Agent-RL 综述型笔记
📅 发表于 2025/05/21
🔄 更新于 2025/05/21
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
agent-rl
#agent-rl
在学习Agent-RL过程中,发现很多有意思的文章,本想放到一篇博客整理,但发现太多,于是对其进行拆开,整体目前分为4个部分:
技术达人写的文章,笔记。
Agent RL 优缺点分析 🧐
🏴 背景
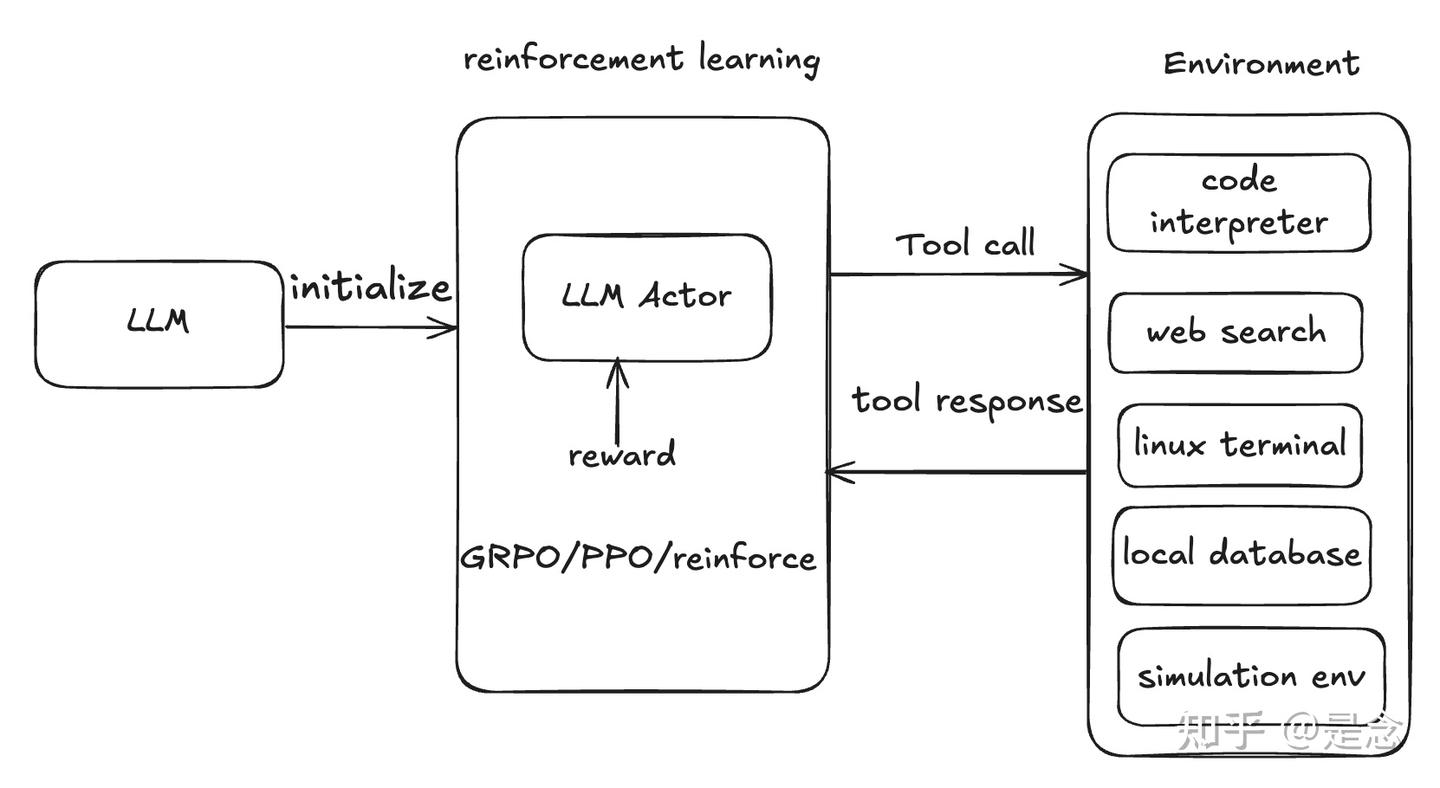
Agentic tool use learning 也开始用上了 GRPO 等 RL 算法,让 LLM 学会使用 code-intepreter、web-search 等工具,增强模型数学及推理能力,包括单轮/多轮 tool-use。🌟 Agent RL 优点
online-rl 方法,需要的数据量小很多,而传统 DPO 需要大量数据进行训练。 ⚠️ Agent RL 缺点
DeepSeek 技术分析 🔍
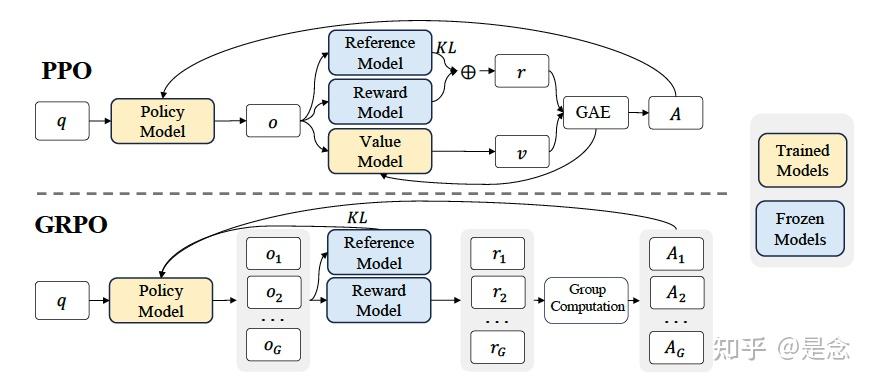
MoE:降低了训练成本、提高了推理效率Multi-Head Latent Attention:减少了注意力部分的KV缓存、Low RankMulti-Token Prediction:提高模型性能(准确性)DualPipe:提高了大规模GPU集群的计算与通信比率和效率FP8 Training:采样低精度训练进一步降低训练成本DeepSeek-R1:采样GRPO和多阶段训练。DeepSeek R1 GRPO 带火了RL技术路线,其中GRPO和PPO相差较小。主要区别是advantage是sampling过程产生样本的reward 求均值求方差得到的。
其他具体内容见拆分后的笔记。

其他具体内容见拆分后的笔记。