各种注意力总结
📅 发表于 2018/03/25
🔄 更新于 2018/03/25
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#Attention
#论文笔记
一切都应该尽可能简单,但不能过于简单。
本文主要是总结:注意力机制、注意力机制的变体、论文中常见的注意力
计算能力不足
神经网络有很强的能力。但是对于复杂任务,需要大量的输入信息和复杂的计算流程。计算机的计算能力是神经网络的一个瓶颈。
减少计算复杂度
常见的:局部连接、权值共享、汇聚操作。
但仍然需要:尽量少增加模型复杂度(参数),来提高模型的表达能力。
简单文本分类可以使用单向量表达文本
只需要一些关键信息即可,所以一个向量足以表达一篇文章,可以用来分类。
阅读理解需要所有的语义
文章比较长时,一个RNN很难反应出文章的所有语义信息。
对于阅读理解任务来说,编码时并不知道会遇到什么问题。这些问题可能会涉及到文章的所有信息点,如果丢失任意一个信息就可能导致无法正确回答问题。
网络容量与参数成正比
神经网络中可以存储的信息称为网络容量。 存储的多,参数也就越多,网络也就越复杂。 LSTM就是一个存储和计算单元。
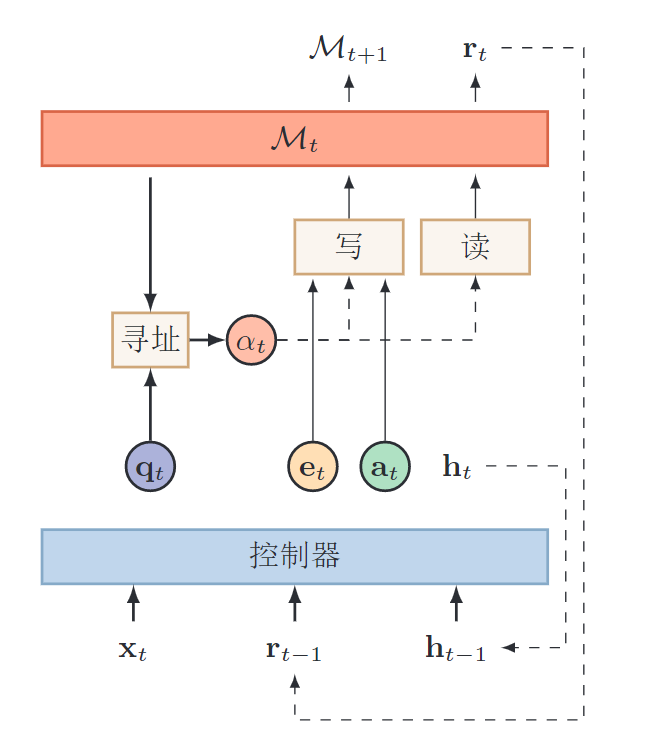
注意力和记忆力解决信息过载问题
输入的信息太多(信息过载问题),但不能同时处理这些信息。只能选择重要的信息进行计算,同时用额外空间进行信息存储。
