Transformer
📅 发表于 2018/08/29
🔄 更新于 2018/08/29
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#Transformer
#Self-Attention
#多头注意力
#残差连接
#层归一化
#位置编码
#机器翻译
#论文笔记
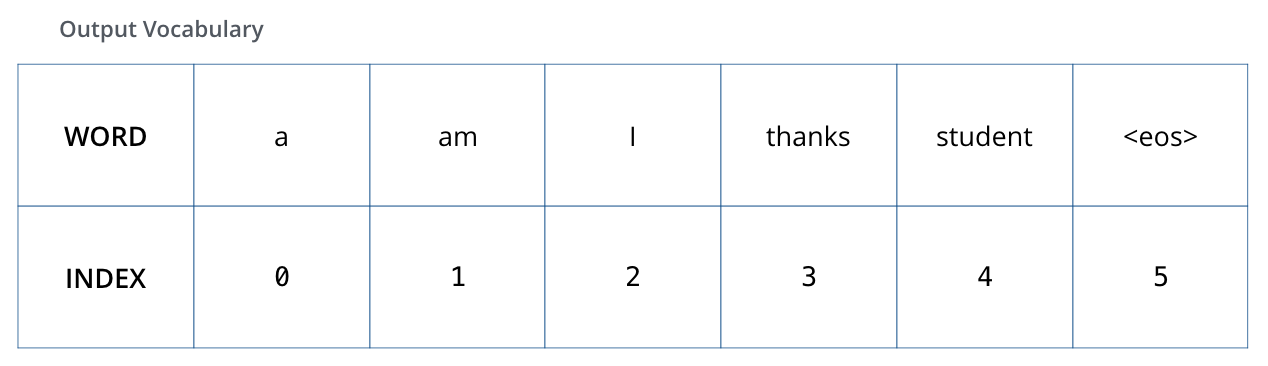
