谷歌RNN翻译模型
📅 发表于 2017/10/17
🔄 更新于 2017/10/17
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
论文笔记
#论文笔记
#神经机器翻译
#RNN
谷歌神经机器翻译系统,Transformer之前最强的基于RNN的翻译模型
神经机器翻译是自动翻译的端到端的学习方法,克服了传统的基于词典翻译的许多缺点。但仍然有以下的缺点
神经机器翻译(NMT)是自动翻译的端到端的学习方法。NMT一般由两个RNN组成,分别处理输入句子和生成目标句子。一般会使用注意力机制,会有效地去处理长句子。
NMT避开了传统基于短语的翻译模型的很多缺点。但是,在实际中,NMT的准确度要比基于短语的翻译模型更差些。
NMT有3个主要的缺点:训练和推理速度太慢,不能有效处理稀有词汇,有时不能完全翻译原句子。
训练和推理速度太慢
训练大数据集,需要大量时间和资源;反馈太慢周期太长。加了一个小技巧,看结果要等很长时间。推理翻译的时候,要使用大量的参数去计算,也很慢。
不能有效处理稀有词汇
有两个方法去复制稀有单词:
copy model但是效果都不是很好,都不可靠,不同语言的对齐效果差;在网络很深的时候,注意力机制的对齐向量也不稳定。而且,简单的复制过去也不是最好的办法,比如需要直译的时候。
不能完整翻译整个句子
不能覆盖整个输入句子的内容,然后会导致一些奇怪的翻译结果。
采用的模型:深层LSTM 、Encoder8层、Decoder8层 。我的LSTM笔记。
各层之间使用残差连接促进梯度流,顶层Enocder到底层Decoder使用注意力连接,提高并行性。
进行翻译推断的时候,使用低精度算法,去加速翻译。
处理稀有词汇:使用sub-word单元,也称作wordpieces方法。把单词划分到有限的sub-word (wordpieces)单元集合,输入输出都这样。sub-word结合了字符分割模型的弹性和单词分割模型的效率。
Beam Search 使用长度规范化和覆盖惩罚。覆盖惩罚就是说,希望,翻译的结果句子,尽量多地包含输入句子中的所有词汇。
使用强化学习去优化模型, 优化翻译的BLEU 分数。
