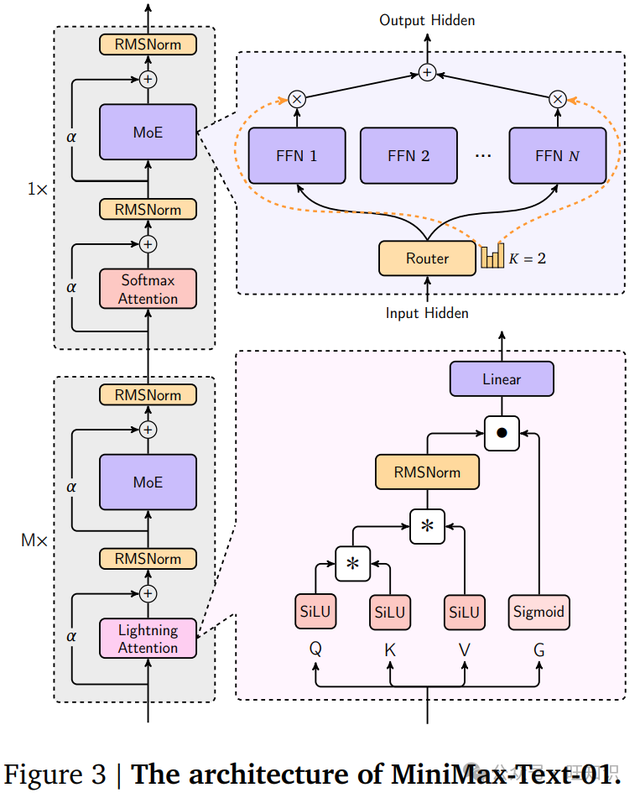
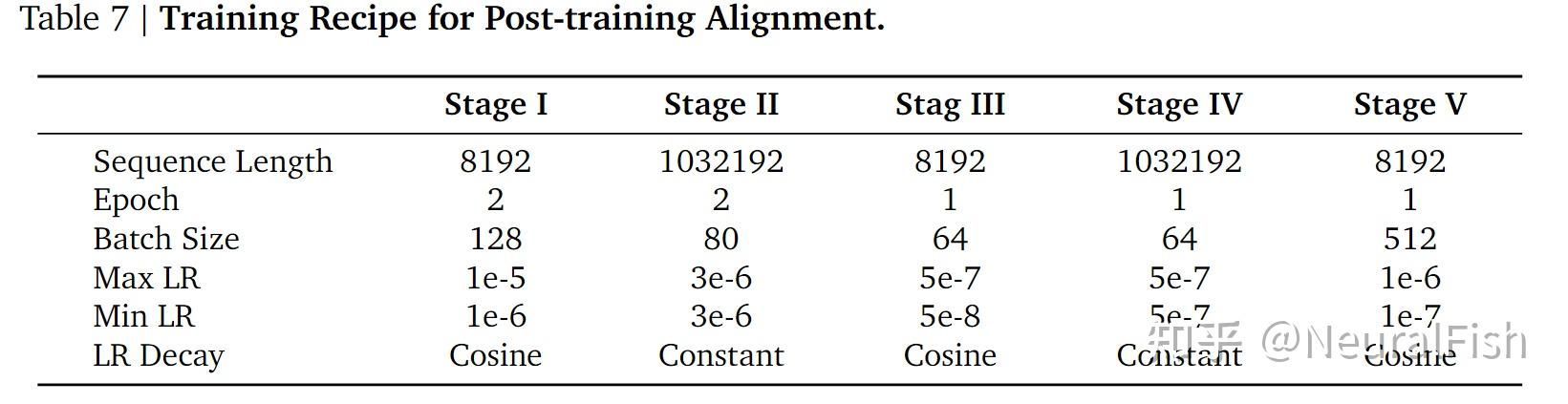
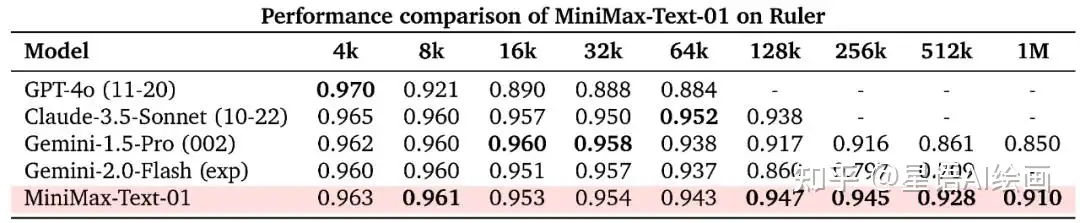
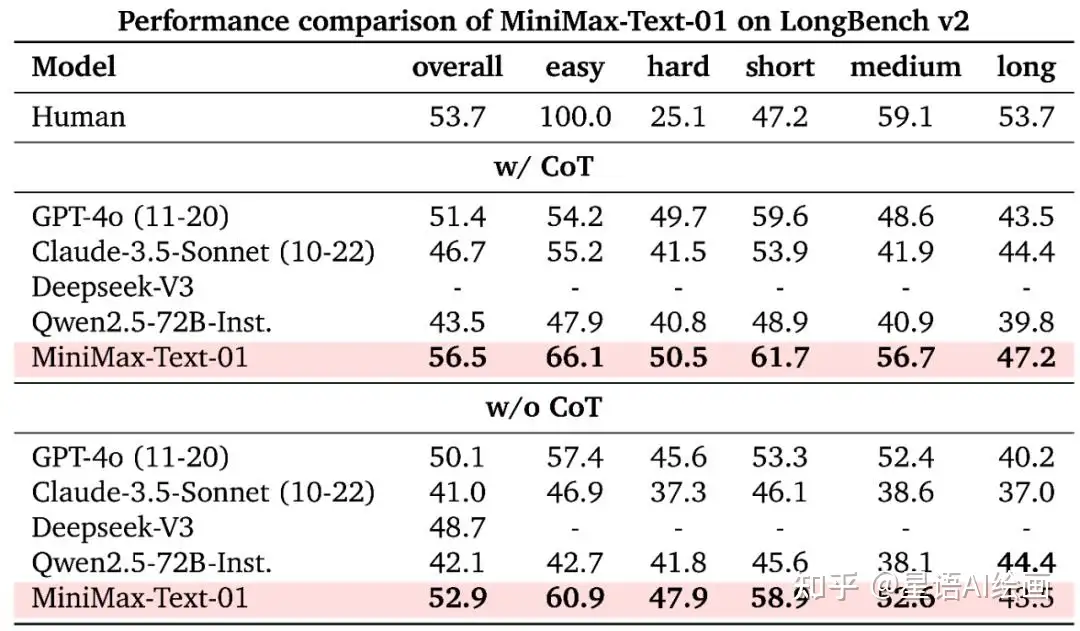
MiniMax 系列
📅 发表于 2025/11/08
🔄 更新于 2025/11/08
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
mainllm
#MiniMax-Text-01
#MiniMax-VL-01
#MiniMax-M1
#Linear attention
#Lightning Attention
#Hybrid Attention
#预训练数据
#数据有效性实验
#多阶段训练策略
#Reward Model
#GenRM
#Offline-DPO
#Online-GRPO
#安全对齐
#长上下文
#VL模型
#CiSPO算法
#可验证数据
#不可验证数据
#SynLogic合成数据
#GenRM长度偏差问题
#长思考Scaling