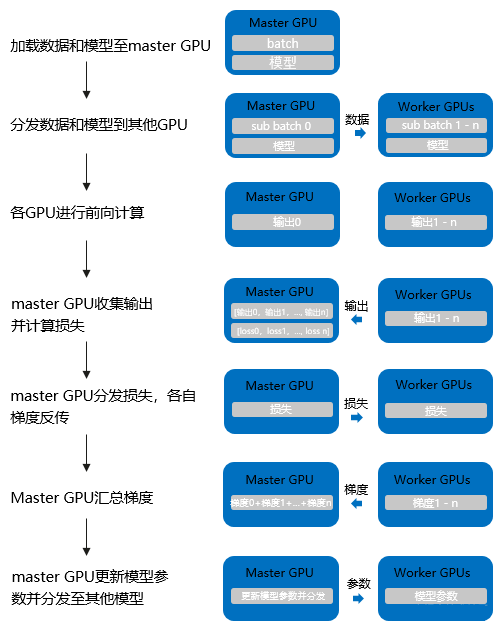
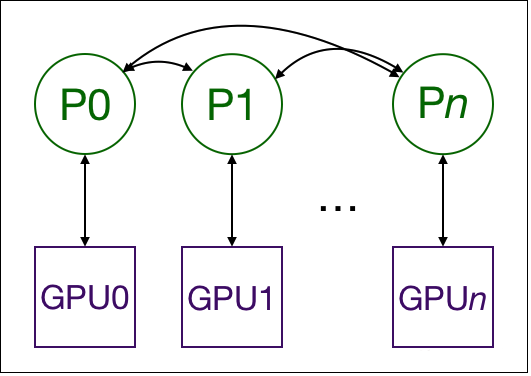
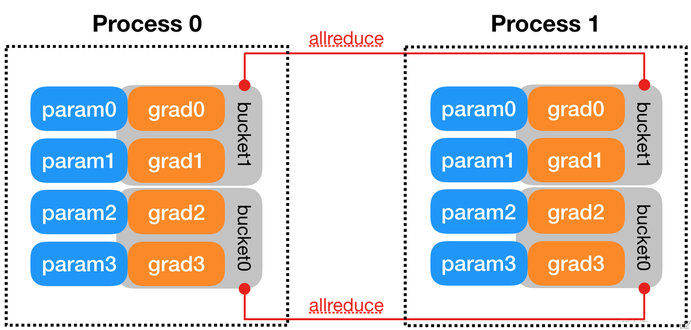
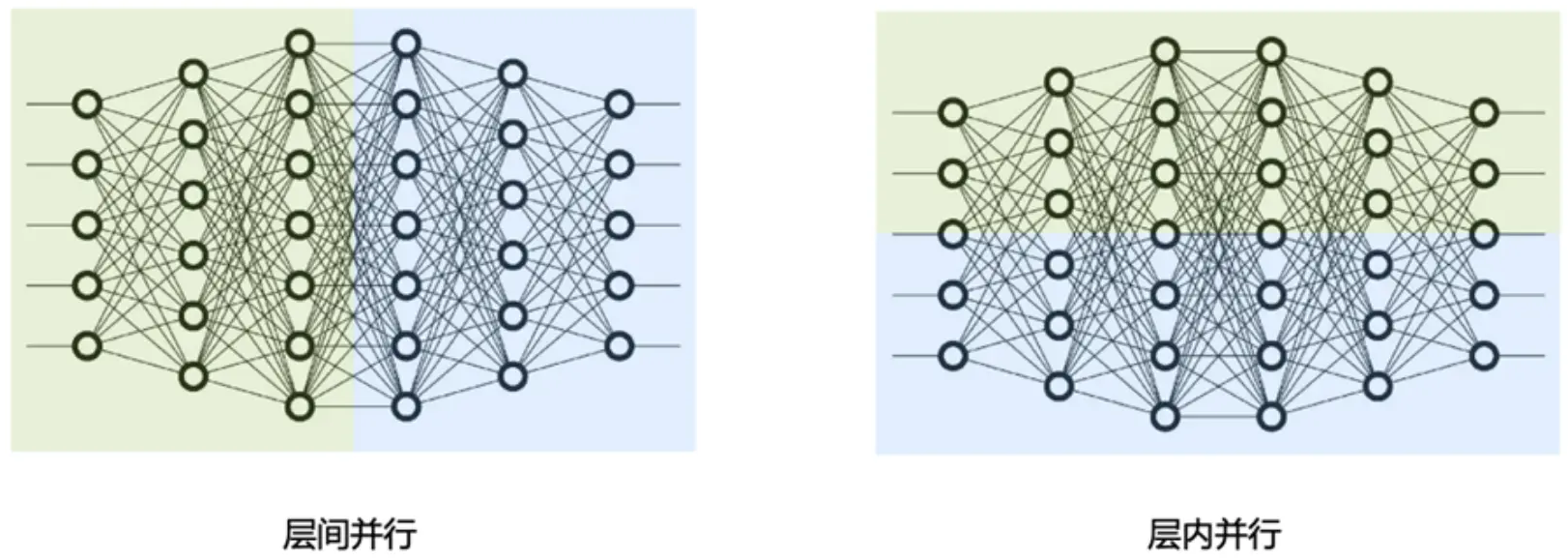
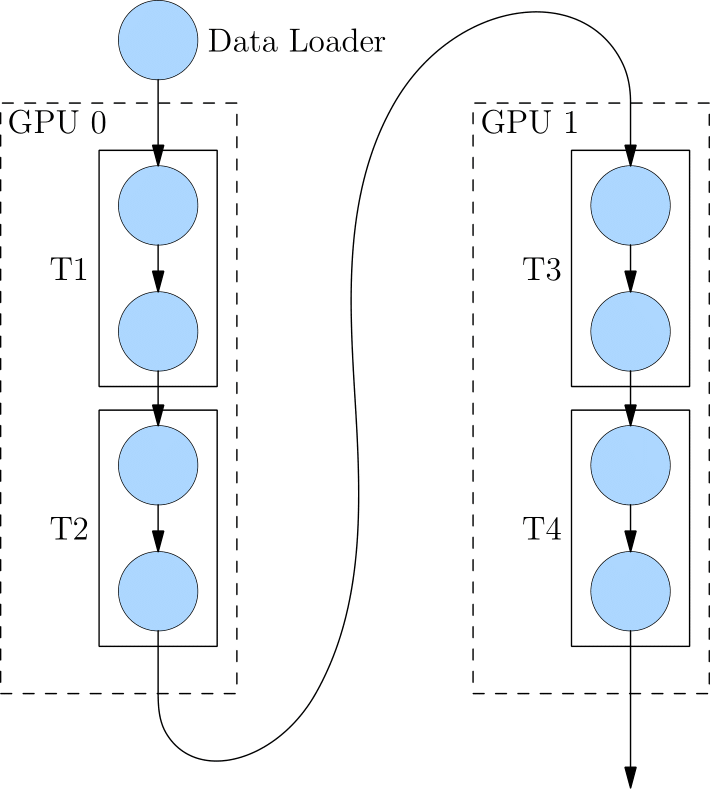
