Dynamic Coattention Network (Plus)
📅 发表于 2018/03/15
🔄 更新于 2018/03/15
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#DCN
#coattention
#QA
先放四张图,分别是DCN的Encoder、Decoder,DCN+的Encoder和Objective。后面再详细总结
Dynamic Coattention Networks For Question Answering
DCN+: Mixed Objective and Deep Residual Coattention for Question Answering
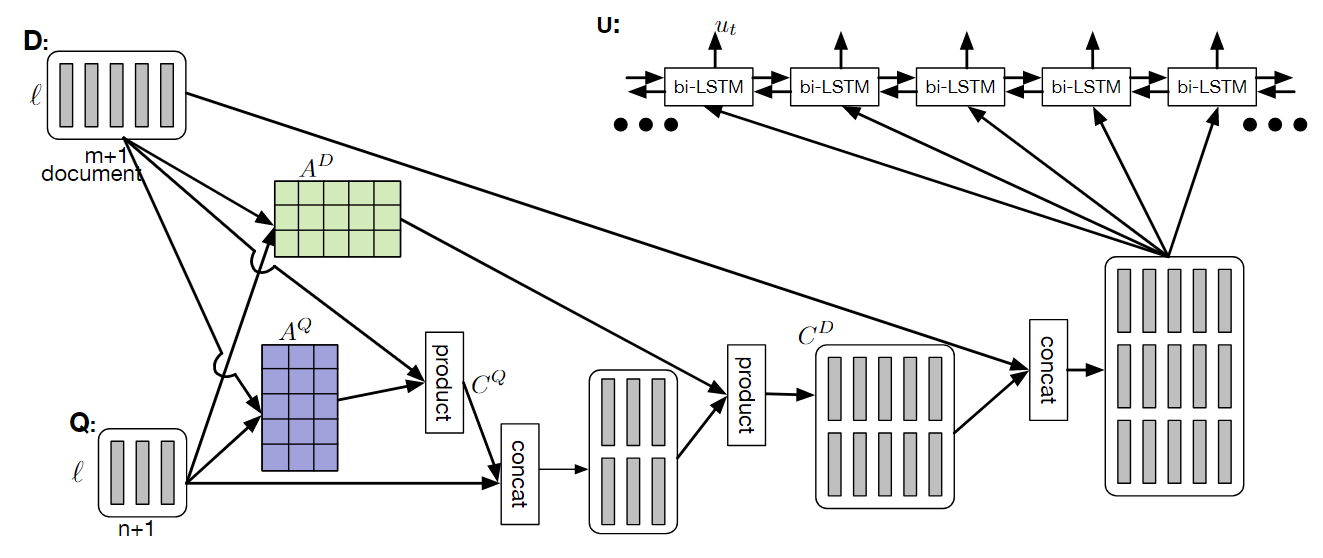
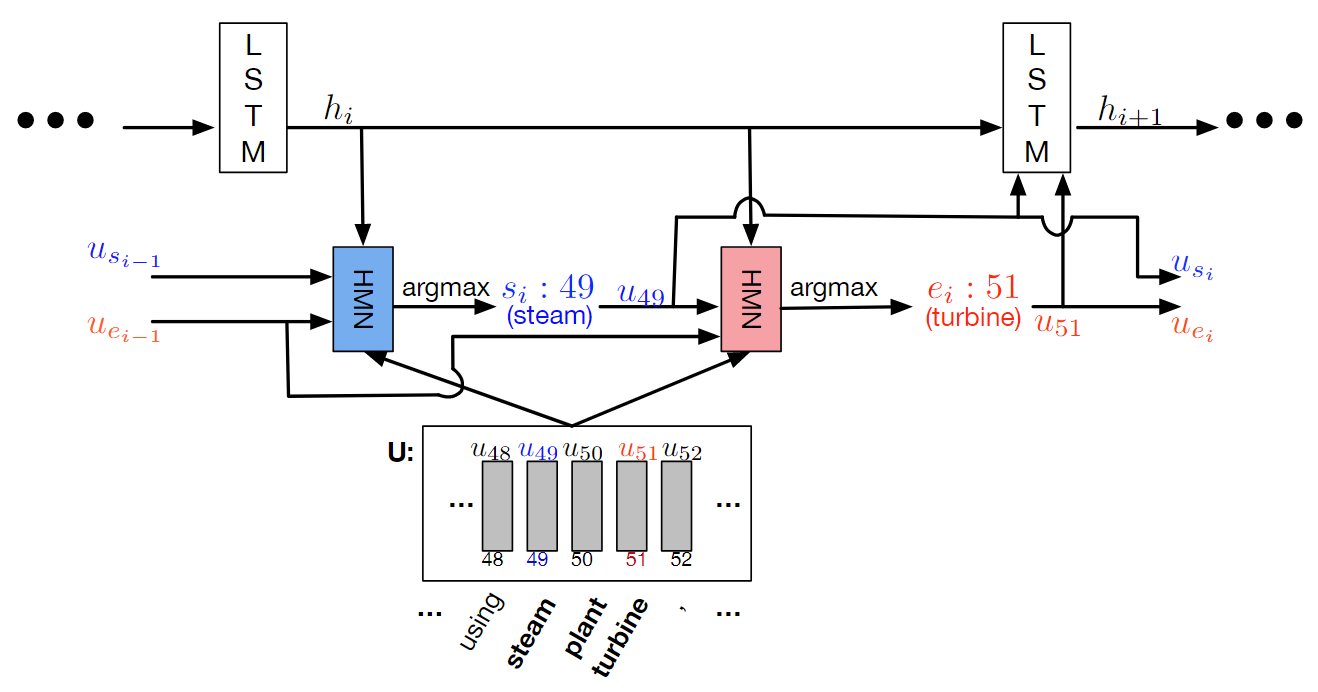
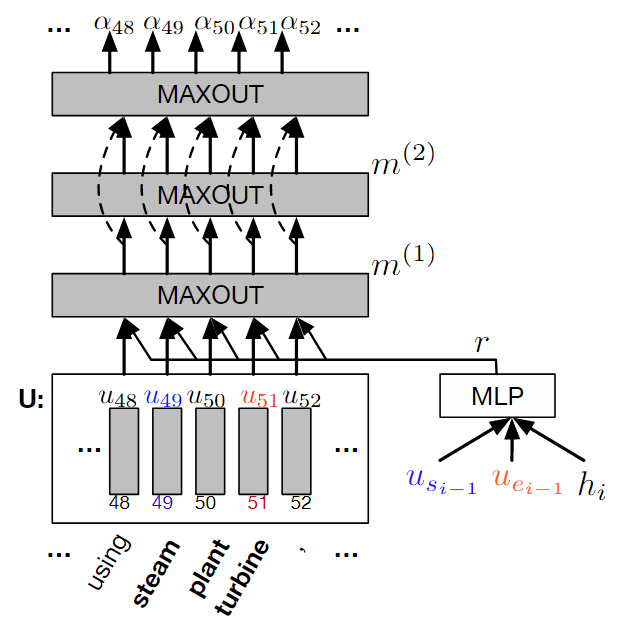
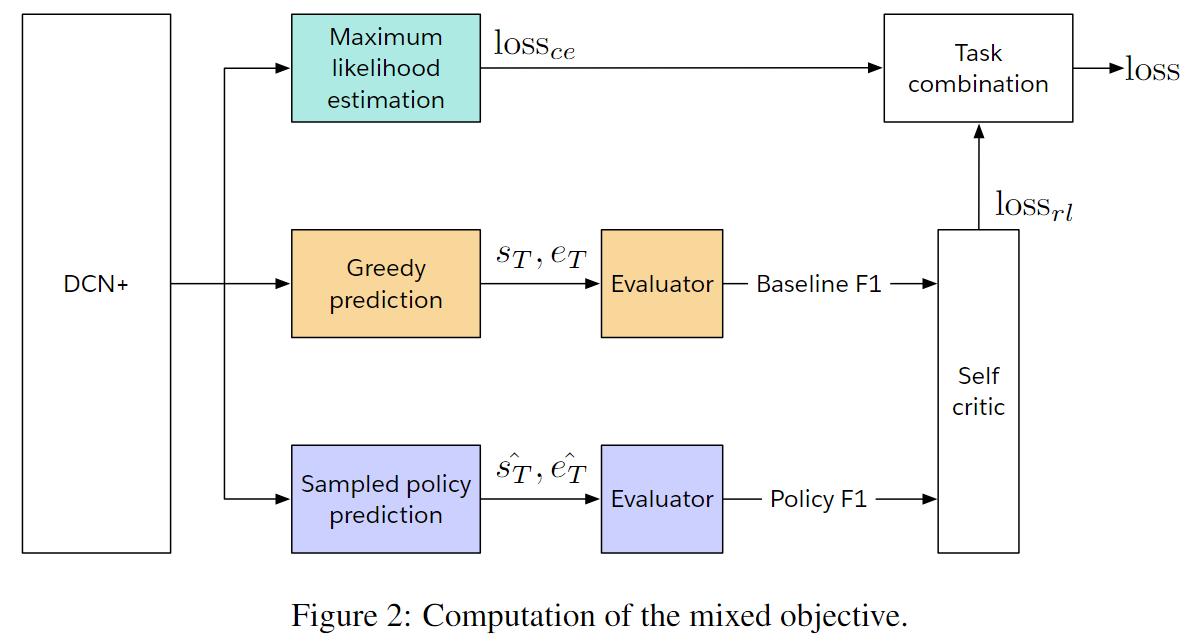
loss没有判断真正的意义
