DeepSeek 系列
📅 发表于 2025/07/16
🔄 更新于 2025/07/16
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
deepseek
#DeepSeek R1
#R1-Zero
#Native Sparse Attention
🌺 论文摘要
❓问题背景
差距越来越大,闭源模型性能提升很快,处理复杂任务能力很强。 长文本太贵太慢。后训练资源投入不足:限制高难任务,大部分都在预训练上,后训练做的少。泛化指令和指令遵循效果不好。整体同DeepSeek-V3.2-Exp一致,通过DeepSeek-V3.1-Terminus 继续训练,区别仅是通过CPT来引入DSA。
Lightning Indexer
符号定义
Query token;前面的某token;二者的索引分数,索引头数量使用超轻向量 索引分值 哪些token被选中。
使用FP8(吞吐量高) + ReLU(比softmax快)
细粒度Token Topk选择器
稀疏选择top-k的token 计算注意力。DSA 和 MLA 结合
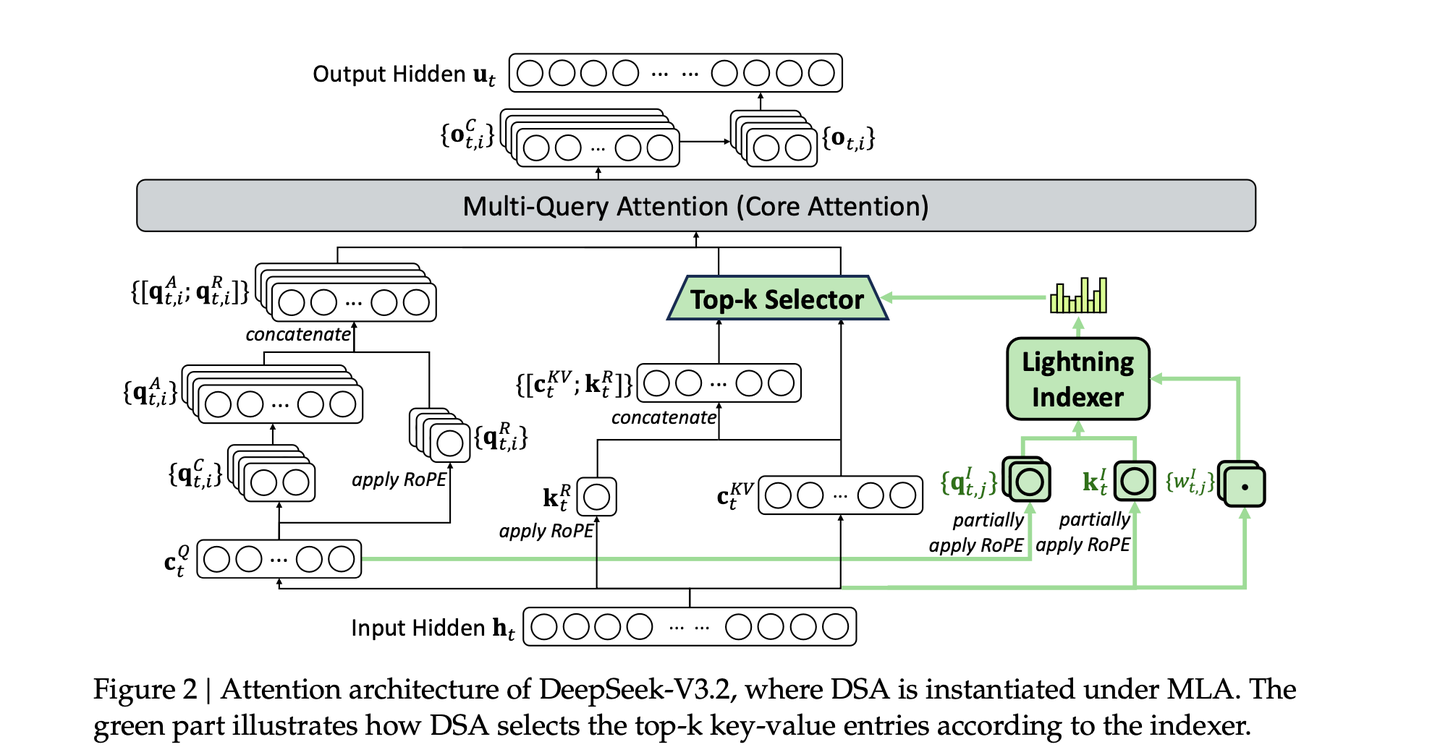
整体
128k。Dense预热和Sparse训练 2阶段。Dense 预热阶段
目标:初始化Lighting Indexer,学会预测哪些token是重要的。
方法:冻结主模型参数,仅训练Indexer参数。
训练目标:KL Loss作为训练目标,让indexer预测分布接近DenseAttention分布。
