推理优化技术
📅 发表于 2025/07/25
🔄 更新于 2025/07/25
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
llm-inference
#prefix caching
#kv cache
#attention优化
#MLA
#flash attention
#PagedAttention
#Copy-On-Write
#动态批处理
具体:模型并行
Multi-Query Attention, MQA
所有Query共享一对K和V,减少KV参数,提升推理速度,优化Group-Query Attention, GQA
把Query分组,每组共享一对K和V,效果比MQA好、速度比MHA快。Multi-Head Latent Attention, MLA
把KV联合压缩成一个 小的潜在向量,来解决KV缓存高的问题。压缩、缓存、重建三步。背景
[1, k-1]步骤计算过方法
增量QKV计算优点
缺点
限制序列长度和BatchSize,影响吞吐量在1个请求内复用,无法做到跨请求,不适用于多轮对话场景 对比示意图,一目了然,每次只用当前Q和前的KV做计算即可,因为前面的行和

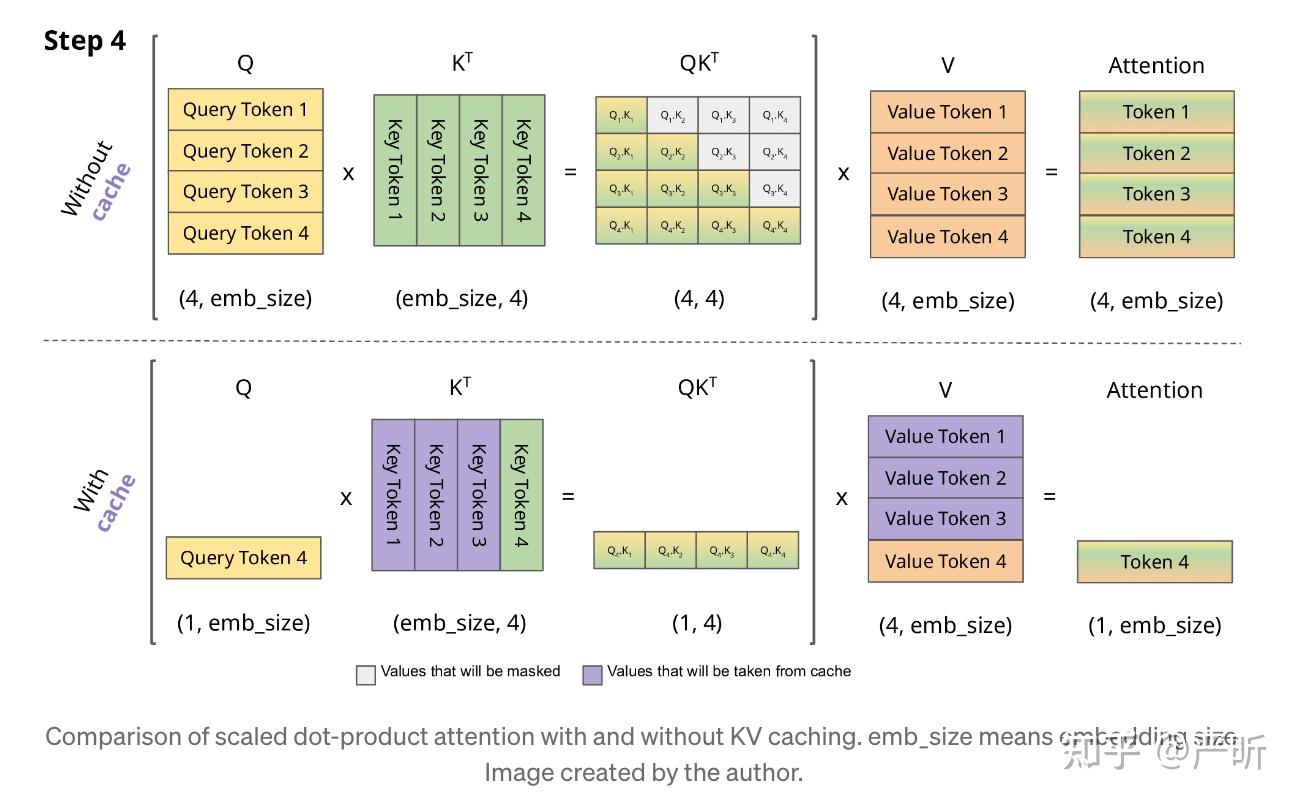
参数定义
b个序列t个token,包括prompt和completionkey和value 2类张量n_layers注意力层n_heads个头d_head向量维度1参数p_a字节,fp32-4,fp16/bf16-2,fp8/int8-1KV Cache大小 (单token)
KV Cache大小 (整个batch) MHA
背景
方法
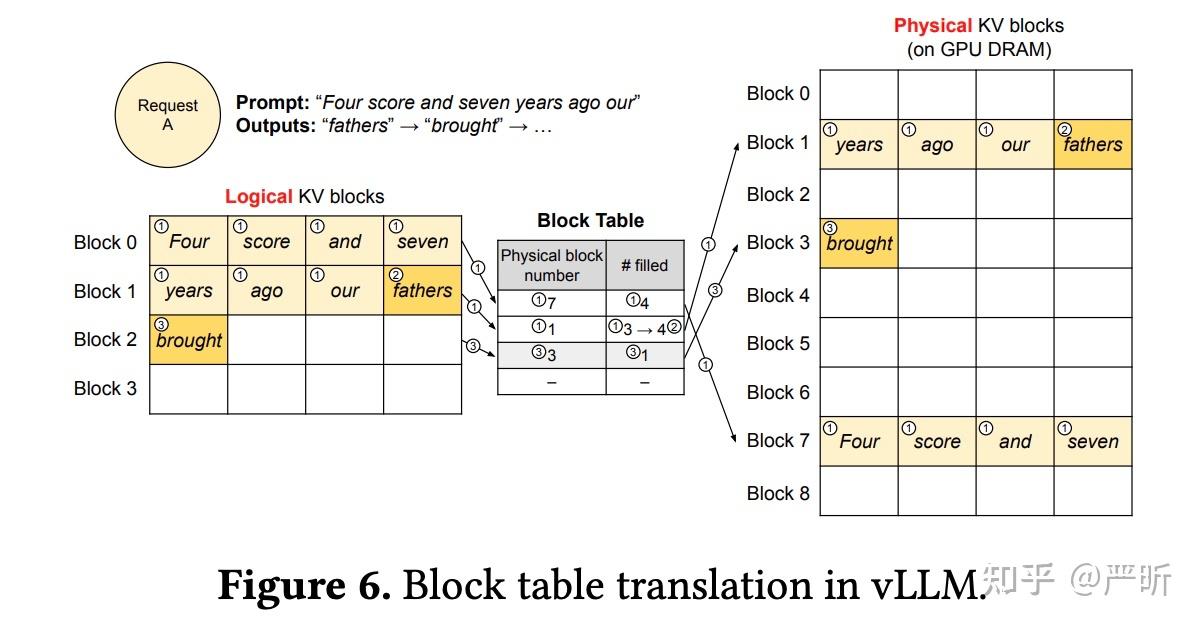
block table来找到块,进而取出k和v优点
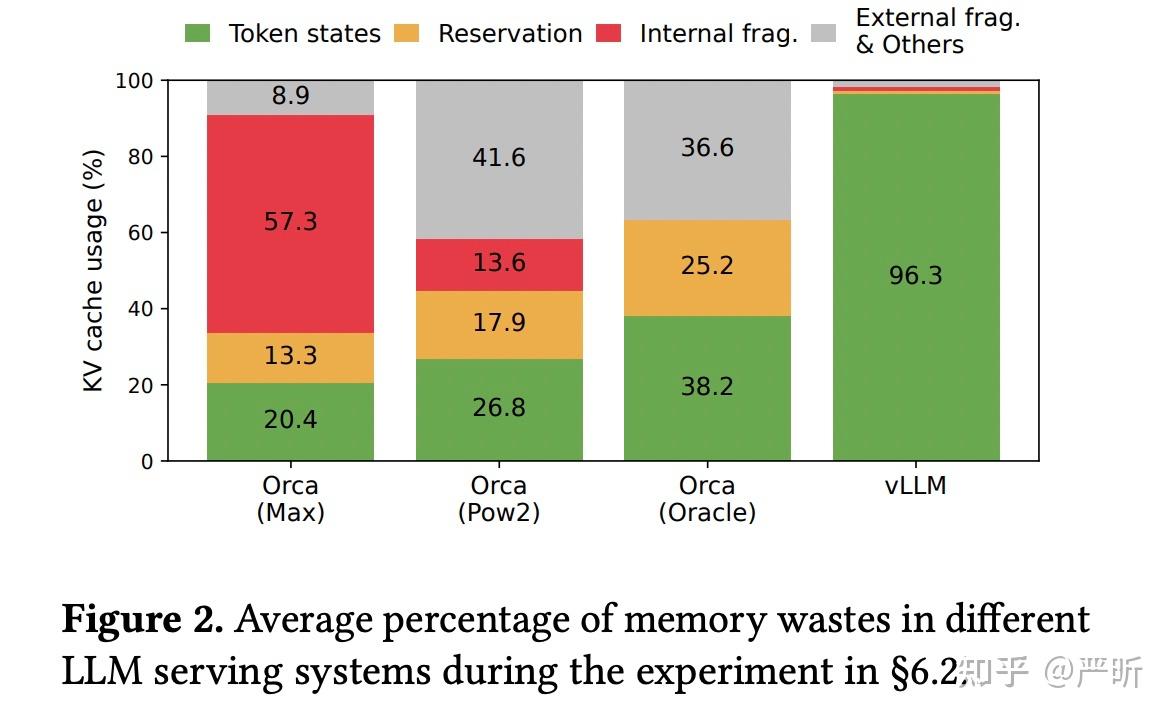
碎片很多:

PageAttention 运行机制