DCN使用传统交叉熵去优化optimization,只考虑答案字符串的匹配程度。但是实际上人的评判evaluation却是看回答的意义。如果只考虑span,则有下面两个问题:
句子:Some believe that the Golden State Warriors team of 2017 is one of the greatest teams in NBA history
问题:which team is considered to be one of the greatest teams in NBA history
正确答案:the Golden State Warriors team of 2017
其实Warriors也是正确答案, 但是传统交叉熵却认为它还不如history。
DCN没有建立起Optimization和 evaluation的联系。 这也是Word Overlap。
单层coattention表达力不强
Mixed Loss
交叉熵+自我批评学习(强化学习)。Word真正意义相似才会给一个好的reward。
Deep Residual Coattention Encoder
多层表达能力更强,详细看下面的优点。
优点
两个别人得出的重要结论:
stacked self-attention 可以加速信号传递比DCN的两个优化点:
coattention with self-attention和多层coattention 。可以对输入有richer representationscoattention outputs进行残差连接。缩短了信息传递路径。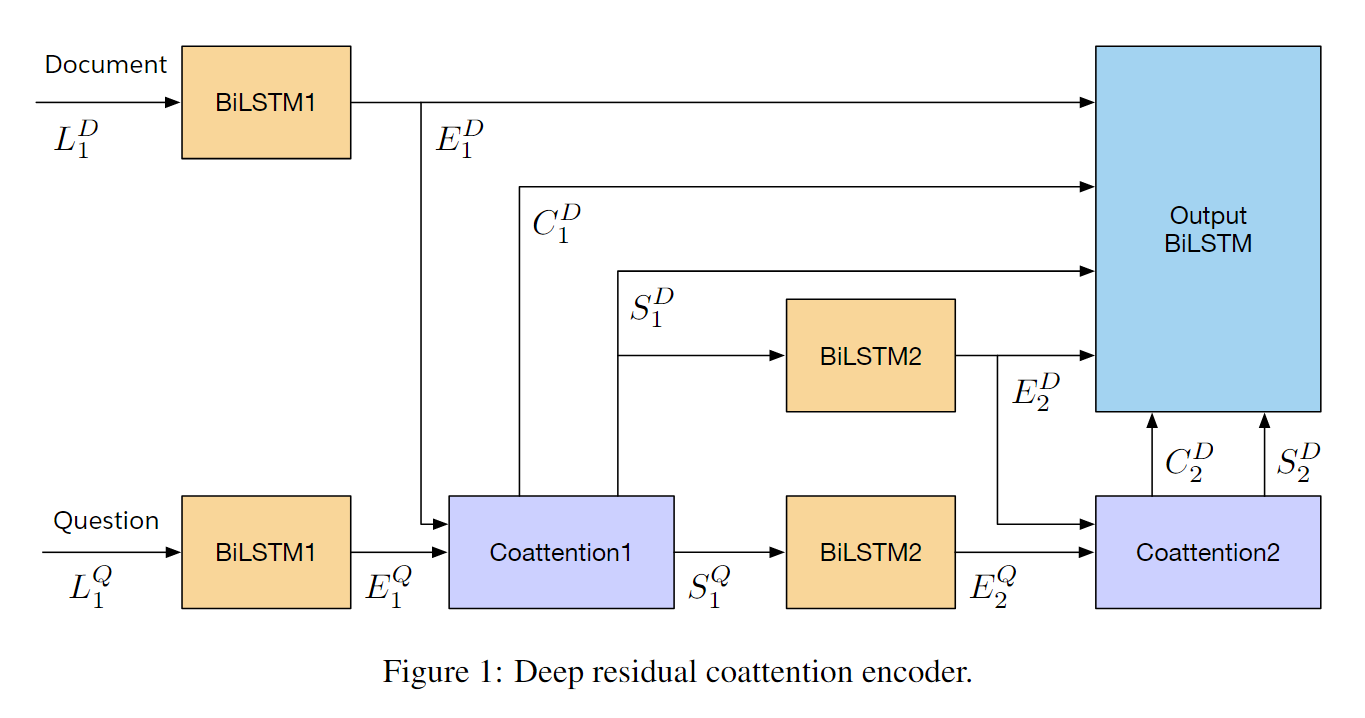
当时理解了很久都不懂,后来一个下午,一直看,结合机器翻译实现和实际例子矩阵计算,终于理解了Attention、Coattention。
参考了我的下面三篇笔记。
单个Coattention层计算
经过双向RNN后,得到两个语义编码:文档
计算关联得分矩阵A
做行Softmax,得到Q对D的权值分配概率attention_weights
计算D的summary,
summary, 也称作D需要context同理,对列做softmax, 得到D对Q的权值分配概率summary,
这时,借鉴alternation-coattention思想 去计算对D的Coattention context
实际上,Summary, 都是context。 只是
使用两层coattention, 最后再残差连接,经过LSTM输出。
第一层
第二层
残差连接所有的D
LSTM编码输出,得到Encoder的输出