LLM Attention 系列
📅 发表于 2025/11/14
🔄 更新于 2025/11/14
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
llm-attention
#softmax attention
| 分类 | 方法 | 核心思想 | 主要解决的问题 |
|---|---|---|---|
| 基础 | Traditional Softmax Attention | 计算完整的 N x N 注意力矩阵 | 建立序列依赖关系 |
| 算法优化 | Linear Attention | 利用矩阵乘法结合律,近似计算 | O(N²) 复杂度 |
| Sparse Attention | 只计算部分重要的注意力权重 | O(N²) 复杂度 | |
| 架构创新 | Multi-Head Attention | 并行计算多个子空间的注意力 | 提升模型表达能力 |
| Multi-Query / Group-Query Attention | 多组/所有头 共享K和V | MHA的KVCache显存瓶颈 | |
| Multi-Head Latent Attention | 引入信息瓶颈(潜向量) | 处理超长序列的 O(N²) 复杂度 | |
| 实现优化 | Flash Attention | 分块计算,避免读写巨大中间矩阵 | 内存带宽瓶颈,硬件利用率低 |
符号定义
核心思想
注意力本质:
Causal场景:有关。
掩码矩阵,下三角矩阵
逐一取log,Softmax Attention 分量形式
权重和,分子每项的权重*值,再求和。除以分母:保持数值稳定性Softmax Attention 精简
最核心为分子,需把
精简:去掉softmax
精简:去掉掩码,非causal
增加归一化
Attention 精简公式
矩阵带掩码 公式
矩阵精简公式
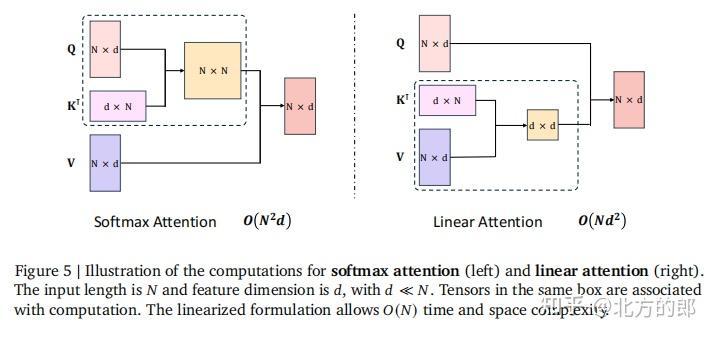
Softmax和线性注意力
当n很大时:由于 计算成本非常高Flash Attention降低了空间需求,但平方时间复杂度依然无法避免。当n很大时,复杂度随n线性递增,计算成本低仅仅是交换了计算顺序Softmax 时间复杂度例子
结果矩阵
第i列,d个元素的行向量,维度为 第j行,d个元素的列向量,维度为 单个元素计算复杂度:
整体复杂度:有
线性注意力时间复杂度例子
结果矩阵
第i行,n个元素的行向量,维度为 第j列,n个元素的列向量,维度为 单个元素计算复杂度:
