阿里小蜜论文
📅 发表于 2018/03/31
🔄 更新于 2018/03/31
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#chatbot
#qa
#IR
#BM25
#seq2seq
#CNN
AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine
1. IR Model
Information Retrieval。有一个QA对知识库,给一个问题,选择最相似的问题Pair,得出答案。
缺点:很难处理那些不在QA知识库里面的Long tail 问句
2. Generation Model
(Seq2Seq) :基于Question生成一个回答
缺点:会产生一些不连贯或者没意义的回答
3. 小蜜的混合模型
集成了IR和生成式模型。
Attentive Seq2Seq对候选答案进行打分阈值,直接输出该得分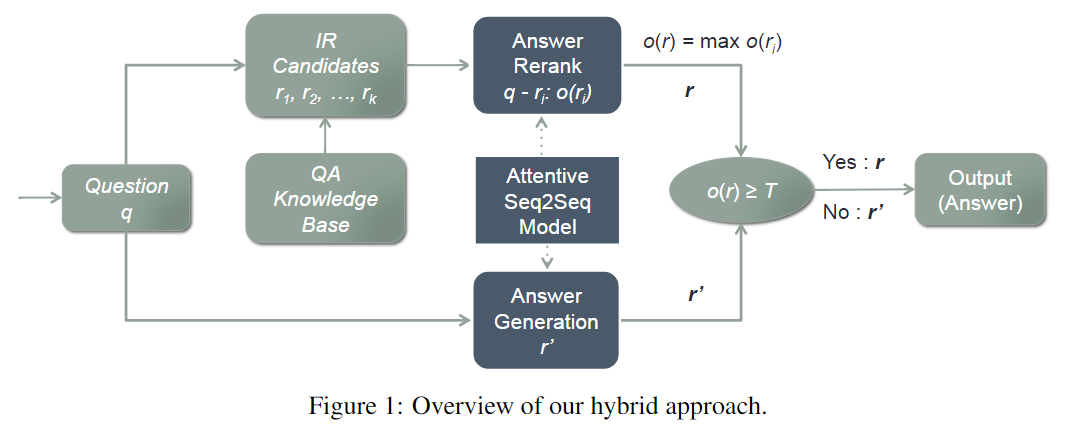
从用户和员工的对话数据中,提取一些问题和答案。也会把几个问题连在一起。最终共9164834个QA对。
1. IR步骤
2. BM25算法
BM25通常用来搜索相关性评分。
一个query和一个d 。把query分割成
IDF来计算。
特别地,一般
调节因子
1. Attentive Seq2Seq
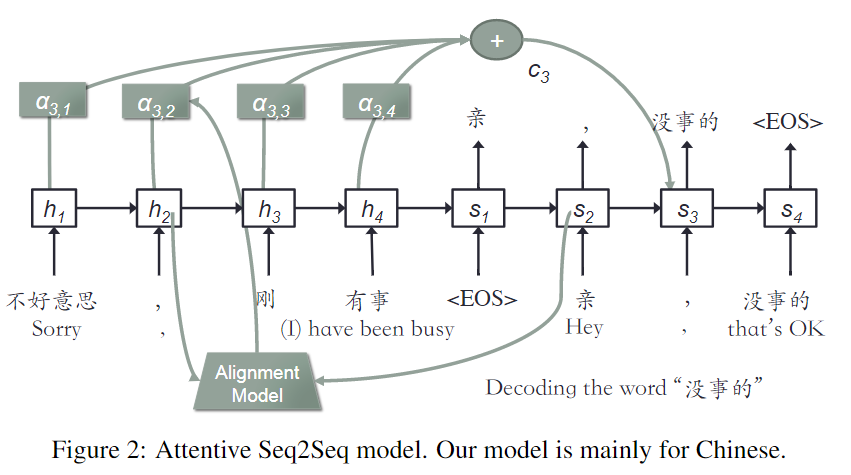
2. 数据padding