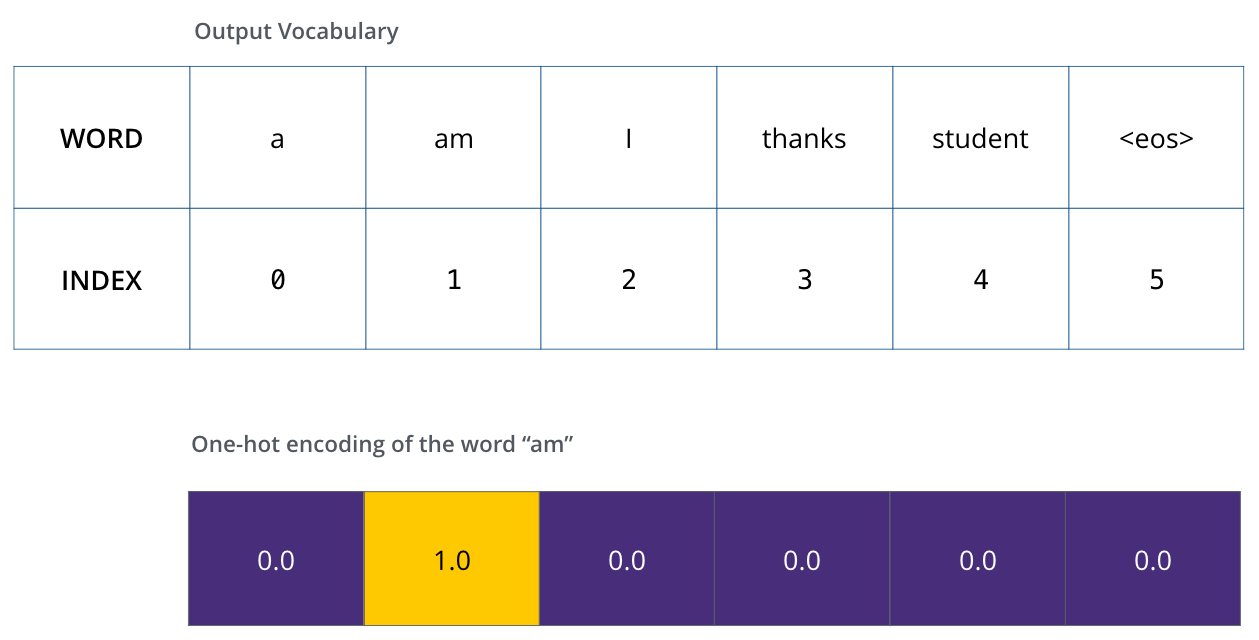
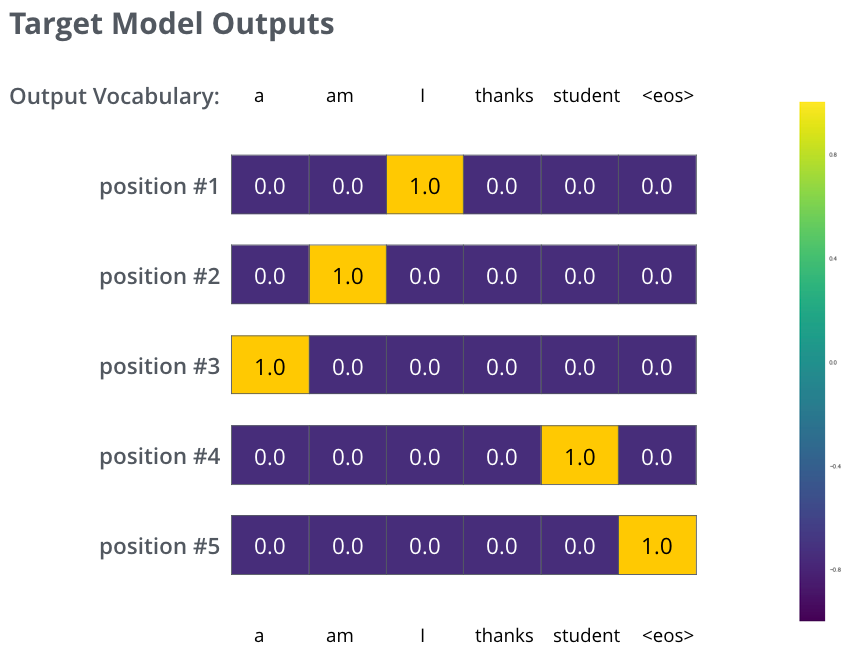
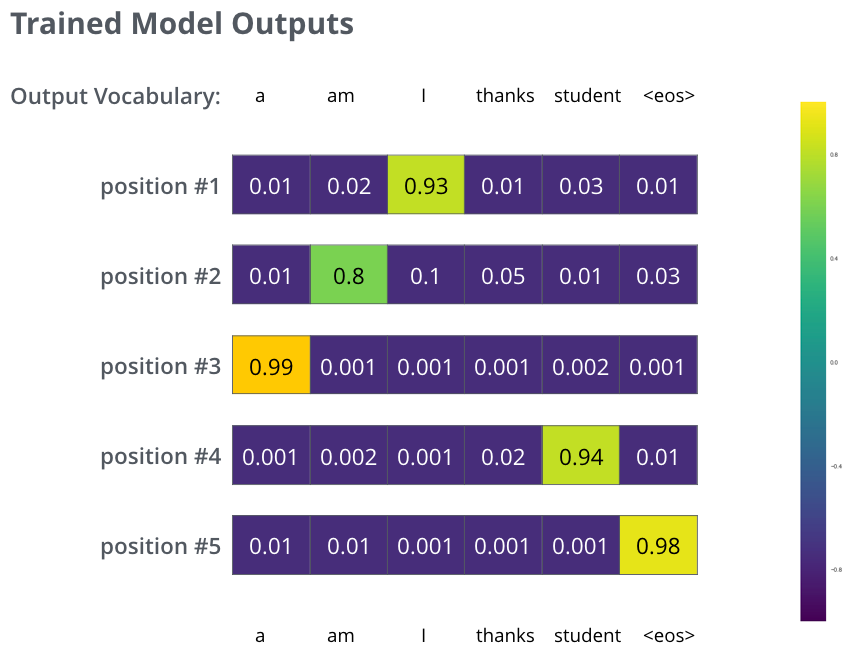
大名鼎鼎的Transformer,Attention Is All You Need
其实也是一个Encoder-Decoder的翻译模型。
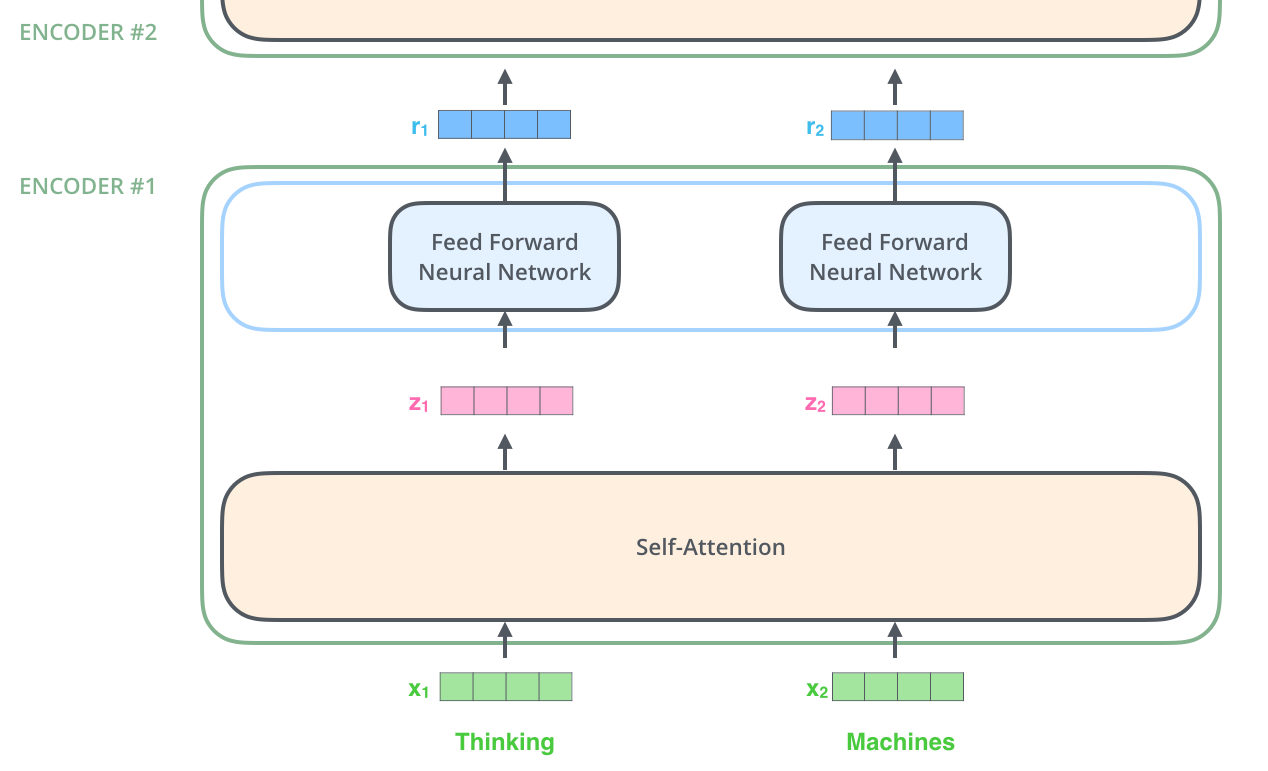