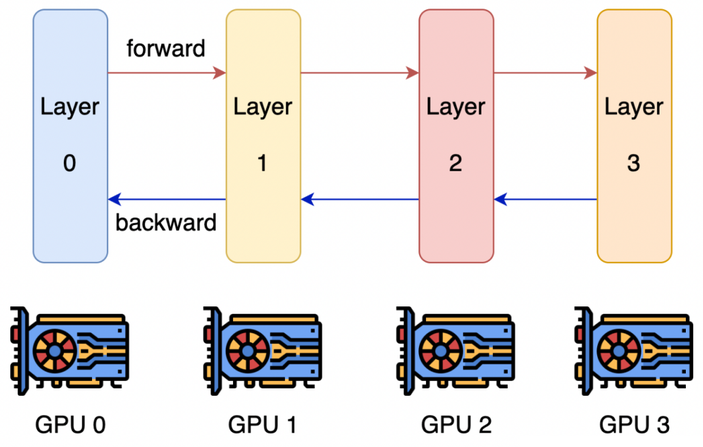
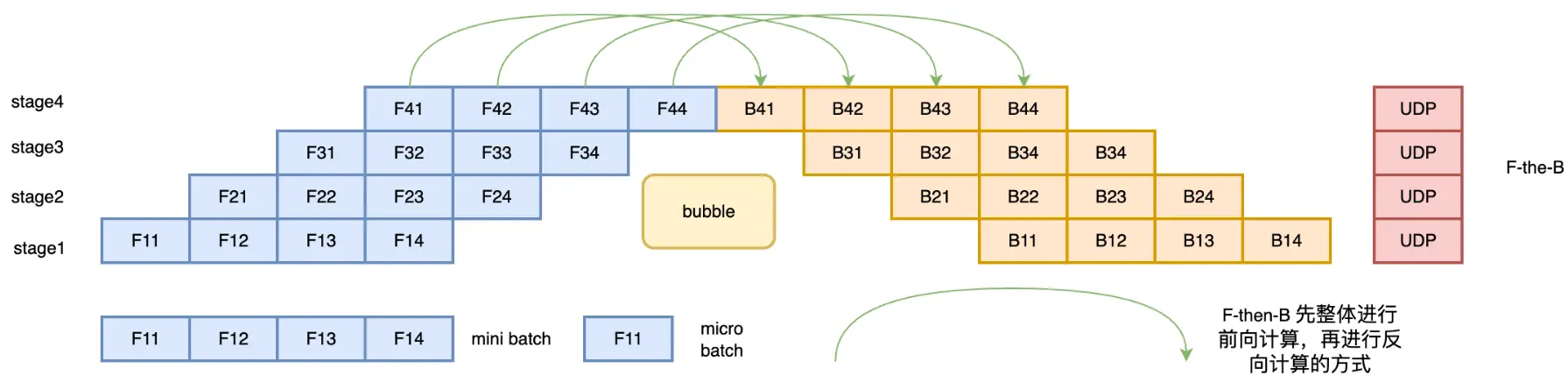
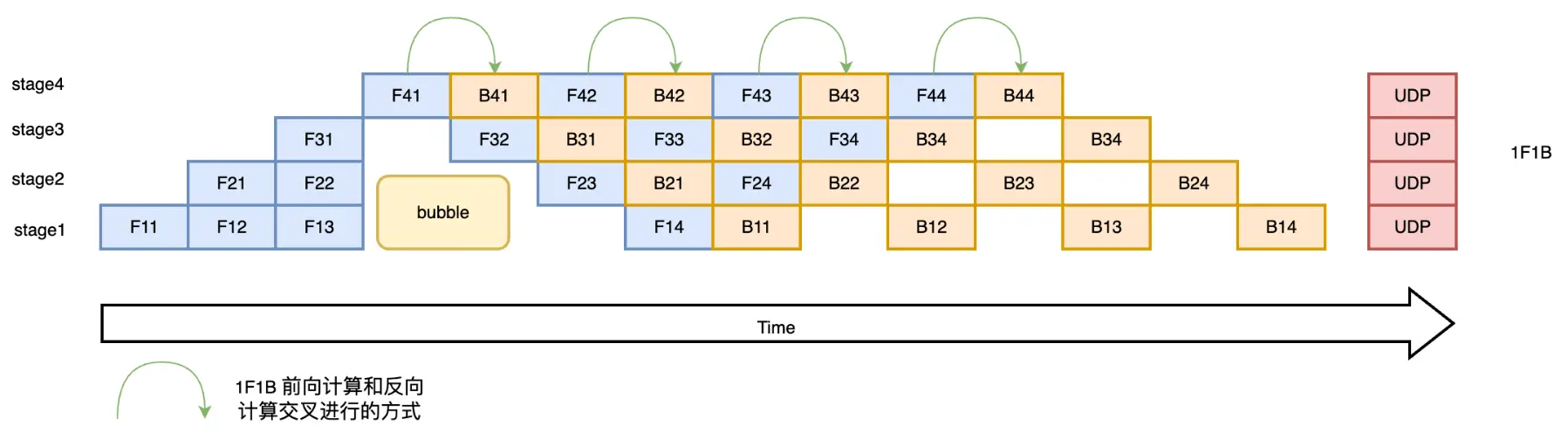
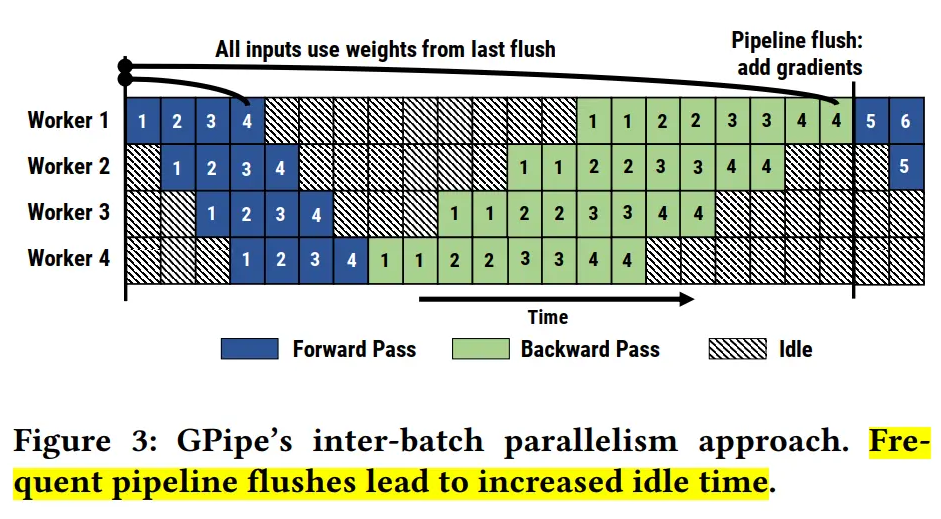
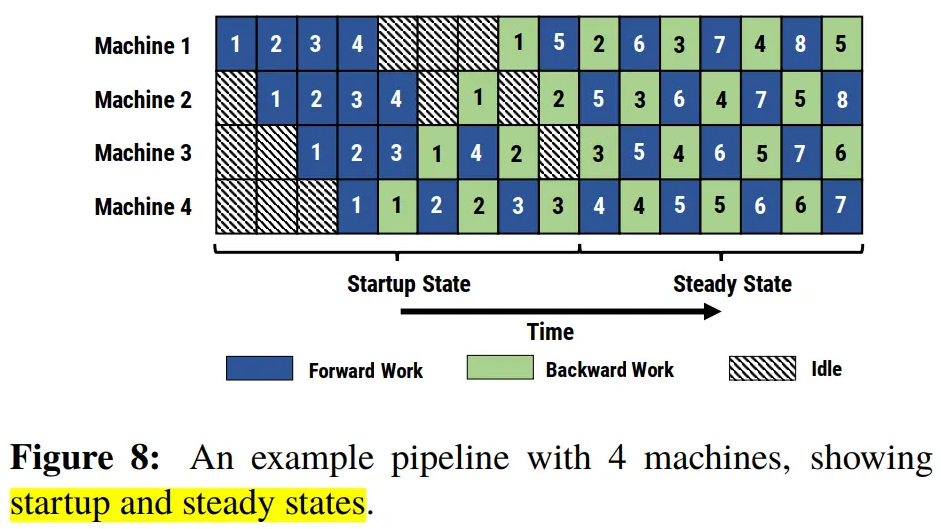
