机器翻译注意力机制及其PyTorch实现
📅 发表于 2017/10/13
🔄 更新于 2017/10/13
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#Attention
#自然语言处理
#深度学习
#论文笔记
#注意力
#机器翻译
前面阐述注意力理论知识,后面简单描述PyTorch利用注意力实现机器翻译
Effective Approaches to Attention-based Neural Machine Translation
在翻译的时候,选择性的选择一些重要信息。详情看这篇文章 。
本着简单和有效的原则,本论文提出了两种注意力机制。
Global
每次翻译时,都选择关注所有的单词。和Bahdanau的方式 有点相似,但是更简单些。简单原理介绍。
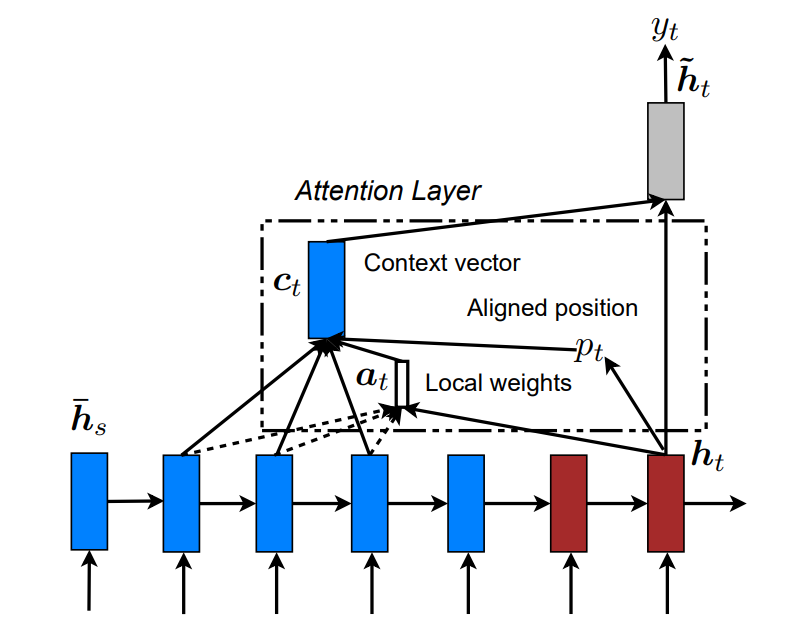
Local
每次翻译时,只选择关注一部分的单词。介于soft和hard注意力之间。(soft和hard见别的论文)。
优点有下面几个
在训练神经网络的时候,注意力机制应用十分广泛。让模型在不同的形式之间,学习对齐等等。有下面一些领域:
输入句子
神经机器翻译(Neural machine translation, NMT),利用神经网络,直接对
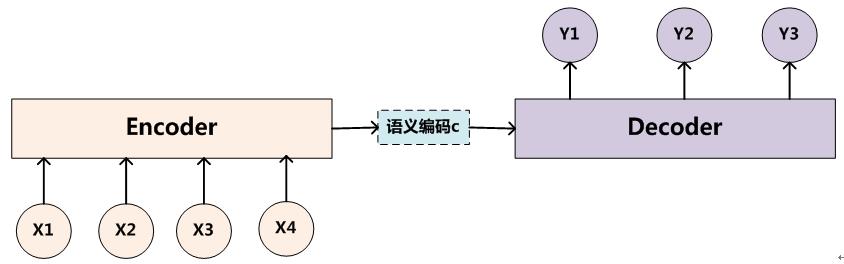
Encoder把输入句子
但是怎么选择Encoder和Decoder(RNN, CNN, GRU, LSTM),怎么去生成语义
结合Decoder上一时刻的隐状态
通过函数softmax,就可以得到翻译的目标单词
语义向量注意力机制。
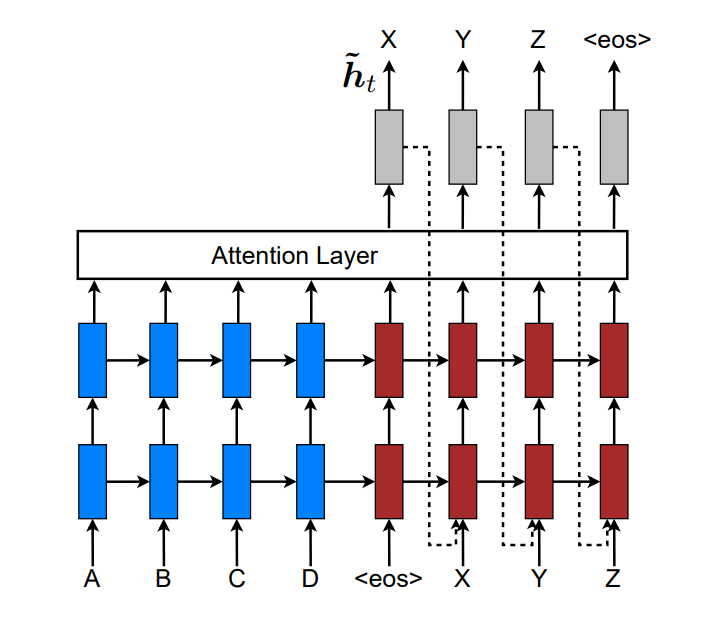
本论文采用stack LSTM的构建NMT系统。如下所示:
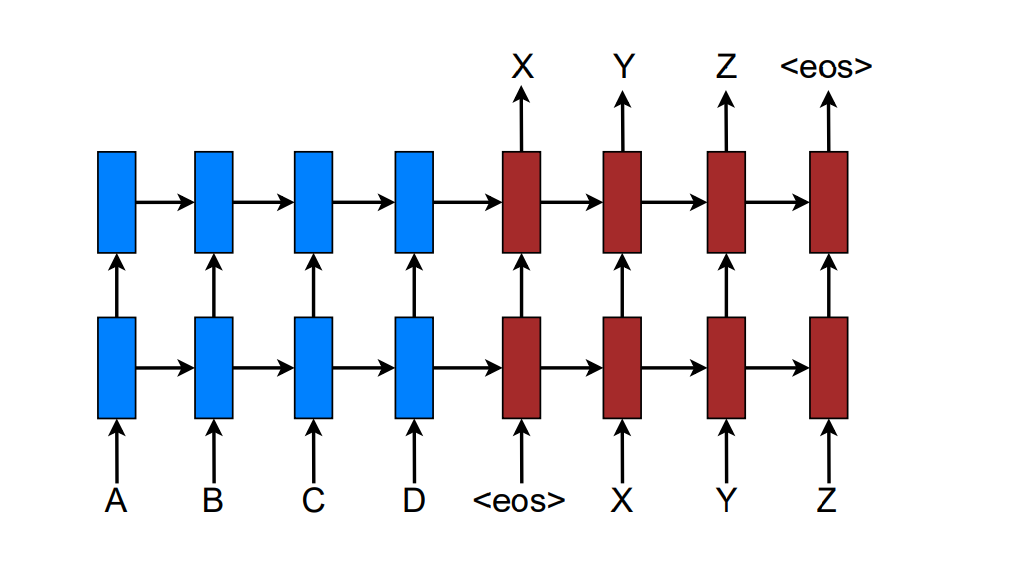
训练目标是
注意力模型广义上分为global和local。Global的attention来自于整个序列,而local的只来自于序列的一部分。
解码总体流程
Decoder时,在时刻
总体思路
在计算
对齐向量
结合上面的解码总体流程,有下面的流程
简单来说是
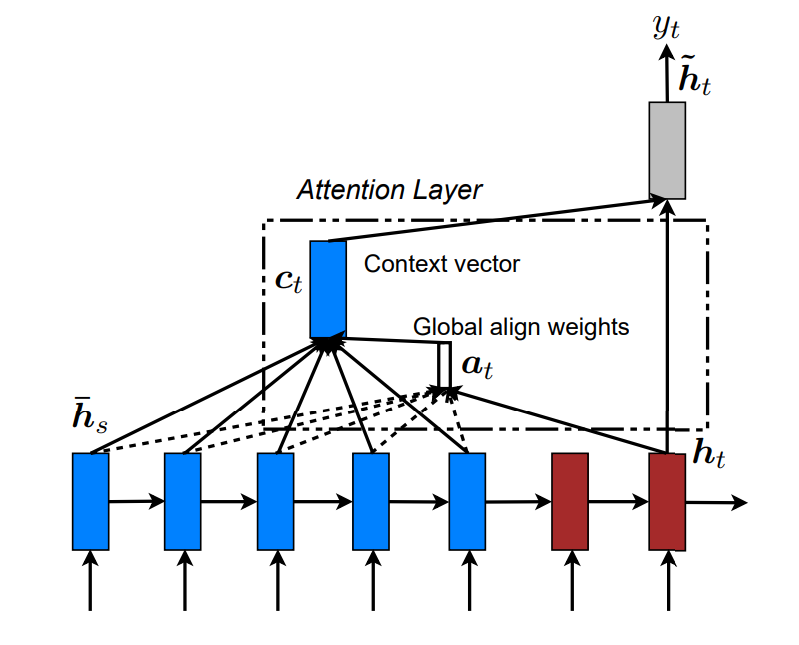
score计算
content-based的函数,有3种实现方式
缺点
生成每个目标单词的时候,都必须注意所有的原单词, 这样计算量很大,翻译长序列可能很难,比如段落或者文章。
在生成目标单词的时候,Local会选择性地关注一小部分原单词去计算
Soft和Hard注意
Soft 注意 :类似global注意,权值会放在图片的所有patches中。计算复杂。