信息选择:聚焦式自上而下地选择重要信息,过滤掉无关的信息。注意力机制外部记忆 : 优化神经网络的记忆结构,使用额外的外部记忆,来提高网络的存储信息的容量。 **记忆力机制 **比如,一篇文章,一个问题。答案只与几个句子相关。所以只需把相关的片段挑选出来交给后续的神经网络来处理,而不需要把所有的文章内容都给到神经网络。
注意力机制Attention Mechanism 是解决信息过载的一种资源分配方案,把计算资源分配给更重要的任务。
注意力:人脑可以有意或无意地从大量的输入信息中,选择小部分有用信息来重点处理,并忽略其它信息
聚焦式注意力
自上而下有意识的注意力。有预定目的、依赖任务、主动有意识的聚焦于某一对象的注意力。
一般注意力值聚焦式注意力。聚焦式注意力会根据环境、情景或任务的不同而选择不同的信息。
显著性注意力
自下而上无意识的注意力。由外界刺激驱动的注意力,无需主动干预,也和任务无关。如Max Pooling和Gating。
鸡尾酒效应
鸡尾酒效应可以理解这两种注意力。 在吵闹的酒会上
把目前的最大汇聚Max Pooling和门控Gating 近似地看做自下而上的基于显著性的注意力机制。
为了节省资源,选择重要的信息给到后续的神经网络进行计算,而不需要把所有的内容都给到后面的神经网络。
输入N个信息
计算注意力分布
注意力分布 ,
加性模型
点击模型
计算注意力
Soft Attention 是对所有的信息进行加权求和。Hard Attention是选择最大信息的那一个。
使用软性注意力选择机制,对输入信息编码为,实际上也是一个期望。

传统机器翻译Encoder-Decoder的缺点:
注意力机制直接从源语言信息中选择相关的信息作为辅助,有下面几个好处:
图像描述生成
Multi-head Attention利用多个查询
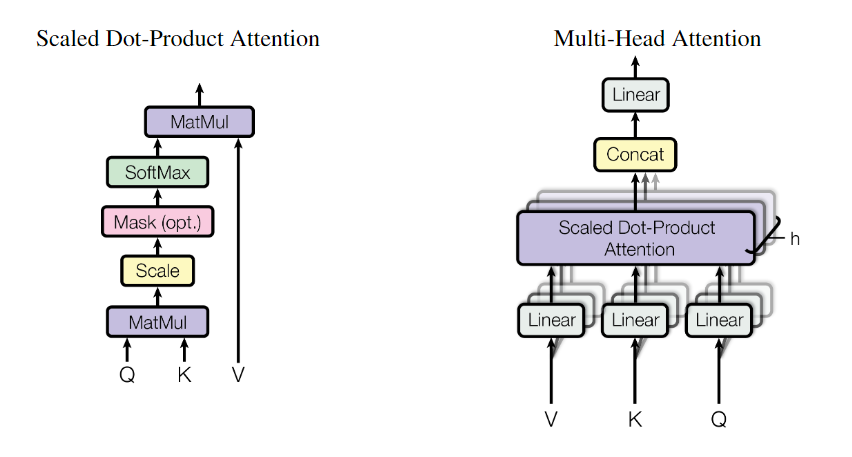
硬性注意力是只关注到一个位置上。
缺点:loss与注意力分布之间的函数关系不可导,无法使用反向传播训练。一般使用软性注意力。
需要:硬性注意力需要强化学习来进行训练。
输入信息:键值对(Key, Value)。 Key用来计算注意力分布
普通注意力是在输入信息上的一个多项分布,是一个扁平结构。
如果输入信息,本身就有层次化的结构,词、句子、段落、篇章等不同粒度的层次。这时用层次化的注意力来进行更好的信息选择。
也可以使用一种图模型,来构建更加复杂的结构化注意力分布。
前面的都是计算注意力对信息进行筛选:计算注意力分布,利用分布对信息进行加权平均。
指针网络pointer network是一种序列到序列的模型,用来指出相关信息的位置。也就是只做第一步。
输入:
输出:
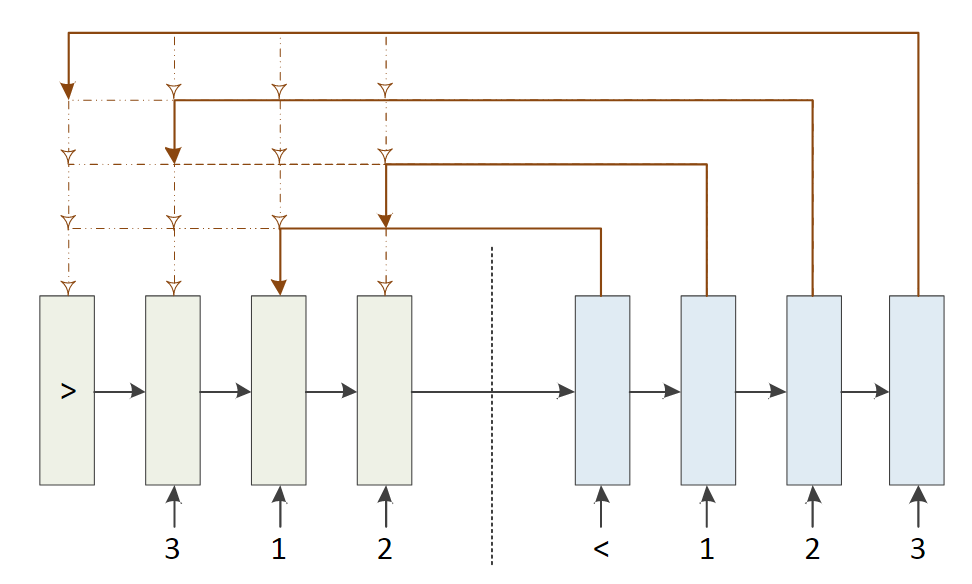
条件概率
第i步时,每个输入向量的得分(未归一化的注意力分布):
其中向量
有
合理所以最重要的就是合理地求出所关心的对象
打分函数的计算:(NMT里面三种score打分函数 )
Local-based Attention ,没有外部的关注对象,自己关注自己。General Attention, 有外部的关注对象,直接乘积,全连接层。Concatenation-based Attention, 有关注的对象,先concat或相加再过连接层。没有外部的信息,每个向量的得分与自己相关,与外部无关。