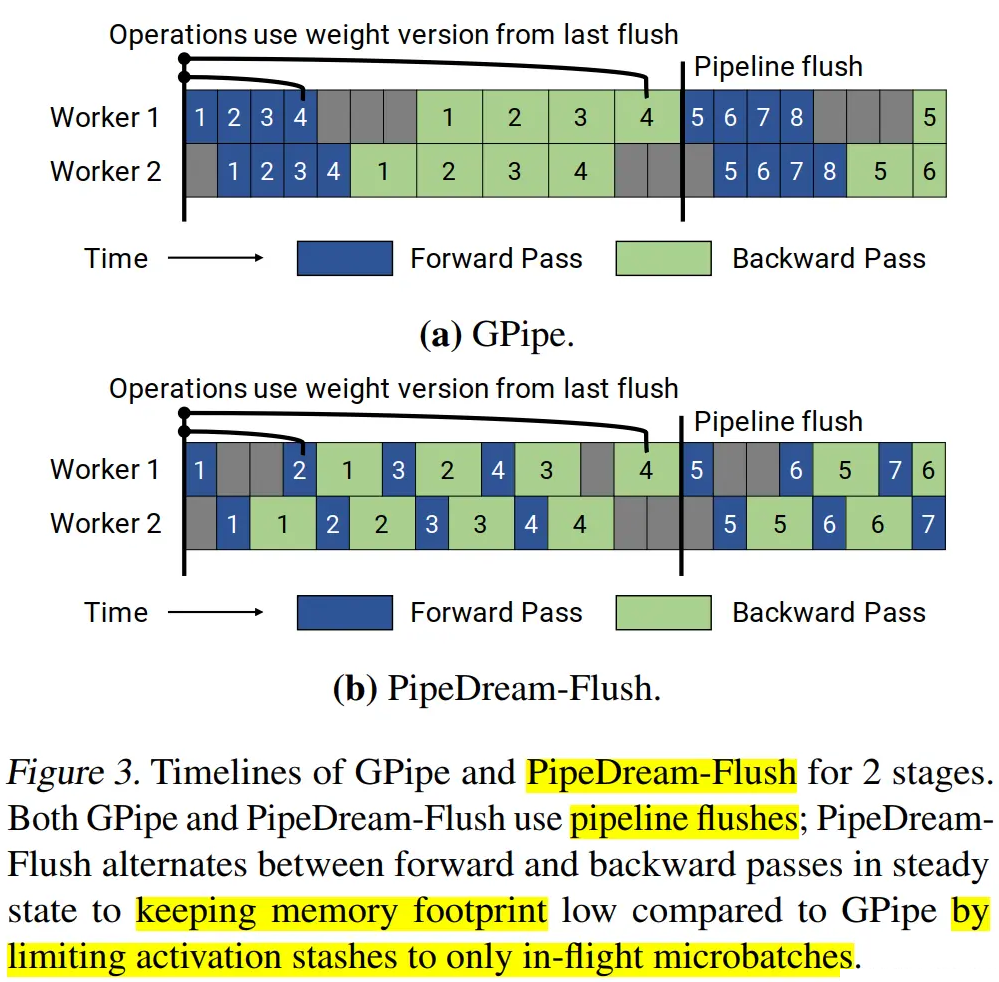
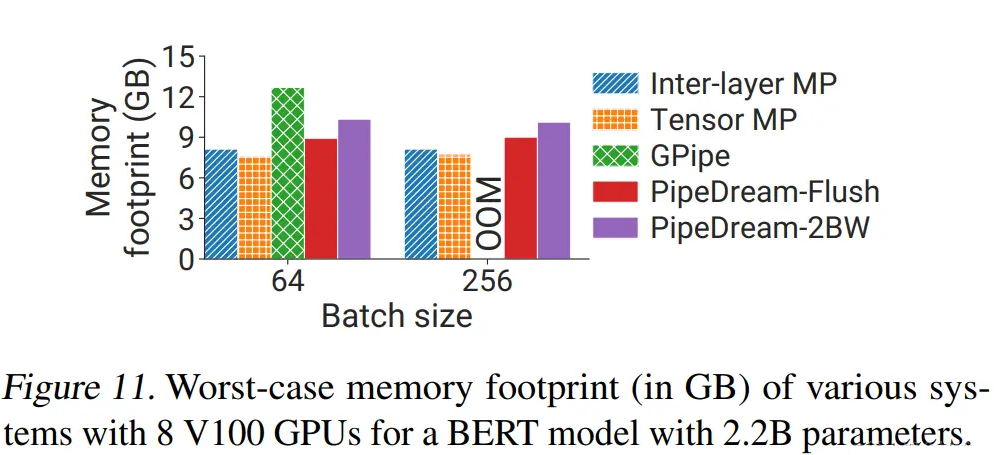
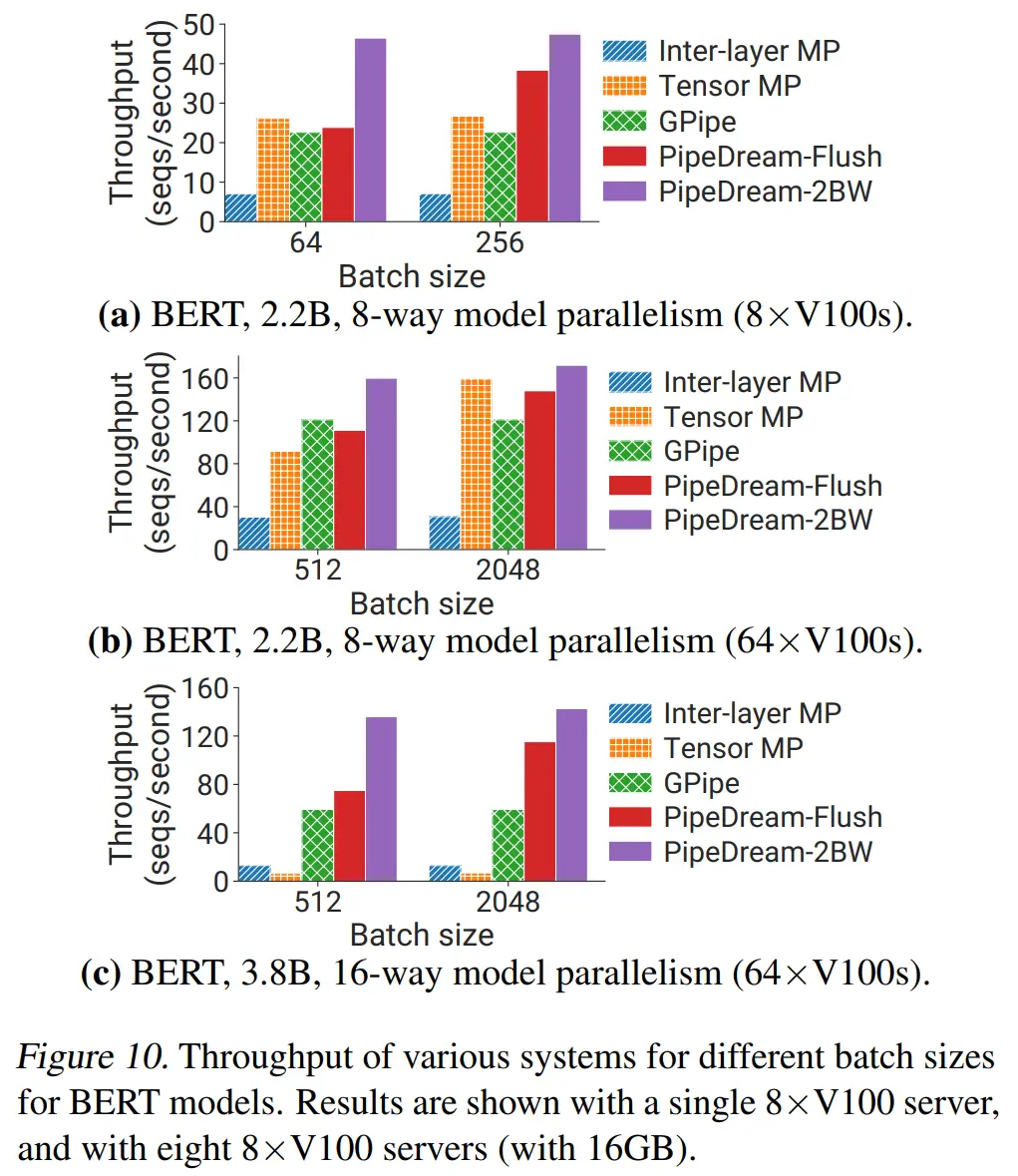
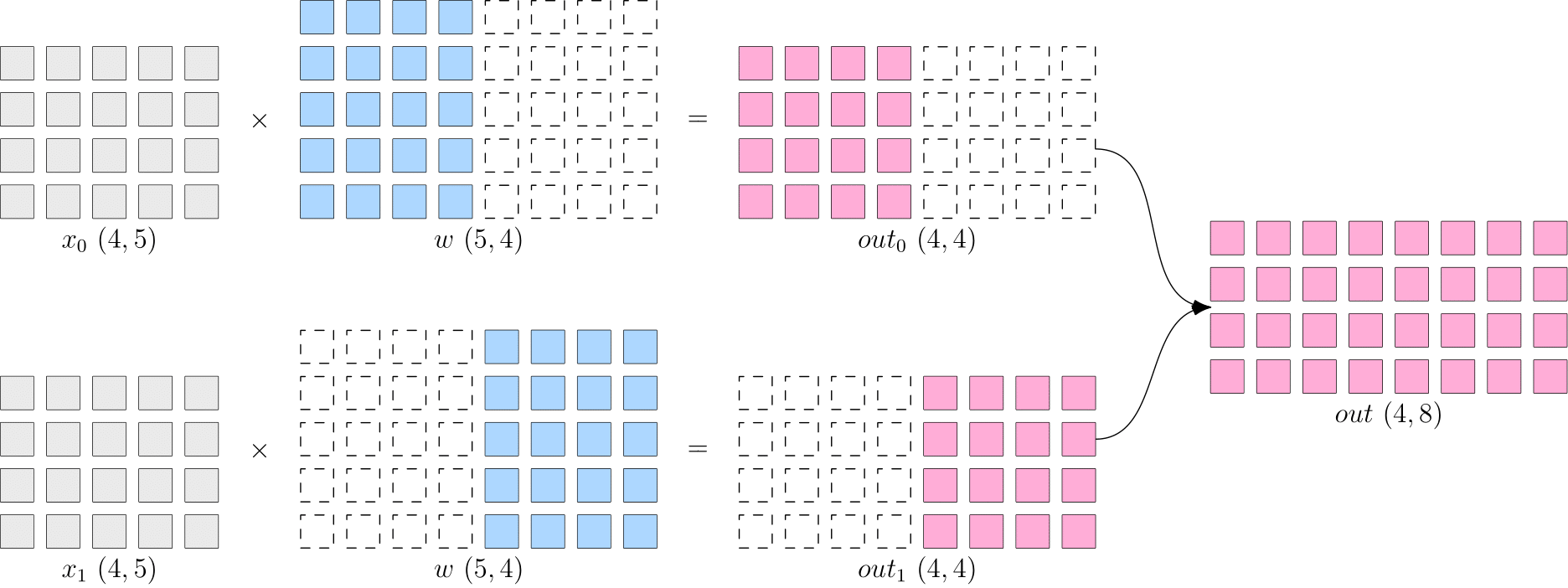