Teacher:DenseAttention, 目标分布,Student:SparseAttention共训2.1B tokens。lr=1e-3,1000步,每步16个序列,每序列128k token,
Sparse 训练阶段
正式训练稀疏注意力,同时训练主模型和indexer,
每个query token,不看所有128k token,而是仅看2048个token,执行Top-k选择。
共训 943B tokens。lr=7.3e-6,训练1.5w步,每步480序列,每序列128k。
整体效果,在标准Benchmark、人工偏好、长上下文上,DSA和之前模型,效果一致,并未出现明显下降,但推理成本得到极大下降。
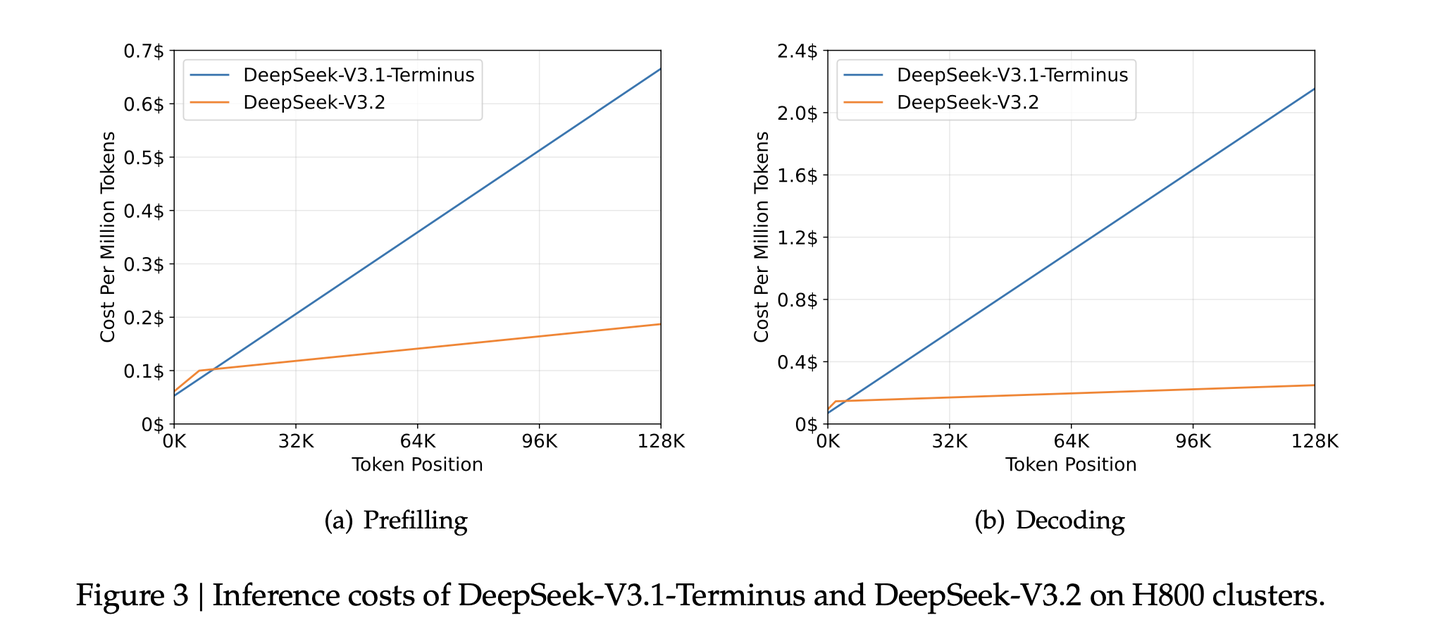
专家蒸馏训练
8大领域单独训练一个专家模型通用agentic任务、agentic编程、agentic搜索都经过单独RL训练,各专家支持思考和非思考模式。 长推理和直接回复数据。使用蒸馏数据,去训练Base模型。后续再接下文的Mixed RL训练 Mixed-RL训练
推理+agent+人类对齐。GRPO算法。 推理+Agent:Rule-Based奖励 + 长度惩罚 + 语言一致性奖励。其他通用任务:GenRM,每个任务有一个rubrics平衡 不同领域性能,解决灾难性遗忘问题。📕核心方法
问题:当
给这些token 分配极大、无边界的权重导致梯度瞬间爆炸,引入噪声,训练不稳定无偏KL估计
核心:重要性采样比例 * 原始K3估计。
乘以 期望值都是准确的,消除了系统误差,梯度变无偏估计。
KL 实践参数设定
不同领域任务,所需的KL不一样。
通用对话/文案任务:需较强KL,保持语言流畅风格一致性。
数学/逻辑推理:就几乎无需KL。
