Word2vec之数学模型
📅 发表于 2017/11/03
🔄 更新于 2017/11/03
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#word2vec
#自然语言处理
Word2vec有两种模型:CBOW和Skip-gram,有两种训练方法:Hierarchical Softmax和Negative Sampling。偏数学公式推导
常用公式:
n-gram模型。当然,我们使用神经概率语言模型。
对于统计语言模型来说,一般利用最大似然,把目标函数设为:
一般使用最大对数似然,则目标函数为:
其实概率
有了函数
一个二元对
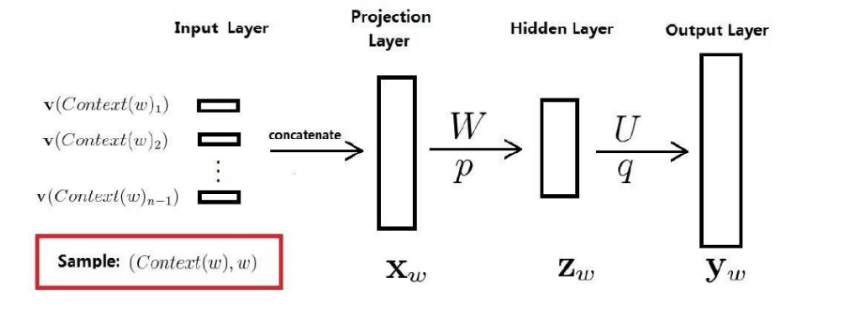
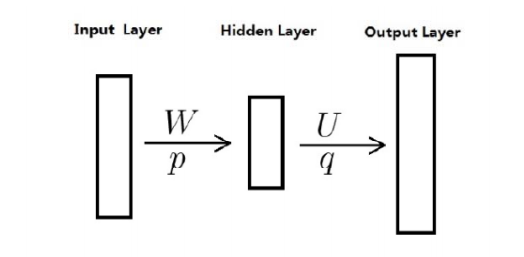
但是一般会减少一层,如下图:(其实是去掉了隐藏层,保留了投影层,是一样的)
窗口大小是
再对
优点
有两种词向量,一种是one-hot representation,另一种是Distributed Representation。one-hot太长了,所以DR中把词映射成为相对短的向量。不再是只有1个1(孤注一掷),而是向量分布于每一维中(风险平摊)。再利用欧式距离就可以算出词向量之间的相似度。
传统可以通过LSA(Latent Semantic Analysis)和LDA(Latent Dirichlet Allocation)来获得词向量,现在也可以用神经网络算法来获得。
可以把一个词向量空间向另一个词向量空间进行映射,就可以实现翻译。
两种模型都是基于下面三层模式(无隐藏层),输入层、投影层和输出层。没有hidden的原因是据说是因为计算太多了。
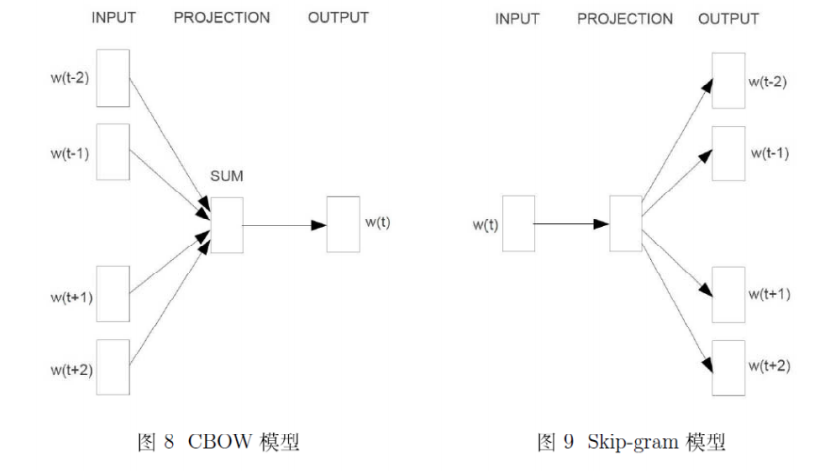
CBOW和Skip-gram模型:
一共有
窗口大小设为
输入层 是上下文单词的词向量。(初始随机,训练过程中逐渐更新)
投影层 就是对上下文词向量进行求和,向量加法。得到单词
输出层 从
因为词语太多,用softmax太慢了。多分类实际上是多个二分类组成的,比如SVM二叉树分类:
这是一种二叉树结构,应用到word2vec中,被称为Hierarchical Softmax。CBOW完整结构如下:
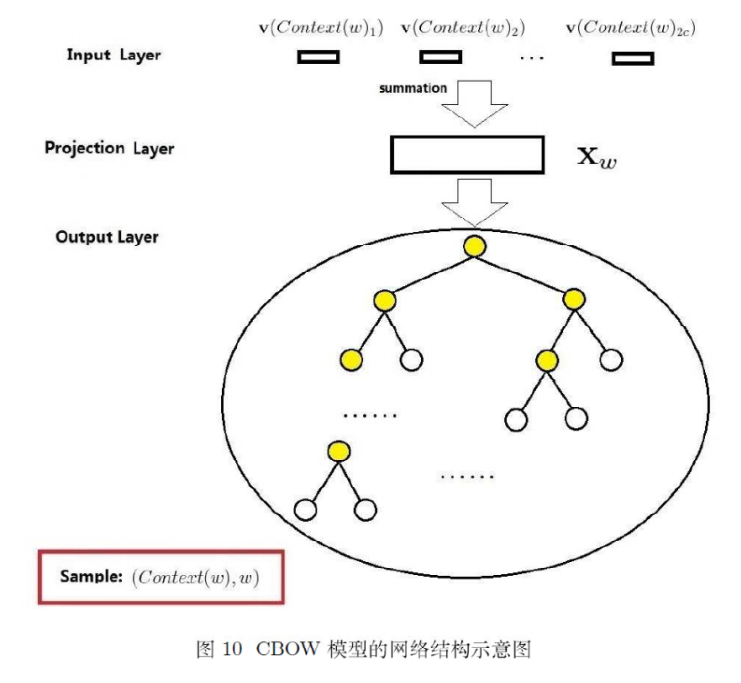
每个叶子节点代表一个词语
哈夫曼树很简单。每次从许多节点中,选择权值最小的两个合并,根节点为合并值;依次循环,直到只剩一棵树。
比如“我 喜欢 看 巴西 足球 世界杯”,这6个词语,出现的次数依次是15, 8, 6, 5, 3, 1。建立得到哈夫曼树,并且得到哈夫曼编码,如下:
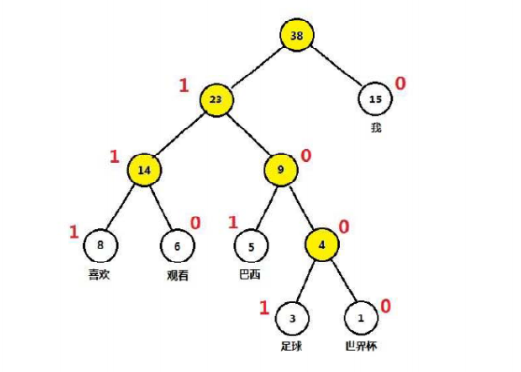
引入一些符号:
看一个例子:
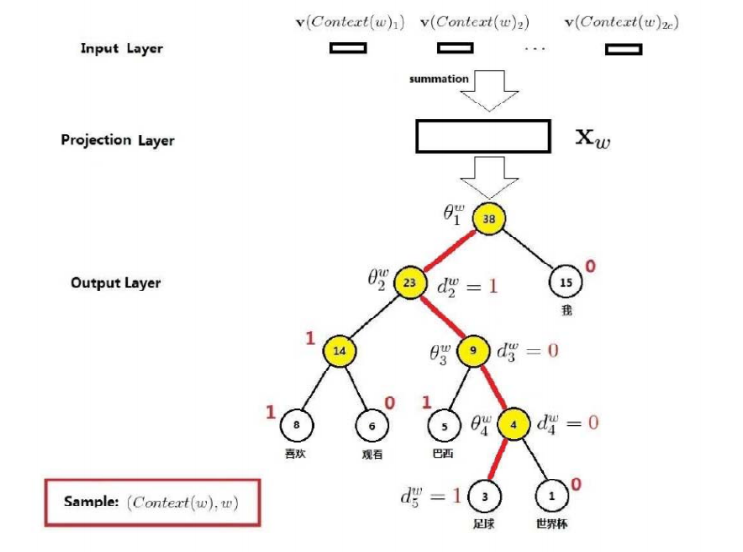
约定编码为1是负类,为0是正类。即左边是负类,右边是正类。
每一个节点就是一个二分类器,是逻辑回归(sigmoid)。其中
那么从根节点到达足球的概率是:
目标函数
从根节点到每一个单词
其中每个节点的概率是,与各个节点的参数和传入的上下文向量和
写成指数形式是
则上下文推中间单词的概率,即目标函数:
对数似然函数
对目标函数取对数似然函数是:
简写:
怎样最大化对数似然函数呢,可以最大化每一项,或者使整体最大化。尽管最大化每一项不一定使整体最大化,但是这里还是使用最大化每一项
sigmoid函数的求导:
注意:
Skip-gram模型是根据当前词语,预测上下文。网络结构依然是输入层、投影层(其实无用)、输出层。如下:
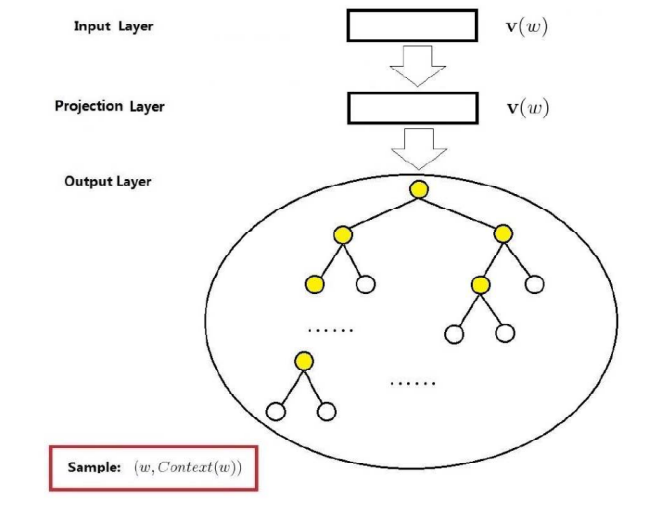
输入一个中心单词的词向量
目标函数
所以
与上面同理,
下文
对数似然函数
同样,简写每一项为
然后就是,分别对
Negative Sampling简称NEG,是Noise Contrastive Estimation(NCE)的一个简化版本,目的是用来提高训练速度和改善所得词向量的质量。
NEG不使用复杂的哈夫曼树,而是使用随机负采样,大幅度提高性能,是Hierarchical Softmax的一个替代。
NCE 细节有点复杂,本质上是利用已知的概率密度函数来估计未知的概率密度函数。简单来说,如果已知概率密度X,未知Y,如果知道X和Y的关系,Y也就求出来了。
在训练的时候,需要给正例和负例。Hierarchical Softmax是把负例放在二叉树的根节点上,而NEG,是随机挑选一些负例。
对于一个单词
定义
设集合
单词
简写为:
要最大化目标函数
观察
每个词都是这样,对于整个语料库的所有词汇,将
简写每一步
计算
更新每个单词的训练参数
对每个单词更新词向量
H给单词
中心单词是
下面
简写为
对于
对于
那么,对于整个预料,要最大化:
对G取对数,最终的目标函数就是:
取
分别对
更新每个单词的训练参数
对每个单词更新词向量