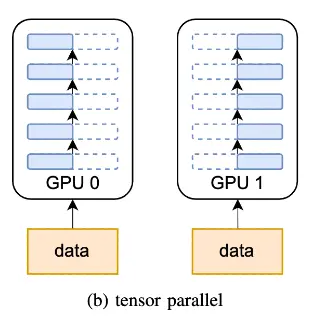
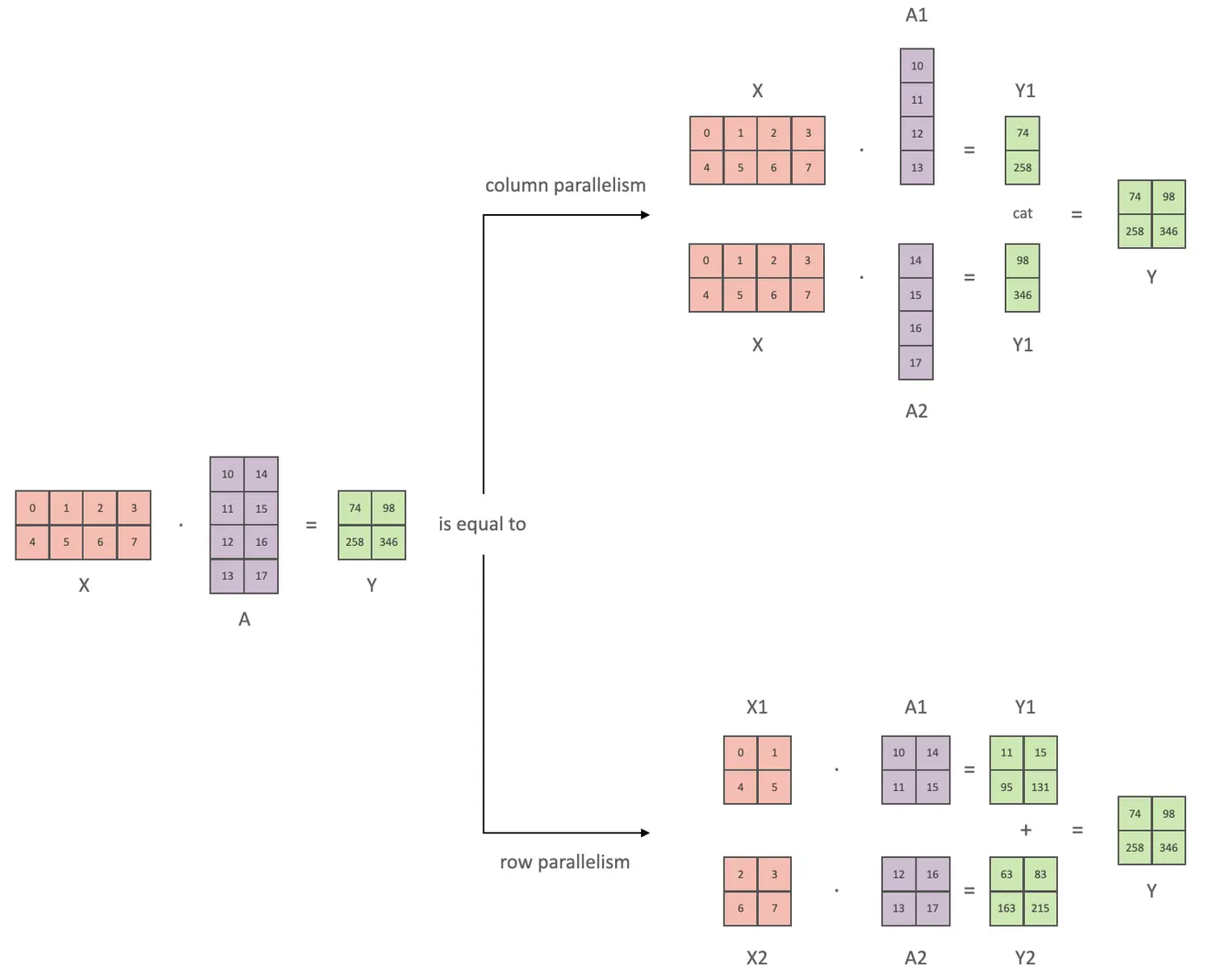
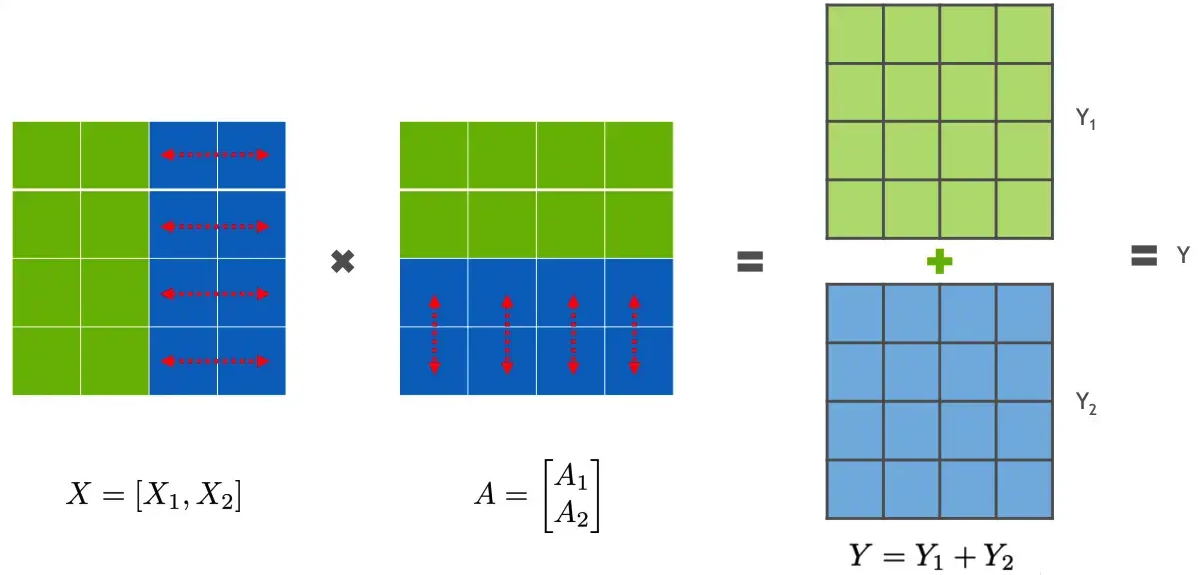
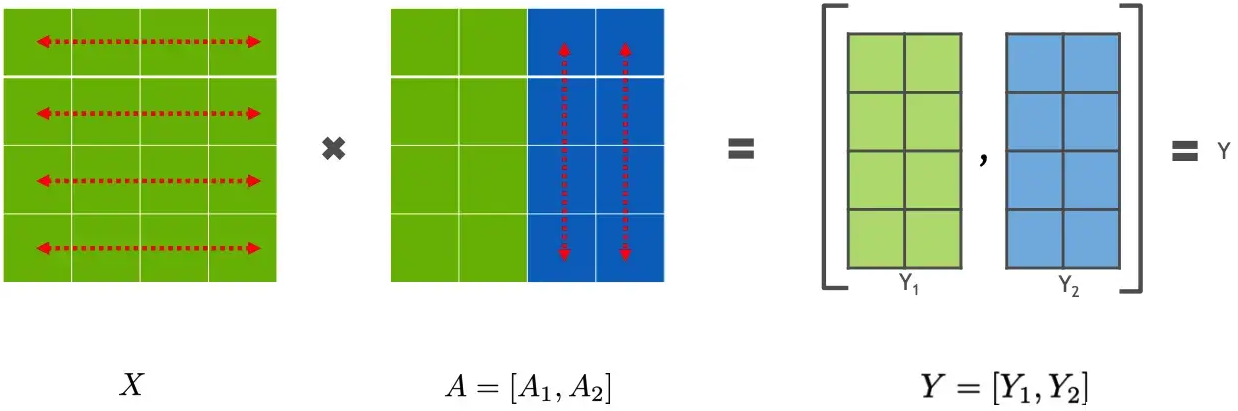
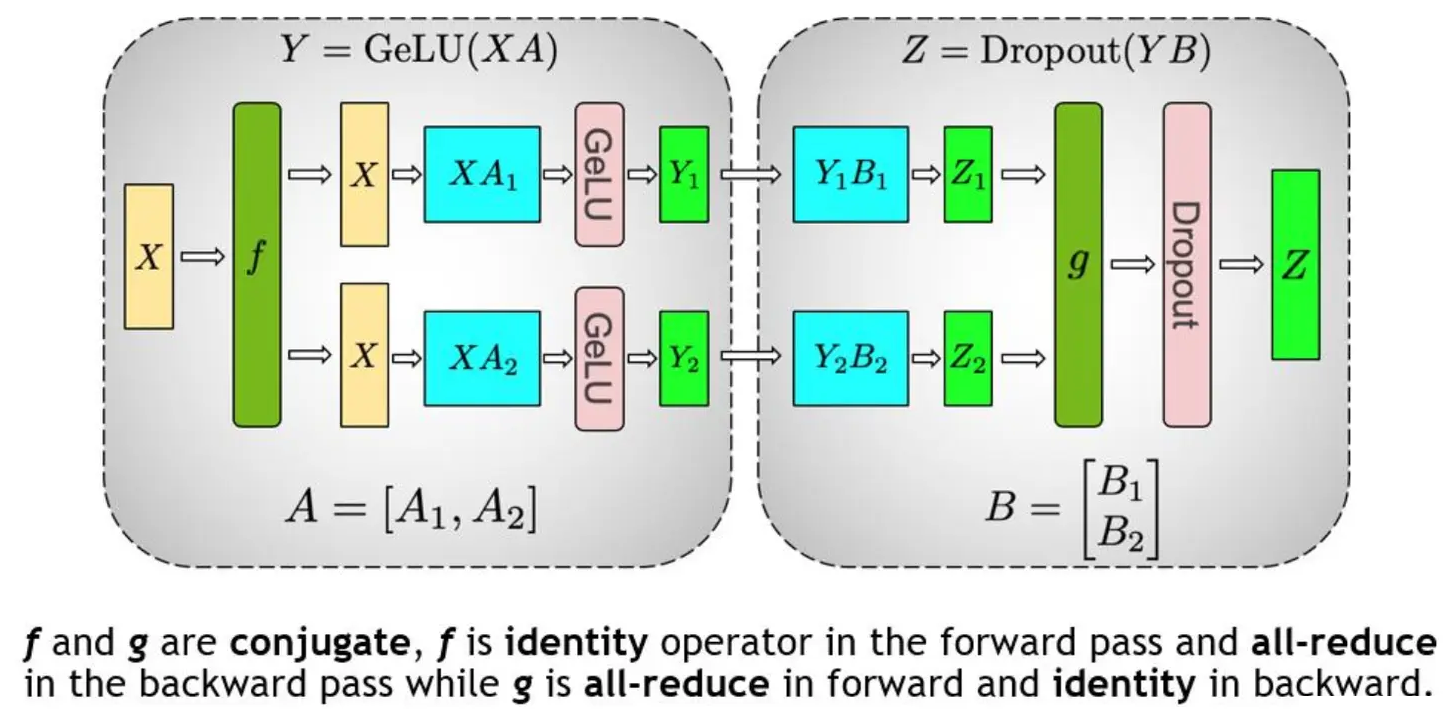
