分布式训练框架
📅 发表于 2025/07/18
🔄 更新于 2025/07/18
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
llm-infra
#浮点数
#有偏指数
#FP32
#FP16
#BF16
#梯度溢出
#舍入误差
#动态损失缩放
#混合精度优化
#FP32权重备份
#模型显存分析
#参数
#梯度
#优化器
#激活值
#DeepSpeed
#ZeRO-DP
#Zero1
#Zero2
#Zero3
#Zero-Offload
1. 机器概念
主节点 master ip/port:协调其他节点、分配任务、结果汇总等。节点编号 node_rank:每个节点的唯一标识,不同计算机通信局部进程编号 local_rank:节点内部的进程编号全局进程编号 rank:整个系统全局进程编号,唯一标识全局进程总数 word_size:整个系统所有进程总数2. 通信策略
mpi:跨节点通信库,常用于CPU集群gloo: 高性能分布式训练框架,支持CPU和GPU集群nccl:英伟达的GPU专有通信库,适用于GPU1. 浮点数三要素🐦
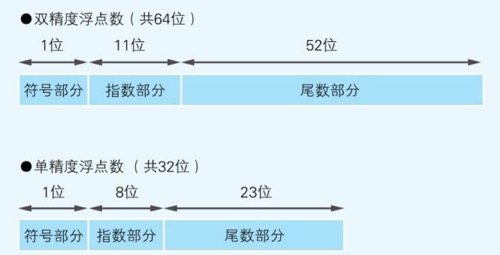
存储指数值-偏移量 ⭐,2位底 124-127=-3,即尾数位全0 - 无穷,尾数位不全0 - NaN ,熟悉的NaN ‼️0,+0, -0,非规范化浮点数,精度;实际尾数=1+尾数部分, 2. 单精度+双精度FP32/FP64🐔
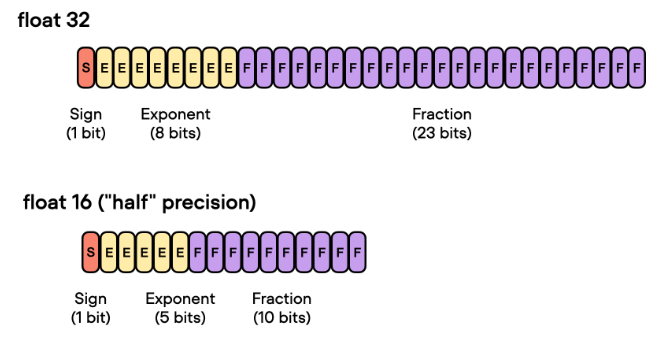
