(18年笔记)基于策略函数的学习方法
📅 发表于 2018/04/22
🔄 更新于 2018/04/22
👁️ -- 次访问
📝 0 字
⏳ 0 分钟
#策略函数
#策略梯度
#REINFORCE
#基准函数
#Actot-Critic
#强化学习算法总结
1. 核心思想
策略连续可微函数 (策略连续可微假设)梯度上升的方法优化参数策略梯度是一种基于梯度的RL方法。2. 总结核心3个推导步骤
目标函数,算导数策略状态转移概率轨迹回报做分解,算出策略梯度 ⭐策略梯度推导 (目标函数
求导数转换成期望形式优化方向:使总回报越大的轨迹概率也越大, 代入策略环境状态转移概率进一步细分偏导数,梯度只和策略相关
代入算出策略梯度
0-t的累计回报 和 t到T的累计回报, 时刻t的动作只能影响t时刻之后的奖励,不能影响t时刻之前的奖励。时刻t作为起始时刻到时刻T,收到的总回报核心思想
当前策略随机采样N条轨迹来近似期望。随机梯度上升算法,每次采样1条轨迹,并计算每个时刻的梯度,来更新参数算法步骤
输入:状态空间可微分策略函数
初始化:随机初始化参数
根据
缺点
训练不稳定;
背景
核心思想
使用基准函数减小策略梯度的方差,基准函数和
每个时刻的策略梯度:引入基准函数之前
引入基准函数之后新旧策略梯度一致,保证了无偏性越相关,方差越小,就越好基准函数的选择
很自然可以选择值函数作为基准函数 :
但由于值函数未知,可用学习参数
用参数估计,目标函数如下,和Q网络参数逼近很像。
用蒙特卡罗来估计
最终策略函数参数
算法步骤
可微分策略函数可微分状态值函数更新值函数和策略函数参数目的
无偏性:减小方差:核心方法
保证无偏性推导期望:推导可知求解极值点 方差恒为正,是常数;根据上式可知凹函数,必然存在极小值求导数并使其为0,求解出最小值时的取值。代回极值点,求解出最小值极小值:
背景
方差大、学习效率较低,计算慢状态s的总回报由即时奖励和下个状态的值函数来估计。核心思想
迭代计算t作为初始时刻的轨迹总回报 通过每步各自不断学习更新,评分越来越准、表演越来越好。 演员,策略函数评论员,值函数值函数目标函数,调整打分标准策略函数策略梯度, 调整策略;值函数作为基线函数,降低方差,打分)调整打分标准)基函数来减少策略梯度的方差(调整策略)优点
算法步骤
可微分策略函数可微分状态值函数执行动作 获得奖励 新状态动态规划估计轨迹回报,计算基准差值 更新值函数参数、更新策略函数参数
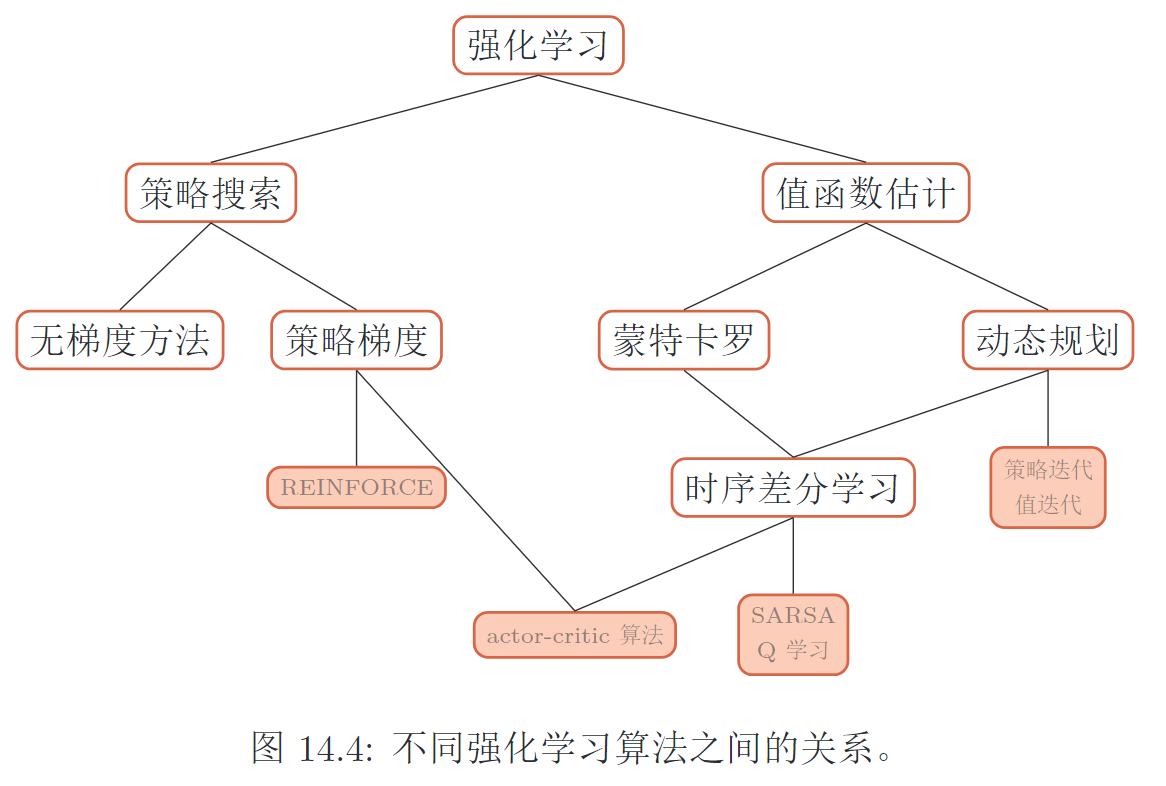
1. 通用步骤
2. 值函数与策略函数的比较
值函数的方法
策略更新,导致值函数的改变比较大,对收敛性有一定的影响
策略函数的方法
策略更新,更加平稳。
缺点:策略函数的解空间很大,难以进行充分采样,导致方差较大,容易陷入局部最优解。

| 强化学习 | 监督学习 | |
|---|---|---|
| 样本 | 与环境进行交互产生样本,进行试错学习 | 人工收集并标注 |
| 反馈 | 只有奖励,并且是延迟的 | 需要明确的指导信息(每个状态对应一个动作) |