有很多先进的技术来提高NMT,下面这些都有论文的。
架构
有3个模块:Encoder,Decoder,Attention。
Encdoer:把句子转换成一系列的向量,每一个向量代表一个输入词汇(符号)。
Decoder:根据这些向量,每一时刻会生成一个目标词汇,直到EOS。
Attention:连接Encoder和Decoder,在解码的过程中,可以让Decoder有权重的有选择的关注输入句子的部分区域。
符号说明
Encoder
输入句子和目标句子组成一个Pair
Encoder其实就是一个转换函数,得到
使用链式条件概率可得到翻译概率
Decoder
在翻译
Decoder是由RNN+Softmax构成的。会得到一个隐状态
Attention
在之前的文章里有介绍论文 和 通俗理解,其实就是影响力模型。原句子的各个单词对翻译当前单词分别有多少的影响力,也叫作对齐概率吧。使用decoder-RNN的输出
时刻
有3个符号定义:
整体详细计算的流程,如下面的公式:
计算打分的函数即
系统架构图说明
架构图如下
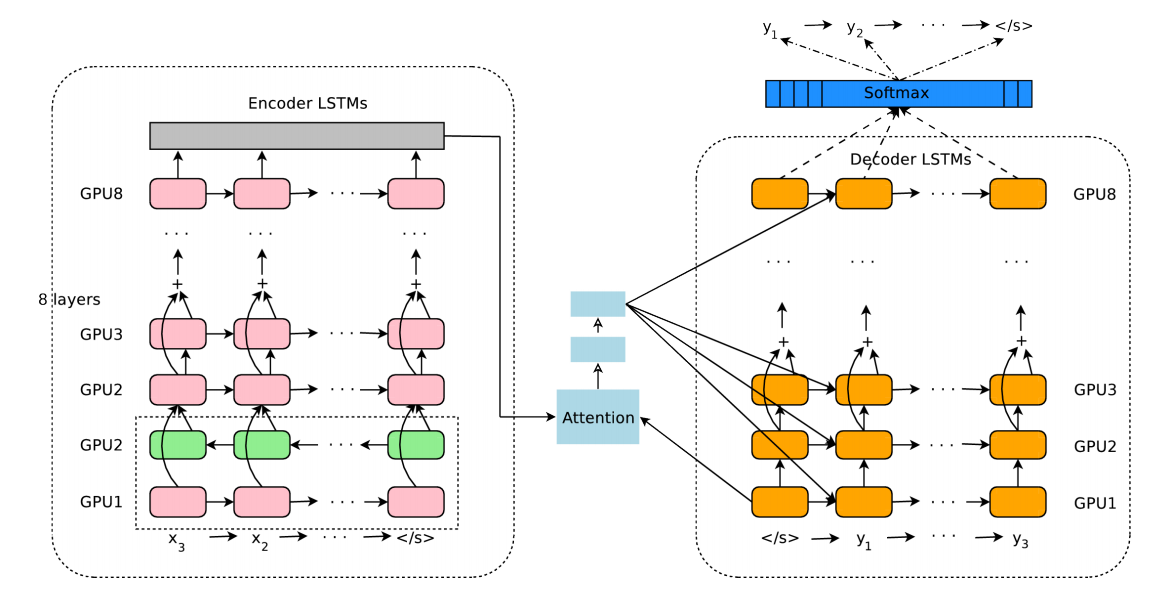
Encoder是8层的LSTM:最底层是双向的LSTM,得到两个方向的信息;上面7层都是单向的。Encoder和Decoder的残差连接都是从第3层开始的。
训练时,会让Encoder最底层的双向的LSTM开始训练,完成之后,再训练别的层,每层都用单独的GPU。
为了提高并行性,Decoder最底层,只是为了用来计算Attention Context。带注意力的语义计算好之后,会单独发给其它的各个层。
经验说明
实验结果得到,要想NMT有好效果,Encoder和Decoder的网络层数一定要够深,才能发现2种语言之间的细微异常规则。和这个同理,深层LSTM比浅层LSTM明显效果好。每加一层,会大约减少10%的perplexity。所以使用deep stacked LSTM。
残差网络讲解 。
虽然深层LSTM比浅层LSTM效果好,但是如果只是简单堆积的话,只在几个少数层效果才可以。经过试验,4层的话估计效果还可以,6层大部分都不好,8层的话,效果就相当差了。这是因为网络会变得很慢和很难训练,很大程度是因为梯度爆炸和梯度消失的问题。