1 + 11 + 52。8个字节。1 + 8 + 23,指数位8位。4个字节。3. 半精度FP16🐱 🚀
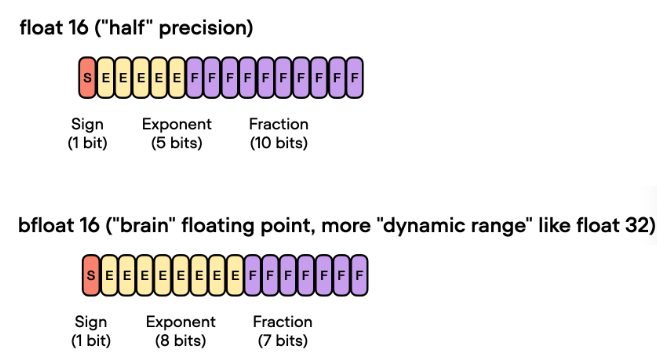
1 + 5 + 10,2个字节 。一半;能训更大模型、更大bs;通信成本降低;2-8倍;数值下溢或上溢问题:数值仅5位范围有限 精度较低+舍入误差问题:尾数位仅10位 动态损失缩放(Dynamic Loss Scaling)混合精度优化(Mixed Precision Optimizer)等4. BF16 (Brain float point)🐻
1 + 8 + 78位,数值范围对齐FP32,对精度做折中梯度累加、权重更新等操作。Fp64&fp32:
非常重要,指数位全0或全1的特殊情况💡 :
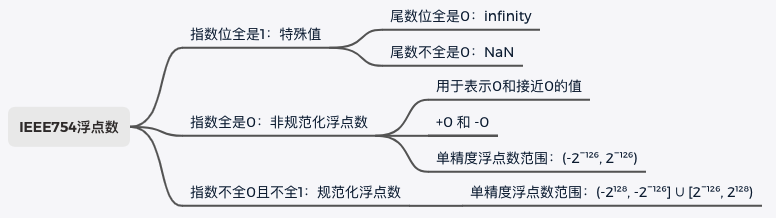
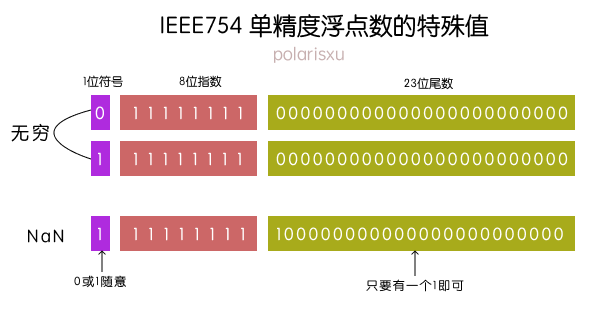
最大值:
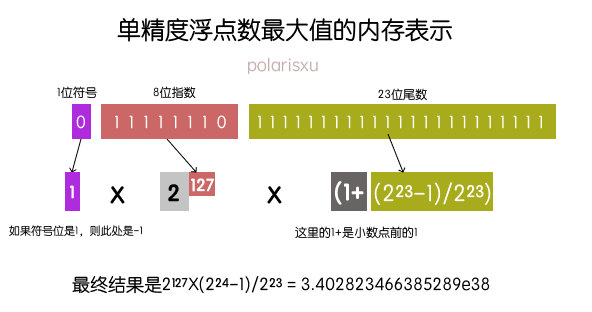
浮点数的示意图:
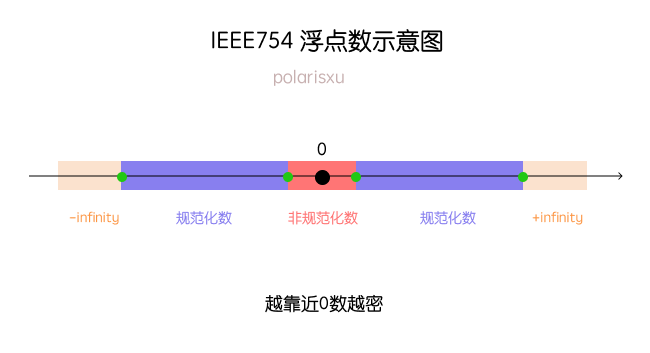

FP16缺点
解法一:FP32权重备份 ⛵
fp16舍入误差问题参数+激活+梯度 在训练时用FP16 🎉 ‼️FP32 参数 ‼️ lr*梯度很小,使用FP32避免FP16更新无效解法二:Loss Scale 🎓
梯度下溢出问题,保留loss关键信息如果用fp16,则全为0Scale UP:loss增大Scale Down:权重梯度缩小解法三:提高算数精度
解法四:BF16
其他方法
主要流程