Hard 注意: 不同时刻,会选择不同的patch。虽然计算少,但是non-differentiable,并且需要复杂的技术去训练模型,比如方差减少和强化学习。
Local注意
类似于滑动窗口,计算一个对齐位置
对齐位置选择
对齐位置的选择就很重要,主要有两种办法。
local-m (monotonic) 设置位置, 即以当前单词位置作为对齐位置
local-p (predictive) 预测位置
对齐向量计算
计算对齐概率:
前面的Global和Local两种方式中,在每一步的时候,计算每一个attention (实际上是指
在每一步的计算中,这些attention应该有所关联,当前知道之前的attention才对。实际是应该有个coverage set去追踪之前的信息。
我们会把当前的注意
这样有两重意义:
比较简单,使用GRU进行编码,使用outputs作为哥哥句子的编码语义。PyTorch RNN处理变长序列
def forward(self, input_seqs, input_lengths, hidden=None):
''' 对输入的多个句子经过GRU计算出语义信息
1. input_seqs > embeded
2. embeded - packed > GRU > outputs - pad -output
Args:
input_seqs: [s, b]
input_lengths: list[int],每个batch句子的真实长度
Returns:
outputs: [s, b, h]
hidden: [n_layer, b, h]
'''
# 一次运行,多个batch,多个序列
embedded = self.embedding(input_seqs)
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
outputs, hidden = self.gru(packed, hidden)
outputs, output_length = nn.utils.rnn.pad_packed_sequence(outputs)
# 双向,两个outputs求和
if self.bidir is True:
outputs = outputs[:, :, :self.hidden_size] + outputs[:, :, self.hidden_size:]
return outputs, hidden实际上就是attn_weights, 也就是输入序列对当前要预测的单词的一个注意力分配。
输入输出定义
Encoder的输出,所有语义encoder_outputs, [is, b, h]。 is=input_seq_len是输入句子的长度