整体复杂度:有复杂度线性依赖于n
Input:一般是一个句子;乘以矩阵得Q/K/V 3个向量
QKV向量
注意力权重
当前query对各个位置的注意力权重dot/concat/w 这3种score计算的3种方式加权求和

Self-Attention
Query作为一个锚点计算attention score后做加权。Attention 变体
符号定义
第i步的完整Attention矩阵attention矩阵的第i行Step=1,共1行
第1行:Step=2,共2行
第1行:step1已算过第2行:Step=3, 共3行
第1行:第1步已算过第2行:第2步已算过第3行:第3步算第3行结论
每一步都存在大量冗余,第i步,只需要计算第i行即可,前i-1行都已经计算过
矩阵中,第k行只和
解码
1、Self-Attention Padding 做 Mask
2、Transformer Multi-Head Attention 要对head 进行降维
降低计算复杂度3、维度和点击的关系
方差的性质
3、深入理解
Attention计算过程:内积
如果不进行缩放:
会很大或很小注意力权重 接近one-hot分布x值继续变大,y几乎不变因此:QK后才除以
softmax入参在不大也不小数学思路
背景
平方复杂度变成线性复杂度。核心思想
优点
缺点
性能效果损失,最新MiniMax-M2 已经由 Lighting Attention 切换回 FullAttention了。线性注意力基本公式
交换位置,时间复杂度由线性依赖于n。 分量形式
状态公式
线性RNN线性Attention:本质是一个cumsum,将所有历史信息 等权地叠加。现行Attention 记忆遗忘缺点
cumsum,各历史信息同等权重叠加。token足够多时,每个token的信息占比会变得很小。固定大小矩阵 每个token的记忆会变得模糊不清。RetNet/MiniMax-01:增加衰减因子
遗忘早期信息,就近原则DFW/Mamba/Mamba2
TTT 思想
把
最后输出
TTT 实现的RNN
当前模型参数为
RNN:把历史数据有效压缩到一个固定大小的State中,而模型参数正好是固定大小的。
类比
背景
随长度二次方增加 稀疏注意力核心思想
只需关注序列中少数几个关键位置,无需关注所有位置。不计算完整 N×N的注意力矩阵,只计算一小部分稀疏位置的。选择与Q相关的少量Token,来计算Query-Key注意力。优点