存储到磁盘的模型权重是FP32精度。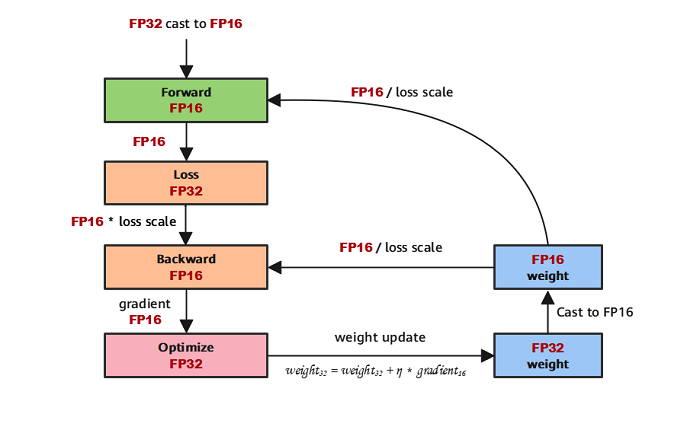
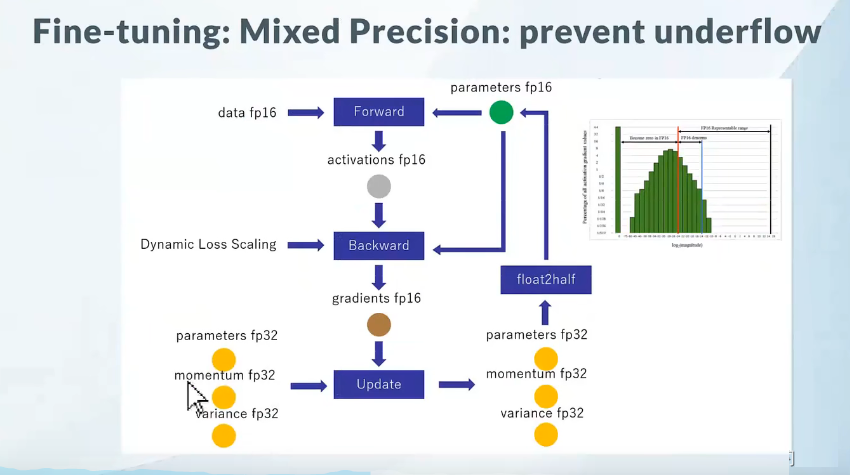
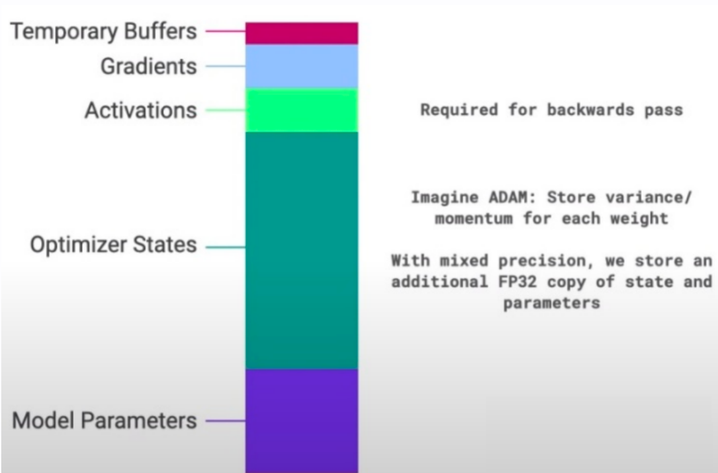
具体显存占用项 (模型参数为m或
模型参数fp16:2m,1参数2Byte
1024*1024*1024 单位就是G模型梯度fp16:2m,1参数2Byte,和模型参数一致
优化器(Adam):12m,1参数12Byte
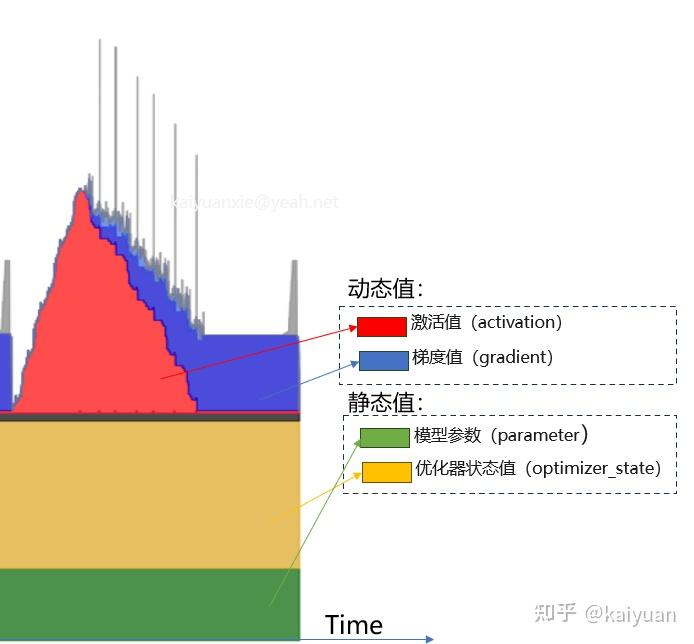
8bit优化器:则是4+1+1=6Byte。激活值(Activation)
占用大量显存‼️ 激活checkpoint或重计算来降低,但仍然很大。总结
模型+梯度+优化器+激活值+其他;前3者统称为模型状态,是ZeRO主要优化对象。模型/(PP*TP) + 梯度/(PP) + 优化器/N + 激活/TP1个参数16Byte,4m+12m=16m,也等于4m+km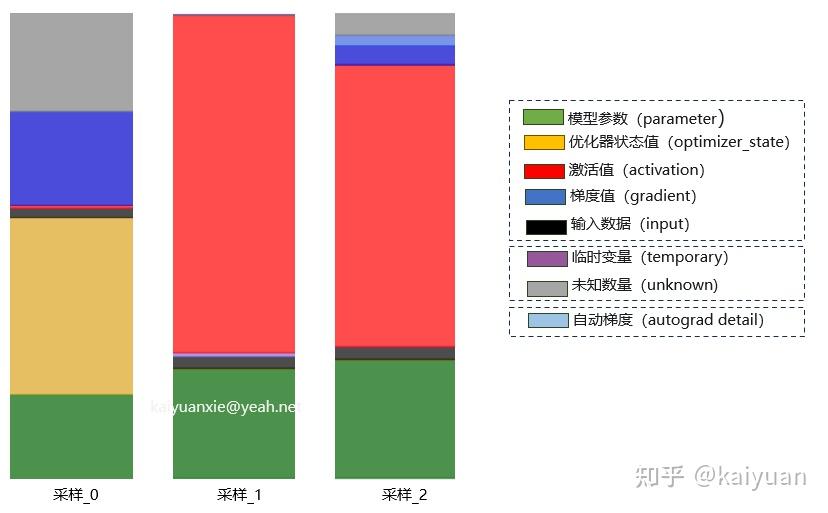

总显存
14B*2 = 28GB14B*2=28GB14B*4=56GB14B*4=56GB14B*4=56GB14B*12=168GB14B*2*3=84GBs*b*h*L*精度8196*32*5120*40*2/1024/1024/1024=100GB324GB + 30GB = 350GB8卡
Qwen3-14B 配置
{
"architectures": [
"Qwen3ForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 5120,
