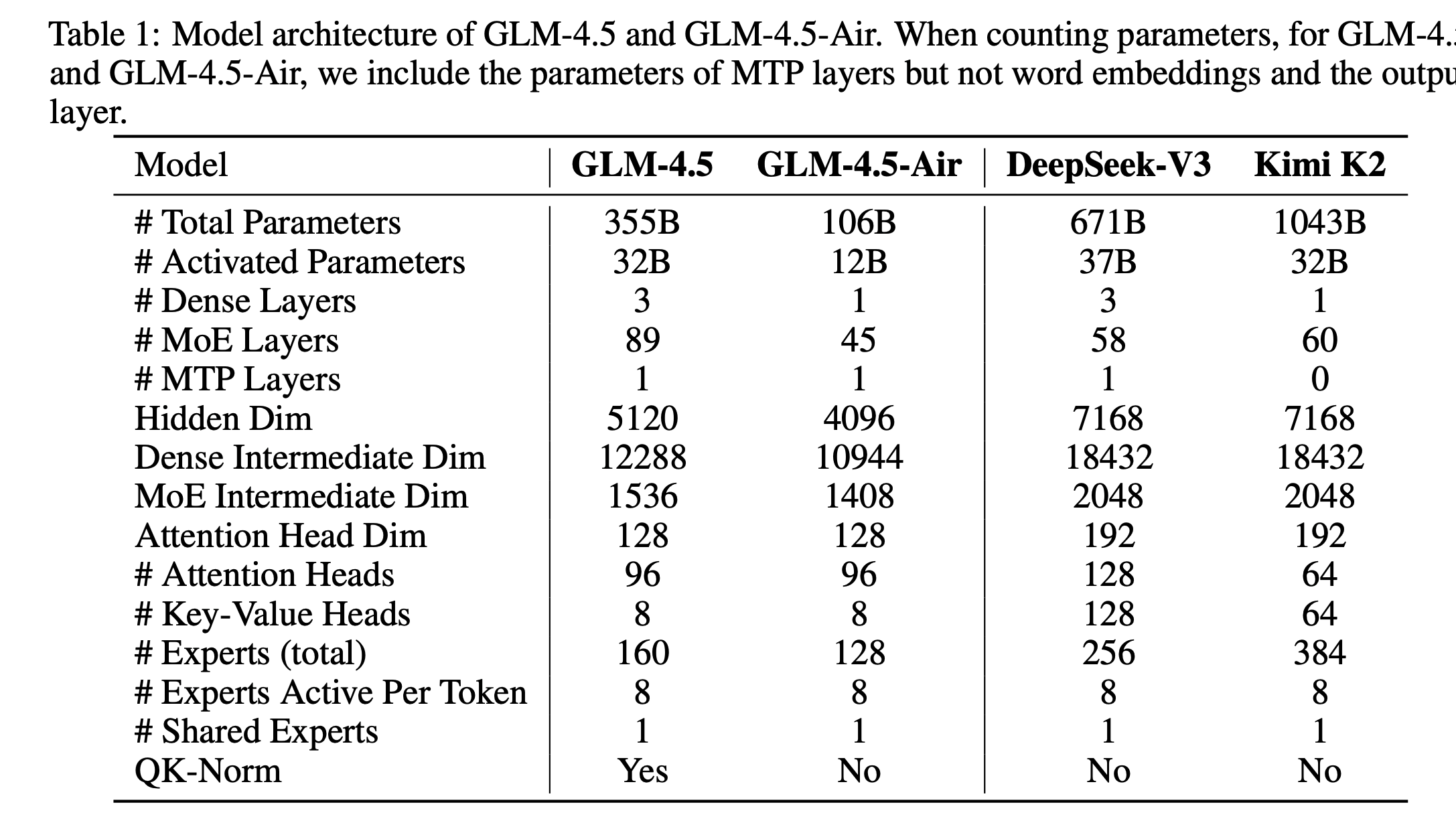
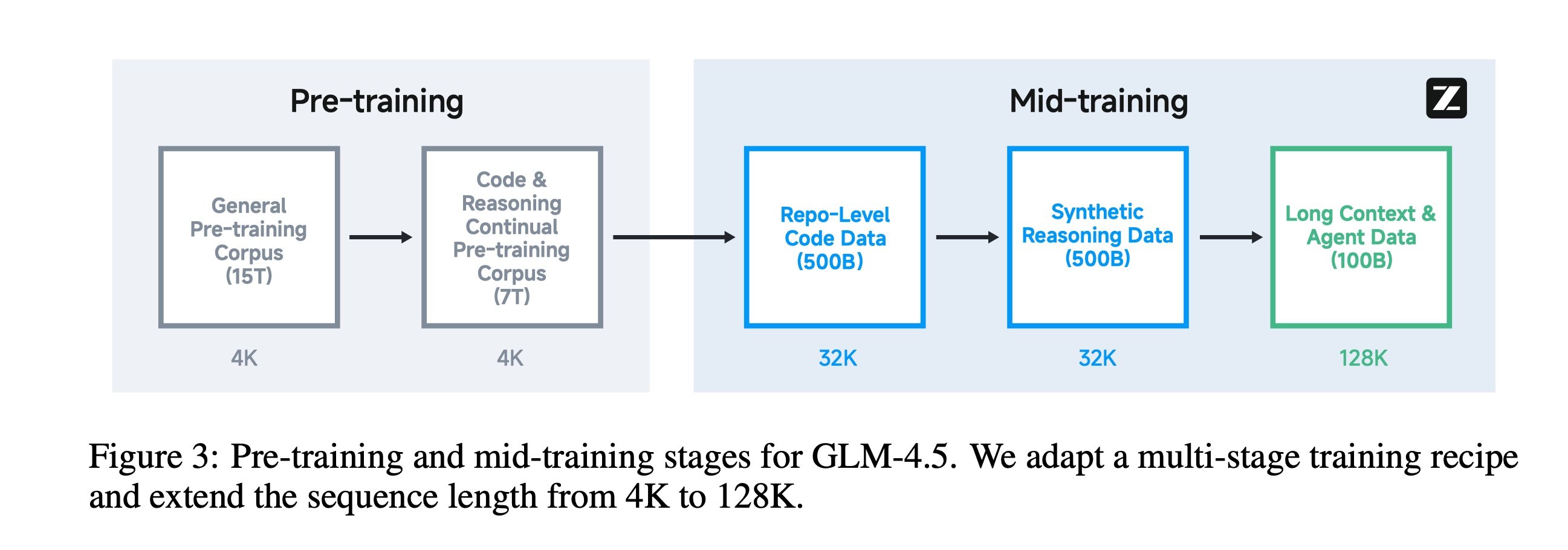
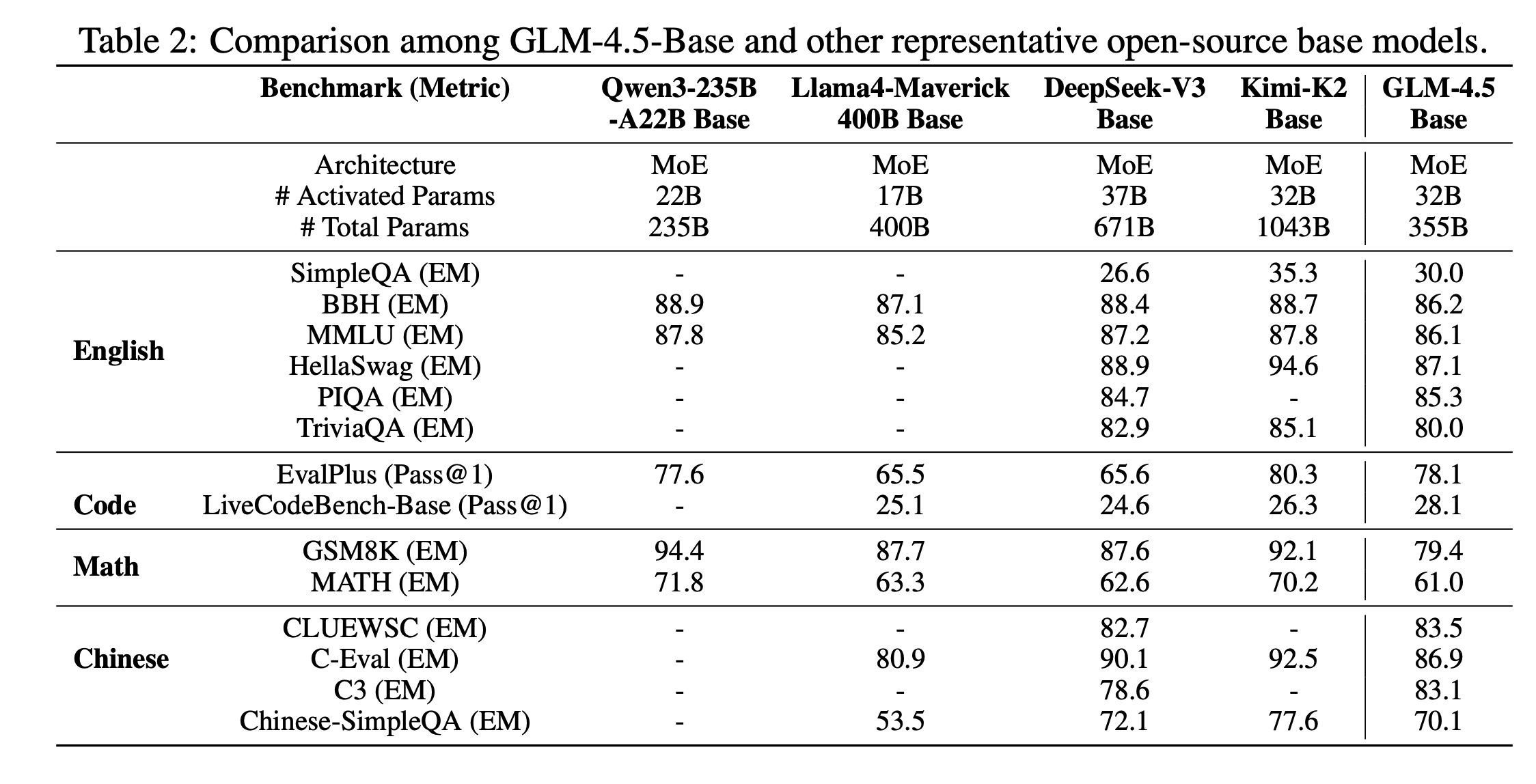
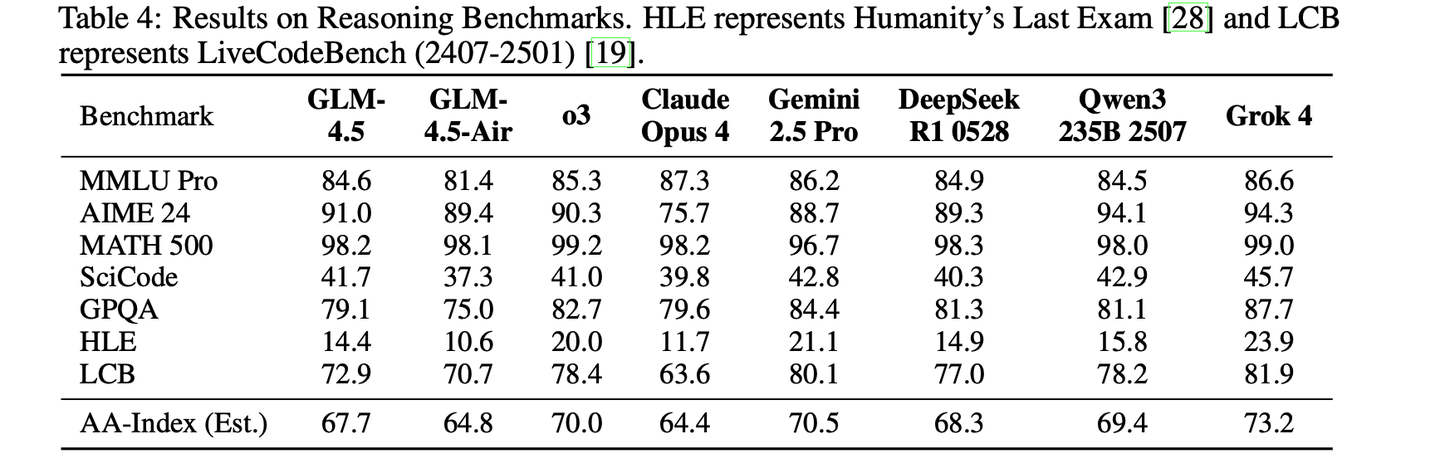
GLM 系列
📅 发表于 2025/09/24
🔄 更新于 2025/09/24
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
mainllm
#glm4.5
#moe
#pretrain
#midtrain
#posttrain
#agentic sft
#reasoning rl
#Agentic RL
#WebSearcj
#SWE RL
#GeneralRL
#HolisticRL
#InstructionFollowing RL
#FunctionCall RL
#Pathology RL