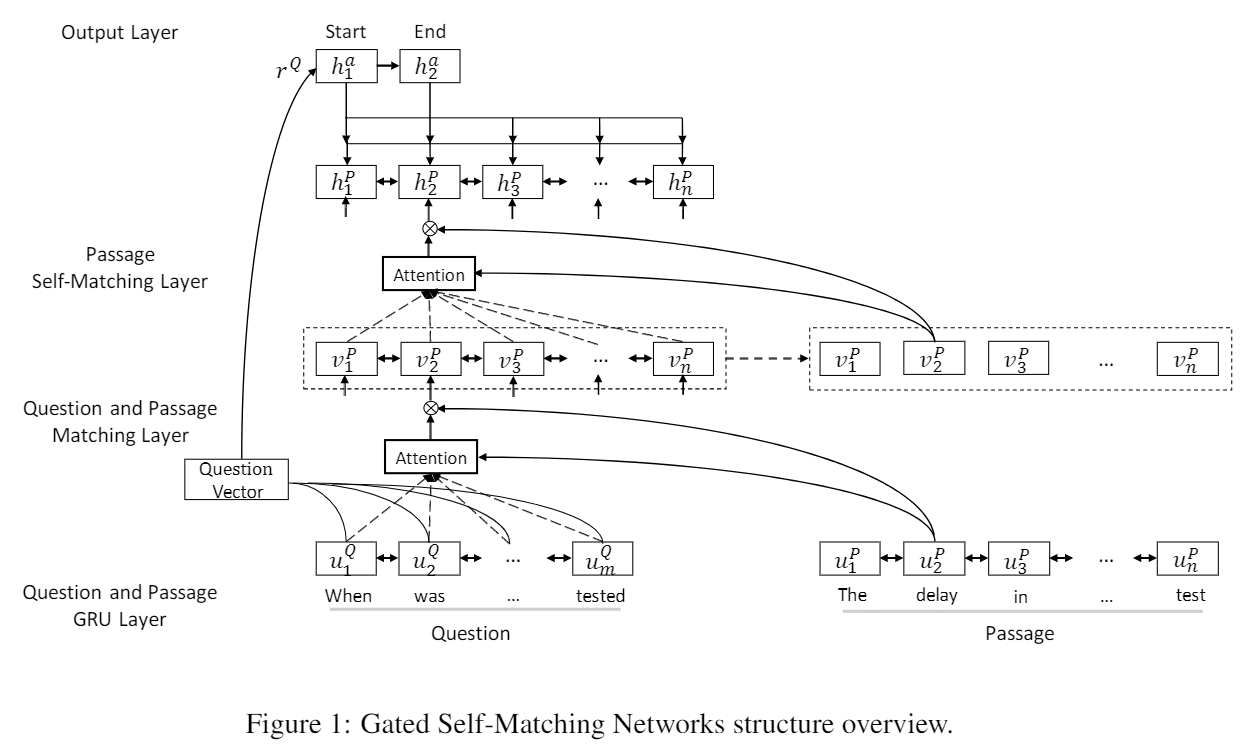
R-Net (Gated Self-Matching Networks)
📅 发表于 2018/05/15
🔄 更新于 2018/05/15
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
机器阅读理解
#机器阅读
#论文笔记
#Gated Attention RNN
#Self-Matching
#RNet
#Pointer Network
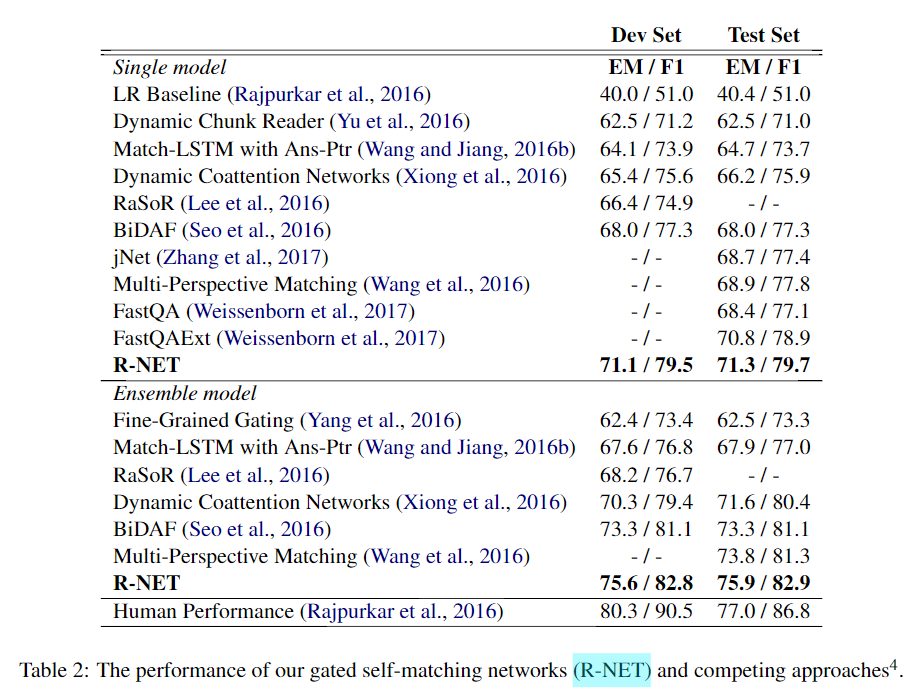
微软亚研院和北大的阅读理解模型R-Net。
- Gated Attention-based RNN 来获得question-aware passage representation,即编码P
- Self-matching Attention来修正编码P,即P与自己做match,有效从全文中编码信息
- Pointer Network预测开始和结束位置
论文地址:
1. Match-LSTM
Match-LSTM and Answer Pointer笔记
2. Dynamic Coatteion Network
DCN笔记。Coattention同时处理P和Q,动态迭代预测答案的位置。
3. Bi-Directional Attention Flow Network
1. BiRNN 分别编码P和Q