"initializer_range": 0.02,
"intermediate_size": 17408,
"max_position_embeddings": 40960,
"max_window_layers": 40,
"model_type": "qwen3",
"num_attention_heads": 40,
"num_hidden_layers": 40,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000,
"sliding_window": null,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.51.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151936
}Qwen2.5-7B 配置:
{
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151643,
"hidden_act": "silu",
"hidden_size": 3584,
"initializer_range": 0.02,
"intermediate_size": 18944,
"max_position_embeddings": 131072,
"max_window_layers": 28,
"model_type": "qwen2",
"num_attention_heads": 28,
"num_hidden_layers": 28,
"num_key_value_heads": 4,
"rms_norm_eps": 1e-06,
"rope_theta": 1000000.0,
"sliding_window": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.40.1",
"use_cache": true,
"use_mrope": false,
"use_sliding_window": false,
"vocab_size": 152064
}GPU存储太多内容,模型、梯度、优化器、激活、buffer等内容。DeepSpeed 采用Zero Redundancy Optimizer,减内存占用
核心思想
普通DDP模型,但每张卡只存一部分优化器状态os、梯度g、参数p。
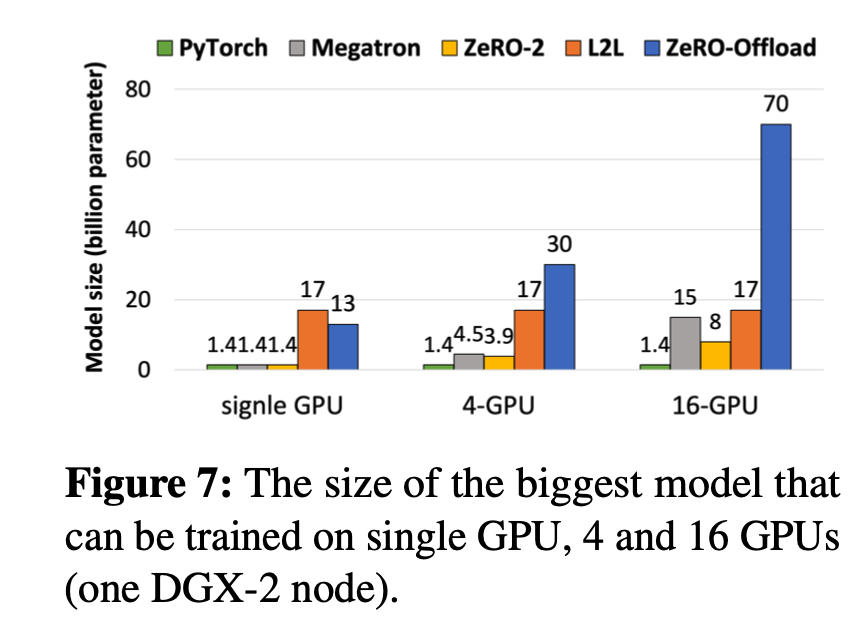
ZeRO-DP:
ZeRO1:+优化器状态划分
4m+12m -> 1/4ZeRO2:+梯度划分
对梯度g做划分,每卡持有4m+12m -> 1/8ZeRO3:+参数划分
对参数p做切分,每卡持有4m+12m -> 趋近于0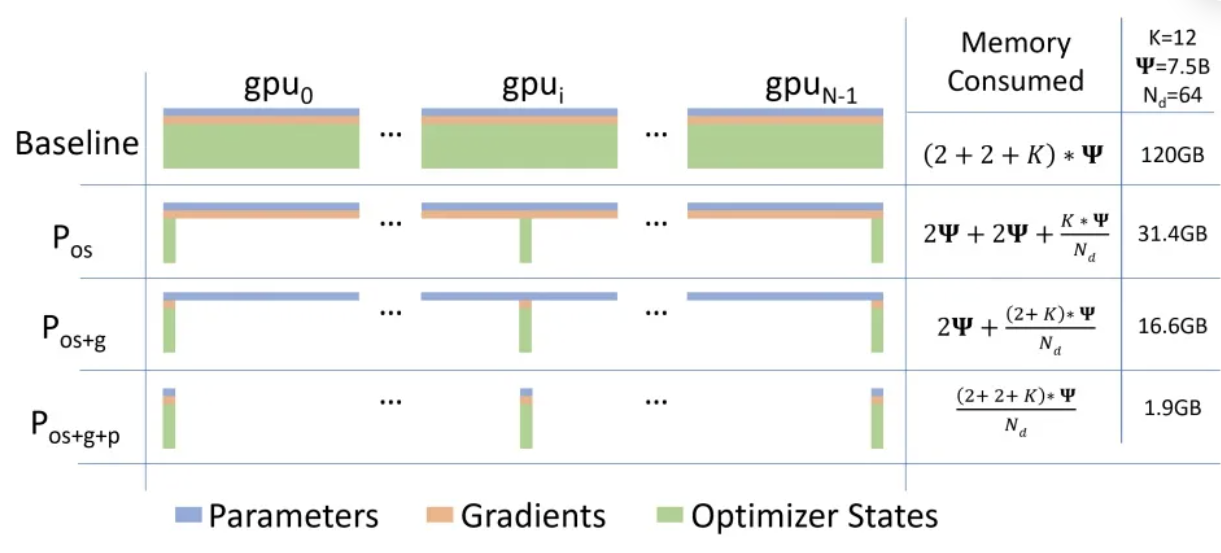
背景
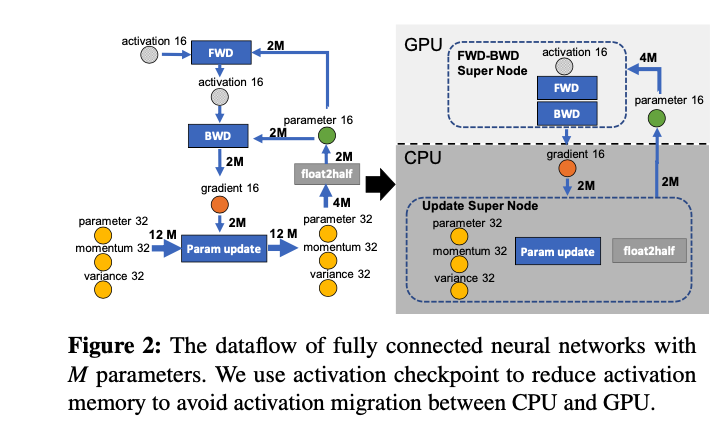
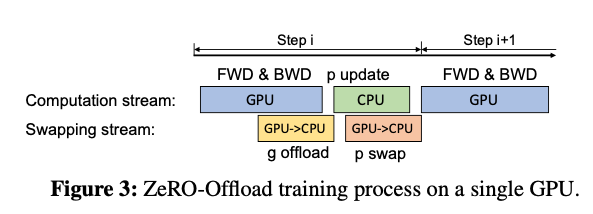
核心思想
前向和反向,合成一个节点,放在GPU上,FWD-BWD Super Node参数更新和float2half,合成一个节点,放在CPU上,Update Super Node