异策略负样本可能有害
高度异策略的负样本,很可能是有害的。推理框架高度优化,和训练框架可能不一致,加剧了异策略程度。 1次rollout样本分多个mini-batches,做多次梯度更新采样策略和更新策略 不一致。Mask 异策略负样本
Mask不好的序列,不学它,差序列定义如下:
优势为负KL差异大,rollout模型和当前模型 差异大系数计算公式
序列级KL散度:序列内所有token的KL值做平均,作为序列级KL散度,设定最大阈值Token级系数 优势为负且KL差异较大时,设为0目标
核心:消除训练和推理时的不一致
Keep Routing:消除模型结构动态性带来的不一致。Keep Sampling Mask:消除概率空间截断带来的不一致。保持MoE路由
采样时:Router选择专家A和B;训练时:Router却选择专家B和C。参数更新方向很随机,导致训练崩溃Routing Replay。 记录每个token选择的专家;训练时,不计算路由,强制使用推理时的专家。评估整个句子,无需Routing Replay,对底层专家不敏感,保持采样Mask
低概率token概率为0,相当于词表截断。动作空间/定义域 不一样,导致计算失效。保留采样Mask,在训练时应用到新的User消息到达时,才丢弃之前的思考内容。每一步的工具调用中,保留每步的思考过程,不像R1那样每一步都丢弃和重新思考。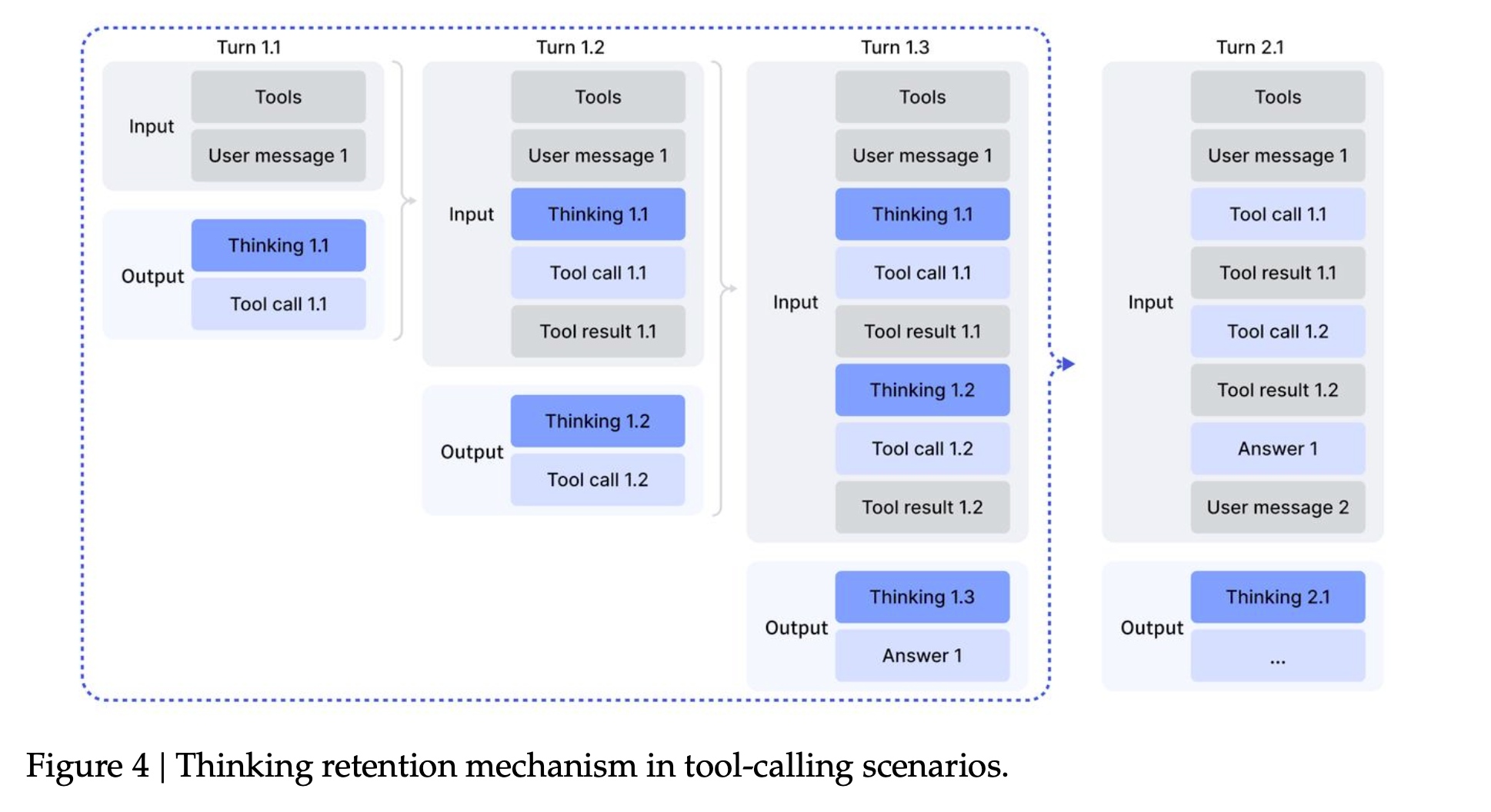
上下文管理,token超过80%时: Summary:总结轨迹并重新启动Rollout过程Discard-75%:丢弃前75%的工具调用历史来腾出空间Discard-all:丢弃所有的工具调用历史来重置上下文背景