背景
方法
vLLM写时复制:当一个序列会改变KV Cache时,vLLM会先创建副本,这样修改就不会影响其他序列
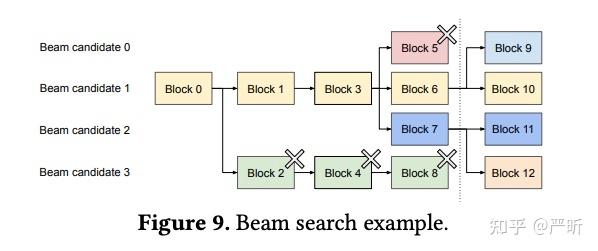
背景
核心思想
复用上一轮结果,提升prefix性能,降低新一轮的TTFT重用SGLang Prefix Caching
vLLM Prefix Caching
DeepSeek Prefix Caching / Context Caching
压缩了KV Cache的大小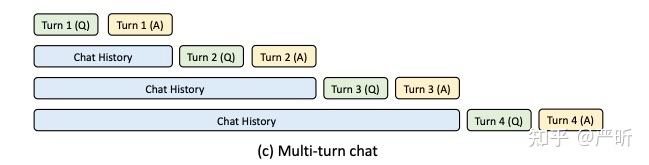
核心思想
训练32/16 -> 存储8/4等。优点
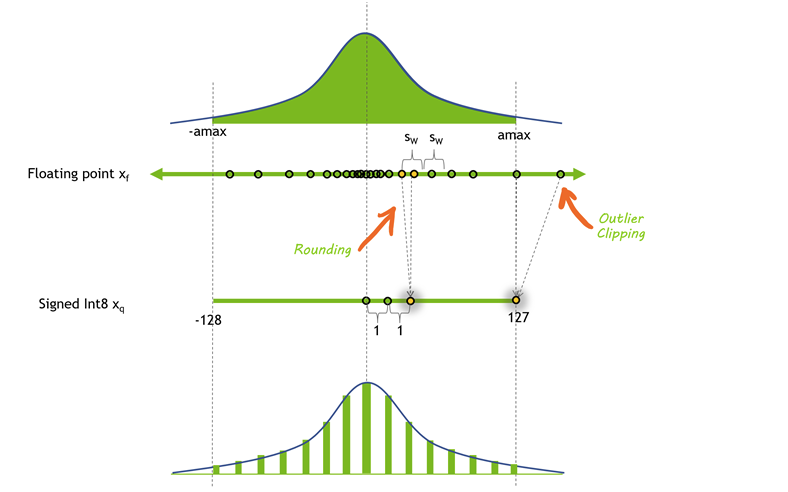
核心思想
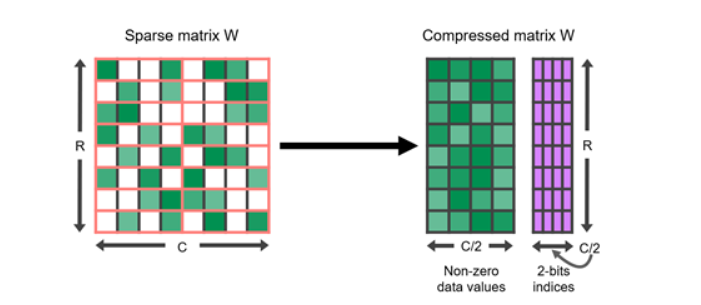
核心思想
模型执行通常受内存带宽限制(特别是权重),期望加载权重时尽可能多的处理他们。
思想
思想