传统稀疏注意力的缺点
局部注意力 / Sliding Window
邻近的几个词。全局注意力 / Global Attention
预设一些全局节点,让所有词都与它们进行计算。组合模式
压缩、选择、滑动窗口三种模式,比如 DeepSeek NSA 论文笔记Multi-Head Attention
多个子空间QKV的注意力,提升模型表达能力。Multi-Query Attention
所有Query共享一对K和V,减少KV参数,提升推理速度,优化Group-Query Attention
把Query分组,每组共享一对K和V,效果比MQA好、速度比MHA快。Multi-Head Latent Attention
把KV联合压缩成一个 小的潜在向量,来解决KV缓存高的问题。压缩、缓存、重建三步。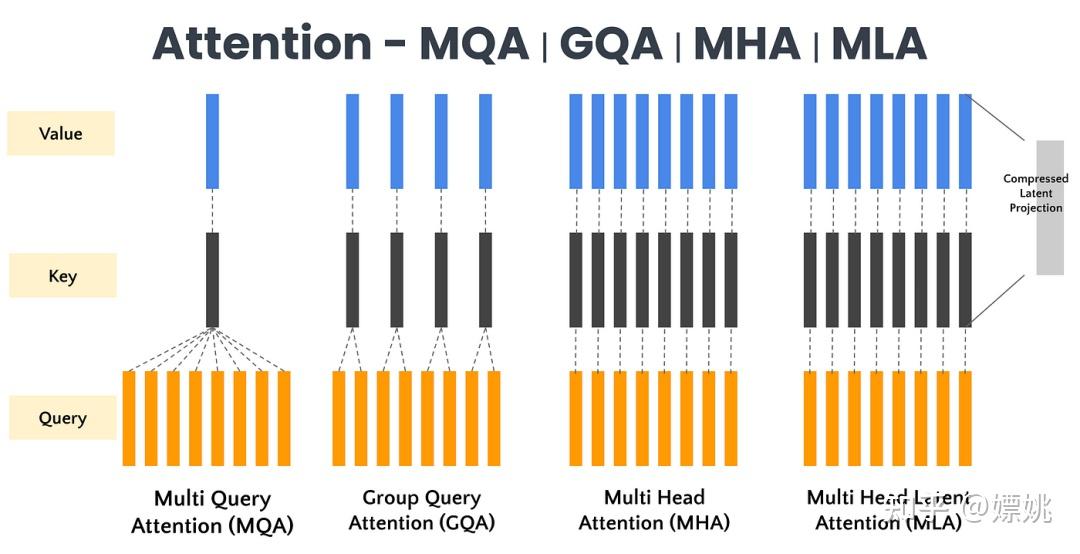
核心思想
多组QKV,学习不同表征模式,增强模型能力,类似CNN多个卷积核优点
多头关注不同部分,最终再融合 起来得更好效果。
如:对词向量维度512进行8头切割,每头输入维度为64,最后采用concat进行融合。
缺点
计算成本高核心思想
所有query共享同一个Key和Value 矩阵,每头仅保留Query参数,优点
大大减少KeyValue参数,提升推理速度缺点
精度损失。核心思想
query分为n组,每组共享Key和Value矩阵。优点
问题
KV缓存高、显存压力大。核心思想: 低秩KeyValue联合压缩
压缩成一个维度很小的latent vector缓存非常小的潜在向量,而非原始KV重建出原始的Key和Value。优点
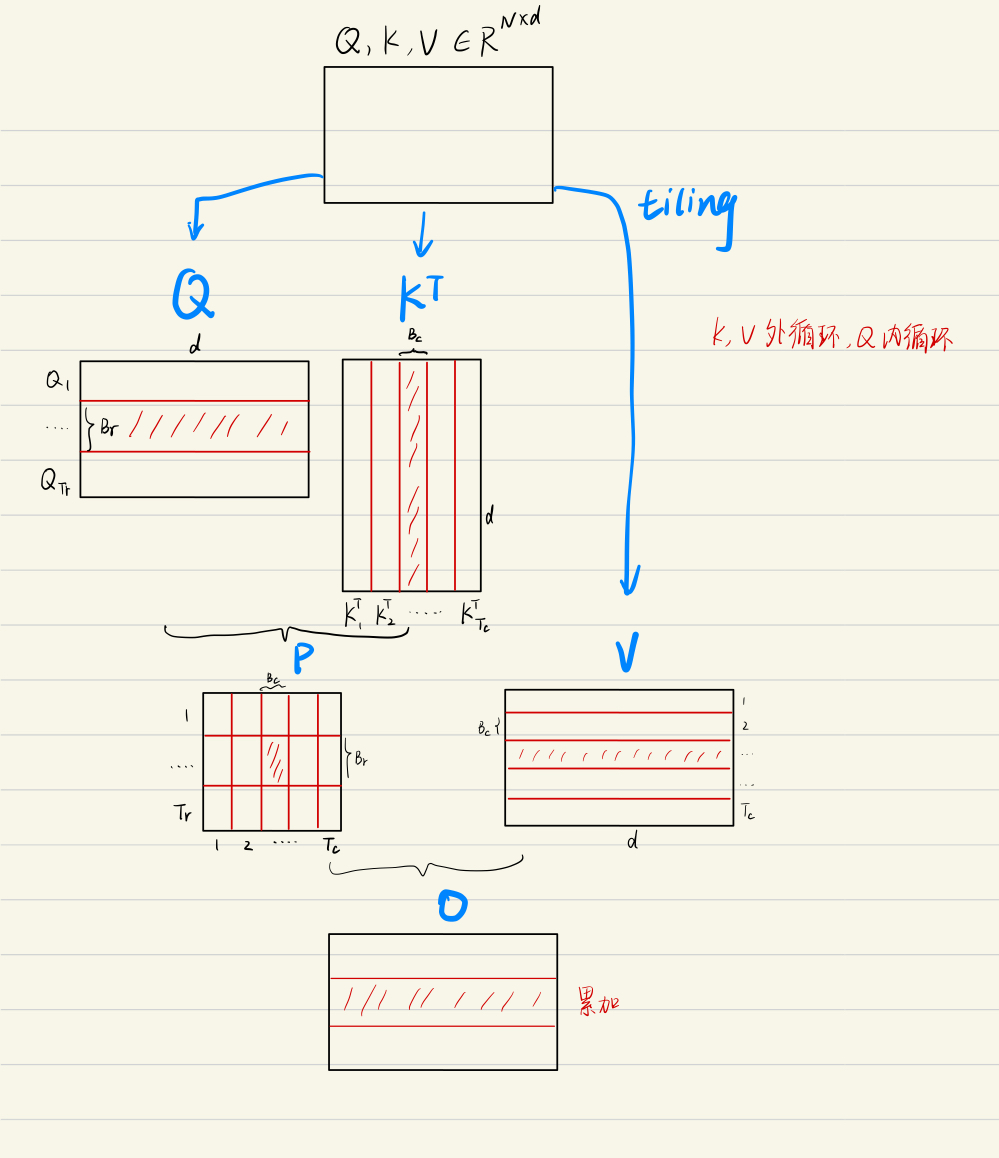
大幅减少KV缓存:与DeepSeek 67B比,KV缓存减少93.3%推理性能提升:最大生成吞吐量提升5.76倍性能还有提升最高效的注意力实现SRAM,将连续的内存块,加载进来进行计算,最大化硬件利用率。GPU - SRAM:很小很快,20MB、19TB/s (吞吐量)GPU - HBM:GPU显存大小,大但慢,80GB、1.5TB/s1TB、12GB/s
参考文章:FlashAttention中的softmax快分块计算详解
数值稳定
过大溢出,每个元素都减去最大值得在[0,1]区间。softmax结果和原softmax一致分块计算softmax:
更新各自分子,得全局分子。softmax tiling算法。通过存储归一化因子来减少HBM内存的消耗。