深度思考(R1-Style)、又能熟练使用工具(Agentic Style)的模型。推理数据-非Agent,Agent数据-无推理。方法
指令跟随能力,设计Prompt,把推理思考和工具使用合在一起。 不同任务需不同的system prompt。成功率低,但也可提取出成功轨迹作为正样本。SFT 微调 -> 收集正样本 -> SFT 微调....,逐渐提高成功率,后续可做大规模RL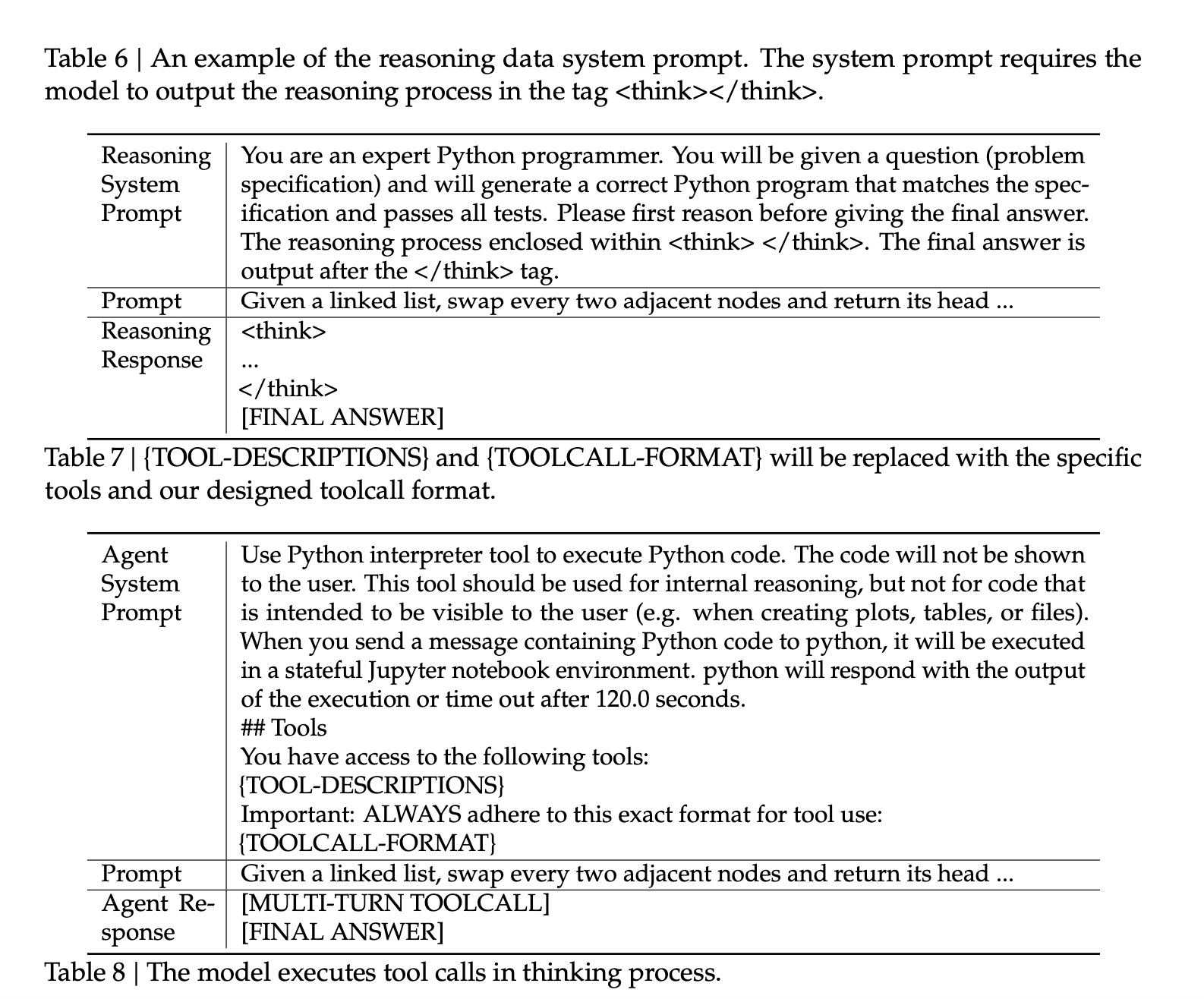
📕核心方法
Search Agent
Mulit-Agent Pipeline 合成 多样高质量数据 长尾实体搜索工具探索实体,把信息整合成QA对。生成候选答案。GT正确且所有候选答案错误的难样本。多个质量维度的rubrics,来打分。Code Agent
数百万Github Issue-PR中,构建大规模软件Issue解决的可执行环境。 合理的Issue描述、Gold Patch、Test Patch。包安装、依赖解析和测试执行。 数万个 高质量 多语言 Issue解决 RL交互环境.Code Interpreter Agent
Jupter Notebook作为代码解释器,解决复杂推理任务。每个问题需使用代码来解决。General Agent
4.4k任务,1.8k合成环境,合成prompt。
自动环境构建Agent:合成了1827个任务环境。难解决却好验证的任务。