当前时刻Decoder的decoder_rnn_output, [ts, b, h] 。实际上ts=1, 因为每次解码一个单词
def forward(self, rnn_outputs, encoder_outputs):
'''ts个时刻,计算ts个与is的对齐向量,也是注意力权值
Args:
rnn_outputs -- Decoder中GRU的输出[ts, b, h]
encoder_outputs -- Encoder的最后的输出, [is, b, h]
Returns:
attn_weights -- Yt与所有Xs的注意力权值,[b, ts, is]
'''计算得分
使用gerneral的方式,先过神经网络(线性层),再乘法计算得分
# 过Linear层 (b, h, is)
encoder_outputs = self.attn(encoder_outputs).transpose(1, 2)
# [b,ts,is] < [b,ts,h] * [b,h,is]
attn_energies = rnn_outputs.bmm(encoder_outputs)softmax计算对齐向量
每一行都是原语义对于某个单词的注意力分配权值向量。对齐向量实际例子
# [b,ts,is]
attn_weights = my_log_softmax(attn_energies)
return attn_weights新的语义也就是,对于翻译单词
输入输出
def forward(self, input_seqs, last_hidden, encoder_outputs):
'''
一次输入(ts, b),b个句子, ts=target_seq_len
1. input > embedded
2. embedded, last_hidden --GRU-- rnn_output, hidden
3. rnn_output, encoder_outpus --Attn-- attn_weights
4. attn_weights, encoder_outputs --相乘-- context
5. rnn_output, context --变换,tanh,变换-- output
Args:
input_seqs: [ts, b] batch个上一时刻的输出的单词,id表示。每个batch1个单词
last_hidden: [n_layers, b, h]
encoder_outputs: [is, b, h]
Returns:
output: 最终的输出,[ts, b, o]
hidden: GRU的隐状态,[nl, b, h]
attn_weights: 对齐向量,[b, ts, is]
'''当前时刻Decoder的隐状态
输入上一时刻的单词和隐状态,通过GRU,计算当前的隐状态。实际上ts=1