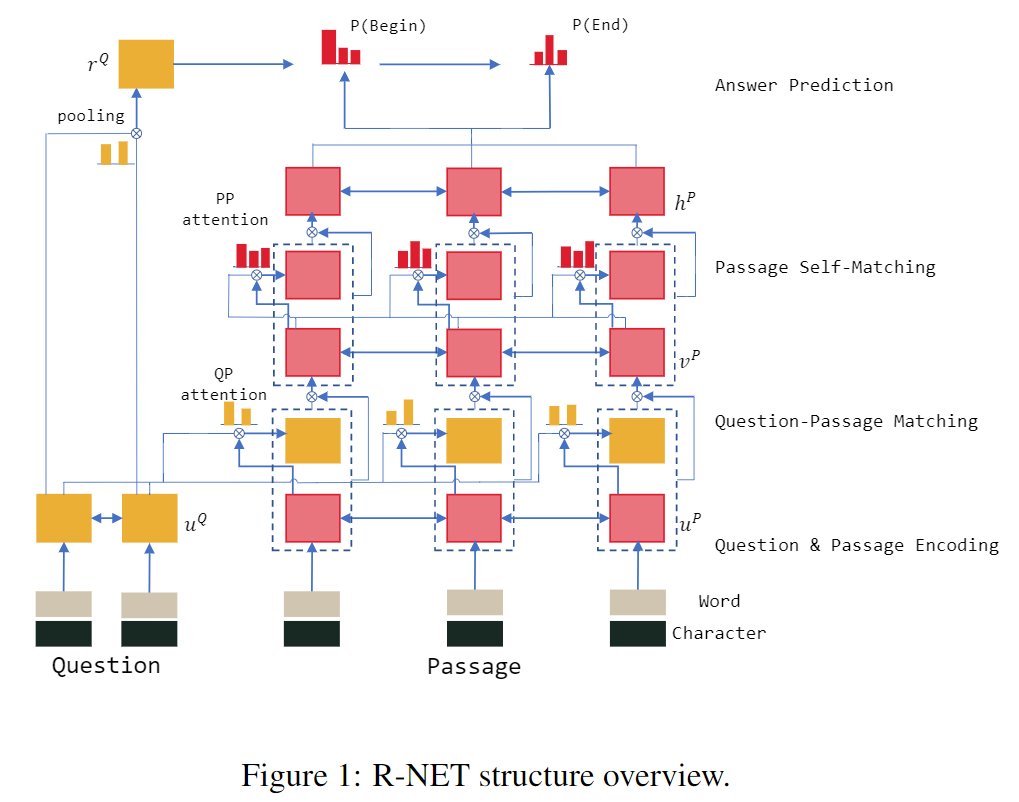
分别编码Question和Passage
2. gated matching layer 编码Q-Aware的Passage
Gated Attention-based RNN。在Match-LSTM上添加了门机制。
3. self-matching layer
再次从整个Passage中提取信息。它的缺点:
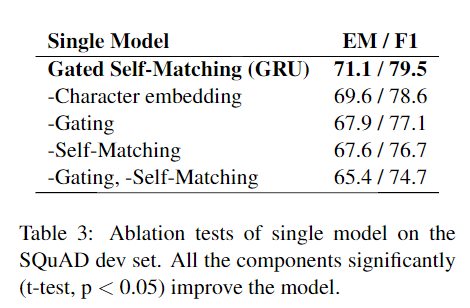
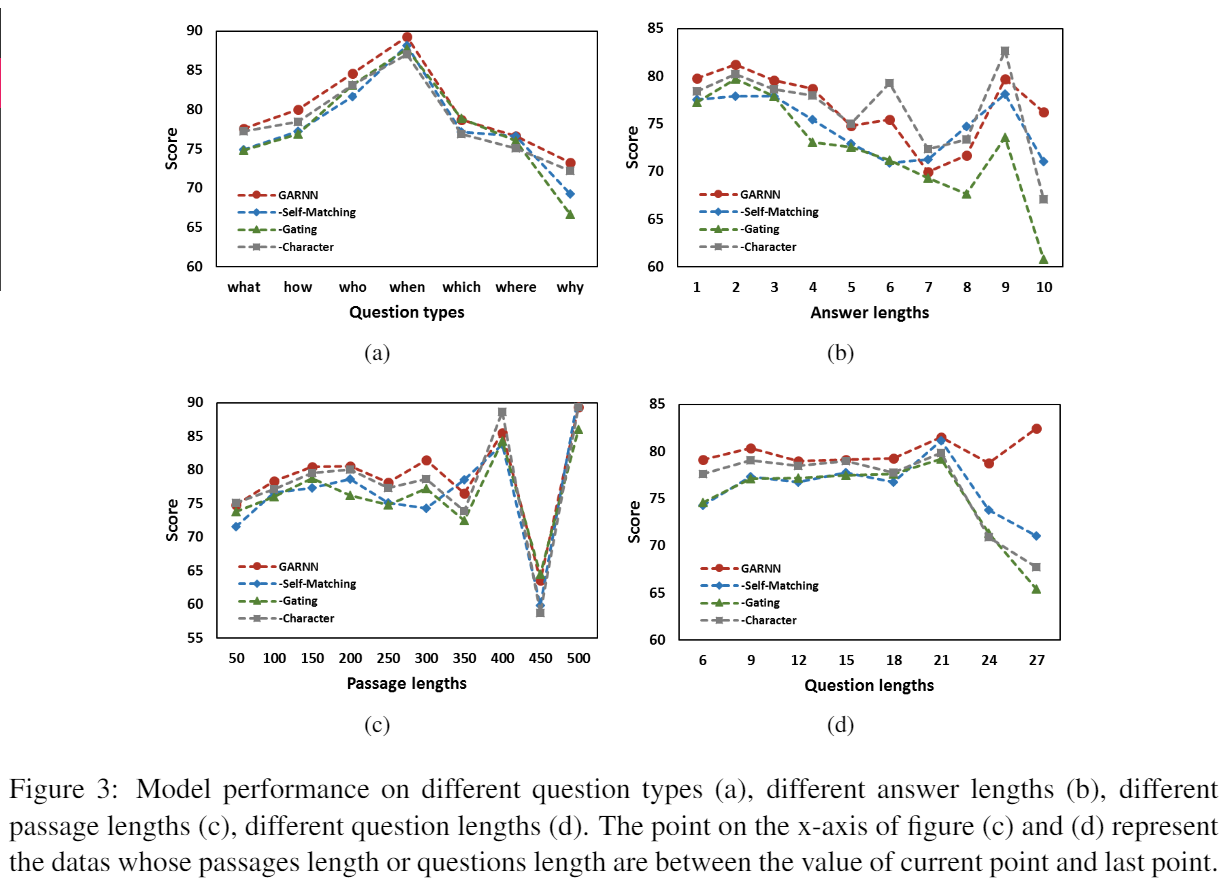
解决方法:对P做self-match。使用Gated Attention-based RNN对P和P自己做match。
4. pointer-network
BiRNN,GARNN(P+Q),GARNN-Selfmatch(P+P),Pointer Network
词向量和字符向量
词向量:
字符向量:
字符向量,使用RNN,用每个单词的最后时刻的隐状态,作为字符向量。有助于处理OOV词汇。
编码Question和Passage
要基于U(
1. Attention RNN
doc 2 query attention
attention pooling vector of the whole question
实际上:
注意力$\mathbf c_t $和上一时刻隐状态
每个
2. Match RNN
Match-LSTM。在输入RNN计算时,把当前
3. Gated Attention-based RNN
用门机制去控制每个
GARNN的门机制
模拟了阅读理解中,只有最终得到了question-aware passage representation :
为了充分利用Passage的上下文信息。
对P做self-match。使用Gated Attention-based RNN对P和P自己做match。
注意力计算
RNN计算
Self-Matching根据当前p单词、Q,从整个Passage中提取信息。最终得到Passage的表达
其实就是个Pointer Network的边界模型,预测起始位置
1. 基于Q计算初始隐状态
初始hidden state是Question的attention-pooling vector
基于Q的编码和一组参数
2. RNN计算开始位置和结束位置
计算t时刻的attention-pooling passage (注意力
RNN前向计算
基于注意力权值去选择位置
数据集
训练集80%,验证集10%,测试10%
分词
斯坦福的CoreNLP中的tokenizer
词向量
预训练好的Glove Vectors。训练中保持不变。
字符向量
单层的双向GRU,末尾隐状态作为该单词的字符向量
BiRNN编码Question和Passage
3层的双向GRU
Hidden Size大小
所有都是75
Dropout
每层之间的DropOut比例是0.2
优化器
AdaDelta。初始学习率为1,衰减率