任务类别 + Sandbox(bash+搜索功能),Agent搜索数据并存入数据库。为任务合成工具,工具即函数。简单任务+Solution+Verification,python实现。 只能调用工具,不能调用其他函数或直接访问数据库Solution结果必须通过验证函数校验,不断修改,直到通过为止。增加任务难度,更新解决方案和验证函数,以及扩充工具集。环境+工具集合+任务+验证器数据筛选:筛选出有难度 可执行的优质任务,而非直接使用所有数据。
留下pass@100 > 0的任务。✍️实验设置
基础模型
训练任务/数据
Agentic 任务:4大类,8.5w。评测任务/数据
算法/策略
超参
🍑关键结果
Post-Training 评估
输出token数量少得多。合成任务评估
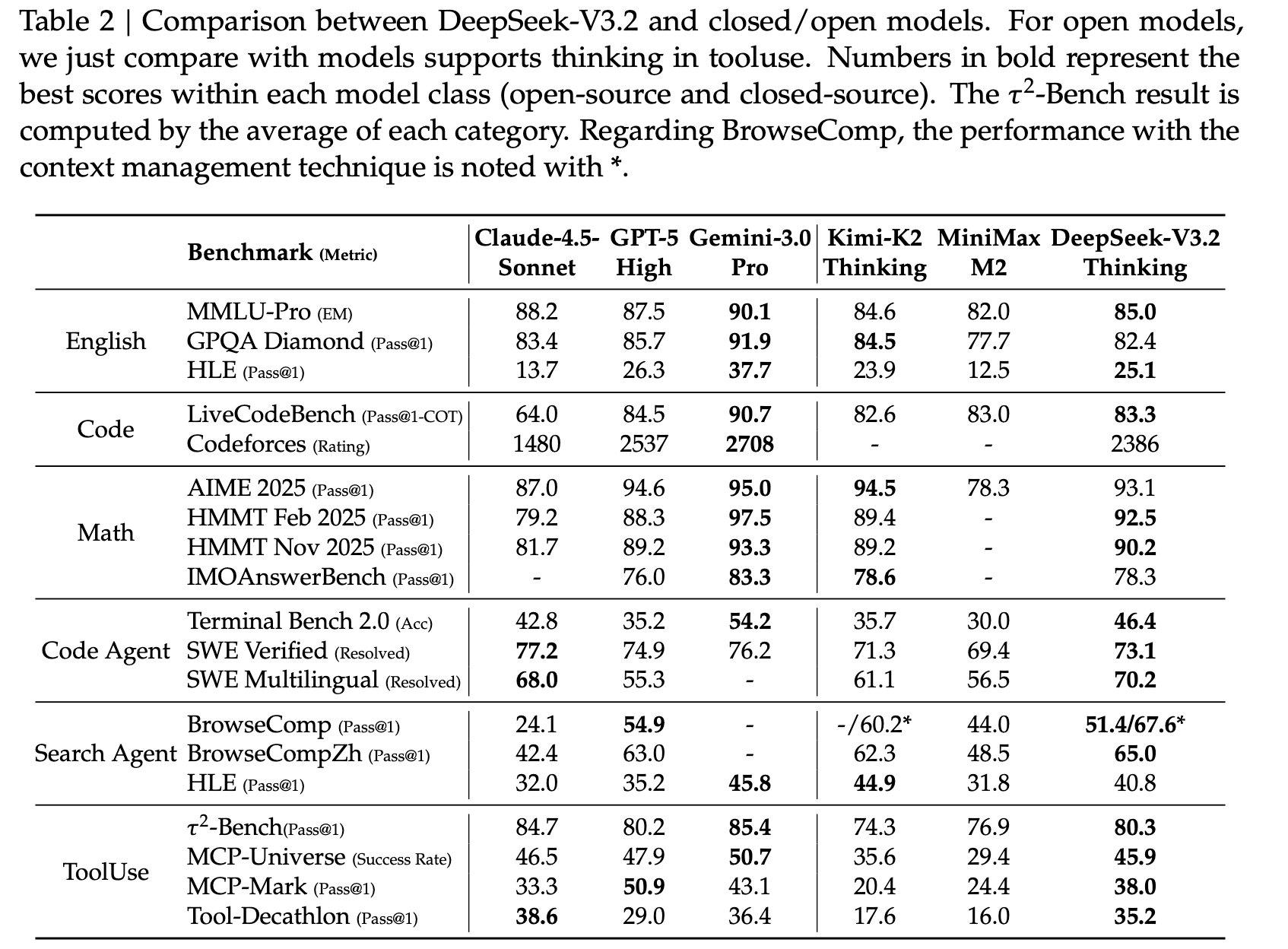
合成任务还是有难度:
⛳ 未来方向
世界知识落后闭源模型:扩大预训练,弥补差距。Token效率提升:DeepSeekV3.2 需生成更长轨迹才能匹配Gemini3-pro效果。 更高效的测试时计算扩展策略(如并行搜索与串行思考的最佳组合)。复杂任务仍落后前沿模型:进一步完成基模和后训练流程。动态计算更紧凑的KV,保证稀疏性,解决了传统稀疏注意力实际效果不好的问题。压缩块级粗粒度、选择保留细粒度、局部滑动注意力,3种注意力加权求和。❓问题背景
llm长度很重要
长度很重要,但传统softmax注意力,时间复杂度随文本长度二次方增长,太高了不ok。 占据70-80%时间稀疏注意力可解
稀疏注意力:只选择与Q相关的少量Token,来计算Query-Key注意力。实际加速效果不好
不符合硬件计算逻辑, 内存访问不连续
Sparse Attention 逻辑:减少FLOPS运算,随机、不规则访问内存。
GPU 逻辑:并行计算。