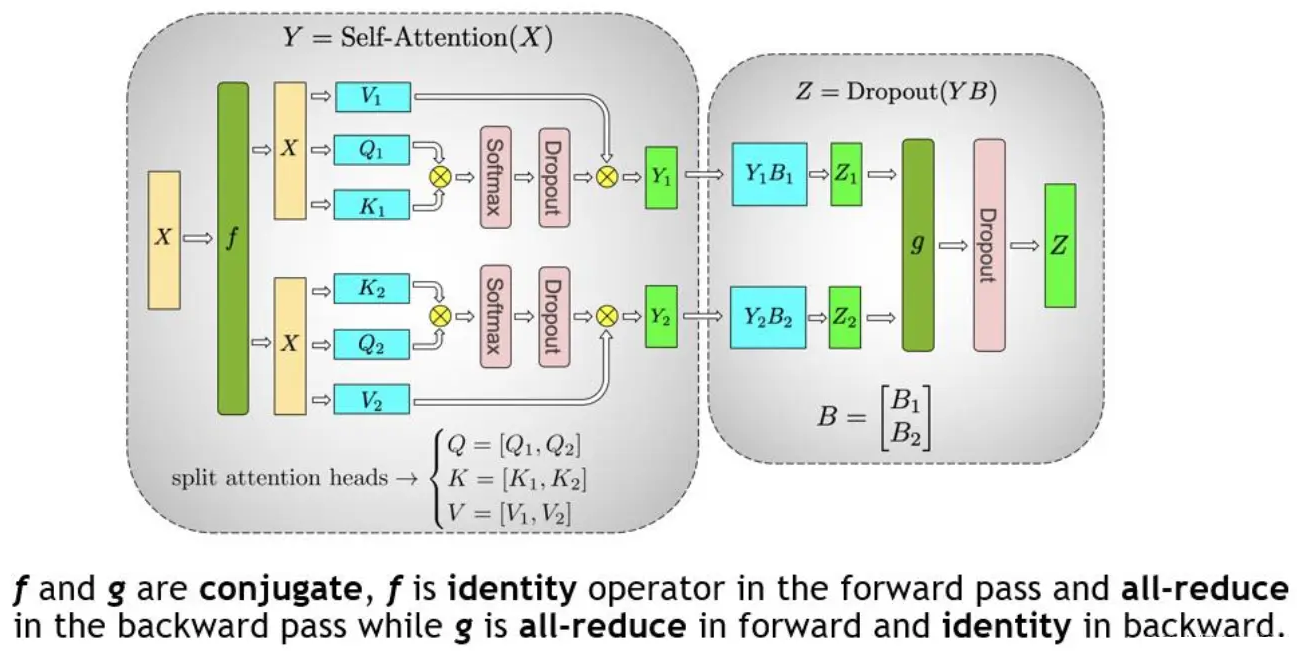
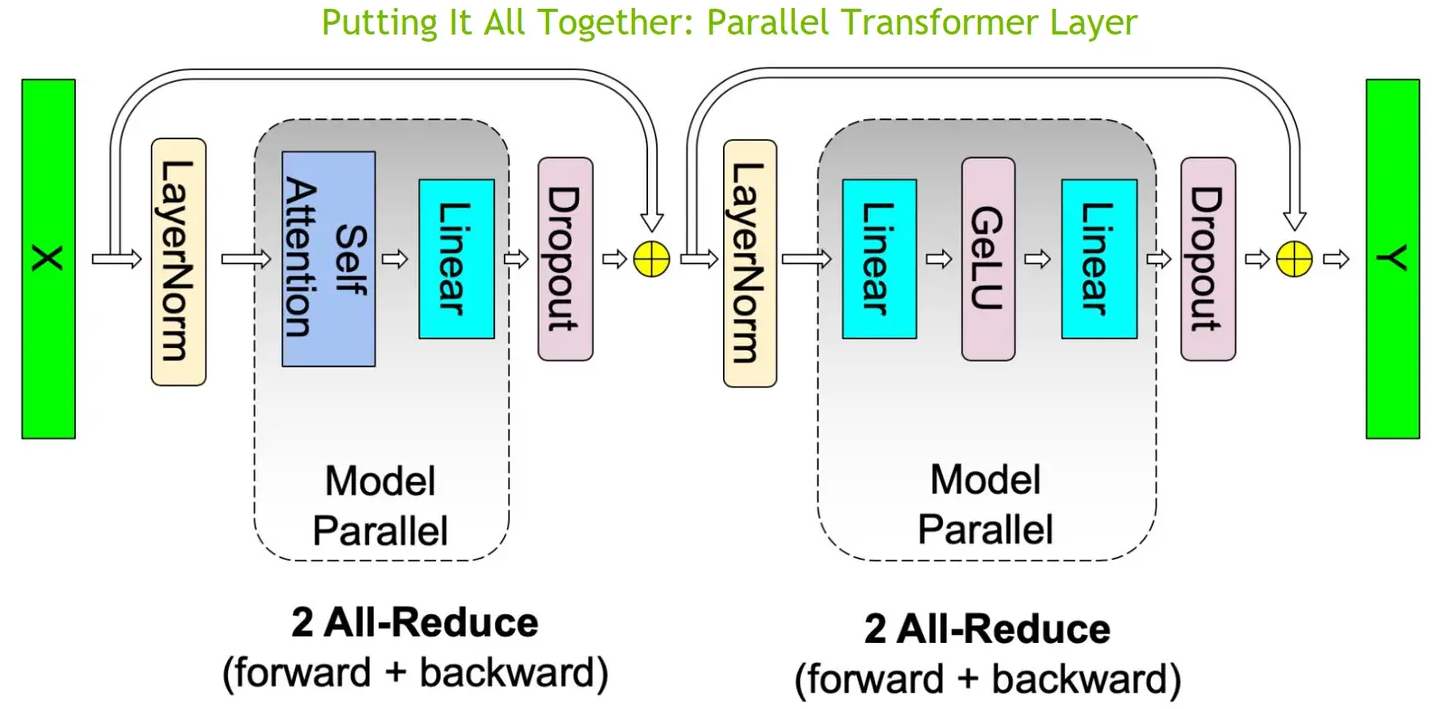
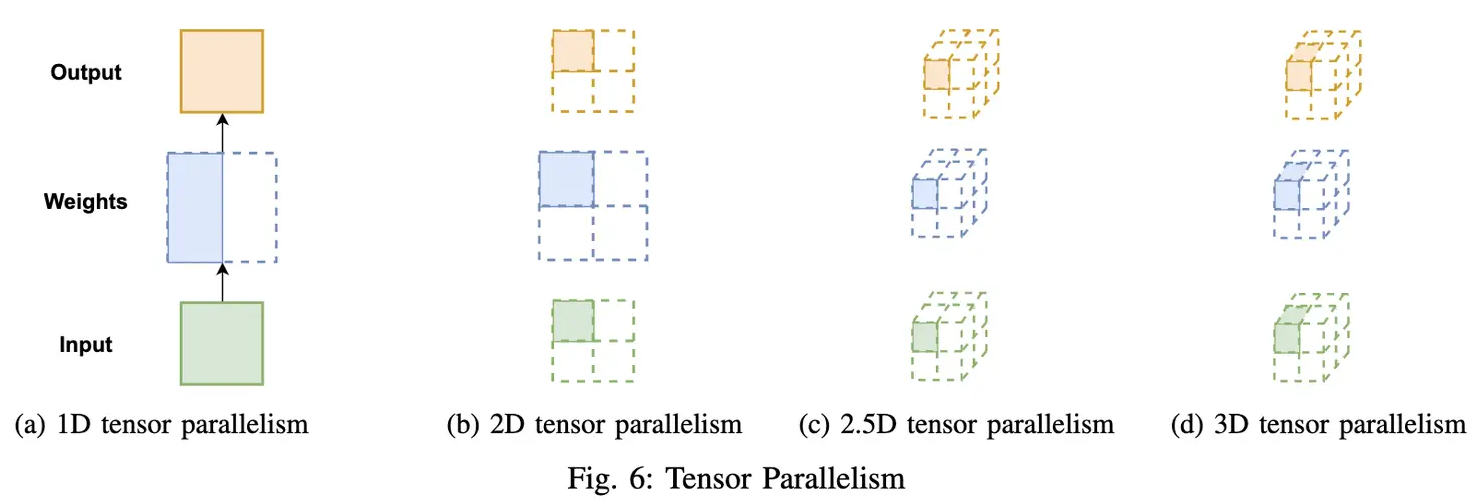
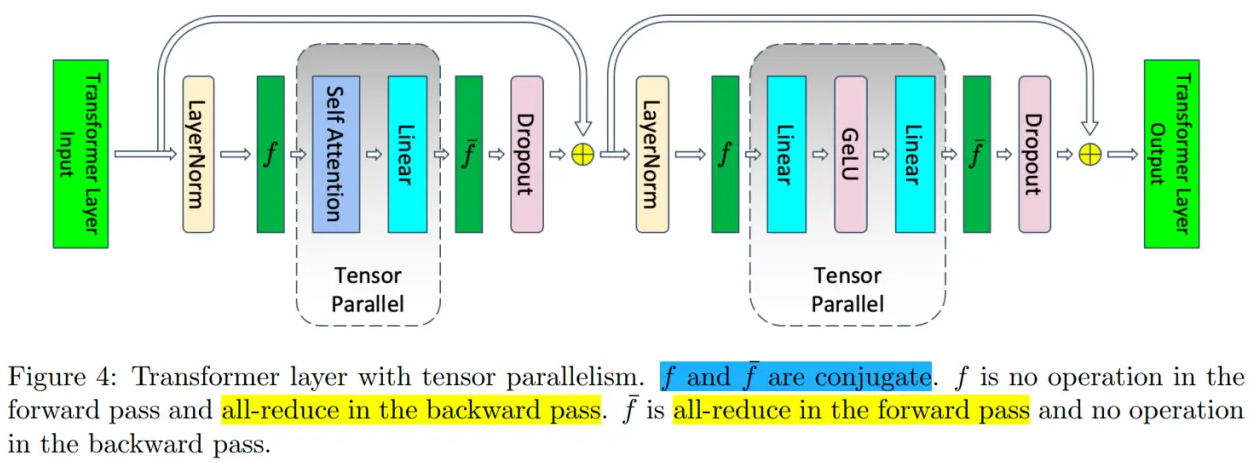
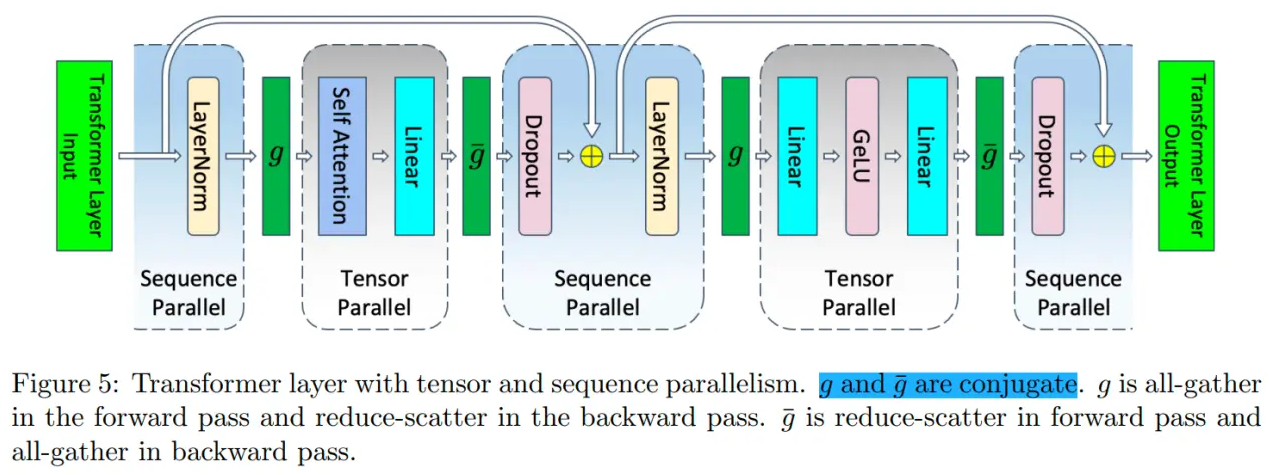