由一个Encoders和一个Decoders组成。
Encoders由多个Encoder块组成。
1个Encoder由Self-Attention和FFN组成
一个Encoder的结果再给到下一个Encoder
Encoder-Decoder
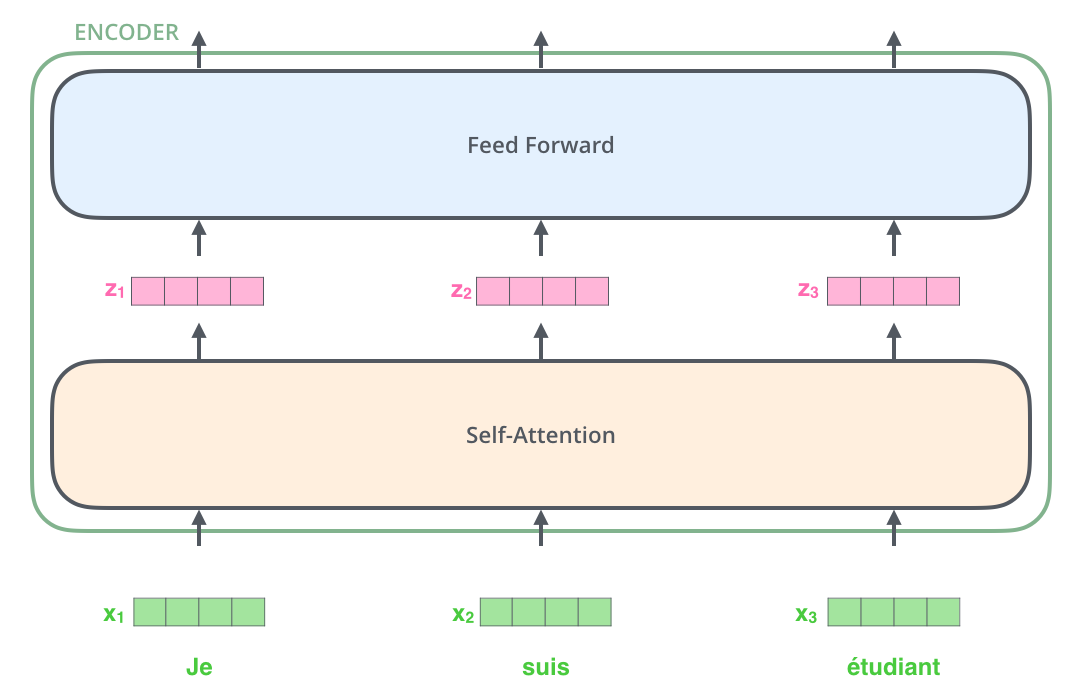
对一个句子进行编码