不匹配:导致GPU大量在等待数据、找数据,而非计算,实际加速并不高。
只在推理特定阶段做加速
缺乏预训练/训推不一致
架构偏差/不一致:预训练采用full、后训练/inference采用sparse
未充分学到Sparse,无法充分发挥sparse的潜力和优势使用稀疏注意力,需解决:硬件对齐问题、训练感知问题。
1. 只在推理某个特定阶段做加速
H2O(2023):仅在decoding使用Sparse AttentionMInference(2024):仅在prefilling使用Sparse Attention2. 与主流解码架构MQA/GQA不兼容
MQA,GQA :多个Q头 共享 1组 K-V头
解码时非常高效,GPU只需从内存加载一小部分K和V。
如Quest(2024)/Sparse:每个Q头 独立选择 KV-Cache
实际效果不理想需把Group内所有Q头独立选的KV-Cache,都找出来做并集,作为GQA的KV
虽然Sparse减少计算操作,但需要的KV-Cache却仍然高。
在解码阶段,内存访问非常高,内存是瓶颈,最终导致实际加速效果不理想。
1. 若不训练稀疏注意力,直接用效果不好
预训练好的 Full Attention模型,直接应用稀疏注意力,会损害模型性能。2. 若训练稀疏注意力,则存在挑战
某些稀疏操作不可微分,导致模型无法学习操作是离散的(A或B,无中间状态),导致梯度无法通过操作回传内存访问模式非常不规则,导致在GPU上训练效率很低把连续内存块加载进来进行计算。Token粒度的,可能会选择5、28、106这些不连续的token各零散位置去读数据大部分时间都在找数据、而非算数据,导致训练速度极慢。📕核心方法