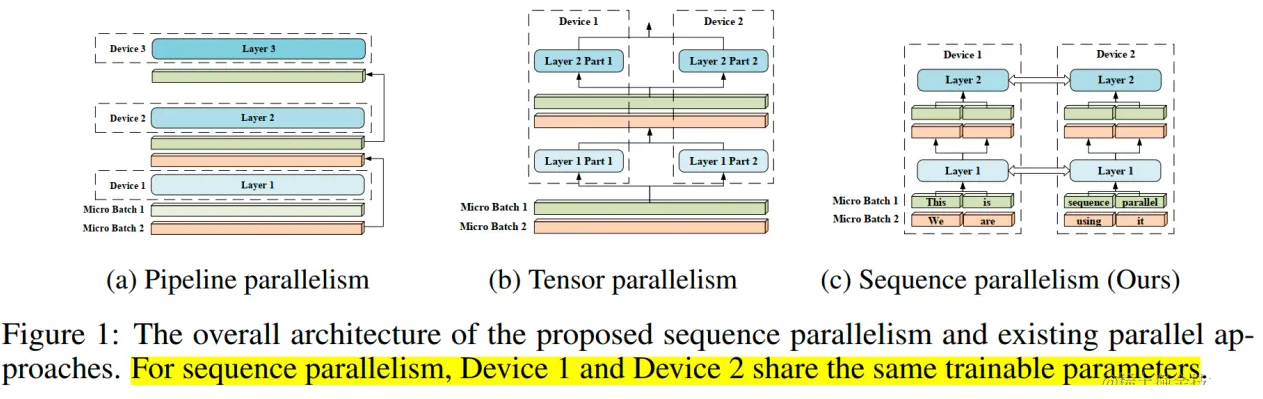
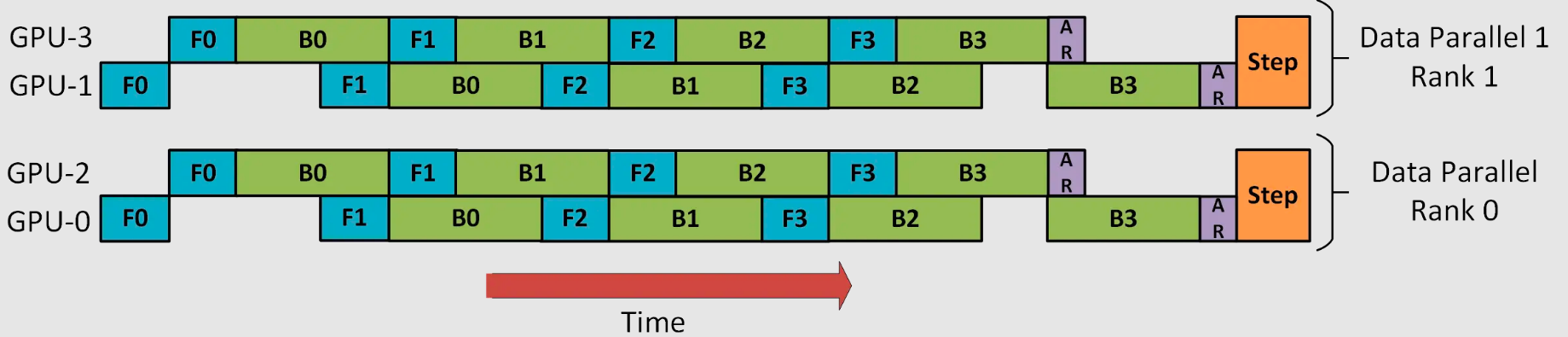
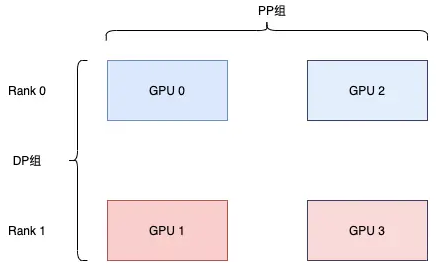
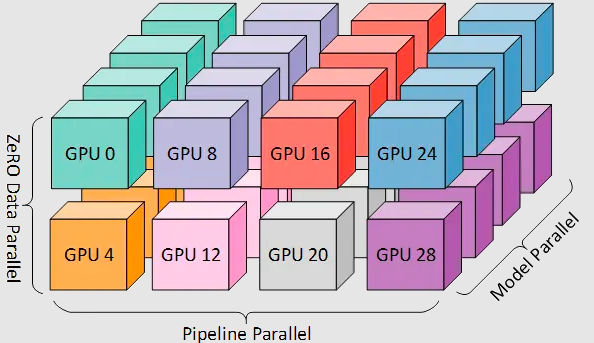
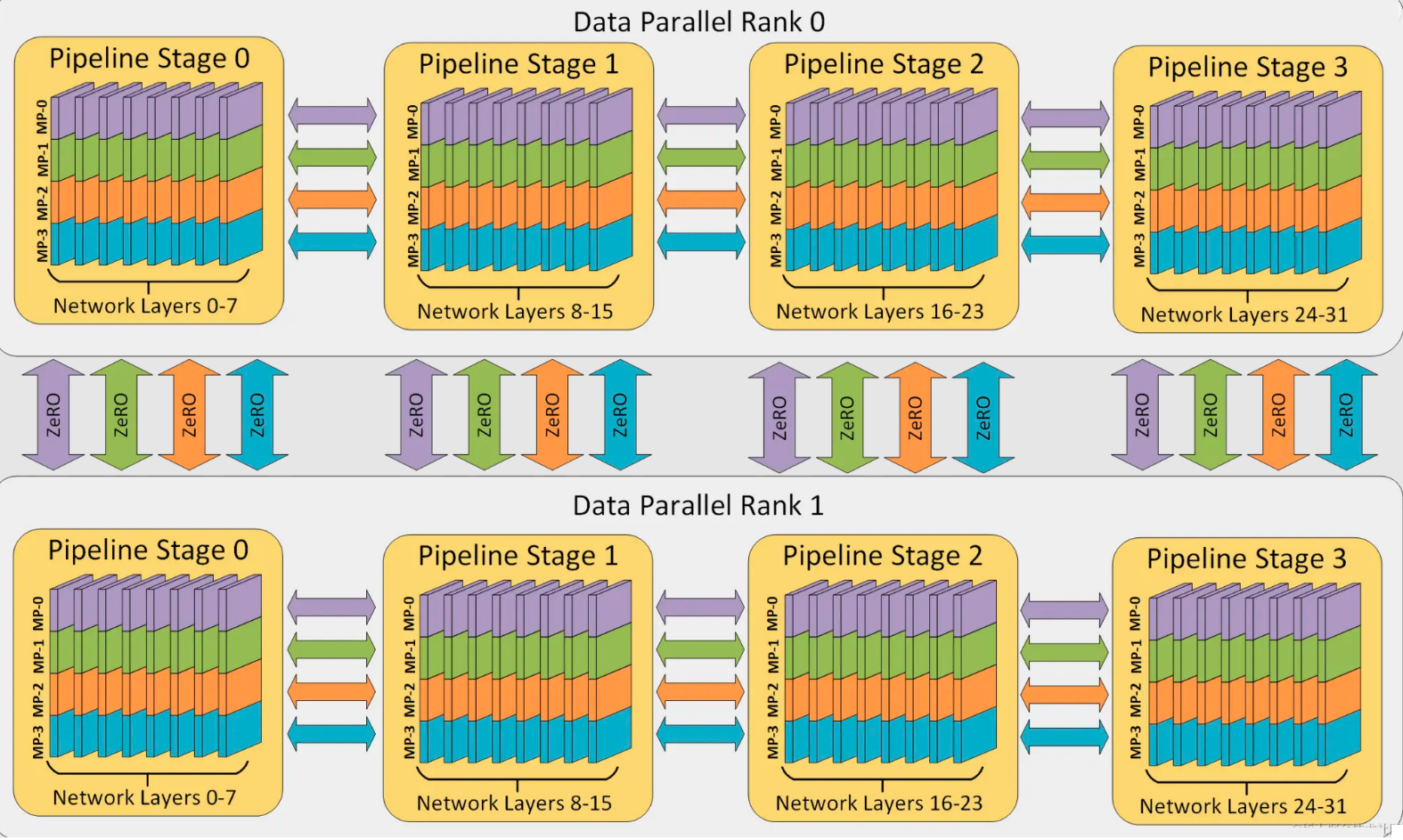