Self-Attention会对每一个单词进行编码,得到对应的向量。
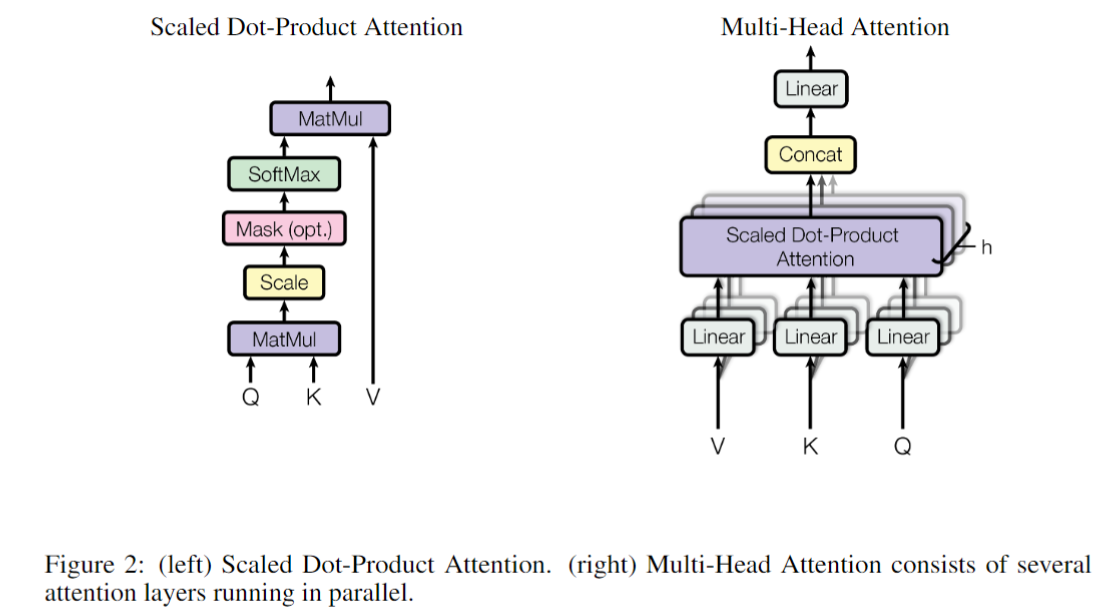
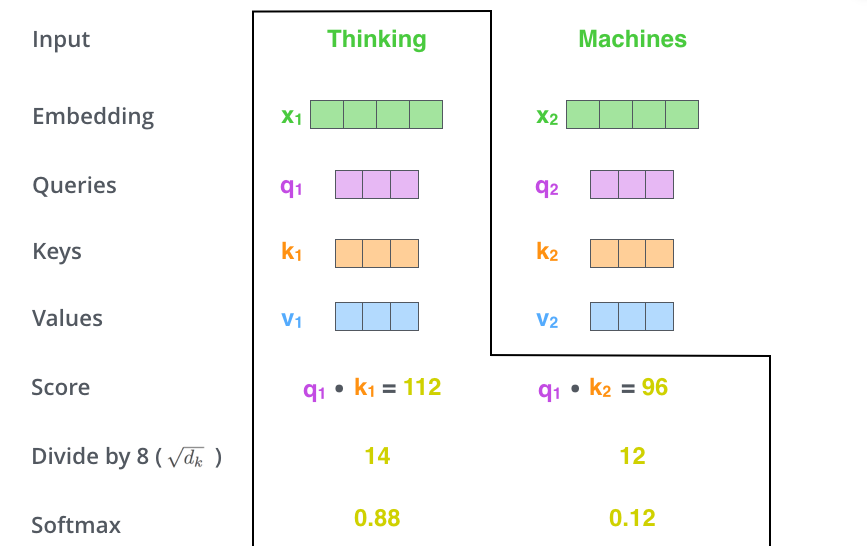
1. 乘以3个矩阵生成3个向量:Query、Key、Value
2. 计算与每个位置的score
编码一个单词时,会计算它与句子中其他单词的得分。会得到每个单词对于当前单词的关注程度。
3. 归一化和softmax得到每个概率
