语言模型重要组件
📅 发表于 2025/07/04
🔄 更新于 2025/07/04
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
llm
#Attention
#Batch Norm
#Layer Norm
#PreLorm
#PostNorm
#RMSNorm
#QK-Norm
#RoPE
#GeLU
#TopK
#TopP
#Temperature
整体移动至页面 LLM Attention 系列。
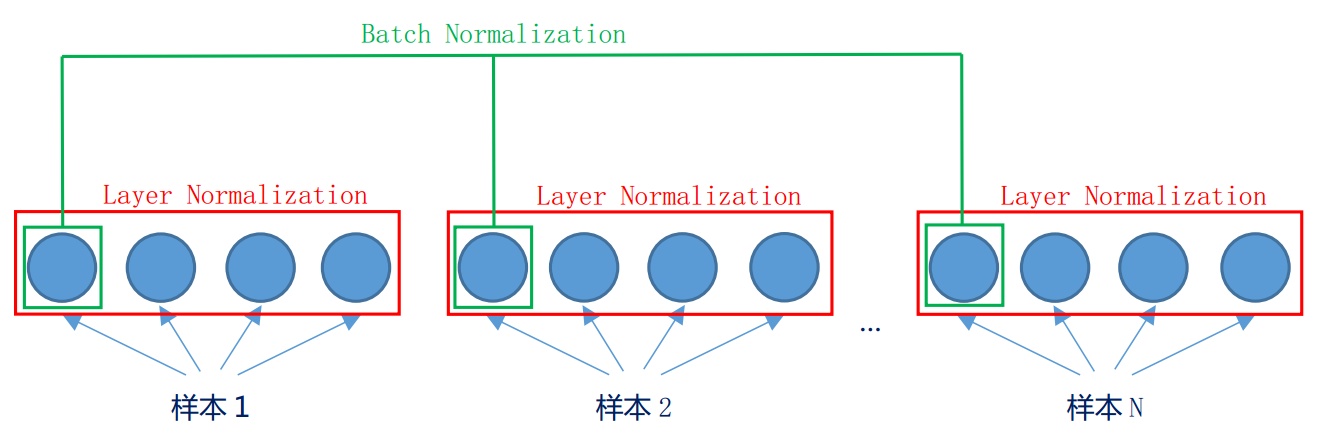
BN定义
让数据标准化到(0, 1)正态分布,避免发生梯度消失保留原有学习来的特征BN优点
存在的问题
定义
对同一层所有神经元的输入 / 某条数据(tensor)的多个维度 做归一化优点
Pre-LN
更稳定。 防止梯度爆炸或消失:一部分参数直接加在后面,没有正则化,可在反向时防止梯度消失或爆炸。会削弱模型深度:梯度可以直接通过残差连接抄近道,不完全流经每一层Post-LN:
性能可能更好:迫使信息和梯度必须流过每1层,完全利用模型深度对参数正则化更强、模型收敛性更好训练不稳定、很容易失败。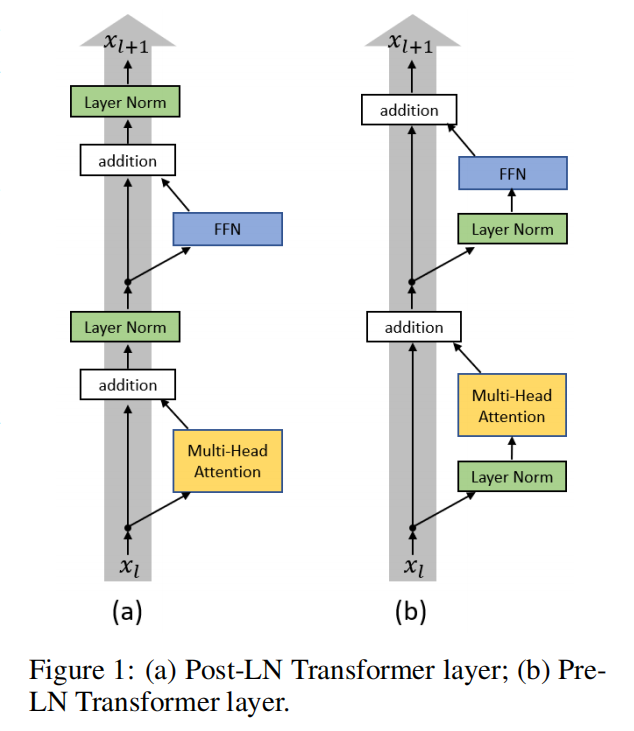