比如:Where is the football? ,where和football在句子中起总结性作用。Attention只与句子中的每个词有关。
一个句子,有多个词,多个向量。通过自己计算注意力分布,再对这些词的注意力进行加权求和,则可以得到这个句子的最终表达。
a是激活函数。 sigmoid, tanh, relu, maxout, y=x(无激活函数)。
1 一个得分简单求法
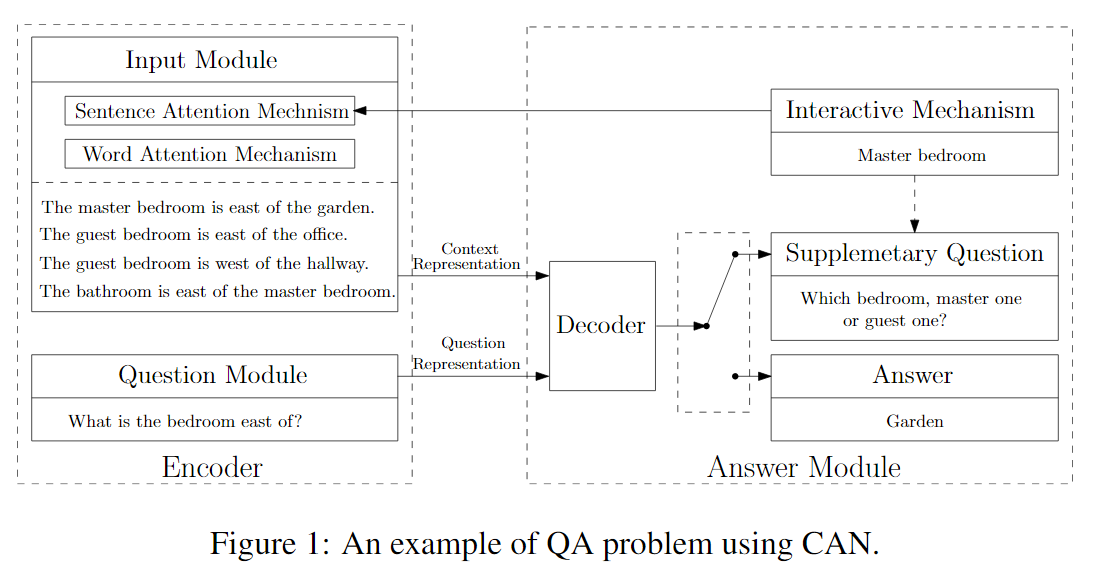
A Context-Aware Attention Network For Interactive Question Answering
利用自己计算注意力分布
利用新的注意力分布去计算最终的attention向量
2 两个得分合并为一个得分
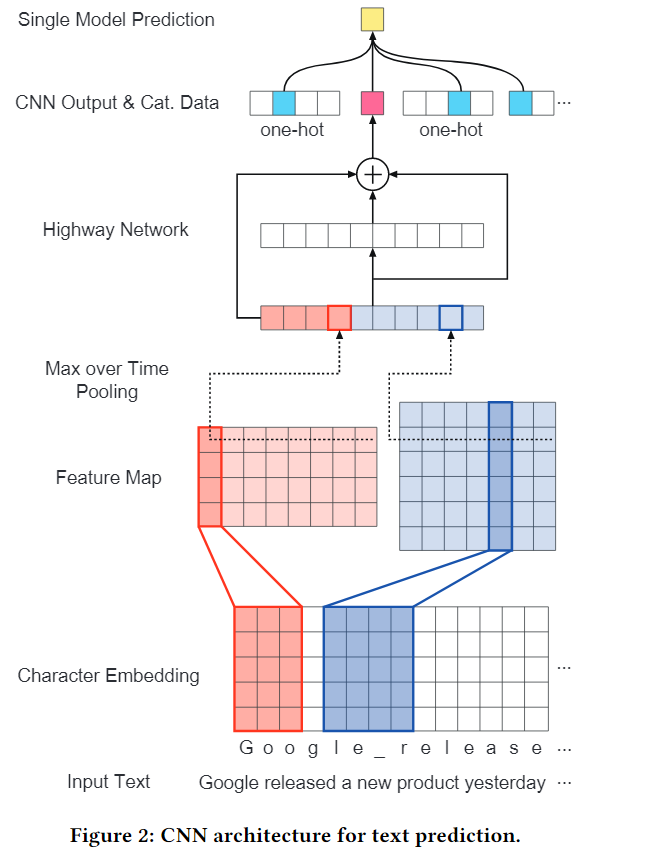
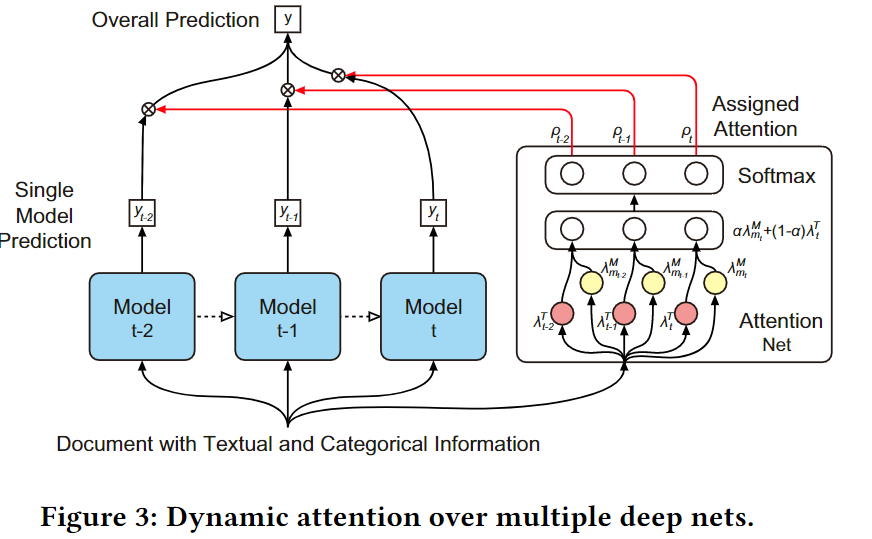
Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors’ Demonstration
计算两个得分
权值合并,求注意力分布:
3 论文图片
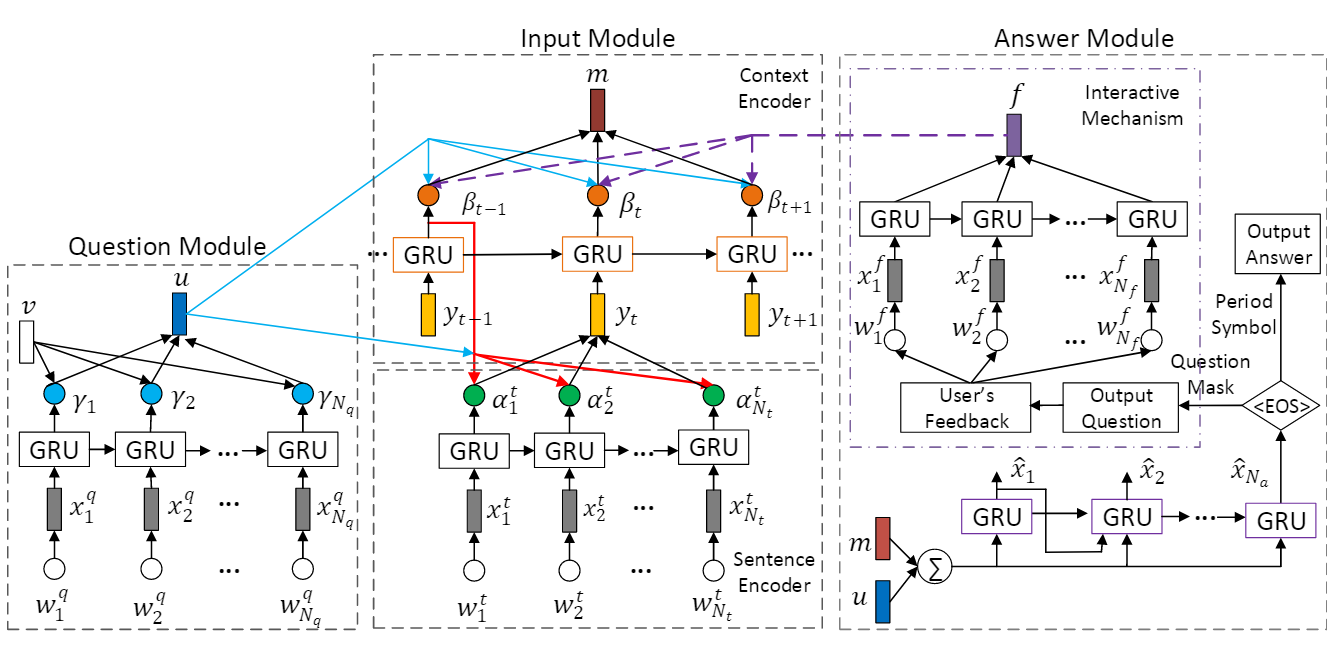
CAN for QA
Dynamic Attention
有外部的信息,
要关注的外部对象是
1 多个元素组成Attention