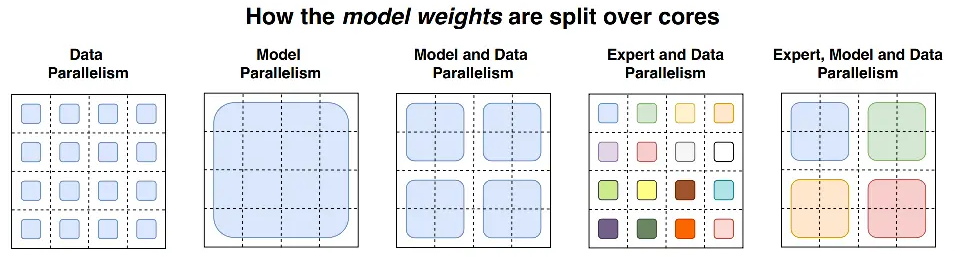
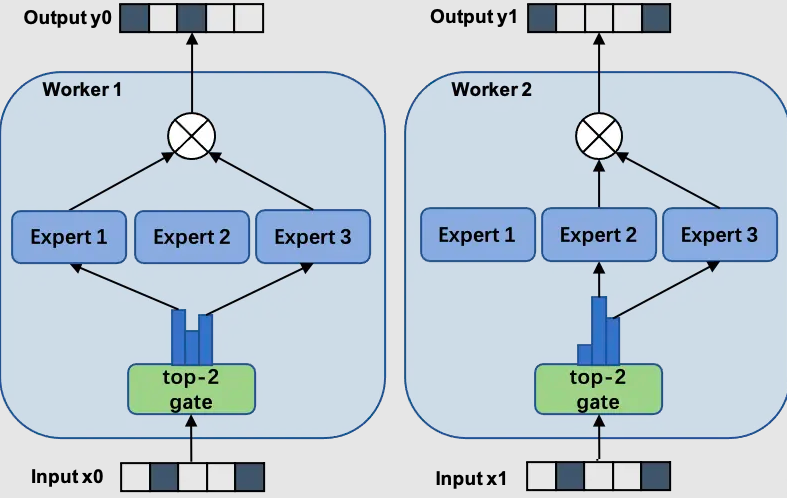
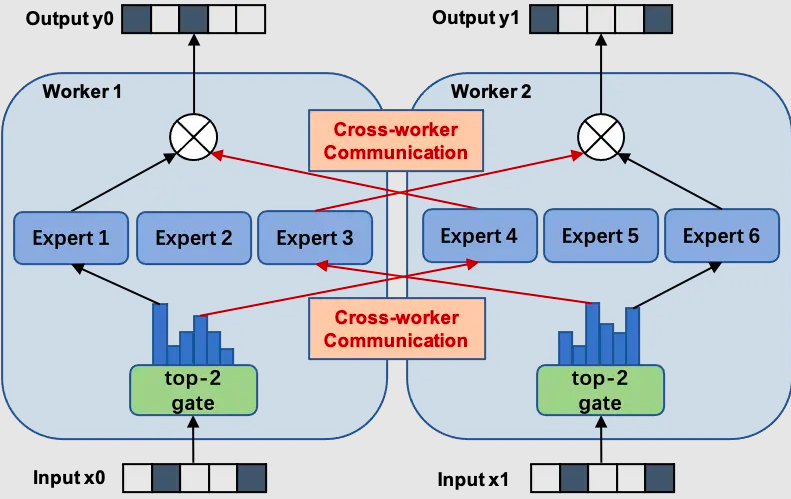
分布式并行策略
📅 发表于 2025/07/18
🔄 更新于 2025/07/18
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
infra
#data parrallel
#pipeline pararrlel
#F-then-B
#1F1B
#Gpipe
#PipeDream
#PipeDream-Flush
#Tensor Parrallel
#行并行
#列并行
#1D Parralel
#多维并行
#3D并行
#序列并行
#混合并行
#DP+PP+TP
#MoE并行