Code TaskRL 论文阅读
📅 发表于 2025/12/21
🔄 更新于 2025/12/21
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
code-rl
#Klear-Reasoner
#LongCoT SFT
#精细化RL数据
#GPPO算法
#SkyWork-OR1
#数学代码数据构建
#多阶段长度扩展
#高温采样
#on-policy
#AceReason-Nemotron
#分阶段RL
#鲁棒数据构建Pipeline
#Code-R1-Interpreter
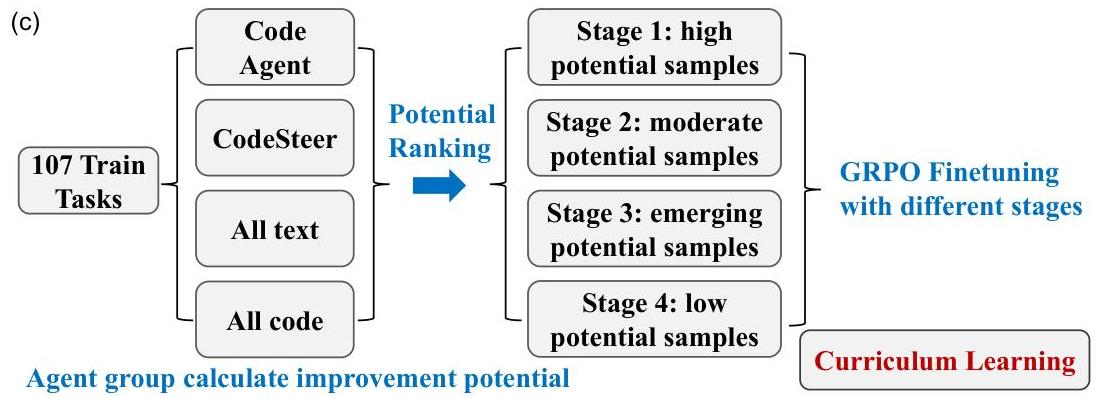
#数据潜力
#多阶段课程学习
#DeepCoder-14B-Preview
#迭代扩展长度
#AceCoder
#RewardModel
#Rule奖励