LLM 基础知识
📅 发表于 2025/07/09
🔄 更新于 2025/07/09
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
LLM训练目标通常是最大似然估计(Max Likelihood Estimation, MLE)。
Batch Training进行小批量样本参数更新。🚀涌现能力
🤔产生原因
scaling law现象,多个子任务组合一起,表现出了复杂任务的顿悟现象。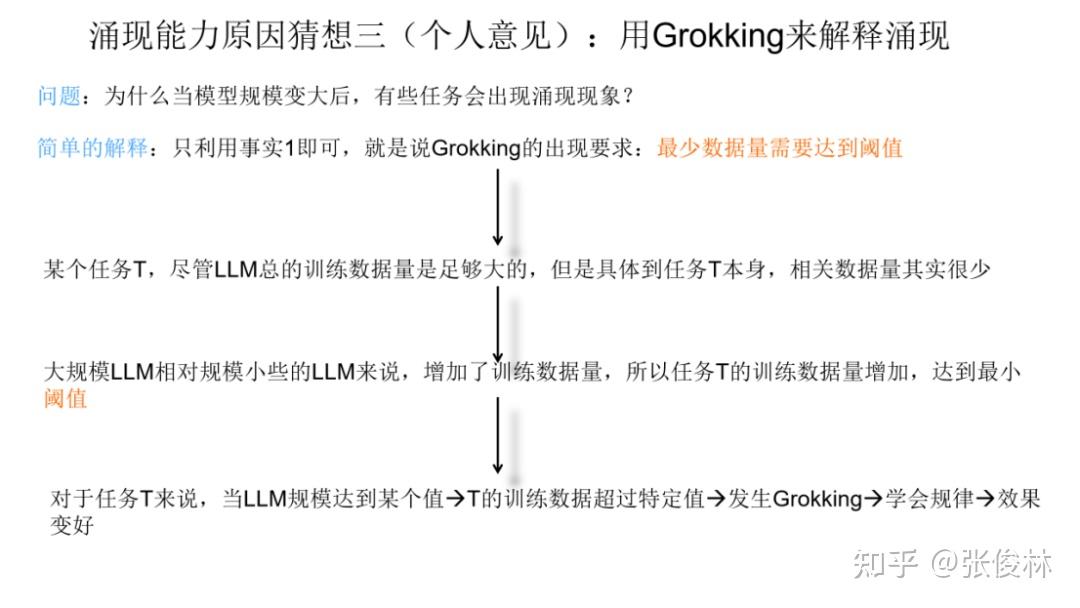
LLMs复读机问题(LLMs Parroting Problem):模型可能会简单地复制输入文本的一部分或全部内容,并将其作为生成的输出,而不提供有意义或新颖的回应,缺乏创造性和独特性。
没有一种通用的方案,需要针对具体情况具体分析, 下面是一些常用手段。
理论上,LLM可以处理任意长度的句子,但是有一些挑战:
1、分块处理
2、层次建模
3、部分生成
4、注意力机制
5、模型结构优化