协同注意力简介
📅 发表于 2018/03/15
🔄 更新于 2018/03/15
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#论文笔记
#注意力
#VQA
只是记录一下Co-Attention,后续再补上本篇论文的全部笔记吧。
论文:Hierarchical Question-Image Co-Attention for Visual Question Answering
我的相关笔记:Attention-based NMT阅读笔记和NLP中的Attention笔记
这里以VQA里面的两个例子记录一下Co-Attention。即图片和问题。
注意力
注意力机制就像人带着问题去阅读, 先看问题,再去文本中有目标地阅读寻找答案。
机器阅读则是结合问题和文本的信息,生成一个关于文本段落各部分的注意力权重,再对文本信息进行加权。
注意力机制可以帮助我们更好地去捕捉段落中和问题相关的信息。
协同注意力
协同注意力是一种双向的注意力, 再利用注意力去生成文本和问句的注意力。
协同注意力分为两种方式:
同时生成注意力交替生成注意力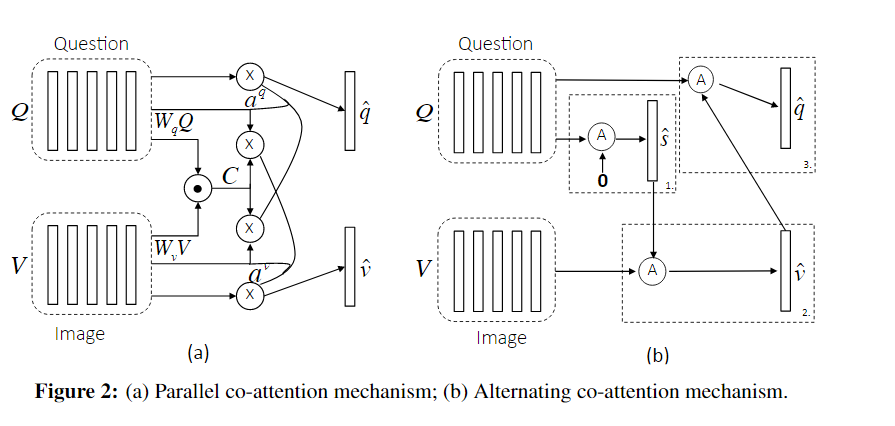
图片特征:
同时生成图片和问题的注意力。
先计算关联矩阵:
计算注意力权值
方法1:直接选择最大值。
方法2:把关联矩阵当做特征给到网络中,进行计算注意力权值,再进行softmax。更好
利用注意力和原特征向量去计算新的特征向量
交替生成图片和问题的注意力。
把问题归纳成一个单独向量
基于
基于
具体地,给一个attention guidance
注意力权值 :
新的注意力向量 (attended image (or question) vector) :
对应本例子如下: