Word2vec之总体介绍
📅 发表于 2017/11/13
🔄 更新于 2017/11/13
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
自然语言处理
#word2vec
#cbow
#skip-gram
#负采样
cs224n笔记,word2vec总体介绍,包括CBOW和Skip-gram,负采样训练
把词汇变成词向量。
| 类别1 | 类别2 | |
|---|---|---|
| 算法 | CBOW,上下文预测中心词汇 | Skip-gram,中心词汇预测上下文 |
| 训练方法 | 负采样 | 哈夫曼树 |
两种句子:
The cat jumped over the puddle。 概率高,有意义。stock boil fish is toy 。概率低,没意义。二元模型
一个句子,有
缺点
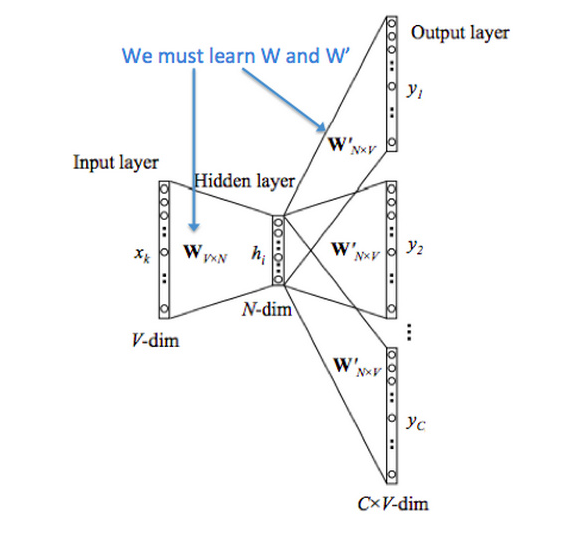
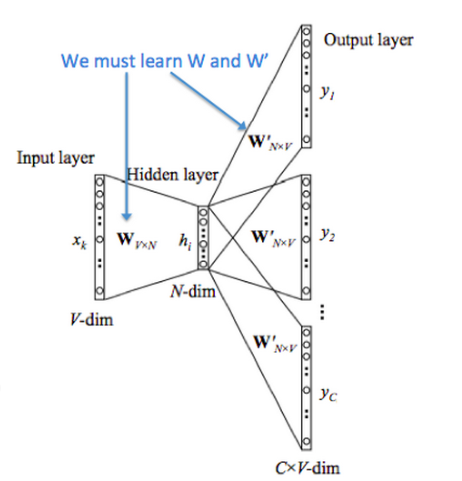
给上下文The cat _ over the puddle ,预测jump 。对于每个单词,学习两个向量:
输入向量 ,(上下文单词)输出向量 , (中心单词)输入与输出
1 上下文单词onehot向量
one-hot向量的表达:
2 上下文单词向量
3 平均上下文词向量
4 输出单词与上下文计算得分向量
5 得分向量转为概率
$\hat y = \mathrm{softmax}(z) \in \mathbb R^V $
6 真实预测概率对比
预测的概率向量交叉熵比较算出loss。
使用交叉熵计算loss,损失函数如下:
由于中心单词
交叉熵很好是因为
最终损失函数:
再使用SGD方法去更新相关的两种向量
给中心单词 jump,预测上下文The cat _ over the puddle 。
输入中心单词
1 中心单词onehot向量
2 中心单词词向量
3 中心词与其他词的得分向量
4 得分向量转为概率
概率
5 预测真实概率对比
预测概率
与CBOW不同的是,Skip-gram做了一个朴素贝叶斯条件假设,所有的输出上下文单词都是独立的。
一样,使用SGD去优化U和V。
损失函数实际上是交叉熵:
每次计算都会算整个词频相关。只需关心:目标函数、梯度、更新规则。
对于一对中心词和上下文单词标签如下:
用sigmoid表示标签函数:
选取合适的
最大化概率也就是最小化负对数似然
为中心单词
给上下文向量
原始loss
负采样loss
给中心单词
原始loss
负采样loss