# (ts, b, h), (nl, b, h)
rnn_output, hidden = self.gru(embedded, last_hidden)计算对齐向量
当前时刻的隐状态 rnn_output 和源句子的语义encoder_outputs,计算对齐向量。对齐向量
每一行都是原句子对当前单词(只有一行)的注意力分配。
# 对齐向量 [b,ts,is]
attn_weights = self.attn(rnn_output, encoder_outputs)
# 如
[0.1, 0.2, 0.7]计算新的语义
原语义和原语义对当前单词分配的注意力,计算当前需要的新语义。
# 新的语义
# [b,ts,h] < [b,ts,is] * [b,is,h]
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))结合新语义和当前隐状态预测新单词
# 语义和当前隐状态结合 [ts, b, 2h] < [ts, b, h], [ts, b, h]
output_context = torch.cat((rnn_output, context), 2)
# [ts, b, h] 线性层2h-h
output_context = self.concat(output_context)
concat_output = F.tanh(output_context)
# [ts, b, o] 线性层h-o
output = self.out(concat_output)
output = my_log_softmax(output)
return output# 1. 对齐向量
# 过Linear层 (b, h, is)
encoder_outputs = self.attn(encoder_outputs).transpose(1, 2)
# 关联矩阵 [b,ts,is] < [b,ts,h] * [b,h,is]
attn_energies = rnn_outputs.bmm(encoder_outputs)
# 每一行求softmax [b,ts,is]
'''每一行都是原语义对当前单词的注意力分配向量'''
attn_weights = my_log_softmax(attn_energies)
# 2. 新语义
# 新的语义 [b,ts,h] < [b,ts,is] * [b,is,h]
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# 3. 新语义和当前隐状态结合,输出
# 语义和输出 [ts, b, 2h] < [ts, b, h], [ts, b, h]
output_context = torch.cat((rnn_output, context), 2)