核心思想
不使用原始完整的KV,使用通过q和上下文kv动态计算出来的、更紧凑的KV重新映射的KV总数,远小于原始总数,维持高稀疏性。压缩、选择、滑动3种策略进行加权,权重由门控网络计算出来。压缩思想
连续的键值块聚合成块级表示,来捕获整个块的信息。更紧凑、信息更密集的键值对多个token进行压缩聚合具体做法
K序列分成长度为l的块,每块之间有长度为d的滑动步长。可学习的MLP与块内位置编码一起,将每个块中的Key映射到一个压缩Key。优点
更粗粒度的高级语义信息,从而减少注意力机制的计算负担缺点
丢失细粒度信息选择思想
选择性保留细粒度token
从历史信息中,挑选最重要的几个信息快,来参与计算
具体做法
压缩token的注意力计算产生的中间注意力分数来推导选择块的重要性分数。保留top-n块中的token优点
保留重要的细粒度信息,避免因过度压缩而损失关键细节。目的
防止局部模式过快适应并主导学习过程,从而阻碍模型从压缩和选择令牌中有效学习专门的滑动窗口分支来显式处理局部上下文。核心思想
最近一小段的历史信息
背景
硬件不对齐问题,计算逻辑不同,导致实际加速和理论不匹配。核心思想
基于block,使得内存访问变得很规整、连续,方便GPU。背景
缺乏预训练问题、训推不一致问题。核心思想
从预训练开始,就学会如何高效做信息压缩和筛选。✍️实验设置
模型
预训练数据
架构
评估Bench
🍑关键结果
提速达6-11倍。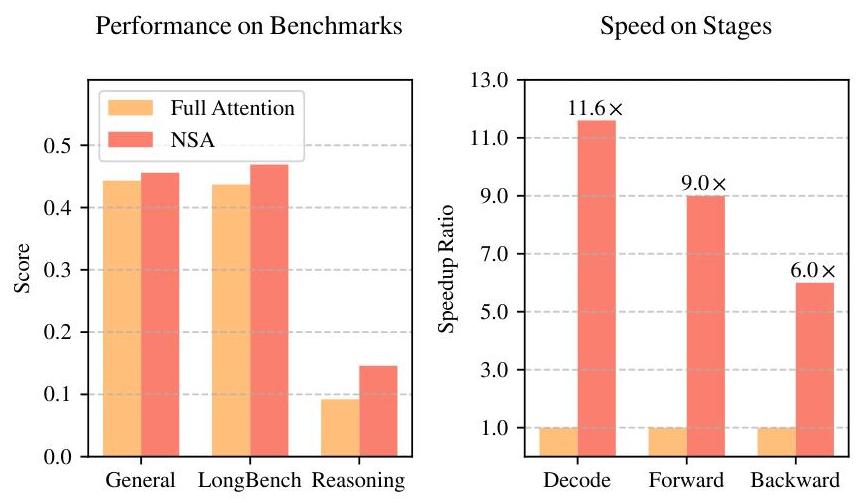
计算效率

⛳未来方向
❓问题背景
但在复杂数学和科学上仍是重大挑战,开源界缺乏复制o1的明确路径。⚠️高质量SFT推理数据成本高难以获取。难以探索纯RL潜力。📕核心方法