利用Tensorflow的Bucket Mechanism组织。选择(5,5),(5,10),(10,15),(20,30),(45,60)。
3. Softmax
训练时,softmax词表使用目标词汇+512个随机词汇。
4. BeamSearch 解码
每个时刻选择top-k(k=10)
打分模型,对所有候选答案计算一个得分,然后选择得分最高的答案。
生成式模型,在解码时会计算各个单词的概率。打分模型和生成式模型使用同一个模型。
打分模型,计算候选回答中每个单词在Decoder时出现的概率。再求平均值作为该回答的得分。
5个评价规则:
答案的三个级别:
top-1概率
小蜜主要包括:助手(Task)服务、客户服务、聊天服务。支持声音、文本输入,支持多轮对话。
1. 系统概览
Rules Parser 直接解析意图,失败则通过 Intention Classifier 解析意图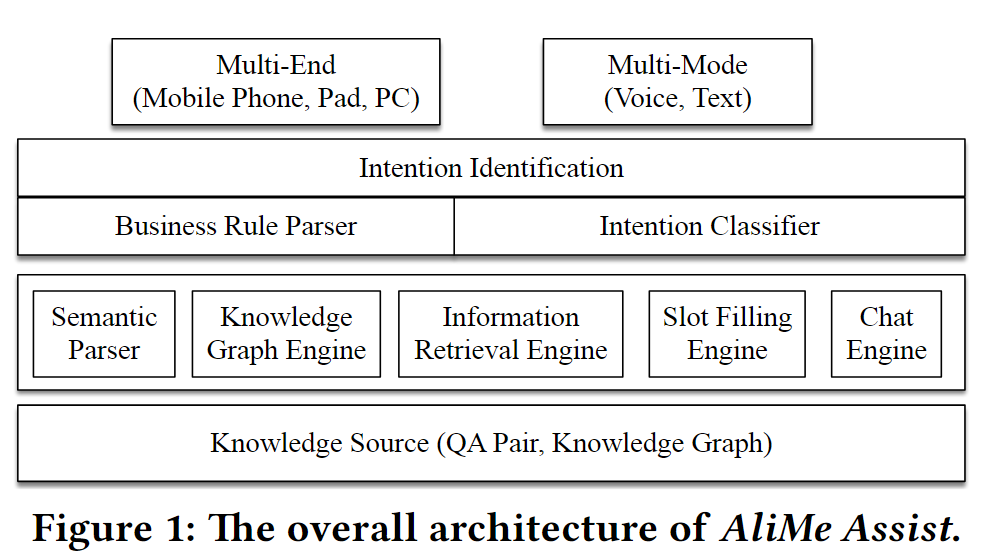
2. 问题的信息流
收到一个问句后
1 使用Business Rules Parser (trie-based)去解析q,如果匹配到一个模式
Slot Filling Engine(槽填充) 直接给答案Sales Promotion ,回答准备好的答案2 没有匹配到一个模式,给到意图分类器去识别意图,也就是识别出意图的场景(比如退货、退款、人工等)
3 如果场景是要转人工,则直接转人工
4 否则,q给到语义解析器,去识别是否包含语义标签(知识图谱中的实体)
IR去提取信息,如果有答案,则输出;如果没有,则转人工5 如果不包含语义标签