Item-Level Attention。可以看到需要加什么Attention,直接向公式里面一加就可以了。
有
Word-level Attention
每个句子,有k个词语,每个词语一个词向量,使用Local-based Attention , 可以得到这个句子的向量表达
Sentence-level Attention
有
得到这些信息之后,再具体问题具体分析。
1. 文章摘要生成
输入一篇文档,输出它的摘要。
Local-based Attention, 生成每个句子的vector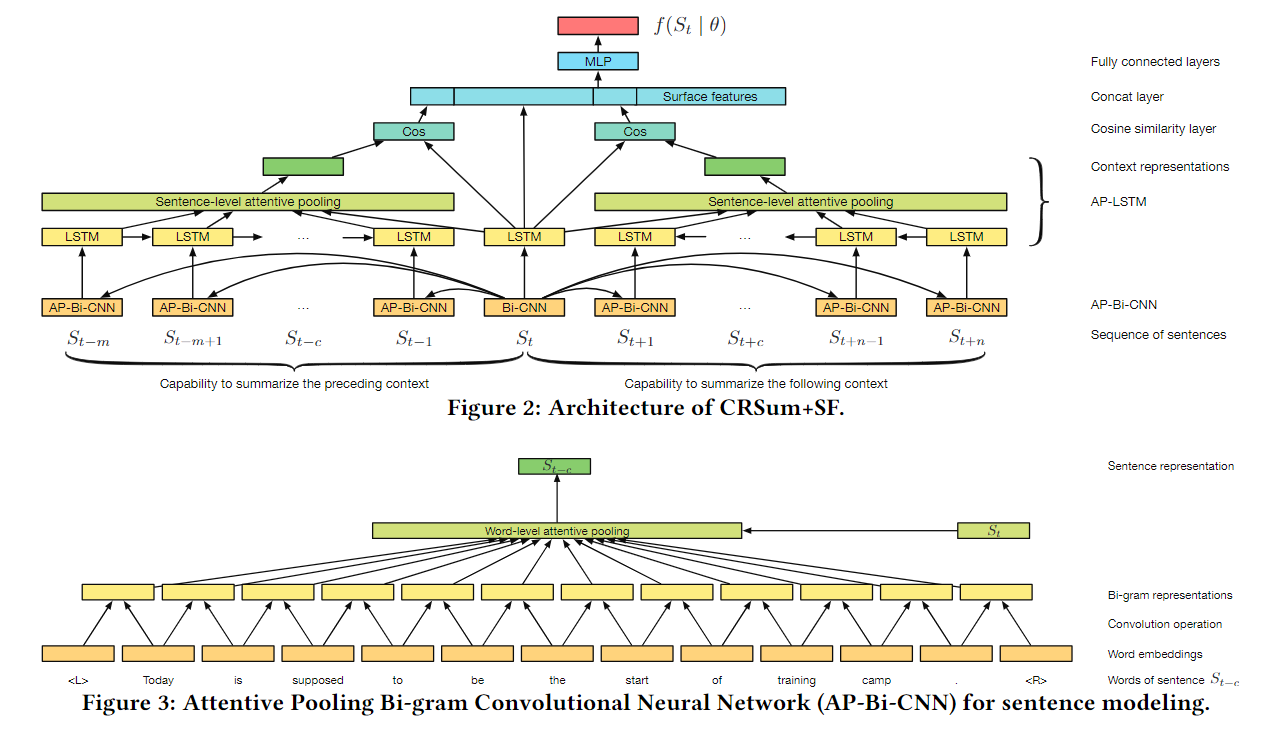
A Context-Aware Attention Network For Interactive Question Answering
第一层Attention
对句子过GRU,每一时刻的output作为词的编码。再使用Local-Attention对这些词,得到问句的表达
第二层Attention
由于上下文有多个句子。
首先,对一个句子进行过GRU,得到每一时刻单词的语义信息
再把当前句子的语义信息给到句子的GRU
第三次Attention
经过GRU,得到每个句子的表达
输出
结合
Period Symbol :是正确答案,直接输出Question Mask: 输出是一个问题,要继续问用户相应的信息用户重新给了反馈之后,对所有词汇信息使用simple attention mechanism, 即平均加权,所有的贡献都是一样的。得到反馈的向量表达
使用新的反馈向量和原始的问句向量,结合,重新生成新的context的语义表达