根据在中间层和目标之间建立差别的思想,引入残差连接,如下图右边所示。其实就是把之前层的输入和当前的输出合并起来,作为下一层的输入。
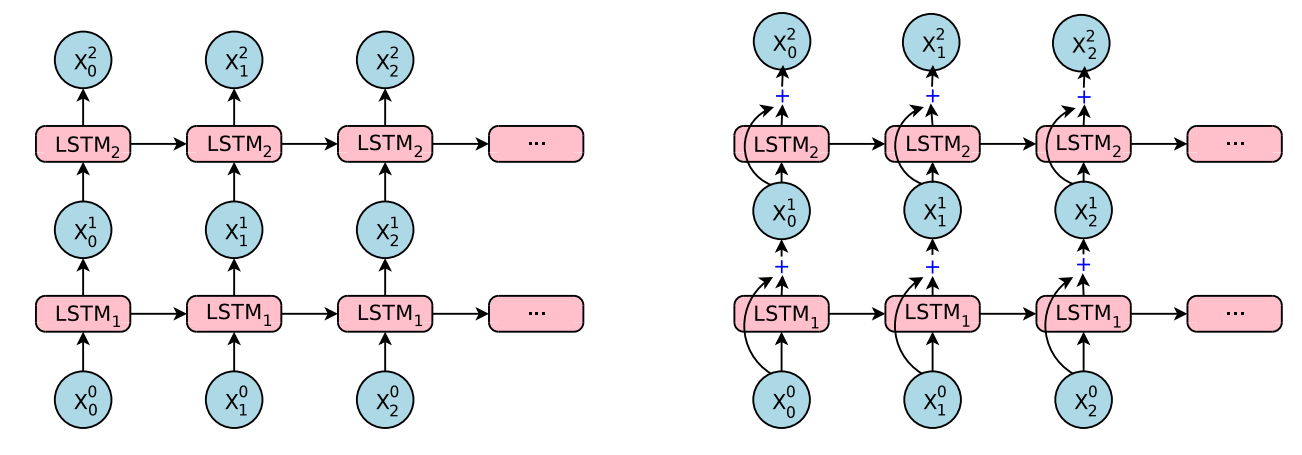
一些参数和符号说明,一下均是时刻
那么
残差连接可以在反向传播的时候大幅度提升梯度流,这样就可以训练很深的网络。
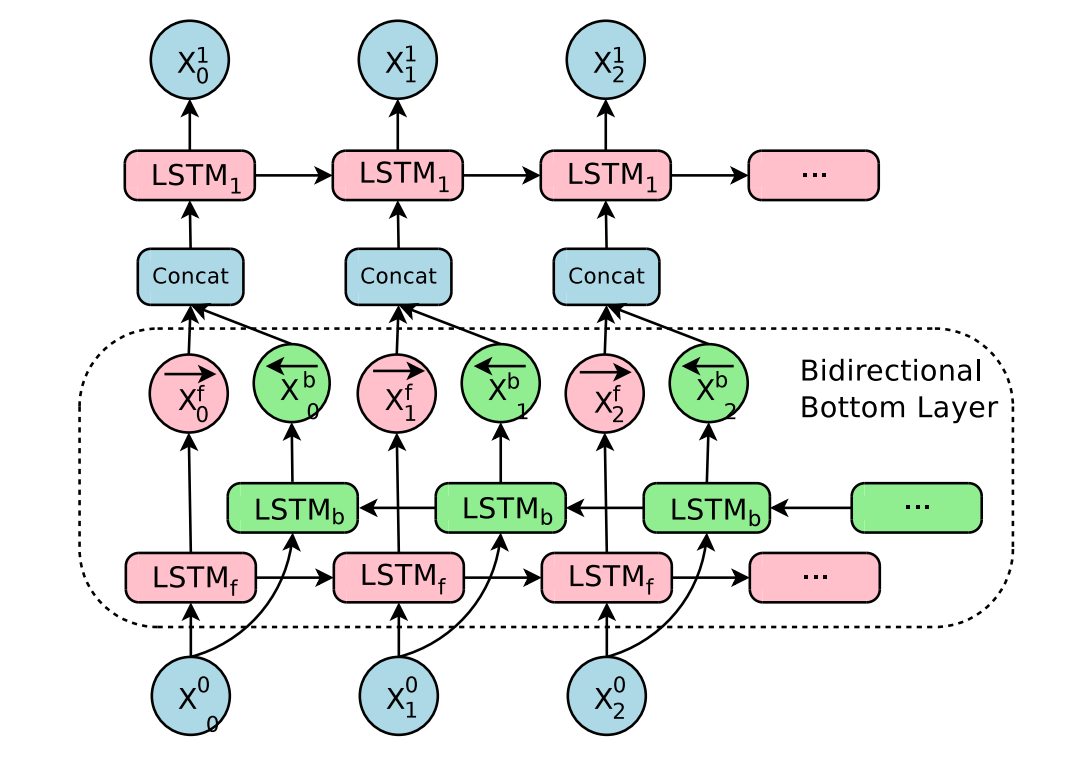
一般输入的句子是从左到右,输出也是。但是由于语言的复杂性,有助于翻译的关键信息可能在原句子的不同地方。为了在Encoder中的每一个点都有最好的上下文语义,所以需要使用双向LSTM。
这里只在Encoder的最底层使用双向LSTM,其余各层均使用单向的LSTM。双向LSTM训练完成之后,再训练别的层。
模型很复杂,所以使用模型并行和数据并行,来加速。
数据并行
数据并行很简单,使用大规模分布式深度网络(Downpour SGD) 同时训练
模型并行
除了数据并行以外,模型并行也会加速每个副本的梯度计算。Encoder和Decoder会进行深度去划分,一般每一层会放在一个单独的GPU上。除了第一层的Encoder之外,所有的层都是单向的,所以第
并行带来的约束
由于要并行计算,所以我们不能够在Encoder的所有层上使用双向LSTM。因为如果使用了双向的,上面层必须等到下面层前向后向完全训练好之后才能开始训练,就不能并行计算。在Attention上,我们也只能使用最顶层的Encoder和最底层的Decoder进行对齐计算。如果使用顶层Encoder和顶层Decoder,那么整个Decoder将没有任何并行性,也就享受不到多个GPU的快乐了。
一般NMT都是的词汇表都是定长的,但是实际上词汇表却是开放的。比如人名、地名和日期等等。一般有两种方法去处理OOV(out-of-vocabulary)单词,复制策略和sub-word单元策略。GNMT是使用sub-word单元策略,也称为wordpiece模型。
复制策略
有下面几种复制策略
sub-word单元
比如字符,混合单词和字符,更加智能的sub-words。