4. 依概率结合每个单词的向量
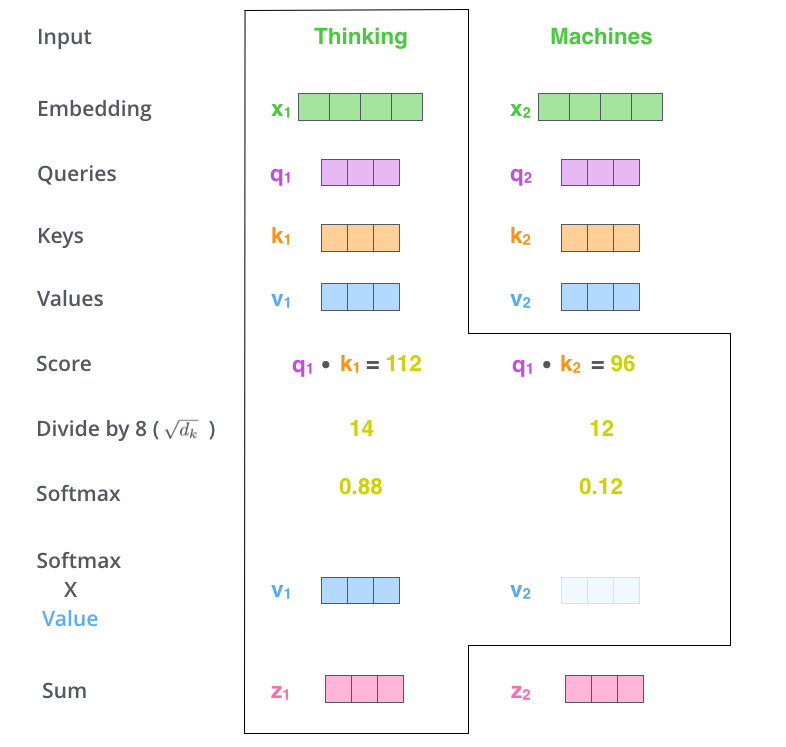
Attention图示
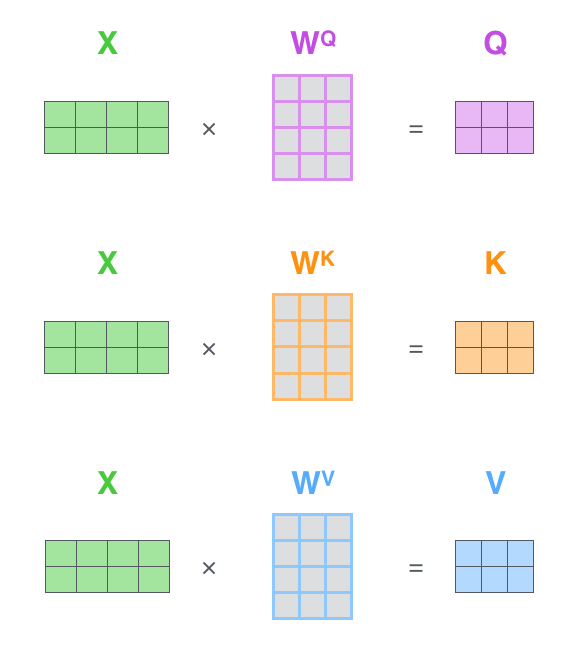
其实就是一个注意力矩阵公式
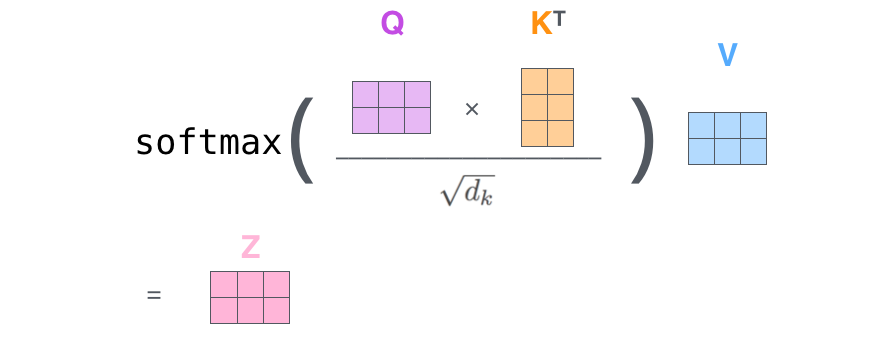
其实就是多个KV注意力。从两个方面提升了Attention Layer的优点
representation subspaces多头注意力矩阵形式
经过多头注意力映射,会生成多个注意力
把这些注意力头拼接起来,再乘以一个大矩阵,最终融合得到一个信息矩阵。会给到FFN进行计算。
Position-wise Feed-Forward Network,会对每个位置过两个线性层,其中使用ReLU作为激活函数。
词向量+位置信息=带位置信息的词向量
示例
再把sin和cos的两个值拼接起来,就得到如下图所示。