定义
LayerNorm(x * alpha + f(x))优点
RMS Norm
针对LayerNorm改进,主要区别在于去掉了减去均值的部分,采用根均方。
RMS 操作 (Root Mean Squre):
pRMS Norm
Instance Norm
Group Norm
RMSNorm,用在Q、K之前。归一化,减少训练中数值不稳定性。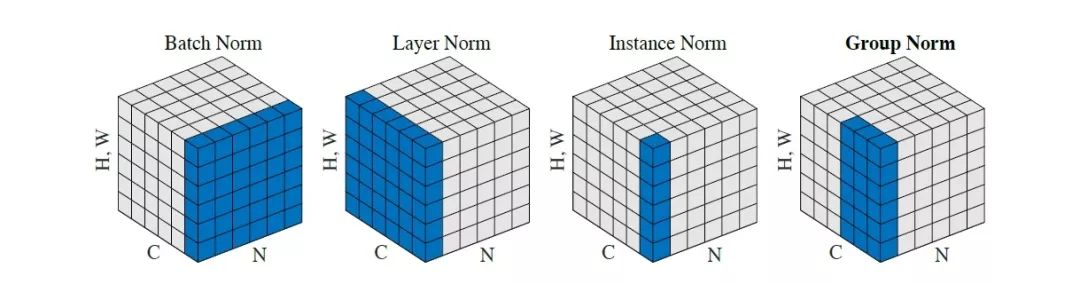
两个全连接层+激活函数:
接在attention输出后面,带有激活函数,做复杂非线性变换,对最终性能非常重要。
增加FFN的维度有利于提升效果,一般比attention层维度大。
注:后期多用GeLU。ReLU 更适用于CNN,而 GeLU FFN。
Sigmoid、Tanh、ReLU、Maxout。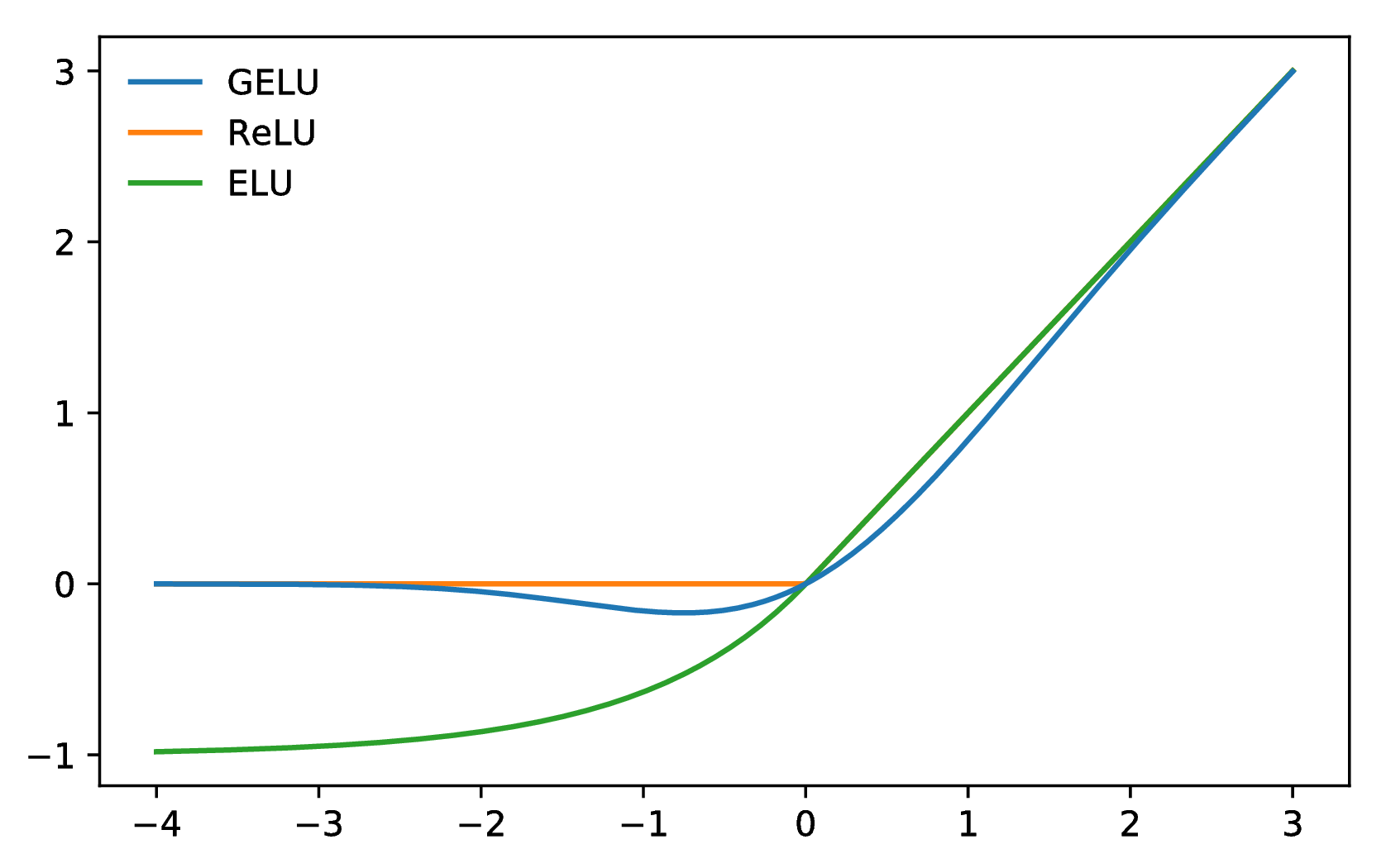
整体移动至文档 LLM解码相关
Encoder和Decoder 可做权重共享
Masked Self-Attention:Decoder解码过程,当前位置不能看到未来的内容。Bert