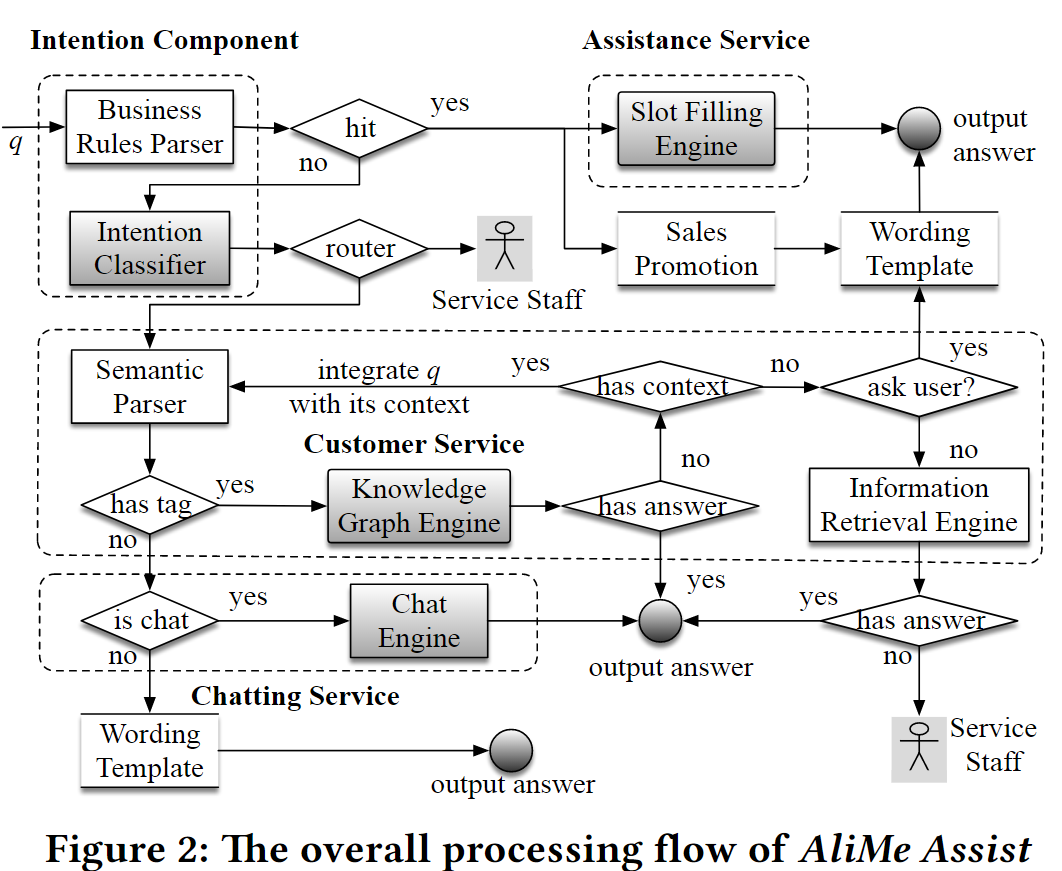
对一个问句结合上下文(前面的文件)去识别出它的意图。有3个大范围:
每一个大的范围都会进行商业细化。比如助手服务会包含订机票、手机充值。
意图分类由商业规则解析器和意图分类器组成。前者解析失败,才会执行后者
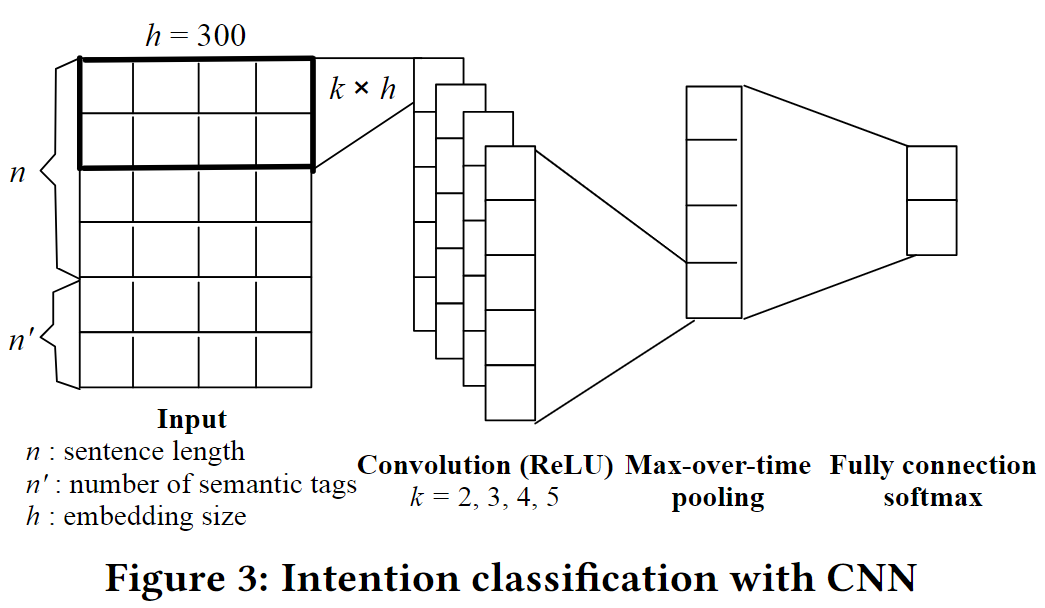
CNN,使用fast-text训练的词向量,fine tuned in CNN
CNN的好处
主要是以强化学习为中心的端到端的对话管理,由下面三个部分组成:
处理用户的输入
使用单层CNN对用户的问句进行编码,得到用户的意图语义向量
提取记录用户的slot信息
决定系统的操作,继续反问用户或者直接产生相应的实际操作
这也是强化学习的核心点,主要包含Episode,Reward,State和Action四个部分。 Episode 在某个场景下,识别出用户该场景的意图,则认为一个Episode开始;执行目的操作或者退出,则认为Episode结束 Reward 收集线上用户的反馈,并根据正负给出相应的Reward。特别注意要使用预训练的环境 State 结合当前新的Slot状态(Context)、历史的Slot信息和用户的当前问句信息,使用线性层+Softmax直接算出各个Actions的概率 Action Action就是系统可以给用户的一些反馈操作,比如继续询问用户、执行一个真实的操作等等。
该Taskbot的瓶颈主要是难以确定用户退出的原因,从而很难给出一些确定的惩罚。