provide you with two tools to help you answer the question:
* A web search tool to help you perform google search.
* A webpage browsing tool to help you get new page content.
You don't have to answer the question now, but you should first think about the research plan or what to search next.
Your output format should be one of the following two formats:
<think>
YOUR THINKING PROCESS
</think>
<answer>
YOUR ANSWER AFTER GETTING ENOUGH INFORMATION
</answer>
or
<think>
YOUR THINKING PROCESS
</think>
<tool_call>
YOUR TOOL CALL WITH CORRECT FORMAT
</tool_call>
You should always follow the above two formats strictly.
Only output the final answer (in words, numbers or phrase) inside the <answer></answer> tag, without any explanations or extra information. If this is a yes-or-no question, you should only answer yes or no.
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"type": "function", "function": {"name": "web_search", "description": "Search the web for relevant information from google. You should use this tool if the historical page content is not enough to answer the question. Or last search result is not relevant to the question.", "parameters": {"type": "object", "properties": {"query": {"type": "array", "items": {"type": "string", "description": "The query to search, which helps answer the question"}, "description": "The queries to search"}}, "required": ["query"], "minItems": 1, "uniqueItems": true}}}
{"type": "function", "function": {"name": "browse_webpage", "description": "Browse the webpage and return the content that not appeared in the conversation history. You should use this tool if the last action is search and the search result maybe relevant to the question.", "parameters": {"type": "object", "properties": {"url_list": {"type": "array", "items": {"type": "string", "description": "The chosen url from the search result, do not use url that not appeared in the search result"}, "description": "The chosen urls from the search result."}}, "required": ["url_list"]}}}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call><|im_end|>
<|im_start|>user
Where was the director of film The Feature born?<|im_end|>
<|im_start|>assistant
<think>❓问题背景
📕核心方法
提出ReSearch框架
<think>、<search>、<result>
✍️实验设置
🍑关键结果

❓问题背景
📕核心方法
提出Search-R1,思路和R1-Searcher一致,不过为1阶段RL
<search>、<information>、<answer>
✍️实验配置
🍑关键结果
❓问题背景
📕核心方法
R1-Searcher++
<in>标记<ex>标记
✍️实验设置
🍑关键结果
⛳未来方向
❓问题背景
时效性,多知识点复杂查询等。Prompt工程难以泛化、依赖大量人工;SFT难以泛化、是记住而非学会搜索,Test-time Scaling/MCTS开销太大。📕核心方法
提出R1-Searcher框架,两阶段RL方法,自主调用搜索工具,无需过程奖励或蒸馏,性能优于RAG。是
Stage-1:学会使用外部检索
检索奖励:n为工具使用次数,激发模型去搜索。
格式奖励:<think></..>, <answer></..>, <begin_of_query></..>
Stage-2:根据检索结果准确回答
格式奖励:
答案奖励: 利用F1_score来作为答案奖励, PN表示预测答案字数,RN表示参考答案字数,IN表示交集字数。
训练期间检索到的文档会被mask,防止外部知识影响loss计算。
✍️实验配置
ACC_R:关键词精准匹配, ACC_L:GPT-4o-mini作为Judge。🍑关键结果
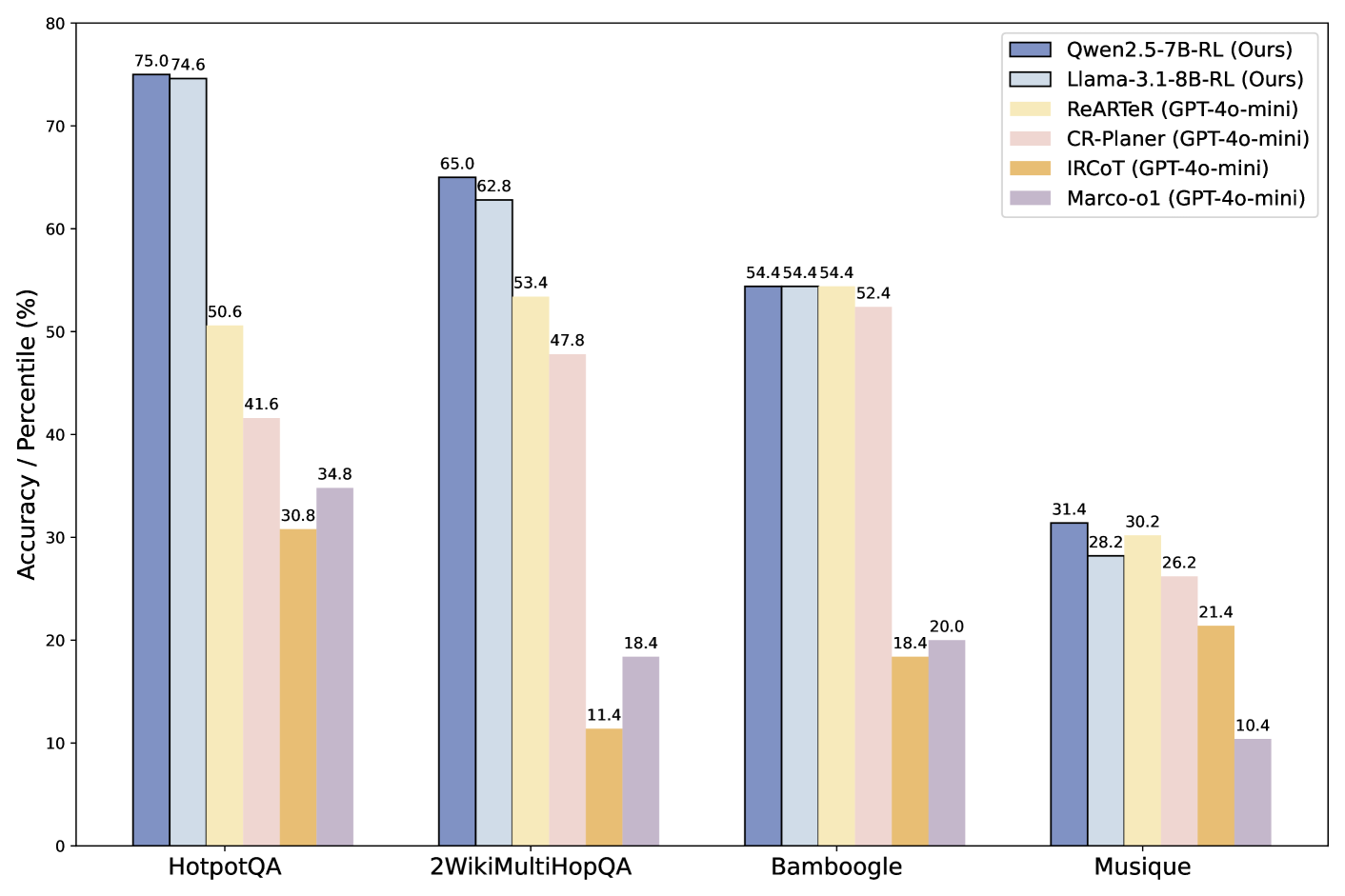
👿局限性和不足