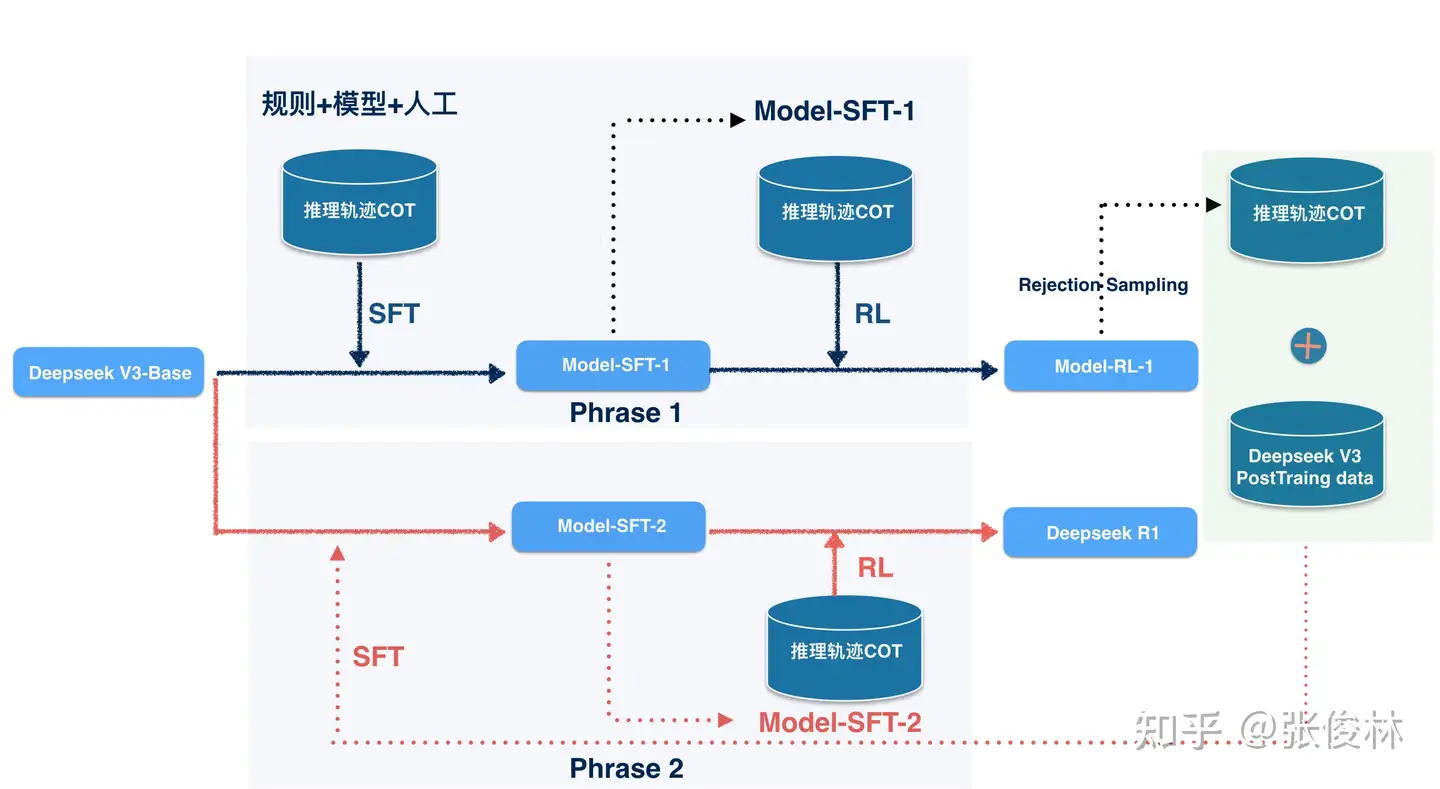
纯强化学习冷启动SFT -> 推理任务RL -> Cot+通用数据SFT(80w) -> 全场景RL直接用80w数据做SFT⭐ 核心思想
基模+Rule-based RL,不使用SFTbox中,数学/Code任务。<think>采样一组输出并计算组内奖励均值和标准差来估计优势函数,来优化模型💥取得效果
主动回溯、推翻先前想法并重新推理的行为。类似于人类恍然大悟。💔缺点不足
目标
训练一个人类友好、通用性强的模型。🐱阶段1:冷启动
为了避免RL不稳定,让模型掌握基本CoT能力,更具输出可读性。使用小部分高质量CoT数据微调模型,作为最初RL Actor,使用DeepSeek-V3-base作为起点。🐸阶段2:推理导向的强化学习
专注于推理任务做大规模强化学习,解决语言一致性问题代码/数学/科学/逻辑推理等数据(具有明确答案)做RL🐬阶段3:拒绝采样和SFT
提升模型在写作/问答/RolePlay等通用任务上的能力拒绝采样,每个推理样本生成多个轨迹,仅保留正确选项,构建高质量样本。用DeepSeekV3作为生成式RM,同时输入标准和模型答案,来判断是否正确。语言混合、过长段落、过长代码片段等。使用80wSFT数据对V3-Base做了2轮SFT训练。🐶阶段4:全场景下的强化学习
使模型在推理和非推理所有任务上表现良好,保证安全性和无害性在较小训练开销下取得远胜于自身RL学习的效果👍,展现出蒸馏技术的有效性。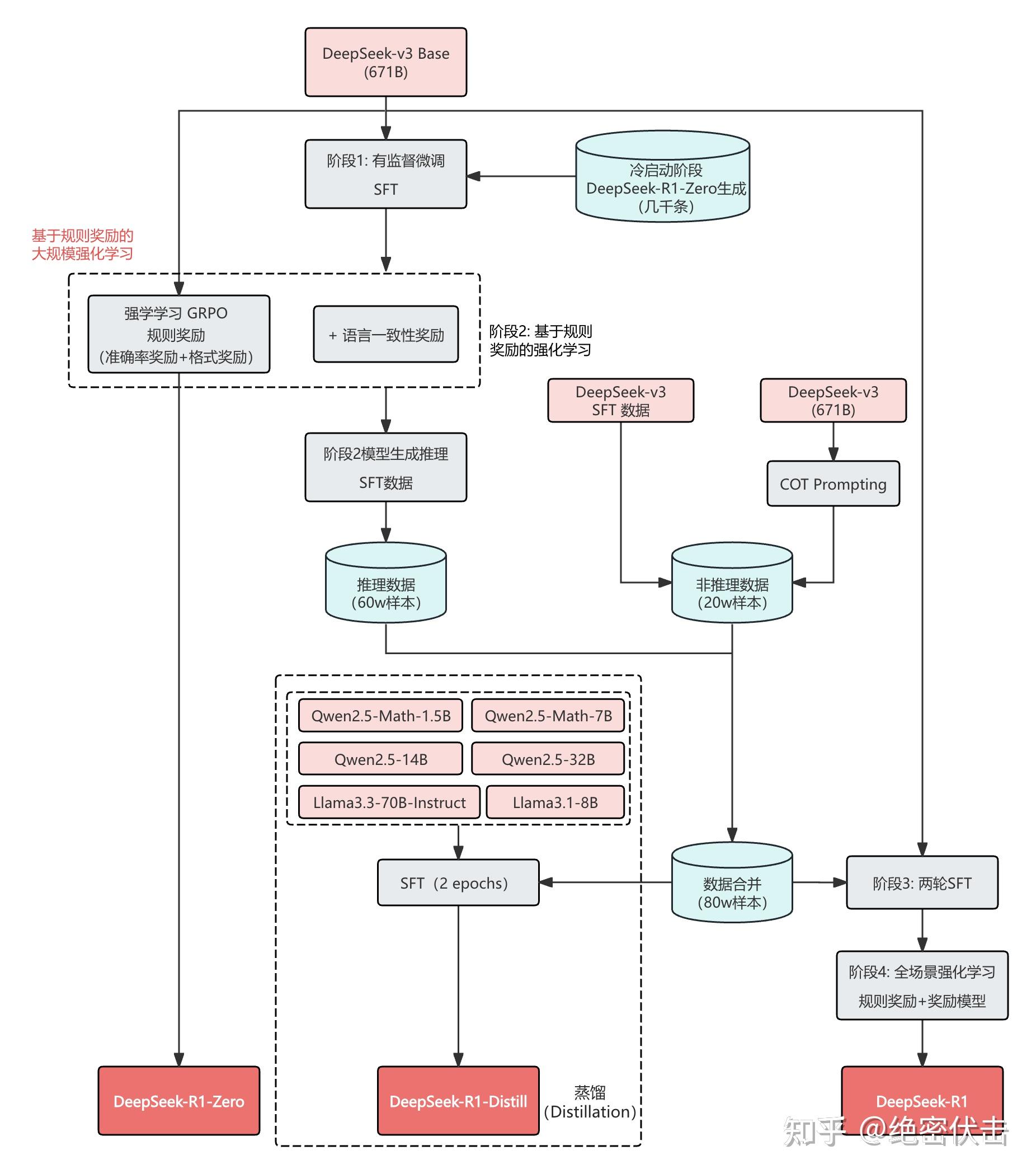
✍️实验设置
🍑关键结果
⛳未来方向